本文主要是介绍Oozie多任务串联和定时任务执行?看这篇就懂了!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面: 博主是一名大数据的初学者,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
在上一篇博客中,博主为大家带来了Oozie的简介,以及常用的基础操作,包括使用Oozie调度shell脚本,hive,mapreduce…(👉什么是Oozie?如何使用Oozie?蒟蒻博主带你快速上手Oozie!)。
本篇博客,为大家介绍的则是Oozie的任务串联和任务调度。

Oozie的任务串联
在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个action,实现多个任务之间的相互依赖关系。
例如现在有一个需求:首先执行一个shell脚本,执行完了之后再执行一个MR的程序,最后再执行一个hive的程序。
我们应该怎么实现呢?
第一步:准备工作目录
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
mkdir -p sereval-actions
第二步:准备调度文件
将我们之前的hive,shell,以及MR的执行,进行串联成到一个workflow当中去,准备资源文件。
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp hive2/script.q sereval-actions/
cp shell/hello.sh sereval-actions/
cp -ra map-reduce/lib sereval-actions/
第三步:开发调度的配置文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
创建配置文件workflow.xml并编辑
vim workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node"><shell xmlns="uri:oozie:shell-action:0.2"><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><configuration><property><name>mapred.job.queue.name</name><value>${queueName}</value></property></configuration><exec>${EXEC}</exec><!-- <argument>my_output=Hello Oozie</argument> --><file>/user/root/oozie_works/sereval-actions/${EXEC}#${EXEC}</file><capture-output/></shell><ok to="mr-node"/><error to="mr-node"/>
</action><action name="mr-node"><map-reduce><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><prepare><delete path="${nameNode}/${outputDir}"/></prepare><configuration><property><name>mapred.job.queue.name</name><value>${queueName}</value></property><!-- <property><name>mapred.mapper.class</name><value>org.apache.oozie.example.SampleMapper</value></property><property><name>mapred.reducer.class</name><value>org.apache.oozie.example.SampleReducer</value></property><property><name>mapred.map.tasks</name><value>1</value></property><property><name>mapred.input.dir</name><value>/user/${wf:user()}/${examplesRoot}/input-data/text</value></property><property><name>mapred.output.dir</name><value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value></property>--><!-- 开启使用新的API来进行配置 --><property><name>mapred.mapper.new-api</name><value>true</value></property><property><name>mapred.reducer.new-api</name><value>true</value></property><!-- 指定MR的输出key的类型 --><property><name>mapreduce.job.output.key.class</name><value>org.apache.hadoop.io.Text</value></property><!-- 指定MR的输出的value的类型--><property><name>mapreduce.job.output.value.class</name><value>org.apache.hadoop.io.IntWritable</value></property><!-- 指定输入路径 --><property><name>mapred.input.dir</name><value>${nameNode}/${inputdir}</value></property><!-- 指定输出路径 --><property><name>mapred.output.dir</name><value>${nameNode}/${outputDir}</value></property><!-- 指定执行的map类 --><property><name>mapreduce.job.map.class</name><value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value></property><!-- 指定执行的reduce类 --><property><name>mapreduce.job.reduce.class</name><value>org.apache.hadoop.examples.WordCount$IntSumReducer</value></property><!-- 配置map task的个数 --><property><name>mapred.map.tasks</name><value>1</value></property></configuration></map-reduce><ok to="hive2-node"/><error to="fail"/></action><action name="hive2-node"><hive2 xmlns="uri:oozie:hive2-action:0.1"><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><prepare><delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/><mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/></prepare><configuration><property><name>mapred.job.queue.name</name><value>${queueName}</value></property></configuration><jdbc-url>${jdbcURL}</jdbc-url><script>script.q</script><param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param><param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param></hive2><ok to="end"/><error to="fail"/></action>
<decision name="check-output"><switch><case to="end">${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}</case><default to="fail-output"/></switch>
</decision>
<kill name="fail"><message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output"><message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
开发job.properties配置文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
vim job.properties
nameNode=hdfs://bd001:8020
jobTracker=bd001:8032
queueName=default
examplesRoot=oozie_works
EXEC=hello.sh
outputDir=/oozie/output
inputdir=/oozie/input
jdbcURL=jdbc:hive2://node03:10000/default
oozie.use.system.libpath=true
# 配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/sereval-actions这个路径下
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/sereval-actions/workflow.xml
第四步:上传资源文件夹到hdfs对应路径
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/
hdfs dfs -put sereval-actions/ /user/root/oozie_works/
第五步:执行调度任务
cd /export/servers/oozie-4.1.0-cdh5.14.0/
bin/oozie job -oozie http://bd001:11000/oozie -config oozie_works/sereval-actions/job.properties -run
正确执行完调度任务,我们能发现跟上一篇Oozie三次单独调度后的效果一致。说明我们使用Oozie的任务串联就成功了!

下面我们来侃侃Oozie的任务调度。
Oozie的任务调度,定时任务执行
在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与workflow类似的,Coordinator 这个模块也是主要通过xml来进行配置即可,接下来我们就来看看如何配置Coordinator 来实现任务的定时调度。
Coordinator 的调度主要可以有两种实现方式
第一种:基于时间的定时任务调度
oozie基于时间的调度主要需要指定三个参数,第一个起始时间,第二个结束时间,第三个调度频率。
第二种:基于数据的任务调度
这种是基于数据的调度,只要在有了数据才会触发调度任务。
Oozie当中定时任务的设置
第一步:拷贝定时任务的调度模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -r examples/apps/cron oozie_works/cron-job
第二步:拷贝hello.sh脚本
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp shell/hello.sh cron-job/
第三步:修改配置文件
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/cron-job
vim job.properties
nameNode=hdfs://bd001:8020
jobTracker=bd001:8032
queueName=default
examplesRoot=oozie_worksoozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/cron-job/coordin
ator.xml
start=2020-06-01T00:00+0800
end=2020-06-02T00:00+0800
EXEC=hello.sh
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/cron-job/workflow.xml
修改coordinator.xml
vim coordinator.xml
<!--oozie的frequency 可以支持很多表达式,其中可以通过定时每分,或者每小时,或者每天,或者每月进行执行,也支持可以通过与linux的crontab表达式类似的写法来进行定时任务的执行例如frequency 也可以写成以下方式frequency="10 9 * * *" 每天上午的09:10:00开始执行任务frequency="0 1 * * *" 每天凌晨的01:00开始执行任务-->
<coordinator-app name="cron-job" frequency="${coord:minutes(1)}" start="${start}" end="${end}" timezone="GMT+0800"xmlns="uri:oozie:coordinator:0.4"><action><workflow><app-path>${workflowAppUri}</app-path><configuration><property><name>jobTracker</name><value>${jobTracker}</value></property><property><name>nameNode</name><value>${nameNode}</value></property><property><name>queueName</name><value>${queueName}</value></property></configuration></workflow></action>
</coordinator-app>
修改workflow.xml
vim workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.5" name="one-op-wf"><start to="action1"/><action name="action1"><shell xmlns="uri:oozie:shell-action:0.2"><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><configuration><property><name>mapred.job.queue.name</name><value>${queueName}</value></property></configuration><exec>${EXEC}</exec><!-- <argument>my_output=Hello Oozie</argument> --><file>/user/root/oozie_works/cron-job/${EXEC}#${EXEC}</file><capture-output/></shell><ok to="end"/><error to="end"/>
</action><end name="end"/>
</workflow-app>
第四步:上传到hdfs对应路径
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
hdfs dfs -put cron-job/ /user/root/oozie_works/
第五步:运行定时任务
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://bd001:11000/oozie -config oozie_works/cron-job/job.properties -run
运行定时任务的命令执行完毕,我们先去Oozie的web页面上查看任务进程状态
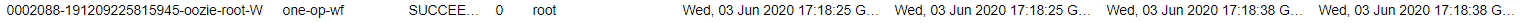
如果是success成功的状态,我们就可以根据我们设置的shell命令,在linux上查看效果。
根据我们shell脚本设置的内容,再加上在job.properties中设置的2020年6月1日到6月2日期间,每隔一分钟就执行一次。
当我们一会再去看脚本指定输出路径时
vim /export/servers/tmp/hello_oozie.txt
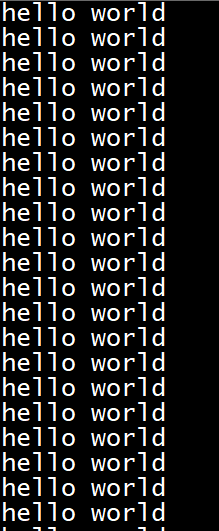
可以发现已经有了很多行的hello world
看到这里,如果你也成功跑出了效果,不妨给自己一个赞!

Oozie常用命令
查看所有普通任务
oozie jobs -oozie http://bd001:11000/oozie
查看定时任务
oozie jobs -oozie http://bd001:11000/oozie -jobtype coordinator
杀死某个任务
oozie可以通过jobid来杀死某个定时任务
oozie job -oozie http://bd001:11000/oozie -kill 0000033-200526143050941-oozie-root-W
小结
本篇博客主要为大家带来了Oozie在实际业务场景中更常用的操作。多个任务的串联和定时任务设置,有任何疑问可以随时后台联系博主哟(^U^)ノ~YO
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波🙏

这篇关于Oozie多任务串联和定时任务执行?看这篇就懂了!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




