本文主要是介绍python爬虫(2)- 爬取今日头条街拍美图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
有时候用requests抓取页面数据时,可能会和我们想要的不一样,也就是不会出现我们想要的数据,浏览器中可以看到,但是requests的结果没有这些数据,这是为什么呢?因为requests得到的是原始的文档,而真正的网页是经过JavaScript渲染得到的,这些数据可能是通过Ajax加载的,也可能是经过JavaScript加密的。
对于Ajax加载,其实是一种异步加载方式,原始页面加载完成后,网页会向服务器请求获取数据,也就是一个Ajax请求,之后再显示在页面上。遇到这种网页就需要分析网页的Ajax请求后的数据。
使用工具
python3.7(python3以上都可以)
pycharm IDE (笔者习惯使用pycharm,也可以使用其他的)
URL: https://www.toutiao.com/search/?keyword=街拍美图
json、requests库
知识准备
什么是Ajax请求
Ajax全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML,如上所言,Ajax请求就是在网页加载完毕后再向服务器请求的数据,服务器会返回一个或者多个URL,里边携带这些数据,这些数据通常以JSON格式存在(后边会讲什么是JSON),通俗点讲,有时候网页会有下滑之类的选项,本来数据不会显示,鼠标下滑后就会出现新的数据而且不会刷新页面,这就是通过Ajax请求后显示的数据。
什么是JSON
json是一种数据存储格式,他以对象和数组的形式存在,所以很方便的调用
重点来了
想抓网页数据,想看看数据在哪,怎么定位,使用requests库对该网页的发送请求,但是发现结果没有想要的数据
import requestsurl = 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D%E7%BE%8E%E5%9B%BE'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/69.0.3486.0 Safari/537.36'}response = requests.get(url=url, headers=header)print(response.text)
于是我们想到了可能是Ajax请求,这里我用的Chrome查看的Ajax请求,如下
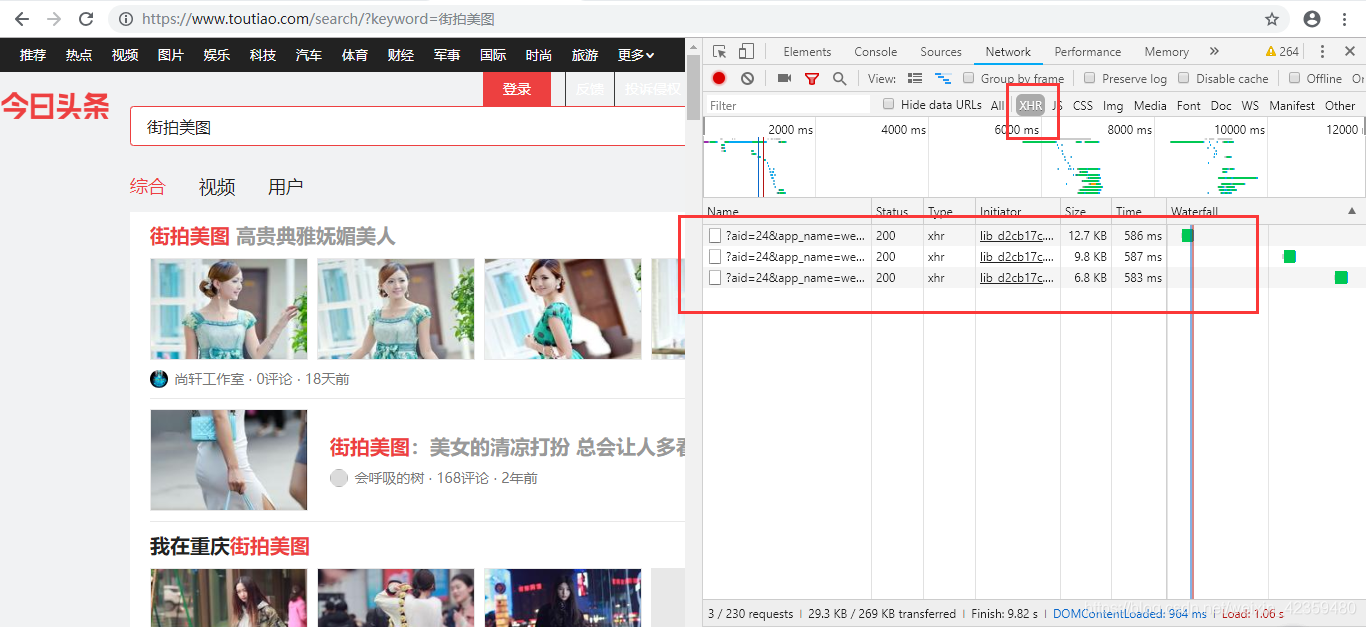
查看一下这些URL内的数据,可以看到,确实是存在我们想要的这些数据的

然后我们对这些数据逐一查看,没错了,就是这里,数据就存在这些URL里,通过观察这些URL,
https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=40&format=json&keyword=街拍美图&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1554034911376
https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=20&format=json&keyword=街拍美图&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1554034847622
不一样的地方只有两处,offset和timestamp,其中offset是有规律的增长,每次20,而timestamp是13位时间戳,用代码也可以获取到,接下来就好说了,找出存放图片的位置,然后,,,,下载!!!!!!
部分代码如下:
offset = 0
# 构造第一个URL
url = 'https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset={}&format=json&keyword=%E8%A1%97' \'%E6%8B%8D%E7%BE%8E%E5%9B%BE&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synth' \'esis×tamp={}'.format(offset, int(round(time.time() * 1000)))
# int(round(time.time() * 1000)) 获取13位时间戳# 保存图片
for i in data:try:info = {'title': '', 'pic': []} # 数据信息字典# 数据写成字典info['title'] = i['title']for k in i['image_list']:info['pic'].append(k)# 创建标题文件夹,首先判断存不存在if not os.path.exists(path + '\picture\{}'.format(info['title'])):os.mkdir(path + '\picture\{}'.format(info['title']))# 图片路径pic_file = path + '\picture\{}'.format(info['title'])# 下载图片for j in info['pic']:# print(j['url'])pic_2 = requests.get(j['url'])# 图片名字设为md5值,不会重复pic_path = path + '\picture\{}'.format(info['title']) + '\{}'.format(md5(pic_2.content).hexdigest()) + '.jpg'print(pic_path)if not os.path.exists(pic_path):with open(pic_path, 'wb') as f:f.write(pic_2.content)print(info['title'], 'is finished!')except:pass结果如下:
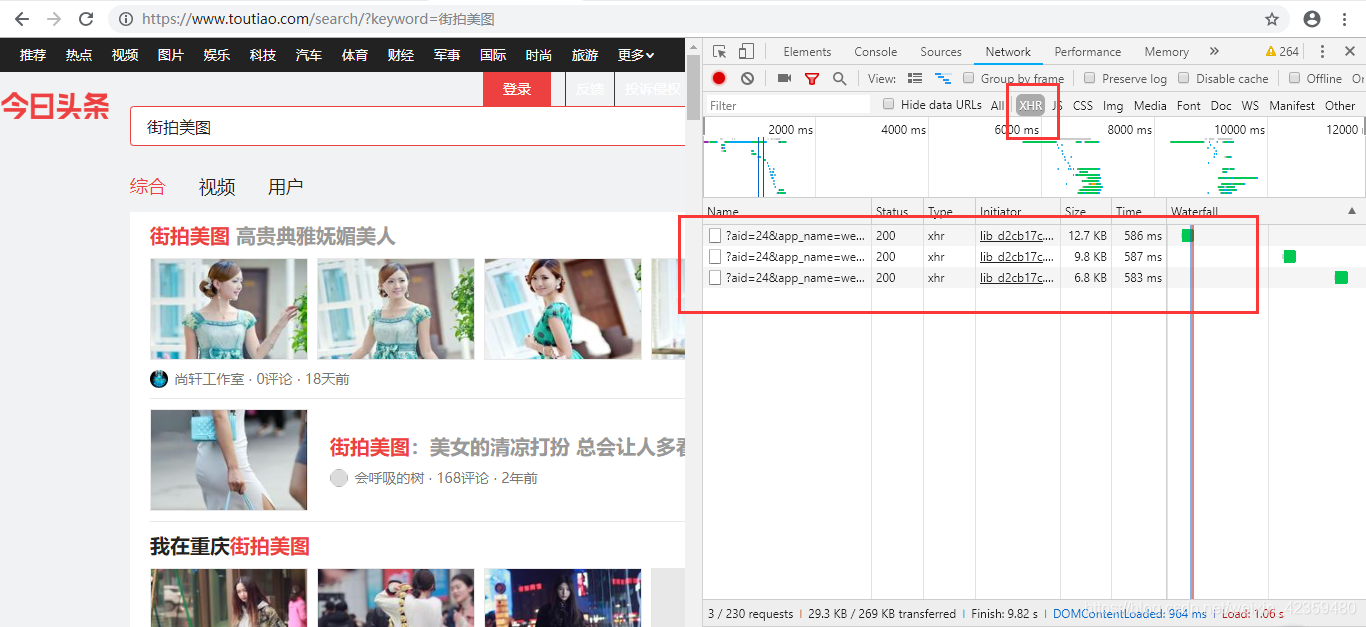
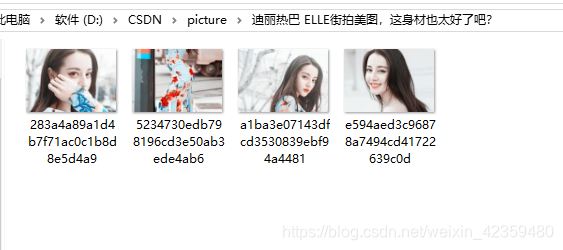
过程写的很粗略,因为细节很多,源码放在GitHub上了,https://github.com/maotai1015/toutiao_jiepai
这篇关于python爬虫(2)- 爬取今日头条街拍美图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





