本文主要是介绍「Mybatis实战二」:Mybatis实现数据新增详析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
本文将在 Mybatis初体验:一小时从入门到运行你的第一个应用 所构建的基础代码结构之上,并实现利用Mybatis进行数据新增的操作。
二、代码演示
1、修改映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="user"><!-- 查询所有用户 --><select id="findAll" resultType="domain.User">select *from user</select><!--新增用户--><!--#{} : mybatis中的占位符,等同于JDBC中的parameterType :指定接收到的参数类型 --><insert id="save" parameterType="domain.User">insert into user(username, birthday, sex, address)values (#{username}, #{birthday}, #{sex}, #{address})</insert>
</mapper>
2、修改测试类
package test;import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import domain.User;import java.io.IOException;
import java.io.InputStream;
import java.util.Date;
import java.util.List;public class MybatisTest {@Testpublic void test() throws IOException {//加载核心配置文件InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");//获取SqlSessionFactory工厂对象SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);//获取SqlSession会话对象SqlSession sqlSession = sqlSessionFactory.openSession();List<User> list = sqlSession.selectList("user.findAll");for (User user : list) {System.out.println(user);}//释放资源sqlSession.close();}@Testpublic void testInsert() throws IOException {InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);SqlSession sqlSession = sqlSessionFactory.openSession();//执行更新User user = new User();user.setUsername("lily");user.setBirthday(new Date());user.setSex("女");user.setAddress("杭州");sqlSession.insert("user.save", user);//DML语句需要手动提交事务sqlSession.commit();sqlSession.close();}}注意:这里插入会出现乱码问题,需要确保数据库连接字符串中指定了正确的字符编码,在连接URL后添加 ?characterEncoding=UTF-8
3、测试结果
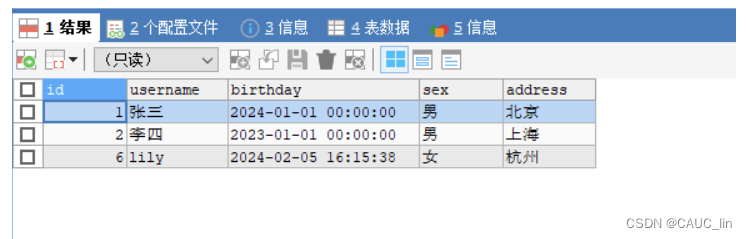
总结
-
插入语句使用insert标签
-
在映射文件中使用parameterType属性指定要插入的数据类型
-
Sql语句中使用#{实体属性名}方式引用实体中的属性值
-
插入操作使用的API是sqlSession.insert(“命名空间.id”,实体对象);
-
在映射文件中使用parameterType属性指定要插入的数据类型
-
Sql语句中使用#{实体属性名}方式引用实体中的属性值
-
插入操作使用的API是sqlSession.insert(“命名空间.id”,实体对象);
-
插入操作涉及数据库数据变化,所以要使用sqlSession对象显示的提交事务,即 sqlSession.commit()
这篇关于「Mybatis实战二」:Mybatis实现数据新增详析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



