本文主要是介绍2018,Pool-Based Sequential Active Learning for Regression,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Abstract
主动学习(Active Learning,AL)是一种减少数据标注工作量的机器学习方法。给定一个未标记样本池,它试图选择最有用的样本进行标记,以便从这些样本中构建的模型可以达到最好的性能。本文重点研究基于池的序列AL回归(ALR)。我们首先提出ALR方法在选择最有用的未标记样本时需要考虑的3个基本标准:信息性、代表性和多样性,并与现有的4种ALR方法进行比较。然后,我们提出了一种新的基于被动采样的ALR方法,该方法同时考虑了初始化和后续迭代中的代表性和多样性。值得注意的是,该方法还可以与文献中现有的其他ALR方法集成,以进一步提高性能。在来自不同领域的11个加州大学欧文分校、卡内基梅隆大学StatLib和佛罗里达大学Media Core数据集上的大量实验验证了我们提出的ALR方法的有效性。
I. INTRODUCTION
作为机器学习的一个子领域,主动学习(AL) [34]考虑了如下问题:如果学习算法可以选择训练数据,那么,在固定的预算下,例如,最大的有标签训练样本数,它应该选择哪个训练样本来最大化学习性能?例如,考虑情感计算中的情感估计[29]。情绪可以在唤醒度和效价的二维空间[31]或唤醒度、效价和优势度的三维空间[27]中表示为连续的数字。然而,情感具有很强的主观性、微妙性和不确定性。因此,通常需要多个人工评价者来获取每个情感样本(视频、音频、图像、生理信号等等)的真实情感值。例如,在"使用生理信号的情感分析数据库"数据集[22]中,每个视频片段由14-16名评估者评估;在VAM (Vera am Mittag用德语, Vera at Noon用英语)自发语音语料库[16]中,每个语句由6-17名评估者评估。International Affective Digitized Sounds 2nd Edition (IADS-2) 数据集第2版(IADS-2)中每个声音至少有110名评估员。这是非常耗时耗力的。如何最优地选择情感样本进行标注,从而以最小的代价(即最小标记样本数量)建立准确的回归模型?这就是AL所针对的典型问题类型。
文献[1],[6],[7],[9] - [11],[15],[24],[30],[32] - [35]中提出了许多AL方法。根据查询场景的不同,可以将其分为两类[38]:基于种群的和基于池的。在基于种群的AL中,测试输入分布已知,可以查询任意期望位置的训练输入样本。其目标是寻找最优的训练输入密度来生成训练输入样本。在基于池的AL中,给定一个未标记样本池,目标是最优地选择一些样本进行标记,使得从它们中训练的模型能够最好地标记剩余的样本。
不管是基于种群还是基于池,通常AL都是迭代的[7]。它首先从少量有标签的训练样本中建立一个基模型,然后选择一些最有帮助的无标签样本和查询作为它们的标签。然后将新标记的样本添加到训练数据集中并用于更新模型。该过程不断迭代,直到满足终止准则,例如最大迭代次数、最大标记样本数量或期望的交叉验证精度。根据每次迭代需要查询的未标记样本数量,AL方法也可以分为两类[7]:顺序型AL,每次查询一个样本;批处理型AL,每次查询多个样本。
本文重点研究基于池的序列AL回归(ALR)。尽管文献[34]中已经提出了许多AL方法,但它们大多是针对分类问题的。在数量有限的ALR方法[6] - [8],[10],[15],[25],[37] - [41]中,只有少数可以用于基于池的顺序ALR [6],[8],[40],[41]。本文将对其进行评述,指出其局限性,并提出提升其绩效的途径。
本文的主要贡献如下
-
我们扩展了AL-信息性、代表性和多样性的三个标准-从分类到回归,并提出了一个通用框架,可用于增强基线(BL) ALR方法。
-
我们实例化了几种同时考虑信息性、代表性和多样性的ALR方法,并展示了它们在广泛的应用领域中的性能。
本文的剩余部分安排如下:第二节介绍了ALR中应该考虑的三个基本标准,然后比较了现有的基于池的顺序ALR方法。第三节提出了几种新的基于池的序贯ALR方法。第四节介绍了评估所提出的ALR方法有效性的数据集和相应的实验结果。最后,第五部分得出结论。
II. EXISTING POOL-BASED SEQUENTIAL ALR APPROACHES
在本节中,我们提出了在基于池的序列ALR中选择未标记样本的三个基本标准,然后介绍了一些现有的基于池的序列ALR方法。我们还将这些ALR方法与这三个标准进行了比较,并指出了它们的局限性。
不失一般性,我们假设池由 N N N d d d维样本 { x n } n = 1 N \{x_n\}^N_{n = 1} {xn}n=1N, x n ∈ R d x_n∈\Bbb{R}^d xn∈Rd组成,并且第一个 M 0 M_0 M0样本已经被标记为 { y n } n = 1 M 0 \{y_n\}^{M0}_{n = 1} {yn}n=1M0。
A. Three Essential Criteria in ALR
我们提出了在基于池的序列ALR中选择对标签最有用的未标记样本应该考虑的以下三个标准。
-
Informativeness 信息性,即所选样本必须包含丰富的信息,因此对其进行标记将显著有利于目标函数。信息性可以通过不确定度(熵、到决策边界的距离、预测的置信度等等)、期望模型变化、期望误差减少等来衡量[34]。例如,在分类和回归中流行的AL方法QBC (Query-bycommittee) [30]中,未标记样本的信息量可以通过委员会成员之间的分歧来计算:分歧越大,样本越不确定,因此信息量越大。
-
Representativeness 代表性,可通过与目标样本(或其密度)相近或相近的样本数量来评价:数量越多,目标样本越具有代表性。显然,目标样本不应该是离群值。例如,在图1中,假设我们要建立一个回归模型来预测 x 1 x_1 x1和 x 2 x_2 x2的输出。灰色圆’ B ‘由于距离很远,很可能是一个离群点从输入空间的所有其他样本中,因此对其进行标注会误导回归模型,导致整体预测性能变差。也就是说,不应该选择像’ B '这样的样本进行ALR标记

- Diversity 多样性,即选择的样本应该分散在整个输入空间,而不是集中在一个小的局部区域。例如,在图1中,未标记样本来自输入空间中的三个簇,因此我们应该从所有三个簇中选择样本进行标记,而不是只关注其中的一个或两个。假设两个绿色圆圈已被选中并标注。那么,从第三个聚类(其中包含’ A ')中选择下一个样本似乎是非常合理的。
需要指出的是,AL for classification (ALC)也采用了类似的标准。例如,Shen等[36]提出了两种基于多准则的批处理模式ALC策略,这两种策略同时考虑了信息性、代表性和多样性。他们的策略1首先选择少数几个信息量最大的样本,对其进行聚类,然后选择聚类中心进行标记。他们的策略2首先计算每个样本的得分,作为其信息性和代表性的线性组合,选择得分高的样本,进一步向下选择其中最多样化的样本进行标注。这两种策略都是针对支持向量机分类器的。He等[19]考虑了批次模式ALC中的不确定性、代表性、信息含量和多样性。令 k k k为批次大小。他们将未标记样本的信息量计算为 不确定性×代表性,选择信息量最大的样本,通过核k-means聚类将其聚成 k k k个簇,最后选择 k k k个簇中心进行标记。
然而,据我们所知,除了我们最近关于增强型批处理模式ALR (EBMALR)的工作[40]外,类似的想法在ALR中没有被探索。将这些概念从分类扩展到回归并不简单,因为可能有许多不同的策略来整合这三个标准,而不同的策略会导致显著不同的性能。EBMALR [40]就是这样的策略之一。然而,尽管我们之前的研究[40]表明其在脑–机接口的批处理模式ALR中取得了很好的性能,但本文(第Ⅳ- E节)表明其在顺序ALR中表现不佳。因此,如何综合信息性、代表性和多样性来设计高性能的基于池的序贯ALR仍然是一个开放性问题。
接下来,我们将介绍几种现有的基于池的序贯ALR方法,并将它们的基本原理与我们的三个标准进行比较。
B. Query-by-Committee
QBC对于分类[1],[15],[26],[34],[35]和回归[6],[10],[11],[24],[30],[34]都是非常流行的基于池的AL方法。其基本思想是从已有的带标签的训练数据集(通常通过辅助程序和/或不同的学习算法实现)中构建一个学习器委员会,然后从池中选择该委员会最不同意的未标记样本进行标注。
本文采用RayChaudhuri和Hamey [30]提出的基于池的QBC回归方法。它首先将 M 0 M_0 M0标记的样本自举成 P P P份,每份包含 M 0 M_0 M0样本,但有重复,并从每份中建立回归模型,即委员会由P个回归模型组成。设第 p p p个模型对第 n n n个未标记样本的预测为 y n p y^p_n ynp。然后,对于 N − M 0 N - M_0 N−M0个无标签样本,计算 P P P个个体预测的方差,即:
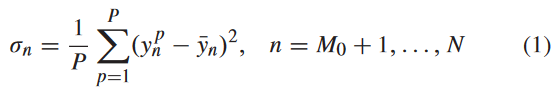
其中 y ˉ n = ( 1 / P ) ∑ p = 1 P y n p \bar{y}_n = (1 / P)\sum^P_{p = 1}y^p_n yˉn=(1/P)∑p=1Pynp,然后选取方差最大的样本进行标记。
与ALR的三个标准相比,QBC只考虑了信息性,而没有考虑代表性和多样性。
C. Expected Model Change Maximization
期望模型变化最大化(EMCM)也是分类[9]、[32] - [34]、回归[7]、[8]和排序[12]中非常流行的AL方法。Cai等[8]提出了线性和非线性回归的EMCM方法。在本节中,我们介绍了他们的线性方法,因为本文只考虑线性回归。
EMCM首先使用所有 M 0 M_0 M0标记样本构建线性回归模型。设其对第 n n n个样本 x n x_n xn的预测为 y ^ n \hat{y}_n y^n .然后,与QBC一样,EMCM也使用bootstrap来构建P个线性回归模型。设第 p p p个模型对第 n n n个样本 x n x_n xn的预测为 y n p y^p_n ynp .然后,对于每个 N − M 0 N - M_0 N−M0无标签样本,计算
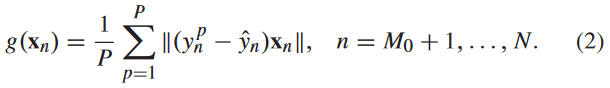
EMCM选择 g ( x n ) g(x_n) g(xn)最大的样本进行标记。
与ALR的三个标准相比,EMCM只考虑了信息性,而没有考虑代表性和多样性。
D. Greedy Sampling
Yu和Kim [41]提出了几种非常有趣的回归被动采样技术。与QBC和EMCM一样,他们并不是根据学习到的回归模型找到最有信息量的样本,而是根据样本在特征空间中的几何特征进行选择。被动采样的一个优点是不需要在每次迭代中更新回归模型和评估未标记样本,因此独立于回归模型。
本文采用贪婪抽样(GS)进行回归[41],该方法易于实现,在文献[41]中表现出良好的性能。它的基本思想是以贪婪的方式选择一个新的样本,使其远离先前选择的已标记样本。具体来说,对于 N − M 0 N - M_0 N−M0个未标记样本 { x n } n = M 0 + 1 N \{x_n\}^N_{n = M_0 + 1} {xn}n=M0+1N中的每一个,它计算它到每个M0标记样本的距离,即:
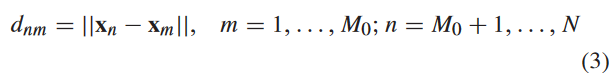
然后,计算 x n x_n xn到 M 0 M_0 M0个标记样本的最小距离 d n d_n dn,即
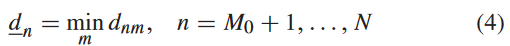
并选取 d n d_n dn最大的样本进行标注。
与ALR的三个标准相比,GS只考虑了多样性,而没有考虑信息性和代表性。
E. Enhanced Batch-Mode ALR
我们已经看到,上述三种ALR方法都只考虑了ALR的三个本质标准之一,因此存在改进的空间。此外,它们都假设我们已经有 M 0 M_0 M0个初始标记样本进行训练。通常情况下,这些 M 0 M_0 M0样本是随机选择的,因为当没有或很少有标记样本可用(因此, QBC和EMCM无法应用)时,回归模型在一开始就无法构建。然而,仍然可以有更好的初始化方法来选择更有代表性和多样性的幼苗样本,而不使用任何标签信息。EBMALR [40]是最近提出的一种同时考虑信息性、代表性和多样性来增强QBC和EMCM的方法。理论上,批处理模式的ALR也可以用于顺序ALR,通过将批大小设置为1。算法1展示了批量大小为1时的EBMALR算法。它首先使用k-means聚类初始化具有代表性和多样性的 d d d个样本,然后使用BL ALR方法,如QBC或EMCM,依次选择后续样本。
与QBC、EMCM和GS相比,EBMALR在初始化前 d d d个样本时识别异常值并排除其被选中,同时考虑了代表性和多样性( R D RD RD)。原始的EBMALR (当批次大于1时)在后续的每次迭代中同时考虑多样性和信息量,但是当批次大小变为1时,EBMALR不再能够考虑所选样本之间的多样性。因此,其性能显著下降,如第IV-E节所示。

F. Design of Experiments
试验设计(Design of Experiment,DOE)在统计学中得到了广泛的研究,并被应用于各个行业,用于探索新的过程和增加对现有过程的了解,然后优化这些过程,以达到世界一流的性能[2]。它的首要目标通常是从尽可能少的观测值中提取最大信息量,这与ALR非常相似。DOEs有两种典型的分类[2]。
- 筛选设计,即从众多潜在的琐碎因素中找出关键少数因素的较小实验。
- 最优设计,即考察项与非线性响应交互作用的更大试验,每个因素在两个以上水平上进行。
最优设计与ALR特别相关。它们为选择一组标签点,为特定的一组假设和目标提供了理论标准。与最优设计相比,ALR方法通常更具有启发性。在本文中,我们只考虑ALR方法。
III. OUR PROPOSED ALR APPROACHES
在本节中,我们首先提出一种基本的基于池的序贯ALR方法,同时考虑RD,然后将其与QBC、EMCM和GS集成以进一步提高性能。
A. Basic RD ALR Approach
假设初始池中的 N N N个样本都没有被标记。我们提出的基本 R D RD RD ALR方法由两部分组成:1) 通过考虑 R D RD RD来更好地初始化前几个样本;2) 在随后的每次迭代中也考虑 R D RD RD来生成新的样本。
由于输入空间有 d d d个维度,因此希望至少有 d d d个初始标记样本来构建合理的线性回归模型1。为了找到这些 d d d个样本的最优位置,我们对 N N N个未标记样本进行k-means ( k = d k = d k=d)聚类,然后从每个聚类中选择距离聚类中心最近的样本进行标记。这样的初始化保证了代表性,因为每个样本都是其所属聚类的良好代表。这也保证了多样性,因为这些 d d d簇覆盖了 x x x的全部输入空间。
ALR中使用聚类进行样本选择的思想是受到ALC中类似思想的启发。例如,Nguyen和Smeulders [28]使用k-medoids聚类来选择具有代表性和多样性的样本。Kang等[21]使用k-means聚类将未标记样本划分为不同的簇,然后从每个簇中选择最接近其质心的样本作为最具代表性的样本。Hu等[20]使用确定性聚类方法(最远优先遍历、凝聚层次聚类和近邻传播聚类)对样本进行初始化,避免了k-中心和k-means等非确定性聚类方法引入的变异。Krempl等[23]提出了一种基于聚类的在线流式ALC优化概率AL方法。然而,据我们所知,目前还没有任何基于池的序列ALR方法使用聚类来初始化样本并执行后续的选择。
在考虑 R D RD RD初始化前 d d d个样本后,我们启动迭代ALR过程,在每次迭代中选择一个新样本进行标记。考虑第1次迭代,此时已经有 d d d个标记样本,需要判断从 N − d N - d N−d个未标记样本中进一步选择哪个样本进行标记。在基本 R D RD RD算法中,我们首先对所有 N N N个样本进行 k − m e a n s k - means k−means聚类,其中 k = d + 1 k = d + 1 k=d+1。由于只有 d d d个标记样本,因此至少有一个聚类不包含任何标记样本。在实际应用中,某些聚类可能包含多个标记样本,因此通常不止一个聚类不包含任何标记样本。然后,我们将不包含任何已标记样本的最大簇识别为当前最具代表性的簇,并选择离其质心最近的样本进行标记。值得注意的是,这种选择策略也保证了多样性,因为识别出的簇与已经包含标记样本的所有其他簇的位置不同。然后重复这个过程,生成更多的标记样本,直到达到最大标记样本数量。
基本RD ALR方法的伪代码在算法2中给出,其中选项1被使用。与GS类似,基本RD方法也采用被动采样,不需要在每次迭代中更新回归模型和评估未标记样本。因此,它独立于回归模型。

B. Integrate RD With QBC, EMCM, and GS
有趣的是,基本的RD ALR方法可以很容易地与现有的基于池的序列ALR方法集成以获得更好的性能。伪码也显示在算法2中,其中选项2或3或4被使用。初始化与基本RD ALR方法相同。在每次迭代中,它还从最大的聚类中选择一个尚未包含已标记样本的样本进行标记。然而,与基本的RD ALR方法一样,它不是选择最接近其质心的样本,而是使用QBC或EMCM或GS来选择信息最丰富或最多样化的样本。我们预期,当使用QBC或EMCM时,集成RD ALR方法可以获得比基本RD ALR方法更好的性能,因为现在同时考虑了信息性、代表性和多样性。
C. Differences From EBMALR
我们提出的ALR方法与EBMALR [40]有一定的相似性,例如使用聚类来确保RD。然而,存在以下几个显著差异
-
本文考虑了基于池的序贯ALR,而[ 40 ]考虑了基于池的批模型ALR。理论上,序贯ALR可以看作是批次模型ALR的特例,当批次大小等于1时。然而,正如第II - E节所指出的,当批次大小变为1时,EBMALR不再能够考虑所选样本之间的多样性。因此,其性能明显劣于本文所提方法,如第IV - E节所示。
-
本文明确地将信息性、代表性和多样性定义为ALR应考虑的3个标准,而EBMALR没有(尽管它隐含地使用了这些概念)。
-
EBMALR还考虑了如何排除异常值被选中,但需要用户自定义参数。通过大量实验,我们发现该部分在大多数应用中并不关键,因此本文不将其包括在内。因此,我们的新算法不需要任何用户自定义的超参数,更易于使用。
-
在后续的每次迭代中,EBMALR (当批次规模大于1时)先考虑信息性再考虑多样性,而本文先考虑多样性再考虑信息性或代表性。实验表明,后者具有更好的性能。
-
本文针对ALR引入了GS方法(第Ⅱ- D节),同时也提出了新的RD方法(第三节- A),两者均未包含在文献[40]中。
-
本文比较了9种ALR方法在11个不同领域数据集上的性能,而文献[40]只比较了5种ALR方法在脑机接口应用中的性能。
V. CONCLUSION
在机器学习中,AL被频繁用于减少数据标注工作量。然而,现有的AL方法大多是针对分类的。本文对ALR进行了研究。我们提出了在基于池的序列ALR中选择新样本时需要考虑的三个重要标准,即信息性、代表性和多样性。提出了一种称为RD的ALR方法,该方法在初始化和后续迭代中都考虑RD。RD方法还可以与现有的基于池的序贯ALR方法,如QBC、EMCM、GS等进行集成,进一步提高性能。在来自不同领域的11个公共数据集上的大量实验证实了我们提出方法的有效性。
代码实现
import numpy as np
import pandas as pd
import xlwt
from pathlib import Path
from copy import deepcopyfrom collections import OrderedDict
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import accuracy_score,mean_absolute_error,f1_score,recall_score
from sklearn.cluster import KMeans
from time import time
from sklearn import datasets
import matplotlib.pyplot as pltclass ALRD():def __init__(self, X_pool, y_pool, labeled, budget, X_test, y_test):self.X_pool = X_poolself.y_pool = y_poolself.X_test = X_testself.y_test = y_testself.nSample, self.nAtt = self.X_pool.shapeself.labeled = list(deepcopy(labeled))self.unlabeled = self.init_unlabeled()self.labels = np.sort(np.unique(y_pool))self.nClass = len(self.labels)self.budgetLeft = deepcopy(budget)self.LATmodel = LogisticRegression()## ----------------## Evaluation criteriaself.AccList = []self.MAEList = []self.RecallList = []self.FscoreList = []self.ALC_ACC = 0self.ALC_MAE = 0self.ALC_F1 = 0self.ALC_Recall = 0def init_unlabeled(self):unlabeled = [i for i in range(self.nSample)]for idx in self.labeled:unlabeled.remove(idx)return unlabeleddef evaluation(self):self.LATmodel.fit(X=self.X_pool[self.labeled],y=self.y_pool[self.labeled])y_pred = self.LATmodel.predict(X=self.X_test)Acc = accuracy_score(y_pred=y_pred,y_true=self.y_test)MAE = mean_absolute_error(y_pred=y_pred,y_true=self.y_test)F1 = f1_score(y_pred=y_pred,y_true=self.y_test,average='macro')Recall = recall_score(y_pred=y_pred,y_true=self.y_test,average='macro')self.AccList.append(Acc)self.MAEList.append(MAE)self.FscoreList.append(F1)self.RecallList.append(Recall)self.ALC_ACC += Accself.ALC_MAE += MAEself.ALC_F1 += F1self.ALC_Recall += Recalldef select(self):while self.budgetLeft > 0:nCluster = len(self.labeled)+1y_pred = KMeans(n_clusters=nCluster).fit_predict(self.X_pool)cluster_labels, count = np.unique(y_pred,return_counts=True)cluster_dict = OrderedDict()for i in cluster_labels:cluster_dict[i] = []for idx in self.labeled:cluster_dict[y_pred[idx]].append(idx)empty_ids = OrderedDict()for i in cluster_labels:if len(cluster_dict[i]) == 0:empty_ids[i] = count[i]tar_label = max(empty_ids,key=empty_ids.get)tar_cluster_ids = []for idx in range(self.nSample):if y_pred[idx] == tar_label:tar_cluster_ids.append(idx)centroid = np.mean(self.X_pool[tar_cluster_ids],axis=0)tar_idx = Noneclose_dist = np.inffor idx in tar_cluster_ids:if np.linalg.norm(self.X_pool[idx] - centroid) < close_dist:close_dist = np.linalg.norm(self.X_pool[idx] - centroid)tar_idx = idxself.labeled.append(tar_idx)self.unlabeled.remove(tar_idx)self.budgetLeft -= 1if __name__ == '__main__':add = [0, 6, 12, 19]data = Nonefor i in range(4):X, yy = datasets.make_blobs(n_samples=200, n_features=2, center_box=(0, 0), cluster_std=3, random_state=45)X += add[i]if i == 0:data = Xelse:data = np.vstack((data, X))y = np.ones(800)y[:200] = 0y[200:400] = 1y[400:600] = 2y[600:800] = 3X = datalabeled = [6, 206, 406, 606]budget = 40model = ALRD(X_pool=X,y_pool=y,labeled=labeled,budget=budget,X_test=X,y_test=y)model.select()plt.scatter(X[:,0],X[:,1],c=y)plt.scatter(X[model.labeled][:, 0], X[model.labeled][:, 1], c=y[model.labeled],edgecolors='r',linewidths=1)plt.show()
sklearn.datasets 中的 make_blobs 函数
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)
参数
- n_samples: int或数组类,可选参数(默认值= 100)如果为int,则为在簇之间平均分配的点总数。 如果是数组,则序列中的每个元素表示每个簇的样本数。
- n_features: int,可选(默认值= 2)每个样本的特征数量。
- centers: int或形状数组
[n_centers,n_features],可选(默认= None)要生成的中心数或固定的中心位置。 如果n_samples是一个int且center为None,则将生成3个中心。 如果n_samples是数组类,则中心必须为None或长度等于n_samples长度的数组。 - cluster_std: 浮点数或浮点数序列,可选(默认值为1.0)聚类的标准偏差。
- center_box: 一对浮点数(最小,最大),可选(默认=(-10.0,10.0))随机生成中心时每个聚类中心的边界框。
- shuffle: 布尔值,可选(默认= True)样本洗牌
- random_state: int,RandomState实例或无(默认)确定用于创建数据集的随机数生成。 为多个函数调用传递可重复输出的int值。
示例
# make_blobs示例
from matplotlib import pyplot as plt
from sklearn.datasets import make_blobsX, y = make_blobs(n_samples=10, centers=3, n_features=2, random_state=0)# 看看数据集长什么样
plt.scatter(X[:, 0], X[:, 1], c=y, cmap="rainbow")
plt.show()
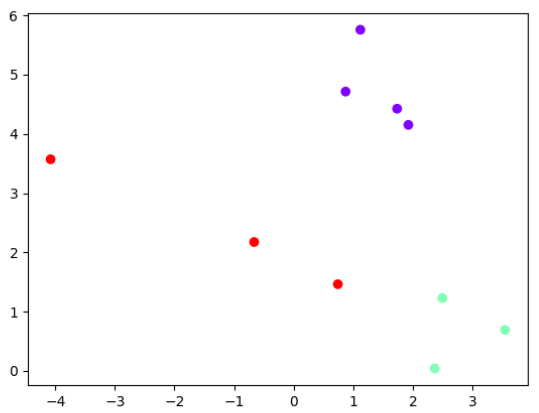
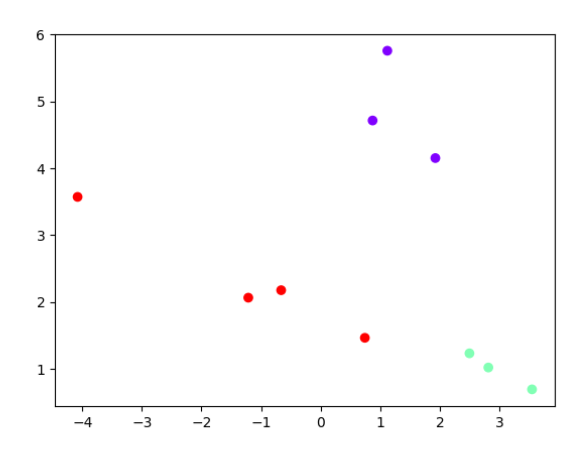
# make_blobs示例
from matplotlib import pyplot as plt
from sklearn.datasets import make_blobsX, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2, random_state=0)plt.scatter(X[:, 0], X[:, 1], c=y, cmap="rainbow")
plt.show()
OrderedDict
1、定义
python中字典Dict是利用hash存储,因此各元素之间没有顺序。OrderedDict听名字就知道他是 按照有序插入顺序存储 的有序字典。 除此之外还可根据key, val进行排序。
2、初始化
2.1 先初始化定义一个OrderedDict,然后按照键值对插入,此时dict可以记录插入字典的顺序
import collections
d = collections.OrderedDict()
d["name"] = "muya"
d["age"] = 25
d["money"] = "Zero"for key, value in d.items():print(key, value)# 输出:
# name muya
# age 25
# money Zero
2.2 在定义时初始化好键值对,之后再对该字典进行插入的键值仍然是有序的。
import collectionsd = collections.OrderedDict(name="muya", age=25, money="Zero")
d["dream"] = "have money"
d["other dream"] = "have gf"for key, value in d.items():print(key, value)
References
[1] python OrderedDict函数详细介绍
References
[1] 论文复现:Pool-Based Sequential Active Learning for Regression
Wu D. Pool-based sequential active learning for regression[J]. IEEE transactions on neural networks and learning systems, 2018, 30(5): 1348-1359.
算法原理
ALR 评价指标
- 信息性 Informativeness:样本附带的信息是否充足,可以借助信息熵、MSE、委员会之间的不同差异
- 代表性 Representativeness:并不是噪声,而是模型真正需要的数据
- 多样性 Diversity:样本分散在输入空间,而不是局部
本文的调研算法
Query-by-Committee
多个模型对数据集进行预测,通过不同模型预测的差异来选择,可以利用 Bootstrap 来抽样选取不同的样本,从而产生多个模型,实际上只是模型参数的变化
与ALR的三个标准相比,QBC只考虑了信息性,而没有考虑代表性和多样性。
Expected Model Change Maximization
EMCM首先使用所有 M 0 M_0 M0标记样本构建线性回归模型。设其对第 n n n个样本 x n x_n xn的预测为 y ^ n \hat{y}_n y^n .然后,与QBC一样,EMCM也使用Bootstrap来构建P个线性回归模型。设第 p p p个模型对第 n n n个样本 x n x_n xn的预测为 y n p y^p_n ynp .然后,对于每个 N − M 0 N - M_0 N−M0无标签样本,计算
EMCM选择 g ( x n ) g(x_n) g(xn)最大的样本进行标记。
与ALR的三个标准相比,EMCM只考虑了信息性,而没有考虑代表性和多样性。
- Bootstrap 详细介绍
Greedy Sampling
基本思想是以贪婪的方式选择一个新的样本,使其远离先前选择的已标记样本。具体来说,对于 N − M 0 N - M_0 N−M0个未标记样本 { x n } n = M 0 + 1 N \{x_n\}^N_{n = M_0 + 1} {xn}n=M0+1N中的每一个,它计算它到每个M0标记样本的距离,即:
然后,计算 x n x_n xn到 M 0 M_0 M0个标记样本的最小距离 d n d_n dn,即
并选取 d n d_n dn最大的样本进行标注。
与ALR的三个标准相比,GS只考虑了多样性,而没有考虑信息性和代表性。
Enhanced Batch-Mode ALR
通常情况下,这些 M 0 M_0 M0样本是随机选择的,因为当没有或很少有标记样本可用(QBC和EMCM无法应用)时,回归模型在一开始就无法构建。然而,仍然可以有更好的初始化方法来选择更有代表性和多样性的幼苗样本,而不使用任何标签信息。EBMALR [40]是最近提出的一种同时考虑信息性、代表性和多样性来增强QBC和EMCM的方法。它首先使用k-means聚类初始化具有代表性和多样性的 d d d个样本,然后使用BL ALR方法,如QBC或EMCM,依次选择后续样本。
与QBC、EMCM和GS相比,EBMALR在初始化前 d d d个样本时识别异常值并排除其被选中,同时考虑了代表性和多样性( R D RD RD)。原始的EBMALR (当批次大于1时)在后续的每次迭代中同时考虑多样性和信息量,但是当批次大小变为1时,EBMALR不再能够考虑所选样本之间的多样性。因此,其性能显著下降,如第IV-E节所示。
本文提出的方法
Basic RD ALR Approach
基本思想为:初始时,有 d d d个标记样本,需要判断从 N − d N - d N−d个未标记样本中进一步选择哪个样本进行标记。在基本 R D RD RD算法中,首先对所有 N N N个样本进行 k − m e a n s k - means k−means聚类,其中 k = d + 1 k = d + 1 k=d+1。由于只有 d d d个标记样本,因此至少有一个聚类不包含任何标记样本。在实际应用中,某些聚类可能包含多个标记样本,因此通常不止一个聚类不包含任何标记样本。然后,我们将不包含任何已标记样本的最大簇识别为当前最具代表性的簇,并选择离其质心最近的样本进行标记。值得注意的是,这种选择策略也保证了多样性,因为识别出的簇与已经包含标记样本的所有其他簇的位置不同。然后重复这个过程,生成更多的标记样本,直到达到最大标记样本数量。
基本RD ALR方法的伪代码在算法2中给出,其中选项1被使用。与GS类似,基本RD方法也采用被动采样,不需要在每次迭代中更新回归模型和评估未标记样本。因此,它独立于回归模型。
Integrate RD With QBC, EMCM, and GS
有趣的是,基本的RD ALR方法可以很容易地与现有的基于池的序列ALR方法集成以获得更好的性能。伪码也显示在算法2中,其中选项2或3或4被使用。初始化与基本RD ALR方法相同。在每次迭代中,它还从最大的聚类中选择一个尚未包含已标记样本的样本进行标记。然而,与基本的RD ALR方法一样,它不是选择最接近其质心的样本,而是使用QBC或EMCM或GS来选择信息最丰富或最多样化的样本。我们预期,当使用QBC或EMCM时,集成RD ALR方法可以获得比基本RD ALR方法更好的性能,因为现在同时考虑了信息性、代表性和多样性。
Differences From EBMALR
我们提出的ALR方法与EBMALR [40]有一定的相似性,例如使用聚类来确保RD。然而,存在以下几个显著差异
-
本文考虑了基于池的序贯ALR,而[40]考虑了基于池的批模型ALR。理论上,序贯ALR可以看作是批次模型ALR的特例,当批次大小等于1时。然而,正如第II-E节所指出的,当批次大小变为1时,EBMALR不再能够考虑所选样本之间的多样性。因此,其性能明显劣于本文所提方法,如第IV - E节所示。
-
本文明确地将信息性、代表性和多样性定义为ALR应考虑的3个标准,而EBMALR没有(尽管它隐含地使用了这些概念)。
-
EBMALR还考虑了如何排除异常值被选中,但需要用户自定义参数。通过大量实验,我们发现该部分在大多数应用中并不关键,因此本文不将其包括在内。因此,我们的新算法不需要任何用户自定义的超参数,更易于使用。
-
在后续的每次迭代中,EBMALR (当批次规模大于1时)先考虑信息性再考虑多样性,而本文先考虑多样性再考虑信息性或代表性。实验表明,后者具有更好的性能。
-
本文针对ALR引入了GS方法(第Ⅱ-D节),同时也提出了新的RD方法(第三节-A),两者均未包含在文献[40]中。
-
本文比较了9种ALR方法在11个不同领域数据集上的性能,而文献[40]只比较了5种ALR方法在脑机接口应用中的性能。
代码实现
#!/usr/bin/python
# -*- coding:utf-8 -*-
# @author : 青年有志
# @time : 2023-05-19 19:28
# @function: Pool-based sequential active learning for regression
# @version : V1import sysimport numpy as np
import pandas as pd
import xlwt
from pathlib import Path
from copy import deepcopyfrom collections import OrderedDict
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import accuracy_score, mean_absolute_error, f1_score, \recall_score, mean_squared_error, r2_score
from sklearn.cluster import KMeans
from time import time
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.utils import check_random_state
from sklearn.ensemble import AdaBoostRegressorclass ALRD():def __init__(self, X_pool, y_pool, labeled, budget, X_test, y_test):self.X_pool = X_pool # 所有数据self.y_pool = y_pool # 所有的样本标签self.X_test = X_test # 测试数据self.y_test = y_test # 测试集标签self.nSample, self.nAtt = self.X_pool.shape # 样本数量和特征数量self.labeled = list(deepcopy(labeled)) # 已经标记的数据索引# self.labels = np.array([i for i in range(self.nAtt)]) # 初始聚类的簇编号集合,大小等于其特征数量self.labels = np.array([i for i in range(1)]) # 初始聚类的簇编号集合,大小等于其特征数量self.unlabeled = self.init_unlabeled() # 所有未标记的数据索引self.nClass = len(self.labels) # 聚类的簇大小self.budgetLeft = deepcopy(budget) # 待选择的样本self.model = AdaBoostRegressor() # 模型def init_unlabeled(self):unlabeled = [i for i in range(self.nSample)] # 遍历所有样本for idx in self.labeled:unlabeled.remove(idx) # 去掉已经标记的样本return unlabeleddef evaluation(self):"""使用 K 折交叉验证,K 中的验证集作为测试集,取平均作为泛化误差:return:"""X_train = self.X_pool[self.labeled]y_train = self.y_pool[self.labeled]# 在所有数据集上进行 K 折,将验证集作为测试集AL_Train_scores = []AL_Test_scores = []AL_R2_scores = []kfold = KFold(n_splits=10, shuffle=True).split(X_train, y_train)for k, (train, test) in enumerate(kfold):self.model.fit(X_train[train], y_train[train])AL_Train_score = mean_squared_error(self.model.predict(X_train[train]), y_train[train])AL_Test_score = mean_squared_error(self.model.predict(X_train[test]),y_train[test])AL_R2_score = r2_score(self.model.predict(X_train[test]), y_train[test])AL_Train_scores.append(AL_Train_score)AL_Test_scores.append(AL_Test_score)AL_R2_scores.append(AL_R2_score)# print('Fold: %2d, score: %.3f' % (k + 1, score))AL_Train_MSE = np.mean(AL_Train_scores)AL_Test_MSE = np.mean(AL_Test_scores)AL_R2 = np.mean(AL_R2_scores)# print('训练集 MAE:', AL_Train_MSE, '测试集 MAE:', AL_Test_MSE)return AL_Train_MSE, AL_Test_MSE, AL_R2def select(self):while self.budgetLeft > 0:nCluster = len(self.labeled) + 1y_pred = KMeans(n_clusters=nCluster).fit_predict(self.X_pool) # 聚类操作,类的大小为初始样本数 + 1cluster_labels, count = np.unique(y_pred, return_counts=True)cluster_dict = OrderedDict() # 定义有序字典# 初始化每个簇对应一个集合for i in cluster_labels: # 遍历簇,形成一个集合cluster_dict[i] = [] # 每个簇用预测结果 i 代表# 先将已经标记的样本加入到对应的簇中for idx in self.labeled:cluster_dict[y_pred[idx]].append(idx) # 将已经标记好的样本添加进入empty_ids = OrderedDict() # 定义一个空字典for i in cluster_labels: # 遍历簇中心if len(cluster_dict[i]) == 0: # 判断此时簇是否为空,如果含有标记样本则为空,没有标记样本则不为空empty_ids[i] = count[i] # 记录空簇的未标记样本的数量# 在所有没有任何提前标记的样本的簇中,即 empty_ids 中,选择簇包含样本数量最大的对应的簇编号tar_label = max(empty_ids, key=empty_ids.get) #tar_cluster_ids = [] # 存储 tar_label 簇中的样本索引# 将在 tar_label 簇中的样本加入到集合 tar_cluster_ids 中for idx in range(self.nSample): # 遍历样本数量if y_pred[idx] == tar_label: # 判断样本是否在 tar_label 中tar_cluster_ids.append(idx)centroid = np.mean(self.X_pool[tar_cluster_ids], axis=0) # 计算 tar_cluster_ids 的中心位置tar_idx = Noneclose_dist = np.inf# 计算 tar_cluster_ids 中,所有样本到簇中心的距离,选择距离最近的一个样本for idx in tar_cluster_ids:if np.linalg.norm(self.X_pool[idx] - centroid) < close_dist:close_dist = np.linalg.norm(self.X_pool[idx] - centroid)tar_idx = idx# 将选出的样本进行标记self.labeled.append(tar_idx)self.unlabeled.remove(tar_idx)self.budgetLeft -= 1if __name__ == '__main__':rng = check_random_state(0) # 设计随机数种子,利用 rng.uniform 产生可复现的数据X_train = rng.uniform(-1, 1, 1000).reshape(500, 2)y_train = X_train[:, 0] ** 2 - X_train[:, 1] ** 2 + X_train[:, 1] - 1labeled = [206, 406] # 未标记的数据索引budget = 40# budget 需要标记的样本个数model = ALRD(X_pool=X_train, y_pool=y_train, labeled=labeled, budget=budget, X_test=0,y_test=0)model.select()这篇关于2018,Pool-Based Sequential Active Learning for Regression的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)




