本文主要是介绍数据结构第十四天(树的存储/双亲表示法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
概述
接口:
源码:
测试函数:
运行结果:
往期精彩内容
前言
孩子,一定要记得你的父母啊!!!
哈哈,今天开始学习树结构中的双亲表示法,让孩子记得归家的路,记得自己的父母是谁😉😉😉
概述
树的双亲表示法是一种常用的树的存储结构,它通过使用一个数组来表示树的节点,并且每个节点都包含了其父节点的索引信息。
在双亲表示法中,树的每个节点都包含以下两个信息:
- 节点的数据域:用来存储节点的数据。
- 父节点索引:用来存储该节点的父节点在数组中的索引。
每一个节点我们可以这样表示:

其中 data 是数据域,存储结点的数据信息。而 parent 是指针域,存储该结点的双亲在数组中的下标。
通过这种方式,我们可以方便地找到一个节点的父节点,并且能够实现树的遍历和操作。
使用双亲表示法可以有效地存储树的结构,并且可以方便地进行遍历和操作。但双亲表示法的缺点是,它不太适合表示具有大量节点的树,因为节点之间的关系需要通过数组来表示,可能会浪费一定的空间。
接口:
void addNode(char* data, char* parent);
void getParent(char* dest, char* child);
bool bTrueIfEmptyTree();
bool bTrueIfFullFilledTree();源码:
#include<string.h>
#include<stdio.h>
#include <malloc.h>
class TREE{
private:struct PARENTSTRUCT{char data[15];struct PARENTSTRUCT* parent;};struct PARENTSTRUCT* index[15];unsigned int currentSite = 0;struct PARENTSTRUCT* findParent(char* child); public:void addNode(char* data, char* parent);
void getParent(char* dest, char* child);
bool bTrueIfEmptyTree();
bool bTrueIfFullFilledTree();
};
struct TREE::PARENTSTRUCT* TREE::findParent(char* child)
{for (int i = 0; i < currentSite; ++i){if (strcmp(child, index[i]->data) == 0){return index[i]->parent;}}}
void TREE::addNode(char* data, char* parent)
{index[currentSite] = (PARENTSTRUCT*)malloc(sizeof(PARENTSTRUCT));strcpy(index[currentSite]->data, data);if (parent == nullptr){index[currentSite]->parent = nullptr;}else{for (int i = 0; i < currentSite; ++i){if (strcmp(parent, index[i]->data) == 0){index[currentSite]->parent = index[i];}}}currentSite++;return;
}
bool TREE::bTrueIfFullFilledTree()
{if (currentSite == 15){return true;}else{return false;}
}
void TREE::getParent(char* dest, char* child)
{PARENTSTRUCT* ptr = findParent(child);if (ptr != nullptr){strcpy(dest, ptr->data);}else{strcpy(dest, "抱歉,此为根");}return;
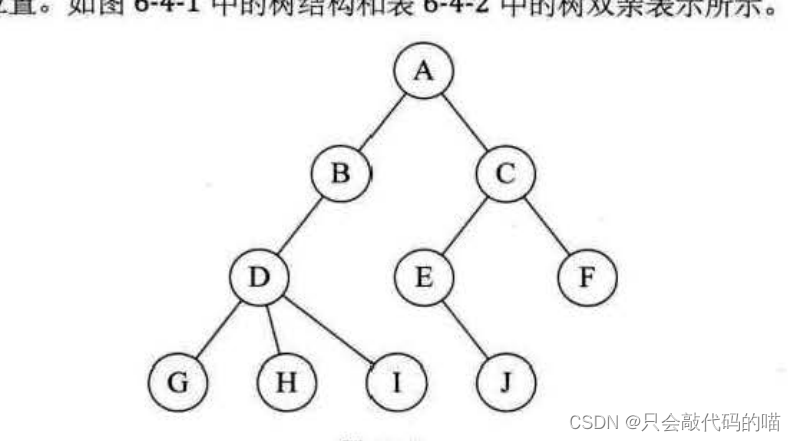
}由下图数据来建一棵树,由此进行测试
测试函数:
#include<stdio.h>
#include<iostream>
using namespace std;
#include"TREE.h"//上面提到的源码函数头文件
#include<windows.h>
int main()
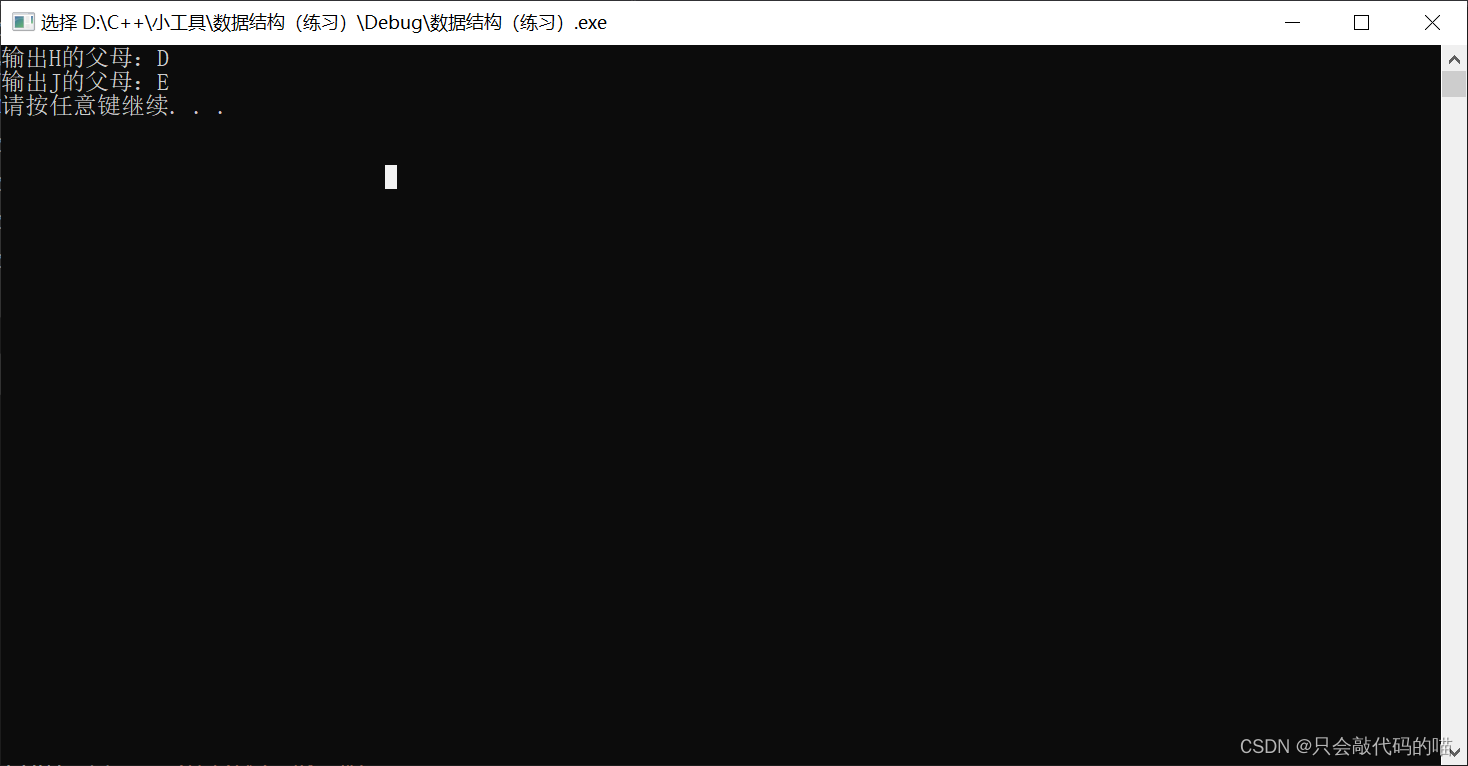
{TREE tree;tree.addNode("A", nullptr);tree.addNode("B","A");tree.addNode("C", "A");tree.addNode("D", "B");tree.addNode("G", "D");tree.addNode("H", "D");tree.addNode("I", "D");tree.addNode("E", "C");tree.addNode("F", "C");tree.addNode("J", "E");char buff[40];tree.getParent(buff, "H");cout << "输出H的父母:" << buff << endl;tree.getParent(buff, "J");cout << "输出J的父母:" << buff << endl;system("pause");return 0;
}运行结果:
往期精彩内容
数据结构第一天(生成1000以内的随机数自动填充数组)
数据结构第二天(直接插入排序/内存申请/指针操作)
数据结构第三天(折半插入排序)
数据结构第四天(希尔排序)
数据结构第五天(冒泡排序)
数据结构第六天(快速排序)
这篇关于数据结构第十四天(树的存储/双亲表示法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





