本文主要是介绍【大模型上下文长度扩展】位置内插 PI:基于Positional Interpolation扩大模型的上下文窗口,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
位置内插 PI:基于Positional Interpolation扩大模型的上下文窗口
- 如何在不牺牲性能或从头训练的情况下,扩展大型语言模型的上下文窗口以处理长文档或长对话?
论文:https://arxiv.org/pdf/2306.15595.pdf
这篇论文介绍了一种名为位置插值(Position Interpolation, PI)的方法。
旨在扩展基于 RoPE 的预训练大型语言模型的上下文窗口大小,解决的核心问题是如何有效且高效地扩展模型的上下文理解能力,以便处理需要长上下文的任务。
比如长文档摘要、语言建模等,而不需要从头开始训练模型以支持更大的上下文窗口,这在资源和时间上都是非常昂贵的。
如何在不牺牲性能或从头训练的情况下,扩展大型语言模型的上下文窗口以处理长文档或长对话?
流程顺序:
-
子问题:需要扩展模型上下文窗口的动机是什么?
- 解法:识别长上下文任务的需求 - 如长文档摘要、语言建模等。
- 例子:想象一篇科学论文的长篇摘要,这需要模型理解并生成超出其预训练上下文限制的内容。
-
子问题:直接外推位置编码在长上下文任务中存在哪些问题?
- 解法:分析外推的局限性 - 直接外推导致性能不稳定。
- 例子:在尝试生成论文的摘要时,直接外推位置编码会导致注意力分数异常升高,从而无法生成连贯的文本。
-
子问题:如何在不重新训练模型的情况下有效地扩展上下文窗口?
- 解法:位置插值(PI)方法 - 通过线性下调位置索引,而不是外推。
- 例子:采用PI,模型可以将原本的[0, 4096]位置范围内的位置信息“压缩”到[0, 2048]内,使得模型可以处理更长的文本,就像处理2048个令牌一样有效。
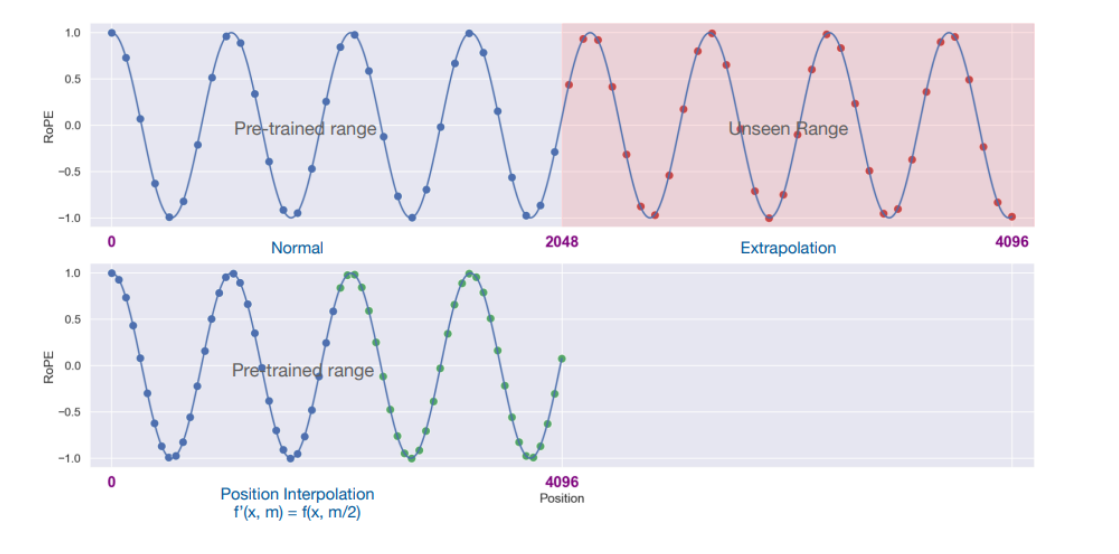
预训练的Llama模型在处理2048个上下文窗口长度时的旋转位置嵌入(RoPE)的正常使用情况。
蓝色点表示预训练范围内的位置索引,而红色点表示在4096范围内未见过的位置索引(超出预训练范围的位置)。
下方展示了位置插值的结果,其中位置索引被缩小了一半(f(x, m) = f(x, m/2)),即将原本的[0, 4096]范围的位置索引映射到[0, 2048]范围内,以适应模型的预训练范围。
这张图说明了位置插值如何通过对输入位置的缩放,使得模型能够处理超出其原始训练范围的输入,而不需要对模型架构进行改动,只通过重新调整位置索引来达成。
如果原始上下文窗口是2048,目标窗口是4096,那么所有位置索引都会被除以2。
位置2048在位置插值后会被处理为1024(即 2048 / 2 = 1024)。
这样处理之后,新的序列的每个位置(不论是原始的还是新增的)都有了一个唯一的、缩放后的位置索引。
一些位置编码方法,如三角函数位置编码或一些变体的旋转位置编码(RoPE),可以在非整数(除以二后变成小数)位置上计算。
这些方法可以将连续的位置信息映射到高维空间,以保持位置的相对关系,即使这些位置是通过插值得到的。
在位置插值中,我们不会直接在位置索引中引入小数点,而是通过调整位置编码函数来处理可能出现的小数位置,以便模型可以连续地处理位置信息,从而适应更长的输入序列。
在新的上下文窗口大小上对模型进行微调,以帮助模型适应位置插值所带来的变化。微调通常是在一个大型的文本语料库上进行,例如Pile数据集。
-
子问题:位置插值方法的效率和有效性如何验证?
- 解法:经验验证和微调成本分析 - 使用少量的微调步骤。
- 选择一个大型的文本数据集,如Pile数据集,用于微调模型。
- 例子:LLaMA 7B模型使用PI扩展到32768上下文窗口后,在Pile数据集上仅需1000步微调,就能显著改善性能。
-
子问题:位置插值扩展后的模型在原始上下文窗口大小的基准任务上表现如何?
- 解法:在原始上下文窗口大小进行基准评估 - 对比原始模型和扩展模型的性能。
- 例子:经过PI扩展到8192的模型,在2048的原始上下文窗口的基准任务上只表现出最多2%的性能下降。
-
子问题:扩展后的模型在实际上下文中的有效性如何衡量?
- 解法:通过通行密钥检索任务测试有效上下文窗口 - 检查模型是否能够恢复长文档中的隐含信息。
- 例子:经过PI的模型能够在一篇长文档中成功恢复隐藏的随机通行密钥,表明其有效上下文窗口至少与通行密钥所在位置一致。
通过位置插值方法,可以有效地扩展预训练模型的上下文窗口,而无需进行资源密集型的重新训练。
通过微调来进一步优化模型,使其在长文档摘要等任务中具备更强的性能,即使在超出原始训练限制的上下文中也能保持稳定性和效率。
这篇关于【大模型上下文长度扩展】位置内插 PI:基于Positional Interpolation扩大模型的上下文窗口的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






