本文主要是介绍深度学习中小知识点系列(二十三) 解读python中的装饰器(极为详尽),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 初探装饰器(概念的通俗化解释)
- 前言
- 一、什么是装饰器
- 二、为什么要用装饰器
- 三、简单的装饰器
- 四、装饰器的语法糖@
- 五、装饰器传参
- 六、带参数的装饰器
- 七、类装饰器
- 八、带参数的类装饰器
- 九、装饰器的顺序
- 内置装饰器()三种
- property
- staticmethod
- classmethod
- 进了一步解读
- 初探装饰器(概念的通俗化解释)
- Hello,装饰器
- 第一种:普通装饰器
- 第二种:带参数的函数装饰器
- 第三种:不带参数的类装饰器
- 第四种:带参数的类装饰器
- 第五种:使用偏函数与类实现装饰器
- 第六种:能装饰类的装饰器
- 12个Python装饰器(案例实现讲解)
- 学会这12个Python装饰器,让你的代码更上一层楼
- 1. @logger
- 2. @wraps
- 3. @lru_cache
- 4. @repeat
- 5. @timeit
- 6. @retry
- 7. @countcall
- 8. @rate_limited
- 9. @dataclass
- 10. @register
- 11. @property
- 12. @singledispatch
- 结论
- 8 个Python装饰器值得一试!
初探装饰器(概念的通俗化解释)
前言
最近有人问我装饰器是什么,我就跟他说,其实就是装饰器就是类似于女孩子的发卡。你喜欢的一个女孩子,她可以有很多个发卡,而当她戴上不同的发卡,她的头顶上就是装饰了不同的发卡。但是你喜欢的女孩子还是你喜欢的女孩子。如果还觉得不理解的话,装饰器就是咱们的手机壳,你尽管套上了手机壳,但并不影响你的手机功能,可你的手机还是该可以给你玩,该打电话打电话,该玩游戏玩游戏,。而你的手机就变成了带手机壳的手机。
装饰器就是python的一个拦路虎,你干或者不干它,它都在那里。如果你想学会高级的python用法,装饰器就是你这个武松必须打倒的一只虎。
本文的环境如下:
win10,python3.7
一、什么是装饰器
装饰器是给现有的模块增添新的小功能,可以对原函数进行功能扩展,而且还不需要修改原函数的内容,也不需要修改原函数的调用。
装饰器的使用符合了面向对象编程的开放封闭原则。
开放封闭原则主要体现在两个方面:
- 对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。
- 对修改封闭,意味着类一旦设计完成,就可以独立其工作,而不要对类尽任何修改。
二、为什么要用装饰器
使用装饰器之前,我们要知道,其实python里是万物皆对象,也就是万物都可传参。
函数也可以作为函数的参数进行传递的。
通过下面这个简单的例子可以更直观知道函数名是如何直接作为参数进行传递
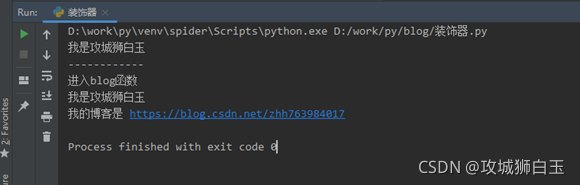
def baiyu():print("我是攻城狮白玉")def blog(name):print('进入blog函数')name()print('我的博客是 https://blog.csdn.net/zhh763984017')if __name__ == '__main__':func = baiyu # 这里是把baiyu这个函数名赋值给变量funcfunc() # 执行func函数print('------------')blog(baiyu) # 把baiyu这个函数作为参数传递给blog函数
执行结果如下所示:
接下来,我想知道这**baiyu和blog**两个函数分别的执行时间是多少,我就把代码修改如下:
import timedef baiyu():t1 = time.time()print("我是攻城狮白玉")time.sleep(2)print("执行时间为:", time.time() - t1)def blog(name):t1 = time.time()print('进入blog函数')name()print('我的博客是 https://blog.csdn.net/zhh763984017')print("执行时间为:", time.time() - t1)if __name__ == '__main__':func = baiyu # 这里是把baiyu这个函数名赋值给变量funcfunc() # 执行func函数print('------------')blog(baiyu) # 把baiyu这个函数作为参数传递给blog函数
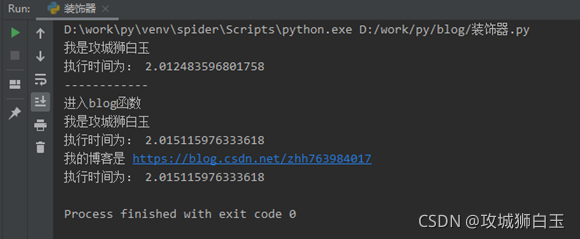
上述的改写已经实现了我需要的功能,但是,当我有另外一个新的函数【python_blog_list】,具体如下:
def python_blog_list():print('''【Python】爬虫实战,零基础初试爬虫下载图片(附源码和分析过程)https://blog.csdn.net/zhh763984017/article/details/119063252 ''')print('''【Python】除了多线程和多进程,你还要会协程https://blog.csdn.net/zhh763984017/article/details/118958668 ''')print('''【Python】爬虫提速小技巧,多线程与多进程(附源码示例)https://blog.csdn.net/zhh763984017/article/details/118773313 ''')print('''【Python】爬虫解析利器Xpath,由浅入深快速掌握(附源码例子)https://blog.csdn.net/zhh763984017/article/details/118634945 ''')
也需要计算函数执行时间的,那按之前的逻辑,就是改写如下:
def python_blog_list():t1 = time.time()print('''【Python】爬虫实战,零基础初试爬虫下载图片(附源码和分析过程)https://blog.csdn.net/zhh763984017/article/details/119063252 ''')print('''【Python】除了多线程和多进程,你还要会协程https://blog.csdn.net/zhh763984017/article/details/118958668 ''')print('''【Python】爬虫提速小技巧,多线程与多进程(附源码示例)https://blog.csdn.net/zhh763984017/article/details/118773313 ''')print('''【Python】爬虫解析利器Xpath,由浅入深快速掌握(附源码例子)https://blog.csdn.net/zhh763984017/article/details/118634945 ''')print("执行时间为:", time.time() - t1)
如果也要这样子写的话,不就重复造轮子了吗?虽说人类的本质是鸽王和复读机,但作为一个优秀的cv攻城狮(ctrl+c和ctrl+v)肯定是要想办法偷懒的呀

装饰器,就是可以让我们拓展一些原有函数没有的功能。
三、简单的装饰器
基于上面的函数执行时间的需求,我们就手写一个简单的装饰器进行实现。
import timedef baiyu():print("我是攻城狮白玉")time.sleep(2)def count_time(func):def wrapper():t1 = time.time()func()print("执行时间为:", time.time() - t1)return wrapperif __name__ == '__main__':baiyu = count_time(baiyu) # 因为装饰器 count_time(baiyu) 返回的时函数对象 wrapper,这条语句相当于 baiyu = wrapperbaiyu() # 执行baiyu()就相当于执行wrapper()
这里的count_time是一个装饰器,装饰器函数里面定义一个wrapper函数,把func这个函数当作参数传入,函数实现的功能是把func包裹起来,并且返回wrapper函数。wrapper函数体就是要实现装饰器的内容。
当然,这里的wrapper函数名是可以自定义的,只要你定义的函数名,跟你return的函数名是相同的就好了
四、装饰器的语法糖@
你如果看过其他python项目里面的代码里,难免会看到@符号,这个@符号就是装饰器的语法糖。因此上面简单的装饰器还是可以通过语法糖来实现的,这样就可以省去
baiyu = count_time(baiyu)
这一句代码,而直接调用baiyu()这个函数
换句话说,其实使用装饰器的是,默认传入的参数就是被装饰的函数。
import timedef count_time(func):def wrapper():t1 = time.time()func()print("执行时间为:", time.time() - t1)return wrapper@count_time
def baiyu():print("我是攻城狮白玉")time.sleep(2)if __name__ == '__main__':# baiyu = count_time(baiyu) # 因为装饰器 count_time(baiyu) 返回的时函数对象 wrapper,这条语句相当于 baiyu = wrapper# baiyu() # 执行baiyu()就相当于执行wrapper()baiyu() # 用语法糖之后,就可以直接调用该函数了
五、装饰器传参
当我们的被装饰的函数是带参数的,此时要怎么写装饰器呢?
上面我们有定义了一个blog函数是带参数的
def blog(name):print('进入blog函数')name()print('我的博客是 https://blog.csdn.net/zhh763984017')
此时我们的装饰器函数要优化一下下,修改成为可以接受任意参数的装饰器
def count_time(func):def wrapper(*args,**kwargs):t1 = time.time()func(*args,**kwargs)print("执行时间为:", time.time() - t1)return wrapper
此处,我们的wrapper函数的参数为*args和**kwargs,表示可以接受任意参数
这时我们就可以调用我们的装饰器了。
import timedef count_time(func):def wrapper(*args, **kwargs):t1 = time.time()func(*args, **kwargs)print("执行时间为:", time.time() - t1)return wrapper@count_time
def blog(name):print('进入blog函数')name()print('我的博客是 https://blog.csdn.net/zhh763984017')if __name__ == '__main__':# baiyu = count_time(baiyu) # 因为装饰器 count_time(baiyu) 返回的时函数对象 wrapper,这条语句相当于 baiyu = wrapper# baiyu() # 执行baiyu()就相当于执行wrapper()# baiyu() # 用语法糖之后,就可以直接调用该函数了blog(baiyu)
六、带参数的装饰器
前面咱们知道,装饰器函数也是函数,既然是函数,那么就可以进行参数传递,咱们怎么写一个带参数的装饰器呢?
前面咱们的装饰器只是实现了一个计数,那么我想在使用该装饰器的时候,传入一些备注的msg信息,怎么办呢?咱们一起看一下下面的代码
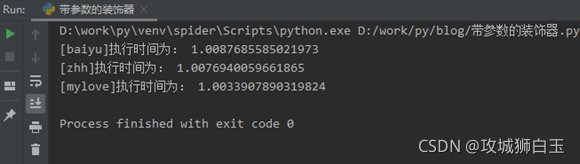
import timedef count_time_args(msg=None):def count_time(func):def wrapper(*args, **kwargs):t1 = time.time()func(*args, **kwargs)print(f"[{msg}]执行时间为:", time.time() - t1)return wrapperreturn count_time@count_time_args(msg="baiyu")
def fun_one():time.sleep(1)@count_time_args(msg="zhh")
def fun_two():time.sleep(1)@count_time_args(msg="mylove")
def fun_three():time.sleep(1)if __name__ == '__main__':fun_one()fun_two()fun_three()
咱们基于原来的count_time函数外部再包一层用于接收参数的count_time_args,接收回来的参数就可以直接在内部的函数里面调用了。上述代码执行效果如下:
七、类装饰器
上面咱们一起学习了怎么写装饰器函数,在python中,其实也可以同类来实现装饰器的功能,称之为类装饰器。类装饰器的实现是调用了类里面的__call__函数。类装饰器的写法比我们装饰器函数的写法更加简单。
当我们将类作为一个装饰器,工作流程:
- 通过__init__()方法初始化类
- 通过__call__()方法调用真正的装饰方法
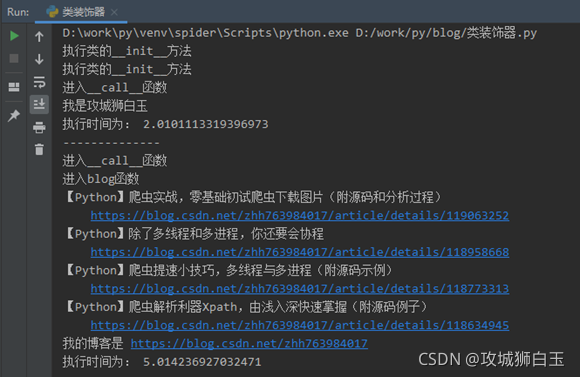
import timeclass BaiyuDecorator:def __init__(self, func):self.func = funcprint("执行类的__init__方法")def __call__(self, *args, **kwargs):print('进入__call__函数')t1 = time.time()self.func(*args, **kwargs)print("执行时间为:", time.time() - t1)@BaiyuDecorator
def baiyu():print("我是攻城狮白玉")time.sleep(2)def python_blog_list():time.sleep(5)print('''【Python】爬虫实战,零基础初试爬虫下载图片(附源码和分析过程)https://blog.csdn.net/zhh763984017/article/details/119063252 ''')print('''【Python】除了多线程和多进程,你还要会协程https://blog.csdn.net/zhh763984017/article/details/118958668 ''')print('''【Python】爬虫提速小技巧,多线程与多进程(附源码示例)https://blog.csdn.net/zhh763984017/article/details/118773313 ''')print('''【Python】爬虫解析利器Xpath,由浅入深快速掌握(附源码例子)https://blog.csdn.net/zhh763984017/article/details/118634945 ''')@BaiyuDecorator
def blog(name):print('进入blog函数')name()print('我的博客是 https://blog.csdn.net/zhh763984017')if __name__ == '__main__':baiyu()print('--------------')blog(python_blog_list)
八、带参数的类装饰器
当装饰器有参数的时候,init() 函数就不能传入func(func代表要装饰的函数)了,而func是在__call__函数调用的时候传入的。
class BaiyuDecorator:def __init__(self, arg1, arg2): # init()方法里面的参数都是装饰器的参数print('执行类Decorator的__init__()方法')self.arg1 = arg1self.arg2 = arg2def __call__(self, func): # 因为装饰器带了参数,所以接收传入函数变量的位置是这里print('执行类Decorator的__call__()方法')def baiyu_warp(*args): # 这里装饰器的函数名字可以随便命名,只要跟return的函数名相同即可print('执行wrap()')print('装饰器参数:', self.arg1, self.arg2)print('执行' + func.__name__ + '()')func(*args)print(func.__name__ + '()执行完毕')return baiyu_warp@BaiyuDecorator('Hello', 'Baiyu')
def example(a1, a2, a3):print('传入example()的参数:', a1, a2, a3)if __name__ == '__main__':print('准备调用example()')example('Baiyu', 'Happy', 'Coder')print('测试代码执行完毕')
建议各位同学好好比对一下这里的代码和不带参数的装饰器代码的区别,加深理解。
九、装饰器的顺序
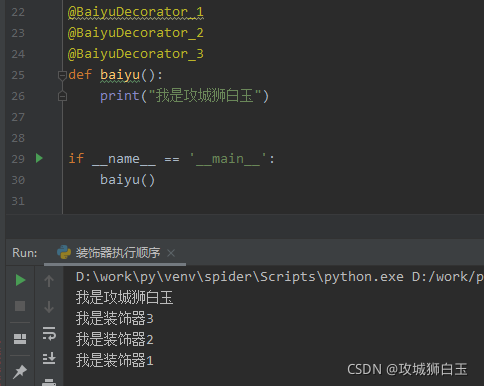
一个函数可以被多个装饰器进行装饰,那么装饰器的执行顺序是怎么样的呢?咱们执行一下下面的代码就清楚了
def BaiyuDecorator_1(func):def wrapper(*args, **kwargs):func(*args, **kwargs)print('我是装饰器1')return wrapperdef BaiyuDecorator_2(func):def wrapper(*args, **kwargs):func(*args, **kwargs)print('我是装饰器2')return wrapperdef BaiyuDecorator_3(func):def wrapper(*args, **kwargs):func(*args, **kwargs)print('我是装饰器3')return wrapper@BaiyuDecorator_1
@BaiyuDecorator_2
@BaiyuDecorator_3
def baiyu():print("我是攻城狮白玉")if __name__ == '__main__':baiyu()
由输出结果可知,在装饰器修饰完的函数,在执行的时候先执行原函数的功能,然后再由里到外依次执行装饰器的内容。
我们带三个装饰器的函数的代码如下:
@BaiyuDecorator_1
@BaiyuDecorator_2
@BaiyuDecorator_3
def baiyu():print("我是攻城狮白玉")
上述的代码可以看作如下代码,就能理解为何是由里到外执行了
baiyu = BaiyuDecorator_1 (BaiyuDecorator_2 (BaiyuDecorator_3(baiyu)))
内置装饰器()三种
内置装饰器也包括引用内置库得到的装饰器
将要详解的内置装饰器如下:
| 装饰器名 | 所在模块 |
|---|---|
| property | 无 |
| staticmethod | 无 |
| classmethod | 无 |
property
property用于装饰类函数,被装饰的类函数不可在类被实例化后被调用,只能通过访问与函数同名的属性进行调用。
class Test:num = 1@propertydef num_val(self):return self.numtest = Test()
print(test.num_val)
out:
1
我们不妨解构这个类,来看看num_val到底是什么:
for i in dir(test):if not i.startswith("__"):print(i, type(getattr(test, i)))
out:
num <class 'int'>
num_val <class 'int'>
可以看到,装饰过的num_val确实变成了一个属性。但是它与普通属性有一个很大区别,就是它没有定义set方法,也就是它不能被赋值,这是一个只读变量:
test.num_val = 1
out:
Traceback (most recent call last):File "e:\python draft\test.py", line 9, in <module>test.num_val = 1
AttributeError: can't set attribute
利用这个特性,我们可以实现对Python类成员的安全访问,还记得Python的私有成员怎么写的吗?通过双下划线前缀可以将一个类属性定义为私有属性。我们利用这些特性就可以实现下述的例子:
class Test:__number = 1@propertydef number(self):return self.__numbertest = Test()try:print(test.__number)
except:print("访问 私有成员 失败")try:print(test.number)print("访问 类属性 成功")
except:passtry:test.number = 1
except:print("修改 类属性 失败")
out:
访问 私有成员 失败
1
访问 类属性 成功
修改 类属性 失败
这个trick在Python开发中非常有用。
staticmethod
被这个装饰器装饰过的类函数就会被声明称一个函数的静态函数。静态函数不需要类实例化就能直接调用。被装饰的函数不需要代表对象实例的self参数。
class Test:@staticmethoddef add(x, y):return x + y@staticmethoddef minus(x, y):return x - yprint(Test.add(1, 1))
print(Test.minus(1, 2))
out:
2
-1
在staticmethod下,你不仅可以实现曾经C++,Java中熟悉的static,还可以直接实现Java中的接口机制或者C++中的命名空间机制。比如这样:
class Game:win = 0loss = 0@staticmethoddef I_win():Game.win += 1@staticmethoddef I_loss():Game.loss += 1Game.I_win()
Game.I_loss()
Game.I_win()
Game.I_win()
Game.I_loss()print(Game.win, Game.loss)
直接定义在Python类中的属性为静态变量,比如上面的win和loss
如果没有staticmethod装饰器,我们也能实现上面的效果:
- 创建文件名为Game.py
- 定义各个变量和函数
- 在入口文件中引入Game.py
- 剩余操作完全一样
但是很显然,这样做比较麻烦,而且如果我们单个接口类实现成本低,那么就会创建若干的python文件,在运行项目时,还增加了读入这些文件的IO成本,使用staticmethod装饰器无疑更加灵活。
classmethod
这个装饰器很有意思,它与staticmethod的使用效果非常像,被装饰的类函数也是可以在没有被实例下直接定义的,只不过被classmethod装饰的函数必须要有一个cls参数,代表类本身。来看一个实例:
class Test:n = 1def __init__(self, a) -> None:self.a = a@classmethoddef add_a(cls):print(cls)print(cls == Test)print(cls.n)Test.add_a()
由于被classmethod装饰的函数强制暴露了类自身,所以我们可以通过被classmethod装饰的函数对类的静态变量进行一定的操作(staticmethod中也可以)
与staticmethod不同的是,classmethod更多是关乎这个类的静态变量的操作,而staticmethod则是与实例无关但与类封装功能有关的函数。
结合python的多态(比如鸭子类型),使用classmethod使得在python中开发抽象程度高于class的实体成为了可能。在许多Python内置库的原语实现代码中,经常能看到classmethod的影子。
进了一步解读
@property
把类内方法当成属性来使用,必须要有返回值,相当于getter;
假如没有定义 @func.setter 修饰方法的话,就是只读属性
class Car:def __init__(self, name, price):self._name = nameself._price = price @propertydef car_name(self):return self._name# car_name可以读写的属性 @car_name.setterdef car_name(self, value):self._name = value# car_price是只读属性 @propertydef car_price(self):return str(self._price) + '万'benz = Car('benz', 30)print(benz.car_name) # benz
benz.car_name = "baojun"
print(benz.car_name) # baojun
print(benz.car_price) # 30万
@staticmethod
静态方法,不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。
@classmethod
类方法,不需要self参数,但第一个参数需要是表示自身类的cls参数。
例子
class Demo(object):text = "三种方法的比较"def instance_method(self):print("调用实例方法")@classmethoddef class_method(cls):print("调用类方法")print("在类方法中 访问类属性 text: {}".format(cls.text))print("在类方法中 调用实例方法 instance_method: {}".format(cls().instance_method()))@staticmethoddef static_method():print("调用静态方法")print("在静态方法中 访问类属性 text: {}".format(Demo.text))print("在静态方法中 调用实例方法 instance_method: {}".format(Demo().instance_method()))if __name__ == "__main__":# 实例化对象d = Demo()# 对象可以访问 实例方法、类方法、静态方法# 通过对象访问text属性print(d.text)# 通过对象调用实例方法d.instance_method()# 通过对象调用类方法d.class_method()# 通过对象调用静态方法d.static_method()# 类可以访问类方法、静态方法# 通过类访问text属性print(Demo.text)# 通过类调用类方法Demo.class_method()# 通过类调用静态方法Demo.static_method()
@staticmethod 和 @classmethod 的 区别 和 使用场景:
在上述例子中,我们可以看出,
区别
在定义静态类方法和类方法时,@staticmethod 装饰的静态方法里面,想要访问类属性或调用实例方法,必须需要把类名写上;
而**@classmethod**装饰的类方法里面,会传一个cls参数,代表本类,这样就能够避免手写类名的硬编码。
在调用静态方法和类方法时,实际上写法都差不多,一般都是通过 类名.静态方法() 或 类名.类方法()。
也可以用实例化对象去调用静态方法和类方法,但为了和实例方法区分,最好还是用类去调用静态方法和类方法。
使用场景
所以,在定义类的时候,
假如不需要用到与类相关的属性或方法时,就用静态方法@staticmethod;
假如需要用到与类相关的属性或方法,然后又想表明这个方法是整个类通用的,而不是对象特异的,就可以使用类方法@classmethod。
初探装饰器(概念的通俗化解释)
今天给大家分享一下关于装饰器的知识点,内容非常干,全程高能,认真吸收看完,一定会对装饰器有更深的理解。
Hello,装饰器
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
装饰器的使用方法很固定
- 先定义一个装饰器(帽子)
- 再定义你的业务函数或者类(人)
- 最后把这装饰器(帽子)扣在这个函数(人)头上
就像下面这样子
# 定义装饰器
def decorator(func):def wrapper(*args, **kw):return func()return wrapper# 定义业务函数并进行装饰
@decorator
def function():print("hello, decorator")
实际上,装饰器并不是编码必须性,意思就是说,你不使用装饰器完全可以,它的出现,应该是使我们的代码
- 更加优雅,代码结构更加清晰
- 将实现特定的功能代码封装成装饰器,提高代码复用率,增强代码可读性
接下来,我将以实例讲解,如何编写出各种简单及复杂的装饰器。
第一种:普通装饰器
首先咱来写一个最普通的装饰器,它实现的功能是:
- 在函数执行前,先记录一行日志
- 在函数执行完,再记录一行日志
# 这是装饰器函数,参数 func 是被装饰的函数
def logger(func):def wrapper(*args, **kw):print('我准备开始执行:{} 函数了:'.format(func.__name__))# 真正执行的是这行。func(*args, **kw)print('主人,我执行完啦。')return wrapper
假如,我的业务函数是,计算两个数之和。写好后,直接给它带上帽子。
@logger
def add(x, y):print('{} + {} = {}'.format(x, y, x+y))
然后执行一下 add 函数。
add(200, 50)
来看看输出了什么?
我准备开始执行:add 函数了:
200 + 50 = 250
我执行完啦。
第二种:带参数的函数装饰器
通过上面两个简单的入门示例,你应该能体会到装饰器的工作原理了。
不过,装饰器的用法还远不止如此,深究下去,还大有文章。今天就一起来把这个知识点学透。
回过头去看看上面的例子,装饰器是不能接收参数的。其用法,只能适用于一些简单的场景。不传参的装饰器,只能对被装饰函数,执行固定逻辑。
装饰器本身是一个函数,做为一个函数,如果不能传参,那这个函数的功能就会很受限,只能执行固定的逻辑。这意味着,如果装饰器的逻辑代码的执行需要根据不同场景进行调整,若不能传参的话,我们就要写两个装饰器,这显然是不合理的。
比如我们要实现一个可以定时发送邮件的任务(一分钟发送一封),定时进行时间同步的任务(一天同步一次),就可以自己实现一个 periodic_task (定时任务)的装饰器,这个装饰器可以接收一个时间间隔的参数,间隔多长时间执行一次任务。
可以这样像下面这样写,由于这个功能代码比较复杂,不利于学习,这里就不贴了。
@periodic_task(spacing=60)
def send_mail():pass@periodic_task(spacing=86400)
def ntp()pass
那我们来自己创造一个伪场景,可以在装饰器里传入一个参数,指明国籍,并在函数执行前,用自己国家的母语打一个招呼。
# 小明,中国人
@say_hello("china")
def xiaoming():pass# jack,美国人
@say_hello("america")
def jack():pass
那我们如果实现这个装饰器,让其可以实现 传参 呢?
会比较复杂,需要两层嵌套。
def say_hello(contry):def wrapper(func):def deco(*args, **kwargs):if contry == "china":print("你好!")elif contry == "america":print('hello.')else:return# 真正执行函数的地方func(*args, **kwargs)return decoreturn wrapper
来执行一下
xiaoming()
print("------------")
jack()
看看输出结果。
你好!
------------
hello.
第三种:不带参数的类装饰器
以上都是基于函数实现的装饰器,在阅读别人代码时,还可以时常发现还有基于类实现的装饰器。
基于类装饰器的实现,必须实现__call__和__init__两个内置函数。
__init__:接收被装饰函数__call__:实现装饰逻辑。
还是以日志打印这个简单的例子为例
class logger(object):def __init__(self, func):self.func = funcdef __call__(self, *args, **kwargs):print("[INFO]: the function {func}() is running..."\.format(func=self.func.__name__))return self.func(*args, **kwargs)@logger
def say(something):print("say {}!".format(something))say("hello")
执行一下,看看输出
[INFO]: the function say() is running...
say hello!
第四种:带参数的类装饰器
上面不带参数的例子,你发现没有,只能打印INFO级别的日志,正常情况下,我们还需要打印DEBUG WARNING等级别的日志。这就需要给类装饰器传入参数,给这个函数指定级别了。
带参数和不带参数的类装饰器有很大的不同。
__init__:不再接收被装饰函数,而是接收传入参数。__call__:接收被装饰函数,实现装饰逻辑。
class logger(object):def __init__(self, level='INFO'):self.level = leveldef __call__(self, func): # 接受函数def wrapper(*args, **kwargs):print("[{level}]: the function {func}() is running..."\.format(level=self.level, func=func.__name__))func(*args, **kwargs)return wrapper #返回函数@logger(level='WARNING')
def say(something):print("say {}!".format(something))say("hello")
我们指定WARNING级别,运行一下,来看看输出。
[WARNING]: the function say() is running...
say hello!
第五种:使用偏函数与类实现装饰器
绝大多数装饰器都是基于函数和闭包实现的,但这并非制造装饰器的唯一方式。
事实上,Python 对某个对象是否能通过装饰器( @decorator)形式使用只有一个要求:decorator 必须是一个“可被调用(callable)的对象。
对于这个 callable 对象,我们最熟悉的就是函数了。
除函数之外,类也可以是 callable 对象,只要实现了__call__函数(上面几个例子已经接触过了)。
还有容易被人忽略的偏函数其实也是 callable 对象。
接下来就来说说,如何使用 类和偏函数结合实现一个与众不同的装饰器。
如下所示,DelayFunc 是一个实现了__call__ 的类,delay 返回一个偏函数,在这里 delay 就可以做为一个装饰器。(以下代码摘自 Python工匠:使用装饰器的小技巧)
'''
学习中遇到问题没人解答?小编创建了一个Python学习交流QQ群:857662006
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import time
import functoolsclass DelayFunc:def __init__(self, duration, func):self.duration = durationself.func = funcdef __call__(self, *args, **kwargs):print(f'Wait for {self.duration} seconds...')time.sleep(self.duration)return self.func(*args, **kwargs)def eager_call(self, *args, **kwargs):print('Call without delay')return self.func(*args, **kwargs)def delay(duration):"""装饰器:推迟某个函数的执行。同时提供 .eager_call 方法立即执行"""# 此处为了避免定义额外函数,# 直接使用 functools.partial 帮助构造 DelayFunc 实例return functools.partial(DelayFunc, duration)
我们的业务函数很简单,就是相加
@delay(duration=2)
def add(a, b):return a+b
来看一下执行过程
>>> add # 可见 add 变成了 Delay 的实例
<__main__.DelayFunc object at 0x107bd0be0>
>>>
>>> add(3,5) # 直接调用实例,进入 __call__
Wait for 2 seconds...
8
>>>
>>> add.func # 实现实例方法
<function add at 0x107bef1e0>
第六种:能装饰类的装饰器
用 Python 写单例模式的时候,常用的有三种写法。其中一种,是用装饰器来实现的。
以下便是我自己写的装饰器版的单例写法。
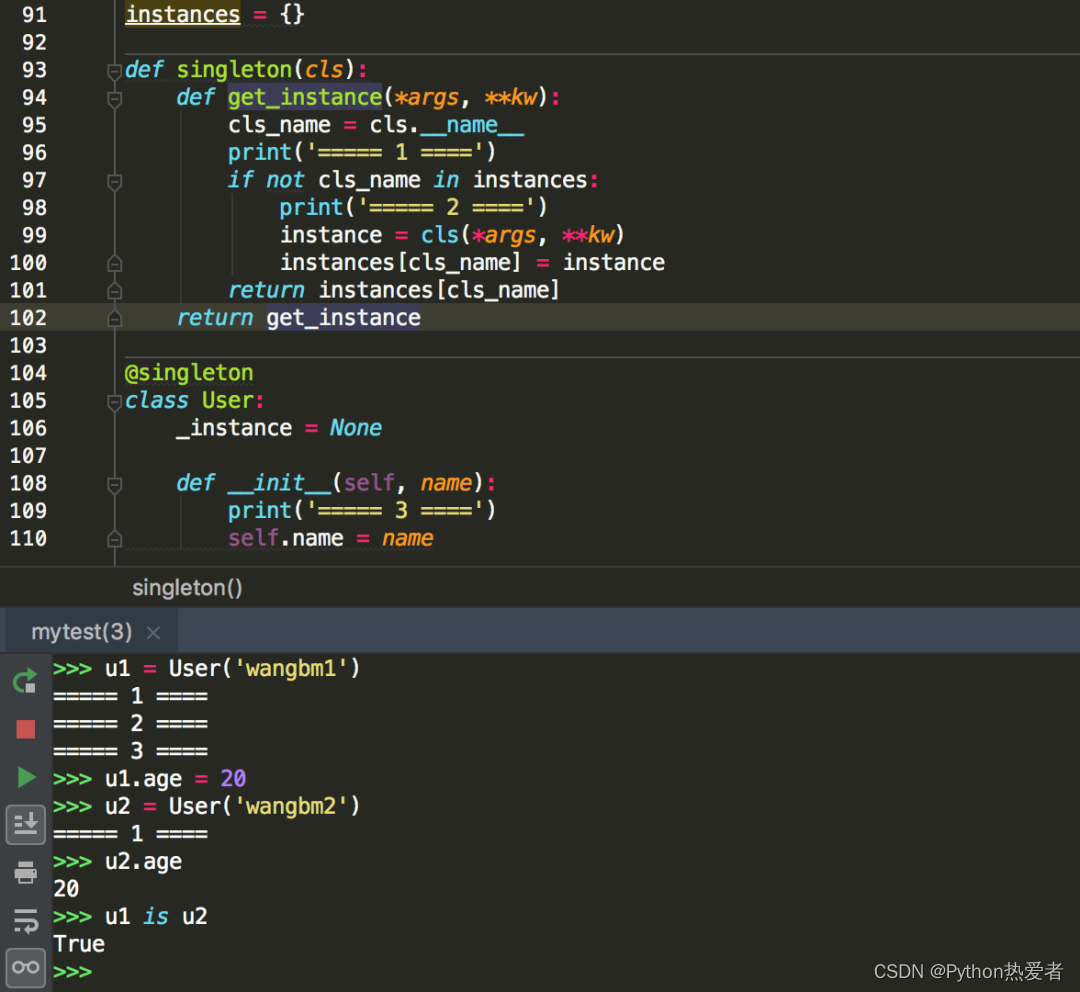
instances = {}def singleton(cls):def get_instance(*args, **kw):cls_name = cls.__name__print('===== 1 ====')if not cls_name in instances:print('===== 2 ====')instance = cls(*args, **kw)instances[cls_name] = instancereturn instances[cls_name]return get_instance@singleton
class User:_instance = Nonedef __init__(self, name):print('===== 3 ====')self.name = name
可以看到我们用singleton 这个装饰函数来装饰 User 这个类。装饰器用在类上,并不是很常见,但只要熟悉装饰器的实现过程,就不难以实现对类的装饰。在上面这个例子中,装饰器就只是实现对类实例的生成的控制而已。
其实例化的过程,你可以参考我这里的调试过程,加以理解。
12个Python装饰器(案例实现讲解)
学会这12个Python装饰器,让你的代码更上一层楼
Python 装饰器是个强大的工具,可帮你生成整洁、可重用和可维护的代码。某种意义上说,会不会用装饰器是区分新手和老鸟的重要标志。如果你不熟悉装饰器,你可以将它们视为将函数作为输入并在不改变其主要用途的情况下扩展其功能的函数。装饰器可以有效提高你的工作效率并避免重复代码。本文我整理了项目中经常用到的 12 个装饰器,值得每一个Python开发者掌握。
1. @logger
我们从最简单的装饰器开始,手动实现一个可以记录函数开始和结束的装饰器。被修饰函数的输出结果如下所示:
some_function(args)# ----- some_function: start -----
# some_function executing
# ----- some_function: end -----
要实现一个装饰器,首先要给装饰器起一个合适的名称:这里我们给装饰器起名为logger。
装饰器本质上是一个函数,它将一个函数作为输入并返回一个函数作为输出。 输出函数通常是输入的扩展版。 在我们的例子中,我们希望输出函数用start和end语句包围输入函数的调用。
由于我们不知道输入函数都带有什么参数,我们可以使用 *args 和 **kwargs 从包装函数传递它们。*args 和 **kwargs 允许传递任意数量的位置参数和关键字参数。
下面是logger装饰器的示例代码:
def logger(function):def wrapper(*args, **kwargs):print(f"----- {function.__name__}: start -----")output = function(*args, **kwargs)print(f"----- {function.__name__}: end -----")return outputreturn wrapper
logger函数可以应用于任意函数,比如:
decorated_function = logger(some_function)
上面的语句是正确的,但Python 提供了更 Pythonic 的语法——使用 @ 修饰符。因此更通常的写法是:
@logger
def some_function(text):print(text)some_function("first test")
# ----- some_function: start -----
# first test
# ----- some_function: end -----some_function("second test")
# ----- some_function: start -----
# second test
# ----- some_function: end -----
2. @wraps
此装饰器更新wrapper函数,使其看起来像一个原始函数,并继承其名字和属性。
要了解 @wraps 的作用以及为什么需要它,让我们将前面写的logger装饰器应用到一个将两个数字相加的简单函数中。
下面的代码是未使用@wraps装饰器的版本:
def logger(function):def wrapper(*args, **kwargs):"""wrapper documentation"""print(f"----- {function.__name__}: start -----")output = function(*args, **kwargs)print(f"----- {function.__name__}: end -----")return outputreturn wrapper@logger
def add_two_numbers(a, b):"""this function adds two numbers"""return a + b
如果我们用__name__ 和 __doc__来查看被装饰函数add_two_numbers的名称和文档,会得到如下结果:
add_two_numbers.__name__
'wrapper'add_two_numbers.__doc__
'wrapper documentation'
输出的是wrapper函数的名称和文档。这是我们预期想要的结果,我们希望保留原始函数的名称和文档。这时@wraps装饰器就派上用场了。
我们唯一需要做的就是给wrapper函数加上@wraps装饰器。
from functools import wrapsdef logger(function):@wraps(function)def wrapper(*args, **kwargs):"""wrapper documentation"""print(f"----- {function.__name__}: start -----")output = function(*args, **kwargs)print(f"----- {function.__name__}: end -----")return outputreturn wrapper@logger
def add_two_numbers(a, b):"""this function adds two numbers"""return a + b
再此检查add_two_numbers函数的名称和文档,我们可以看到该函数的元数据。
add_two_numbers.__name__
# 'add_two_numbers'add_two_numbers.__doc__
# 'this function adds two numbers'
3. @lru_cache
@lru_cache是Python内置装饰器,可以通过from functools import lru_cache引入。@lru_cache的作用是缓存函数的返回值,当缓存装满时,使用least-recently-used(LRU)算法丢弃最少使用的值。
@lru_cache装饰器适合用于输入输出不变且运行时间较长的任务,例如查询数据库、请求静态页面或一些繁重的处理。
在下面的示例中,我使用@lru_cache来修饰一个模拟某些处理的函数。然后连续多次对同一输入应用该函数。
import random
import time
from functools import lru_cache@lru_cache(maxsize=None)
def heavy_processing(n):sleep_time = n + random.random()time.sleep(sleep_time)# 初次调用
%%time
heavy_processing(0)
# CPU times: user 363 µs, sys: 727 µs, total: 1.09 ms
# Wall time: 694 ms# 第二次调用
%%time
heavy_processing(0)
# CPU times: user 4 µs, sys: 0 ns, total: 4 µs
# Wall time: 8.11 µs# 第三次调用
%%time
heavy_processing(0)
# CPU times: user 5 µs, sys: 1 µs, total: 6 µs
# Wall time: 7.15 µs
从上面的输出可以看到,第一次调用花费了694ms,因为执行了time.sleep()函数。后面两次调用由于参数相同,直接返回缓存值,因此并没有实际执行函数内容,因此非常快地得到函数返回。
4. @repeat
该装饰器的所用是多次调用被修饰函数。这对于调试、压力测试或自动化多个重复任务非常有用。
跟前面的装饰器不同,@repeat接受一个输入参数,
def repeat(number_of_times):def decorate(func):@wraps(func)def wrapper(*args, **kwargs):for _ in range(number_of_times):func(*args, **kwargs)return wrapperreturn decorate
上面的代码定义了一个名为repeat的装饰器,有一个输入参数number_of_times。与前面的案例不同,这里需要decorate函数来传递被修饰函数。然后,装饰器定义一个名为wrapper的函数来扩展被修饰函数。
@repeat(5)
def hello_world():print("hello world")hello_world()
# hello world
# hello world
# hello world
# hello world
# hello world
5. @timeit
该装饰器用来测量函数的执行时间并打印出来。这对调试和监控非常有用。
在下面的代码片段中,@timeit装饰器测量process_data函数的执行时间,并以秒为单位打印所用的时间。
import time
from functools import wrapsdef timeit(func):@wraps(func)def wrapper(*args, **kwargs):start = time.perf_counter()result = func(*args, **kwargs)end = time.perf_counter()print(f'{func.__name__} took {end - start:.6f} seconds to complete')return resultreturn wrapper@timeit
def process_data():time.sleep(1)process_data()
# process_data took 1.000012 seconds to complete
6. @retry
当函数遇到异常时,该装饰器会强制函数重试多次。它接受三个参数:重试次数、捕获的异常以及重试之间的间隔时间。
其工作原理如下:
wrapper函数启动num_retrys次迭代的for循环。- 将被修饰函数放到try/except块中。每次迭代如果调用成功,则中断循环并返回结果。否则,休眠
sleep_time秒后继续下一次迭代。 - 当for循环结束后函数调用依然不成功,则抛出异常。
示例代码如下:
import random
import time
from functools import wrapsdef retry(num_retries, exception_to_check, sleep_time=0):"""遇到异常尝试重新执行装饰器"""def decorate(func):@wraps(func)def wrapper(*args, **kwargs):for i in range(1, num_retries+1):try:return func(*args, **kwargs)except exception_to_check as e:print(f"{func.__name__} raised {e.__class__.__name__}. Retrying...")if i < num_retries:time.sleep(sleep_time)# 尝试多次后仍不成功则抛出异常raise ereturn wrapperreturn decorate@retry(num_retries=3, exception_to_check=ValueError, sleep_time=1)
def random_value():value = random.randint(1, 5)if value == 3:raise ValueError("Value cannot be 3")return valuerandom_value()
# random_value raised ValueError. Retrying...
# 1random_value()
# 5
7. @countcall
@countcall用于统计被修饰函数的调用次数。这里的调用次数会缓存在wraps的count属性中。
from functools import wrapsdef countcall(func):@wraps(func)def wrapper(*args, **kwargs):wrapper.count += 1result = func(*args, **kwargs)print(f'{func.__name__} has been called {wrapper.count} times')return resultwrapper.count = 0return wrapper@countcall
def process_data():passprocess_data()
process_data has been called 1 times
process_data()
process_data has been called 2 times
process_data()
process_data has been called 3 times
8. @rate_limited
@rate_limited装饰器会在被修饰函数调用太频繁时,休眠一段时间,从而限制函数的调用速度。这在模拟、爬虫、接口调用防过载等场景下非常有用。
import time
from functools import wrapsdef rate_limited(max_per_second):min_interval = 1.0 / float(max_per_second)def decorate(func):last_time_called = [0.0]@wraps(func)def rate_limited_function(*args, **kargs):elapsed = time.perf_counter() - last_time_called[0]left_to_wait = min_interval - elapsedif left_to_wait > 0:time.sleep(left_to_wait)ret = func(*args, **kargs)last_time_called[0] = time.perf_counter()return retreturn rate_limited_functionreturn decorate
该装饰器的工作原理是:测量自上次函数调用以来所经过的时间,并在必要时等待适当的时间,以确保不超过速率限制。其中等待时间=min_interval - elapsed,这里min_intervalue是两次函数调用之间的最小时间间隔(以秒为单位),已用时间是自上次调用以来所用的时间。如果经过的时间小于最小间隔,则函数在再次执行之前等待left_to_wait秒。
⚠注意:该函数在调用之间引入了少量的时间开销,但确保不超过速率限制。
如果不想自己手动实现,可以用第三方包,名叫ratelimit。
pip install ratelimit
使用非常简单,只需要装饰被调用函数即可:
from ratelimit import limitsimport requestsFIFTEEN_MINUTES = 900@limits(calls=15, period=FIFTEEN_MINUTES)
def call_api(url):response = requests.get(url)if response.status_code != 200:raise Exception('API response: {}'.format(response.status_code))return response
如果被装饰函数的调用次数超过允许次数,则会抛出ratelimit.RateLimitException异常。要处理该异常可以将@sleep_and_retry装饰器与@limits装饰器一起使用。
@sleep_and_retry
@limits(calls=15, period=FIFTEEN_MINUTES)
def call_api(url):response = requests.get(url)if response.status_code != 200:raise Exception('API response: {}'.format(response.status_code))return response
这样被装饰函数在再次执行之前会休眠剩余时间。
9. @dataclass
Python 3.7 引入了@dataclass装饰器,将其加入到标准库,用于装饰类。它主要用于存储数据的类自动生成诸如__init__, __repr__, __eq__, __lt__,__str__ 等特殊函数。这样可以减少模板代码,并使类更加可读和可维护。
另外,@dataclass还提供了现成的美化方法,可以清晰地表示对象,将其转换为JSON格式,等等。
from dataclasses import dataclass, @dataclass
class Person:first_name: strlast_name: strage: intjob: strdef __eq__(self, other):if isinstance(other, Person):return self.age == other.agereturn NotImplementeddef __lt__(self, other):if isinstance(other, Person):return self.age < other.agereturn NotImplementedjohn = Person(first_name="John", last_name="Doe", age=30, job="doctor",)anne = Person(first_name="Anne", last_name="Smith", age=40, job="software engineer",)print(john == anne)
# Falseprint(anne > john)
# Trueasdict(anne)
#{'first_name': 'Anne',
# 'last_name': 'Smith',
# 'age': 40,
# 'job': 'software engineer'}
10. @register
如果你的Python脚本意外终止,但你仍想执行一些任务来保存你的工作、执行清理或打印消息,那么@register在这种情况下非常方便。
from atexit import register@register
def terminate():perform_some_cleanup()print("Goodbye!")while True:print("Hello")
运行上面的代码会不断在控制台输出"Hello",点击Ctrl + C强制终止脚本运行,你会看到控制台输出"Goodbye",说明程序在中断后执行了@register装饰器装饰的terminate()函数。
11. @property
@property装饰器用于定义类属性,这些属性本质上是类实例属性的getter、setter和deleter方法。
通过使用@property装饰器,可以将方法定义为类属性,并将其作为类属性进行访问,而无需显式调用该方法。
如果您想在获取或设置值时添加一些约束和验证逻辑,使用@property装饰器会非常方便。
下面的示例中,我们在rating属性上定义了一个setter,对输入执行约束(介于0和5之间)。
class Movie:def __init__(self, r):self._rating = r@propertydef rating(self):return self._rating@rating.setterdef rating(self, r):if 0 <= r <= 5:self._rating = relse:raise ValueError("The movie rating must be between 0 and 5!")batman = Movie(2.5)
batman.rating
# 2.5batman.rating = 4
batman.rating
# 4batman.rating = 10# ---------------------------------------------------------------------------
# ValueError Traceback (most recent call last)
# Input In [16], in <cell line: 1>()
# ----> 1 batman.rating = 10
# Input In [11], in Movie.rating(self, r)
# 12 self._rating = r
# 13 else:
# ---> 14 raise ValueError("The movie rating must be between 0 and 5!")
#
# ValueError: The movie rating must be between 0 and 5!
12. @singledispatch
@singledispatch允许函数对不同类型的参数有不同的实现,有点像Java等面向对象语言中的函数重载。
from functools import singledispatch@singledispatch
def fun(arg):print("Called with a single argument")@fun.register(int)
def _(arg):print("Called with an integer")@fun.register(list)
def _(arg):print("Called with a list")fun(1) # Prints "Called with an integer"
fun([1, 2, 3]) # Prints "Called with a list"
结论
装饰器是一个重要的抽象思想,可以在不改变原始代码的情况下扩展代码,如缓存、自动重试、速率限制、日志记录,或将类转换为超级数据容器等。
装饰器的功能远不止于此,本文介绍的12个常用装饰器只是抛砖引玉,当你理解了装饰器思想和用法后,可以发挥创造力,实现各种自定义装饰器来解决具体问题。
最后给大家推荐一个很棒的装饰器列表,里面记录了大量实用的、有趣的装饰器,大家可以多多尝试使用。
8 个Python装饰器值得一试!
Python 编程语言的一大优点是它把所有功能都打包到一个小包中,这些功能非常有用。许多特性改变了 Python 代码,使得该语言更加灵活。如果使用得当,一些功能可以有效缩短编写程序所需的时间。
装饰器是什么?
装饰器(decorators)是一个可以用于改变一个 Python 函数对象行为的函数。它们可以应用于类和函数,可以做很多非常有趣的事情!
装饰器可以用来缩短代码、加速代码并彻底改变代码在 Python 中的行为方式。
今天我想分享一些我认为值得一试的装饰器。
01
@lru_cache
此列表中的第一个装饰器来自 functools 模块。
该模块包含在标准库中,非常易于使用。它还包含比这个装饰器更酷的功能,但这个装饰器肯定是我最喜欢的。
此装饰器可用于使用缓存加速函数的连续运行。当然,这应该在使用时记住一些关于缓存的注意事项,但在通用使用情况下,大多数时候这个装饰器是值得使用的。
能够用一个简单的装饰器来加速代码是非常棒的。
可以从这样的装饰器中受益的函数的一个很好的例子是递归函数,例如计算阶乘的函数:
def factorial(n):return n * factorial(n-1) if n else 1
递归在计算时间上可能非常困难,但添加此装饰器有助于显着加快此函数的连续运行速度。
@lru_cache
def factorial(n):return n * factorial(n-1) if n else 1
现在每当我们运行这个函数时,前几个阶乘计算将被保存到缓存中。
因此,下次我们调用该函数时,我们只需要计算我们之前使用的阶乘之后的阶乘。
当然,并不是所有的阶乘计算都会被保存,但是很容易理解为什么这个装饰器的一个很好的应用程序来加速一些自然很慢的代码。
02
@jit
JIT 是即时编译(Just In Time)的缩写。通常每当我们在 Python 中运行一些代码时,发生的第一件事就是编译。
这种编译会产生一些开销,因为类型被分配了内存,并存储为未分配但已命名的别名。使用即时编译,我们在执行时才进行编译。
在很多方面,我们可以将其视为类似于并行计算的东西,其中 Python 解释器同时处理两件事以节省一些时间。
Numba JIT 编译器因将这一概念提供到 Python 中而闻名。与@lru_cache 类似,可以非常轻松地调用此装饰器,并立即提高代码的性能。Numba 包提供了 jit 装饰器,它使运行更密集的软件变得更加容易,而不必进入 C。
以下案例使用@jit 装饰器加速蒙特卡洛方法计算。
from numba import jit
import random@jit(nopython=True)
def monte_carlo_pi(nsamples):acc = 0for i in range(nsamples):x = random.random()y = random.random()if (x ** 2 + y ** 2) < 1.0:acc += 1return 4.0 * acc / nsamples
03
@do_twice
do_twice 装饰器的功能与它的名字差不多。此装饰器可用于通过一次调用运行两次函数。这当然有一些用途,我发现它对调试特别有用。
它可以用于测量两个不同迭代的性能。以 Functools 为例,我们可以让一个函数运行两次,以检查是否有改进。该函数由 Python 中的装饰器模块提供,该模块位于标准库中。
from decorators import do_twice
@do_twice
def timerfunc():
%timeit factorial(15)
04
@count_calls
count_calls 装饰器可用于提供有关函数在软件中使用多少次的信息。
像 do_twice 一样,这当然可以在调试时派上用场。
当添加到给定的函数时,我们将收到一个输出,告诉我们该函数每次运行时已经运行了多少次。这个装饰器也在标准库的装饰器模块中。
from decorators import count_calls
@count_calls
def function_example():
print("Hello World!")function_example()
function_example()
function_example()
05
@dataclass
为了节省编写类的时间,我一直使用的最好的装饰器之一是@dataclass 装饰器。
这个装饰器可用于快速编写类中常见的标准方法,这些方法通常会在我们编写的类中找到。
这个装饰器来自 dataclass 模块。这个模块也在标准库中,所以不需要 PIP 来尝试这个例子!
from dataclasses import dataclass@dataclass
class Food:
name: str
unit_price: float
stock: int = 0def stock_value(self) -> float:return(self.stock * self.unit_price)
这段代码将自动创建一个初始化函数 init(),其中包含填充类中数据所需的位置参数。
它们也将自动提供给 self,因此无需编写一个很长的函数来将一些数据参数放入类中。
06
@singleton
为了理解单例装饰器的用途,我们首先需要了解单例(singleton)是什么。从某种意义上说,单例是全局变量类型的一个版本。
这意味着类型被定义为只存在一次。尽管这些在 C++ 等语言中很常见,但在 Python 中却很少见到。使用单例,我们可以创建一个只使用一次的类并改变类,而不是通过初始化来构造新的类型。
通常,单例装饰器是由用户自己编写的,实际上并不是导入的。
这是因为单例仍然是对我们单例装饰器中提供的模板的引用。我们可以命名一个单例函数并编写一个包装器,以便在我们的类上使用这个装饰器:
def singleton(cls):instances = {}def wrapper(*args, **kwargs):if cls not in instances:instances[cls] = cls(*args, **kwargs)return instances[cls]return wrapper
@singleton
class cls:def func(self):
另一种方法是使用元类!
class Singleton(type):_instances = {}def __call__(cls, *args, **kwargs):if cls not in cls._instances:cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)return cls._instances[cls]class Logger(object):__metaclass__ = Singleton
07
@use_unit
在科学计算中经常派上用场的一种装饰器是 @use_unit 装饰器。
此装饰器可用于更改返回结果的表示单位。这对于那些不想在数据中添加度量单位但仍希望人们知道这些单位是什么的人很有用。
这个装饰器也不是在任何模块中真正可用,但它是非常常见的,对科学应用程序非常有用。
def use_unit(unit):"""Have a function return a Quantity with given unit"""use_unit.ureg = pint.UnitRegistry()def decorator_use_unit(func):@functools.wraps(func)def wrapper_use_unit(*args, **kwargs):value = func(*args, **kwargs)return value * use_unit.ureg(unit)return wrapper_use_unitreturn decorator_use_unit@use_unit("meters per second")
def average_speed(distance, duration):return distance / duration
08
@singledispatch
Functools 凭借非常有用的@singledispatch 装饰器再次在此列表中脱颖而出。
单调度是一种编程技术,在许多编程语言中都很常见,因为它是一种非常棒的编程方式。虽然我更喜欢多调度,但我认为单调度可以在很多方面扮演相同的角色。
这个装饰器使得在 Python 中使用多类型数据变得更加容易, 尤其当我们希望通过同一方法传递多种类型数据时,情况更是如此。
@singledispatch
def fun(arg, verbose=False):if verbose:print("Let me just say,", end=" ")print(arg)
@fun.register
def _(arg: int, verbose=False):if verbose:print("Strength in numbers, eh?", end=" ")print(arg)
@fun.register
def _(arg: list, verbose=False):if verbose:print("Enumerate this:")for i, elem in enumerate(arg):print(i, elem)
这篇关于深度学习中小知识点系列(二十三) 解读python中的装饰器(极为详尽)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





