本文主要是介绍BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用于长尾视觉识别的带累积学习的双边分支网络
长尾问题:少数类样本数量大,而多数类的样本很小,是一种数据分布不平衡的问题。
传统解决方法:重加权和重采样,这些方法统称为重平衡方法。之所以可以取得较好的精确度,是因为它能显著的促进深度网络的分类器学习,但同时它又会一定程度上损害已学习的深层特征的表征能力。
双边分支网络:提出的新方法。用于兼顾表征学习和分类器学习。 并通过实验证明了该方法的有效性。
结构

- 设计了表征学习和分类器学习两个分支,分别称为常规学习分支和再平衡分支
- 两个分支使用相同的残差网络结构,共享除最后一个残差块之外的所有权值
- 分别使用均匀采样器和反向采样器
累积学习策略: 用于在训练阶段在两个分支间转移注意力。通过自适应权衡参数控制两个分支的权值,将加权后的特征向量分别送入两个分支对应的分类器中。
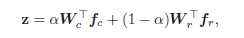
带权交叉熵分类损失:
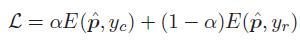
注:
传统学习分支:输入数据来自均匀采样器,训练样本在每个epoch中以等概率采样一次。其保留了原始分布的特征,因此有利于表征学习;重平衡分支的输入数据来自反向采样器,缓解了极端不平衡问题,提高了尾部类的分类精度。反向——每个类的采样可能性与其样本量的倒数成正比。
双边分支:数据采样与权值共享。其中权值共享好处有:传统学习分支的良好学习有利于再平衡分支的学习,共享权值将大大降低推理阶段的计算复杂度。
累积学习:

分子代表当前当前epoch,分母代表总的训练epoch。累积学习策略是先学习通用模式,然后逐渐关注尾部数据。
这篇关于BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







