本文主要是介绍swarm mysql集群_立足Docker运行MySQL:多主机网络下Docker Swarm模式的容器管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文将以多主机网络环境为基础,探讨如何利用内置编排工具 Docker Swarm模式对各主机上的容器加以管理。
Docker Engine – Swarm模式
在多台主机之上运行MySQL容器拥有一定程度的复杂性,而具体水平则取决于您所选择的集群技术。
在尝试利用容器加多主机网络运行MySQL之前,我们首先需要理解镜像的起效原理、各资源的分配方式(包括磁盘、内存与CPU)、网络(覆盖网络驱动因素,默认情况下包括flannel与weave等)以及容错机制(容器如何实现重新定位、故障转移以及负载均衡等)。
这一切都会给数据库的整体运行、正常运行时间以及性能表现造成影响。我们建议大家使用编排工具保证Docker引擎集群拥有更出色的可管理性与可扩展性。最新的Docker Engine(版本为1.12,发布于2016年7月14日)当中包含有Swarm模式,专门用于以原生方式管理名为Swarm的Docker Engine集群。
需要注意的是,Docker Engine Swarm模式与Docker Swarm是两个不同的项目,二者虽然工作原理类似,但却拥有不同的安装步骤。
下面我们来看看着手进行之前,首先需要完成的准备工作:
必须首先打开以下端口:
2377 (TCP) – 集群管理
7946 (TCP 与UDP) – 节点通信
4789 (TCP与UDP) – 覆盖网络流量
节点类型分为2种:
管理节点 - 管理节点负责执行维护Swarm必要状态所必需的编排与集群管理功能。管理节点会选择单一主管理方执行编排任务。
工作节点 - 工作节点负责从管理节点处接收并执行各项任务。在默认情况下,管理节点本身同时也作为工作节点存在,但大家可以通过配置保证其仅执行管理任务。
在本文中,我们将立足于3台Docker主机(docker1、docker2与docker3)在负载均衡Galera Cluster之上部署应用程序容器,同时将其接入一套覆盖网络。我们将利用Docker Engine Swarm模式作为编排工具。
集群构建
首先让我们将Docker节点纳入Swarm集群当中。Swarm模式要求利用奇数台管理节点(当然不止一台)以维持容错能力。因此,我们在这里需要让三台节点全部作为管理节点。需要注意的是,在默认情况下,管理节点同时亦作为工作节点。
首先在docker1上对Swarm模式进行初始化。完成之后,该节点将成为管理节点及当前管理方:
[root@docker1]$ docker swarm init --advertise-addr 192.168.55.111
Swarm initialized: current node (6r22rd71wi59ejaeh7gmq3rge) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-16kit6dksvrqilgptjg5pvu0tvo5qfs8uczjq458lf9mul41hc-dzvgu0h3qngfgihz4fv0855bo \
192.168.55.111:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
我们还需要将其它两个节点添加为管理节点。使用join命令将这两台节点注册为管理节点:
[docker1]$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-16kit6dksvrqilgptjg5pvu0tvo5qfs8uczjq458lf9mul41hc-7fd1an5iucy4poa4g1bnav0pt \
192.168.55.111:2377
在docker2与docker3上,运行以下命令以进行节点注册:
$ docker swarm join \
--token SWMTKN-1-16kit6dksvrqilgptjg5pvu0tvo5qfs8uczjq458lf9mul41hc-7fd1an5iucy4poa4g1bnav0pt \
192.168.55.111:2377
验证是否全部节点都已经正确添加:
[docker1]$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
5w9kycb046p9aj6yk8l365esh docker3.local Ready Active Reachable
6r22rd71wi59ejaeh7gmq3rge * docker1.local Ready Active Leader
awlh9cduvbdo58znra7uyuq1n docker2.local Ready Active Reachable
到这里,我们的docker1.local作为主管理节点。
覆盖网络
要让不同主机之上的运行的容器彼此实现对接,惟一的方式就是使用覆盖网络。大家可以将其视为一套构建于另一网络(在本示例中为物理主机网络)之上的容器网络。Docker Swarm模式提供一套默认覆盖网络,其负责配合libnetwork与libkv实现一套基于VxLAN的解决方案。当然,大家也可以选择Flannel、Calico或者Weave等其它覆盖网络驱动方案,但需要执行额外的安装步骤。
在Docker Engine Swarm模式当中,大家可以单纯立足管理节点创建一套覆盖网络,而且其不需要etcd、consul或者Zookeeper等额外的键值存储机制。
这套Swarm仅为集群内的各节点提供覆盖网络。当大家创建一项需要用到覆盖网络的服务时,管理节点会自动将覆盖网络延伸至运行该服务任务的节点处。
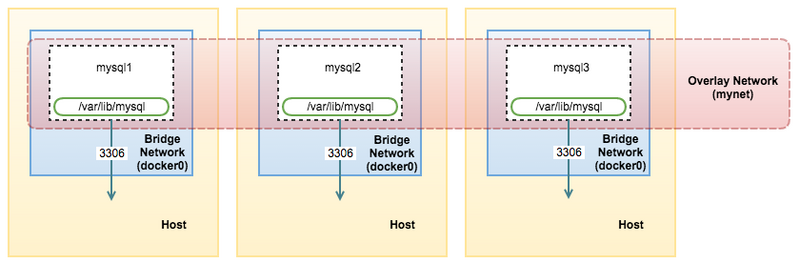
下面让我们为各容器创建一套覆盖网络。在这里,我们需要将Percona XtraDB集群与应用程序容器分别部署在各Docker主机之上,用以实现容错性。这些容器必须运行在同一覆盖网络当中,从而确保其能够彼此通信。
这里我们将网络命名为“mynet”。大家只能在管理节点上完成这一创建工作:
[docker1]$ docker network create --driver overlay mynet
下面来看我们的现有网络:
[docker1]$ docker network ls
NETWORK ID NAME DRIVER SCOPE
213ec94de6c9 bridge bridge local
bac2a639e835 docker_gwbridge bridge local
5b3ba00f72c7 host host local
03wvlqw41e9g ingress overlay swarm
9iy6k0gqs35b mynet overlay swarm
12835e9e75b9 none null local
现在Swarm当中拥有2套覆盖网络。其中“mynet”网络正是我们在部署容器时所创建的成果。而ingress覆盖网络则为默认提供。Swarm管理节点会利用ingress负载均衡以将服务公布至集群之外。
利用服务与任务实现部署
接下来我们将通过服务与任务进行Galera集群容器部署。当大家创建一项服务时,需要指定使用哪套容器镜像并在容器内执行哪些命令。服务类型共分为两种:
复制服务——将一系列复制任务分发至各节点当中,具体取决于您所需要的设置状态,例如“——replicas 3”。
全局服务——适用于集群内全部可用节点上的服务任务,例如“——mode global”。如果大家在Swarm集群中设有7台Docker节点,则全部节点之上都将存在对应容器。
Docker Swarm模式在管理持久数据存储方面功能有限。当一台节点发生故障时,管理节点会绕过各相关容器并创建新容器,用于继续保持原有运行状态。由于容器在下线后会被丢弃,因此我们会失去其中的全部数据分卷。幸运的是,Galera集群允许各MySQL容器以自动方式在加入时利用状态/数据接受配置。
部署键-值存储
我们在这里使用的docker镜像为Percona-Lab。这套镜像要求各MySQL容器访问一套键-值存储(仅支持etcd)以实现集群初始化与引导过程中的IP地址发现。各容器将在etcd当中搜索其它IP地址,从而利用正确的wsrep_cluster_address完成MySQL启动。否则,首套容器将使用gcomm://作为引导地址。
首先部署我们的etcd服务。大家可以点击此处获取我们使用的etcd镜像。其要求我们根据所需部署的etcd节点数量使用一条发现URL。在这种情况下,我们需要设置单独的etcd容器,其具体命令为:
[docker1]$ curl -w "\n" 'https://discovery.etcd.io/new?size=1'
https://discovery.etcd.io/a293d6cc552a66e68f4b5e52ef163d68
在此之后,使用生成的URL作为“-discovery”值,同时为etcd创建该服务:
[docker1]$ docker service create \
--name etcd \
--replicas 1 \
--network mynet \
-p 2379:2379 \
-p 2380:2380 \
-p 4001:4001 \
-p 7001:7001 \
elcolio/etcd:latest \
-name etcd \
-discovery=https://discovery.etcd.io/a293d6cc552a66e68f4b5e52ef163d68
到这里,Docker Swarm模式将编排其中一台Docker主机上的容器部署工作。
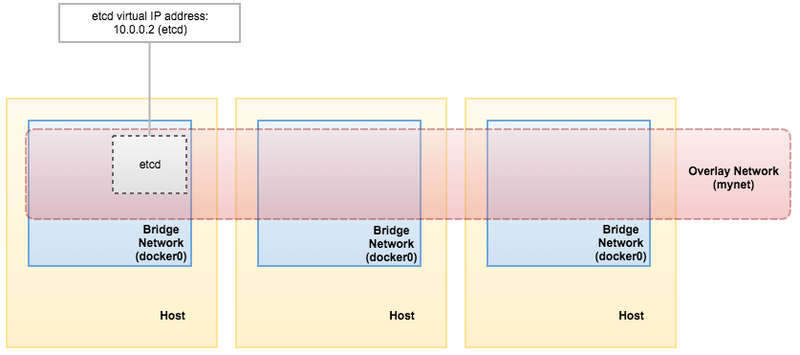
检索etcd服务虚拟IP地址。我们需要在下一步部署集群时使用此IP地址:
[docker1]$ docker service inspect etcd -f "{{ .Endpoint.VirtualIPs }}"
[{03wvlqw41e9go8li34z2u1t4p 10.255.0.5/16} {9iy6k0gqs35bn541pr31mly59 10.0.0.2/24}]
到这里,我们的架构如下图所示:
部署数据库集群
利用以下命令为etcd指定虚拟IP地址,用于部署Galera(Percona XtraDB集群)容器:
[docker1]$ docker service create \
--name mysql-galera \
--replicas 3 \
-p 3306:3306 \
--network mynet \
--env MYSQL_ROOT_PASSWORD=mypassword \
--env DISCOVERY_SERVICE=10.0.0.2:2379 \
--env XTRABACKUP_PASSWORD=mypassword \
--env CLUSTER_NAME=galera \
perconalab/percona-xtradb-cluster:5.6
整个部署流程需要耗费一段时间,包括将镜像下载至对应的工作/管理节点。大家可以使用以下命令验证其部署状态:
[docker1]$ docker service ps mysql-galera
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
8wbyzwr2x5buxrhslvrlp2uy7 mysql-galera.1 perconalab/percona-xtradb-cluster:5.6 docker1.local Running Running 3 minutes ago
0xhddwx5jzgw8fxrpj2lhcqeq mysql-galera.2 perconalab/percona-xtradb-cluster:5.6 docker3.local Running Running 2 minutes ago
f2ma6enkb8xi26f9mo06oj2fh mysql-galera.3 perconalab/percona-xtradb-cluster:5.6 docker2.local Running Running 2 minutes ago
可以看到,mysql-galera服务目前已经开始运行。下面列出全部现有服务:
[docker1]$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
1m9ygovv9zui mysql-galera 3/3 perconalab/percona-xtradb-cluster:5.6
au1w5qkez9d4 etcd 1/1 elcolio/etcd:latest -name etcd -discovery=https://discovery.etcd.io/a29...
Swarm模式包含一项内部DNS组件,其负责自动为Swarm中的每项服务分配一条DNS入口。因此,大家可以使用该服务名称以解析至对应的虚拟IP地址:
[docker2]$ docker exec -it $(docker ps | grep etcd | awk {'print $1'}) ping mysql-galera
PING mysql-galera (10.0.0.4): 56 data bytes
64 bytes from 10.0.0.4: seq=0 ttl=64 time=0.078 ms
64 bytes from 10.0.0.4: seq=1 ttl=64 time=0.179 ms
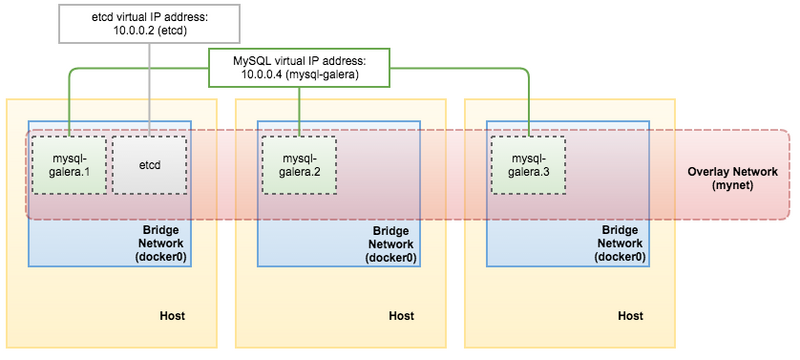
或者直接使用“docker service inspect”命令检索该虚拟IP地址:
[docker1]# docker service inspect mysql-galera -f "{{ .Endpoint.VirtualIPs }}"
[{03wvlqw41e9go8li34z2u1t4p 10.255.0.7/16} {9iy6k0gqs35bn541pr31mly59 10.0.0.4/24}]
到这里,我们的架构如下图所示:
部署应用程序
最后,大家可以创建应用程序服务并将MySQL服务名称(mysql-galera)作为数据库主机值进行交付:
[docker1]$ docker service create \
--name wordpress \
--replicas 2 \
-p 80:80 \
--network mynet \
--env WORDPRESS_DB_HOST=mysql-galera \
--env WORDPRESS_DB_USER=root \
--env WORDPRESS_DB_PASSWORD=mypassword \
wordpress
部署完成之后,我们随后能够通过“docker service inspect”命令检索wordpress服务的虚拟IP地址:
[docker1]# docker service inspect wordpress -f "{{ .Endpoint.VirtualIPs }}"
[{p3wvtyw12e9ro8jz34t9u1t4w 10.255.0.11/16} {kpv8e0fqs95by541pr31jly48 10.0.0.8/24}]
现在再来看目前的架构示意图:
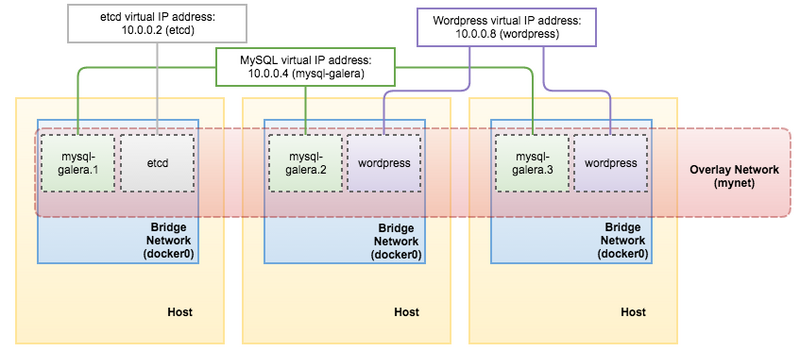
我们的分布式应用程序与数据库设置已经由Docker容器部署完成。
接入服务与负载均衡
到这里,以下端口都已经在集群中的全部Docker节点上被打开(基于每条“docker service create”命令上的-p标记),而无论各节点目前是否正在运行该服务任务:
etcd - 2380, 2379, 7001, 4001
MySQL - 3306
HTTP - 80
如果我们直接利用简单循环接入PublishedPort,则可看到MySQL服务已经在各容器之上实现负载均衡:
[docker1]$ while true; do mysql -uroot -pmypassword -h127.0.0.1 -P3306 -NBe 'select @@wsrep_node_address'; sleep 1; done
10.255.0.10
10.255.0.8
10.255.0.9
10.255.0.10
10.255.0.8
10.255.0.9
10.255.0.10
10.255.0.8
10.255.0.9
10.255.0.10
^C
现在,Swarm管理节点负责负载均衡的内部管理,而且我们无法配置该负载均衡算法。在此之后,我们可以利用外部负载均衡器将外部流量路由至各Docker节点当中。一旦任何Docker节点发生故障,该服务将被重新定位至其它可用节点。
基于最新 Docker SwarmKit 技术的数人云容器管理面板Crane发布新版本啦,点击下方了解更多:
这篇关于swarm mysql集群_立足Docker运行MySQL:多主机网络下Docker Swarm模式的容器管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







