本文主要是介绍模型压缩开源项目:阿里-tinyNAS/微软NNI/华为-vega,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 阿里-TinyNAS
- 使用流程
- 步骤一:搜索模型结构
- 步骤二:导出模型结果
- 步骤三:使用搜索的模型结构
- 图像分类任务
- 目标检测任务
- 华为-vega
- 简介
- 定位
- 优点
- 缺点
- 微软NNI
- 简介
- 定位
- 优点
- 缺点
阿里-TinyNAS
https://github.com/alibaba/lightweight-neural-architecture-search
- 聚焦NAS,进行合理的模块划分;
- 更偏向算法使用平台,搜索得到精度较好的模型结构,通过该项目得到damoyolo 的
backbone结构;
使用流程
步骤一:搜索模型结构
python tools/search.py configs/classification/R50_FLOPs.py
configs/classification/R50_FLOPs.py
# Copyright (c) Alibaba, Inc. and its affiliates.
# The implementation is also open-sourced by the authors, and available at
# https://github.com/alibaba/lightweight-neural-architecture-search.work_dir = './save_model/R50_R224_FLOPs41e8/'
log_level = 'INFO' # INFO/DEBUG/ERROR
log_freq = 1000""" image config """
image_size = 224 # 224 for Imagenet, 480 for detection, 160 for mcu""" Model config """
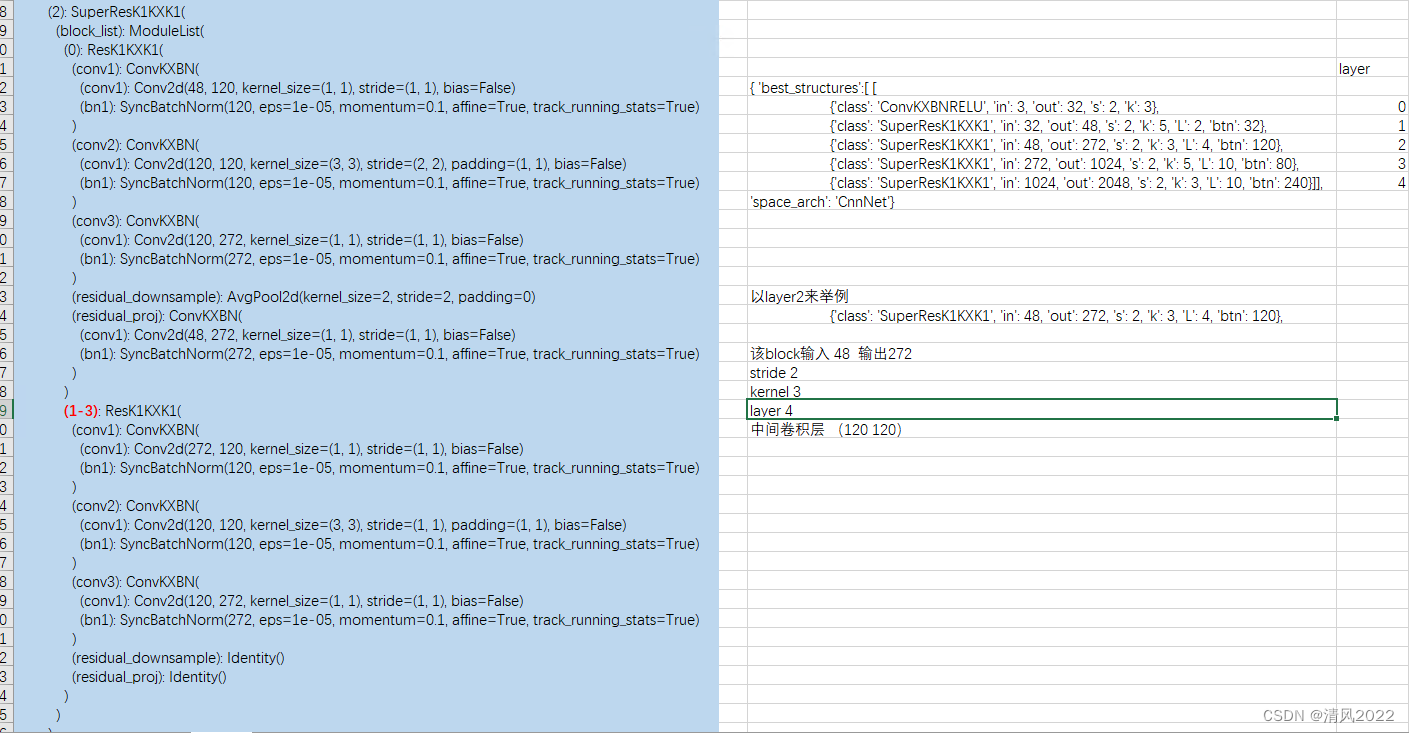
model = dict(type = 'CnnNet',structure_info = [ {'class': 'ConvKXBNRELU', 'in': 3, 'out': 32, 's': 2, 'k': 3}, \{'class': 'SuperResK1KXK1', 'in': 32, 'out': 256, 's': 2, 'k': 3, 'L': 1, 'btn': 64}, \{'class': 'SuperResK1KXK1', 'in': 256, 'out': 512, 's': 2, 'k': 3, 'L': 1, 'btn': 128}, \{'class': 'SuperResK1KXK1', 'in': 512, 'out': 768, 's': 2, 'k': 3, 'L': 1, 'btn': 256}, \{'class': 'SuperResK1KXK1', 'in': 768, 'out': 1024, 's': 1, 'k': 3, 'L': 1, 'btn': 256}, \{'class': 'SuperResK1KXK1', 'in': 1024, 'out': 2048, 's': 2, 'k': 3, 'L': 1, 'btn': 512}, \]
)""" Budget config """
budgets = [dict(type = "flops", budget = 41e8),dict(type = "layers",budget = 49),dict(type = "model_size", budget = 25.55e6)]""" Score config """
score = dict(type = 'madnas', multi_block_ratio = [0,0,0,0,1])""" Space config """
space = dict(type = 'space_k1kxk1',image_size = image_size,)""" Search config """
search=dict(minor_mutation = False, # whether fix the stage layerminor_iter = 100000, # which iteration to enable minor_mutationpopu_size = 256,num_random_nets = 100000, # the searching iterationssync_size_ratio = 1.0, # control each thread sync number: ratio * popu_sizenum_network = 1,
)
界面显示如下

输出文件如下
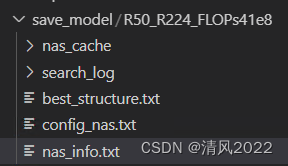
- nas_cache:nas过程的缓存数据;
- search_log: nas过程日志保存;
- best_structure.json:在搜索过程中找到的几个最佳模型架构;
- config_nas.txt: nas的config信息
- nas_info.txt:nas网络结构的其他信息。包括 layers,acc,flops,model_size,score
步骤二:导出模型结果
python tools/export.py save_model/R50_R224_FLOPs41e8 output_dir
将demo 中的相关代码拷贝至output_dir/R50_R224_FLOPs41e8/目录中
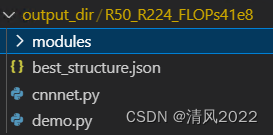
包含以下几部分:
best_structure.json:在搜索过程中找到的几个最佳模型架构;demo.py:一个简单的示例说明如何使用模型, 可通过如下命令行运行示例
python demo.py --structure_txt best_structure.json
cnnnet.py:用于构建模型的类定义和使用函数;modules: 模型的基本模块;weights/:在搜索过程中找到的几个最优模型权重(仅适用于one-shot NAS方法).
说明:modules,cnnnet.py,demo.py 是从目录tinynas/deploy中拷贝过来的:

步骤三:使用搜索的模型结构
图像分类任务
图像分类任务中可以直接运行
- demo.py 就是一个使用的示例,可在上述步骤后直接运行demo.py.
- 继续以resnet-50结构在分类任务上为例,核心代码如下
目标检测任务
在该nas项目中模型结构搜索仅限于backbone,而一般的图像检测任务 由backbone+neck+head 三部分组成
目标检测器主要由4部分组成:
Input、Backbone(提取特征训练)、Neck(整合收集特征)、Head(目标检测)。
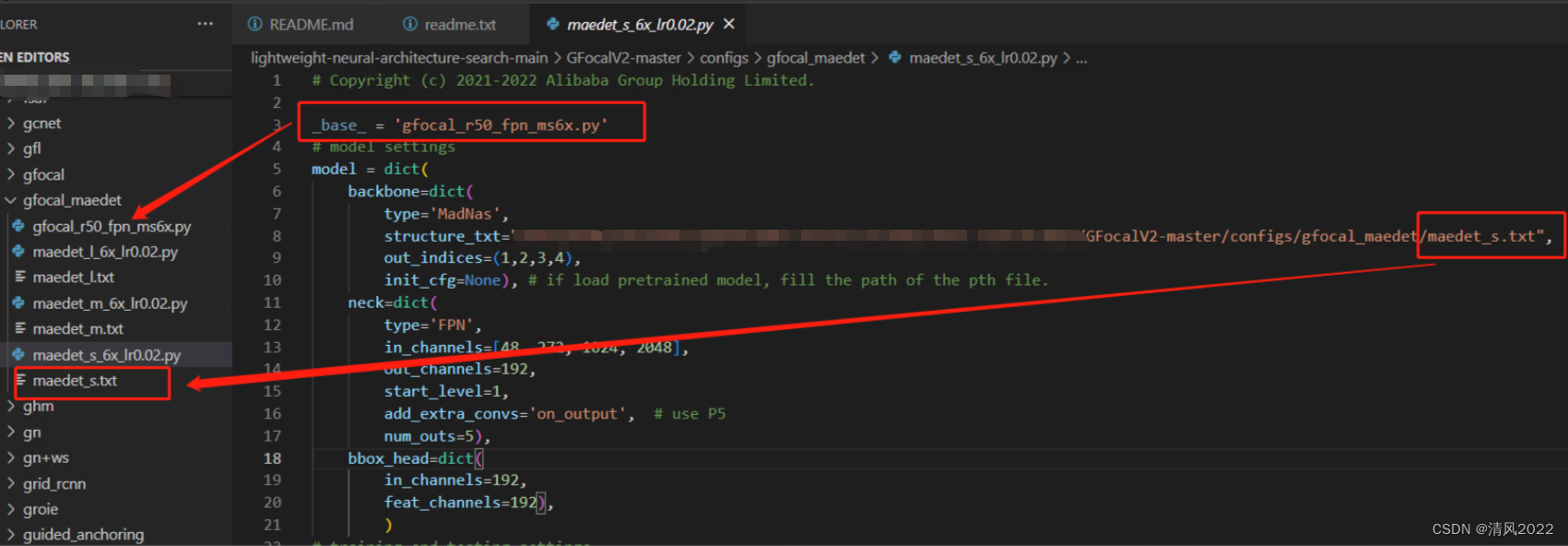
因此使用TinyNAS 检索出backbone后,需要对接项目GFocalV2构造整个模型
其中neck采用的是FPN(Feature Pyramid Network),head采用的是GFL(GFocalHead)
使用步骤参见 readme.txt
MAE-DET-S uses 60% less FLOPs than ResNet-50;
MAE-DET-M is alignedwith ResNet-50 with similar FLOPs and number of parameters as ResNet-50;
MAE-DET-L is aligned with ResNet-101.
华为-vega
简介
Vega是诺亚方舟实验室自研的AutoML算法工具链,有主要特点:
- 完备的
AutoML能力:涵盖HPO(超参优化, HyperParameter Optimization)、Data-Augmentation、NAS(网络架构搜索, Network Architecture Search)、Model Compression、Fully Train等关键功能,同时这些功能自身都是高度解耦的,可以根据需要进行配置,构造完整的pipeline。 - 业界标杆的自研算法:提供了诺亚方舟实验室自研的 业界标杆(Benchmark) 算法,并提供 Model Zoo 下载SOTA(State-of-the-art)模型。
- 高并发模型训练能力:提供高性能Trainer,加速模型训练和评估。
- 细粒度
SearchSpace:可以自由定义网络搜索空间,提供了丰富的网络架构参数供搜索空间使用,可同时搜索网络架构参数和模型训练超参,并且该搜索空间可以同时适用于Pytorch、TensorFlow和MindSpore。 - 多Backend支持:支持PyTorch(GPU, Ascend 910), TensorFlow(GPU, Ascend 910), MindSpore(Ascend 910).。
- 支持昇腾平台:支持在Ascend 910搜索和训练,支持在Ascend 310上模型评估。
定位
自动机器学习,基于硬件的算法工具链
优点
-
文档完善
-
提供pipline流程,更加贴近业务,实现端到端的AutoML流程,输入数据,即可得到所需的模型,使用上有一定的门槛
-
场景覆盖全面

-
提供端侧模型评估
缺点
-
已有一年不再更新
![[图片]](https://img-blog.csdnimg.cn/direct/076daaf8abc94496aaf89f7df711f596.png)
-
NAS相关的算法
配置文件示例
general:backend: pytorch # pytorch# 定义pipeline。
# pipeline: [my_nas, my_hpo, my_data_augmentation, my_fully_train]
pipeline: [nas, fully_train]nas:pipe_step:type: SearchPipeStepdataset:type: Cifar10common:data_path: /cache/datasets/cifar10/train_portion: 0.5num_workers: 8drop_last: Falsetrain:shuffle: Truebatch_size: 128val:batch_size: 3500search_algorithm:type: CARSAlgorithmpolicy:num_individual: 8start_ga_epoch: 50ga_interval: 10select_method: uniformwarmup: 50search_space:type: SearchSpacemodules: ['super_network']super_network:type: CARSDartsNetworkstem:type: PreOneSteminit_channels: 16stem_multi: 3head:type: LinearClassificationHeadinit_channels: 16num_classes: 10auxiliary: Falsesearch: Truecells:modules: ['normal', 'normal', 'reduce','normal', 'normal', 'reduce','normal', 'normal']normal:type: NormalCellsteps: 4genotype:[[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 2, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 2, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 3, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 3, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 3, 2 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 2 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 3 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 2 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 3 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 4 ],]concat: [2, 3, 4, 5]reduce:type: ReduceCellsteps: 4genotype:[[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 2, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 2, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 3, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 3, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 3, 2 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 2 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 4, 3 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 0 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 1 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 2 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 3 ],[ ['none', 'max_pool_3x3', 'avg_pool_3x3', 'skip_connect', 'sep_conv_3x3', 'sep_conv_5x5', 'dil_conv_3x3', 'dil_conv_5x5'], 5, 4 ],]concat: [2, 3, 4, 5]trainer:type: Trainerdarts_template_file: "{default_darts_cifar10_template}"callbacks: CARSTrainerCallbackepochs: 500optimizer:type: SGDparams:lr: 0.025momentum: 0.9weight_decay: !!float 3e-4lr_scheduler:type: CosineAnnealingLRparams:T_max: 500eta_min: 0.001grad_clip: 5.0seed: 10unrolled: Trueloss:type: CrossEntropyLossfully_train:pipe_step:type: TrainPipeStepmodels_folder: "{local_base_path}/output/nas/"trainer:ref: nas.trainerepochs: 600lr_scheduler:type: CosineAnnealingLRparams:T_max: 600.0eta_min: 0loss:type: MixAuxiliaryLossparams:loss_base:type: CrossEntropyLossaux_weight: 0.4seed: 100drop_path_prob: 0.2evaluator:type: Evaluatorhost_evaluator:type: HostEvaluatormetric:type: accuracydataset:ref: nas.datasetcommon:train_portion: 1.0train:batch_size: 96shuffle: Truetransforms:- type: RandomCropsize: 32padding: 4- type: RandomHorizontalFlip- type: ToTensor- type: Normalizemean:- 0.49139968- 0.48215827- 0.44653124std:- 0.24703233- 0.24348505- 0.26158768- type: Cutoutlength: 8 # pipeline scale this number to 8*20/10val:batch_size: 96shuffle: False
微软NNI
简介
NNI (Neural Network Intelligence) 是一个轻量而强大的工具,可以帮助用户 自动化:
- 超参调优
- 架构搜索
- 模型压缩
- 特征工程
定位
大而全面的工具
优点
- 模块之间高度解耦,更加灵活
- 项目完整,包含剪枝 NAS 量化,提供能可视化界面
缺点
NAS方法,需要设置搜索范围,对用户要求高
![[图片]](https://img-blog.csdnimg.cn/direct/84a6f122b6bf484a82385f3edc1cf954.png)
这篇关于模型压缩开源项目:阿里-tinyNAS/微软NNI/华为-vega的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








