本文主要是介绍Quo Vadis_Is Trajectory Forecasting the Key 论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
主要解决长期跟踪问题
研究动机:在更长的时间范围内对未来轨迹进行推理
Introduction
首先说明,目前方法已经在短期预测、可见物体跟踪方向上取得成功。
用数据+图说明,长遮挡时,跟踪成功率(ID recall率)显著降低(问题引入)
(读一下这篇引用 Donald B Reid. An algorithm for tracking multiple targets. In Transactions on Automatic Control, 1979)
“This combinatorial complexity hinders the ability of visual-based ReID models to disambiguate between objects.” (“Quo Vadis_Is Trajectory Forecasting the Key”, p. 1) 这种组合复杂性阻碍了基于视觉的ReID模型对对象间进行消歧的能力。
为什么REID不能处理这种问题?
将轨迹预测应用于多目标跟踪并不简单,因为在图像空间中观测到的物体轨迹不遵循现实世界轨迹预测的假设。换句话说,物体在图像中的移动和出现方式与它们在现实世界中的移动和出现方式不同。这是由于各种因素造成的,例如相机的固有参数、方向和位置,以及由于观测时间有限、关联错误和物体定位不精确而导致的轨迹不确定性。因此,为了弥合预测和跟踪之间的差距,需要从图像空间到现实世界空间的转换。这种变换假设物体在平面地面上移动,并使用最初未知的同构变换将检测边界框的底部中心点映射到二维鸟瞰坐标。
Pipeline:
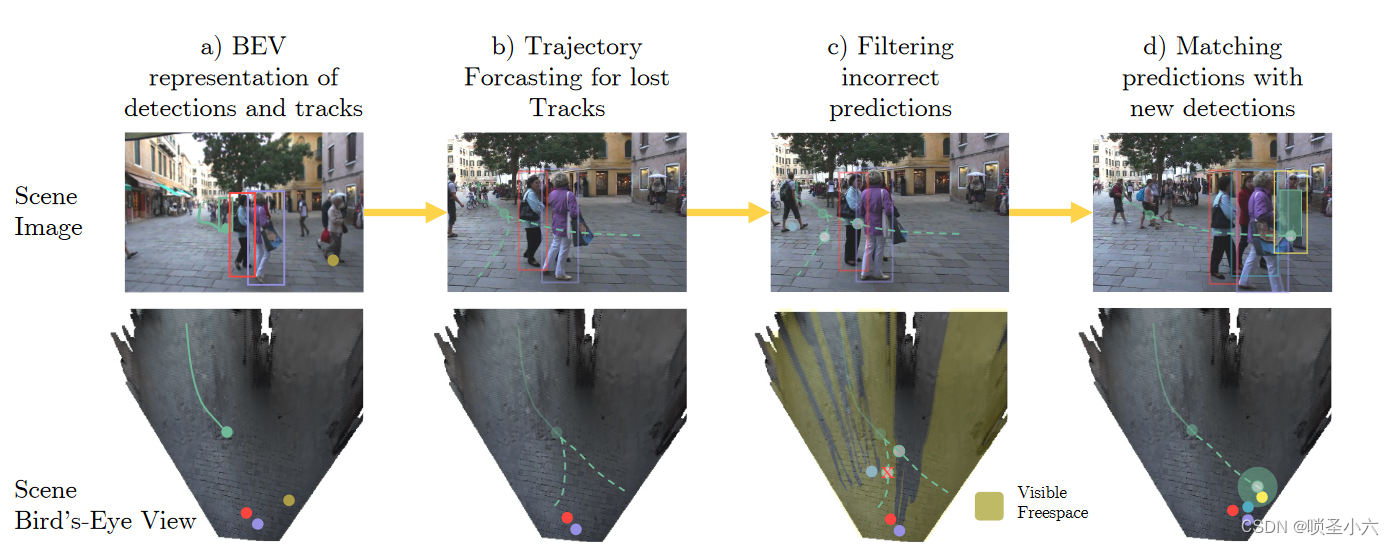
1.在原画面上进行跟踪,当目标丢失时转换到BEV进行轨迹预测
2.可见空间过滤,当预测轨迹出现在可见空间中,而没有相应匹配的detection时,认为该预测轨迹是错误的,删除
3.匹配到detection时进行重连
Method
3.1 H矩阵
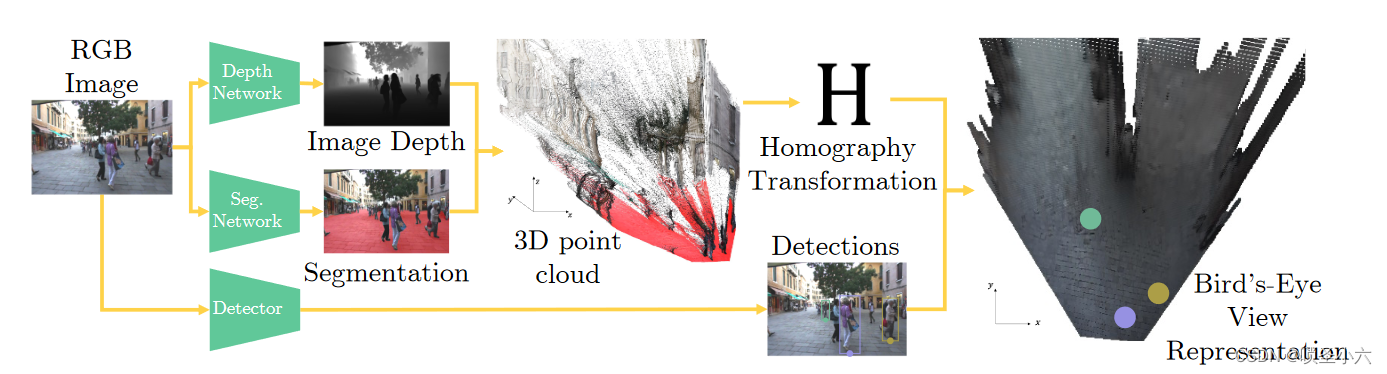
深度估计器:Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. In Conference on Computer Vision and Pattern Recognition, 2021.
人工数据集:Matteo Fabbri, Guillem Brasó, Gianluca Maugeri, Orcun Cetintas, Riccardo Gasparini, Aljoša Ošep, Simone Calderara, Laura Leal-Taixé, and Rita Cucchiara. MOTSynth: How can synthetic data help pedestrian detection and tracking? In International Conference on Computer Vision, 2021.
语义分割网络:https: //github.com/facebookresearch/detectron2
分静态相机和运动相机讨论,
静态:只估计第一帧,后面全用相同的H
运动:对每一帧t计算不同的H_t,根据光流找出相邻帧中对应的像素(地面像素)并计算平移向量,从而估计相机的运动信息
3.2 forecasting
前处理:由于要使用LSTM编码,而该模型需要固定大小的输入,因此作者构造了如下规则的输入,
- 同一Track ID的时序连续的detection
- 卡尔曼滤波器平滑定位噪声
- 线性外推到过去(保证每一轨迹的长度相同)
轨迹预测设计模式:需满足以下要求,
- 随机性,social GAN + “best of many” loss(这两个都需要去了解一下)得到未来轨迹的可能分布(该分布受观测值约束),再去从该分布中采样
- 社会互动,这些方法会将社会环境(即周围行人的轨迹)提供给轨迹的decoder,类似于nlp的方法。作者训练的social GAN 首先通过最大池化把不相邻的行人“分开”,之后送入decoder学习行人调整轨道、避免碰撞的模式
- 多样性(复杂程度),作者实现了一个多生成器 GAN 网络,该网络训练多个解码器头专注于不同的模式。这允许通过从这些不同的生成器中进行采样来生成一组合理但最大程度分离的预测。(什么是最大程度分离?)
3.3 tracking
约定online tracker的输出为
![]()
f_i是resnet backbone提取的外观特征,b_i为bbox坐标,可以通过H矩阵变换为BEV坐标
- 不更新的轨迹 -> 不活跃 -> 开始预测轨迹(该活动只在不活跃轨迹的第一帧开始)
- 设置轨迹最大寿命
- 确定相机的最大可见空间(根据Tarasha Khurana, Achal Dave, and Deva Ramanan. Detecting invisible people. In International Conference on Computer Vision, 2021.)这个变量是什么?
![]()
- 如果预测轨迹进入可见空间,我们认为预测位置的BEV投影应该处于地面mask内并且与其他物体的重叠度小于0.25,不满足该条件则移除当前预测
- 相对顺序的确定?(没看懂)
- 当某一不活跃轨迹的所有预测都被移除,即使它还没有到寿命上限,我们也予以删除
关联代价设计:
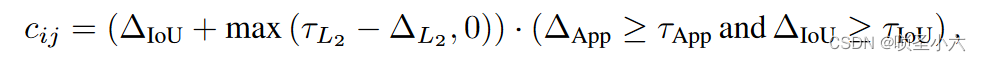
该公式的约束说明:只有两bbox包围内容的外观相似度足够大且IOU足够大时才计算该函数
拟合较好时,IOU大,BEV投影的欧式距离小,得分高;反之,IOU小,max函数输出小(或等于0),得分低。
约束的作用是在候选者外观偏离巨大时过滤掉这些候选者,起到验证作用
基于现实空间距离的缺点:出现大量新检测且拥挤时,这些新检测的区分度不高,很容易导致ID错误
实验
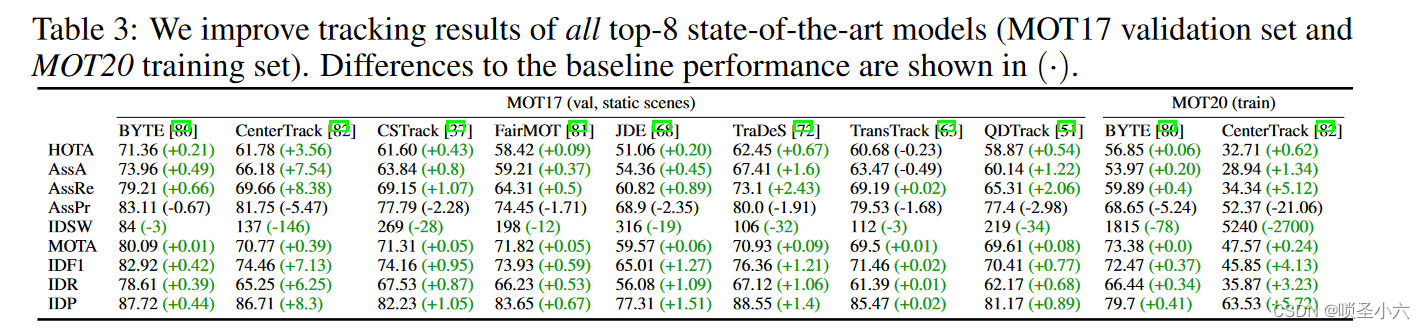
从结果来看,该方法对MOTA提升不大,对IDSW,HOTA,AssA提升大,关联环节性能提升明显
这篇关于Quo Vadis_Is Trajectory Forecasting the Key 论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


