本文主要是介绍神经网络 | 基于 CNN 模型实现土壤湿度预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hi,大家好,我是半亩花海。在现代农业和环境监测中,了解土壤湿度的变化对于作物生长和水资源管理至关重要。通过深度学习技术,特别是卷积神经网络,我们可以利用过去的土壤湿度数据来预测未来的湿度趋势。本文将使用 PaddlePaddle 作为深度学习框架,通过数据分析、可视化、数据预处理、模型组网、模型训练和模型预测,基于卷积神经网络(CNN)模型来来处理时间序列数据,完成 10cm 土壤湿度的预测,从而实现一个简单的回归模型。
目录
一、导入必要库
二、数据分析
三、数据预处理
四、模型组网
五、模型训练
六、模型预测
一、导入必要库
import time
import warnings
import numpy as np
import paddle
import paddle.nn as nn
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScalerwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来设置字体样式(黑体)以正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False
二、数据分析
# 读取数据
soil_humidity = pd.read_excel("./soil_humidity.xlsx", engine="openpyxl")
# print(soil_humidity.head())# 构建Datetime字段
soil_humidity["Datetime"] = pd.to_datetime(soil_humidity["datetime"])
soil_humidity.drop(["datetime"], axis=1, inplace=True)# 按照时间顺序排序
soil_humidity.index = soil_humidity.Datetime
soil_humidity.drop(["Datetime"], axis=1, inplace=True)
soil_humidity = soil_humidity.sort_index()
print(soil_humidity.head())
# print(soil_humidity.describe()) # 查看数据统计学描述
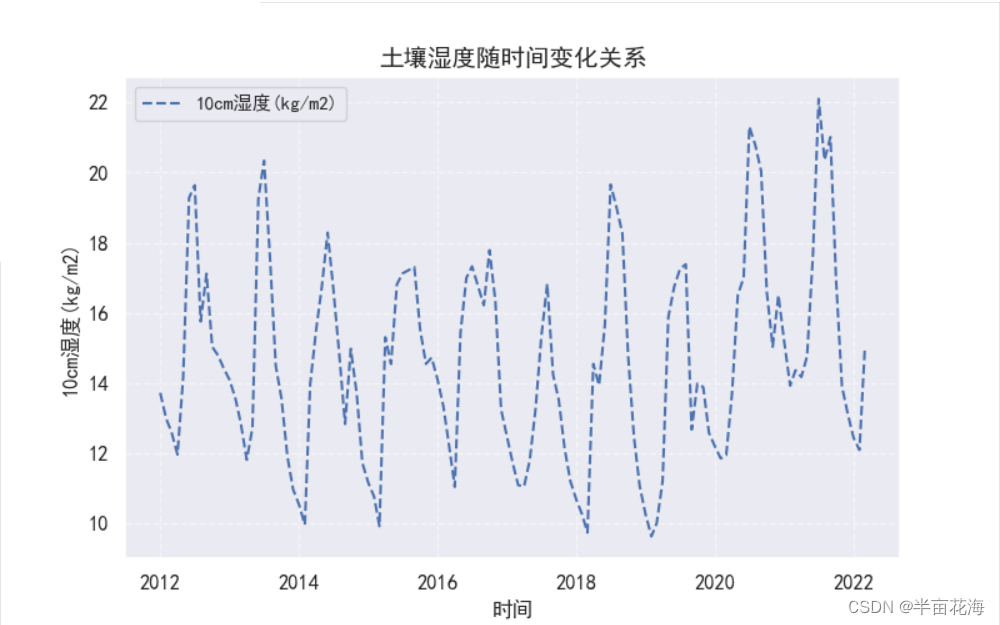
# print(soil_humidity.dtypes) # 查看数据类型# 可视化数据分布
sns.set(font='SimHei') # 设置Seaborn字体
plt.figure(figsize=(8, 5))
plt.plot(soil_humidity.index, soil_humidity["10cm湿度(kg/m2)"], "b--", label='10cm湿度(kg/m2)')
plt.title("土壤湿度随时间变化关系", fontsize=14)
plt.xlabel("时间", fontsize=12)
plt.ylabel("10cm湿度(kg/m2)", fontsize=12)
plt.yticks(fontsize=12)
plt.xticks(fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5) # 添加网格显示(开启网格,虚线,透明度0.5)
plt.show()# 筛选所需要的字段
soil_humidity_10cm = soil_humidity.loc[soil_humidity.index[:], ['10cm湿度(kg/m2)']]
print(soil_humidity_10cm)# 绘制热力图,表示数据框中各列之间的相关性
sns.set(font='SimHei') # 设置Seaborn字体
corr = soil_humidity.corr() # 计算数据框中各列之间的相关性
plt.figure(figsize=(12, 8), dpi=100)
plt.title("数据框中各列之间的相关性", fontsize=13)
heatmap = sns.heatmap(corr, square=True, linewidths=0.2, annot=True, annot_kws={'size': 9})
heatmap.set_xticklabels(heatmap.get_xticklabels(), rotation=35, horizontalalignment='right') # 设置y轴标签向左旋转45度
# 设置x轴和y轴标签字体大小
heatmap.tick_params(axis='x', labelsize=8.5)
heatmap.tick_params(axis='y', labelsize=9)
# 调整热力范围字体大小
cbar = heatmap.collections[0].colorbar
cbar.ax.tick_params(labelsize=9)
plt.show()
soil_humidity.head() 输出结果:
10cm湿度(kg/m2) 40cm湿度(kg/m2) ... 最大单日降水量(mm) 降水天数
Datetime ...
2012-01-01 13.73 30.87 ... 0.51 5
2012-02-01 13.00 30.87 ... 0.76 5
2012-03-01 12.60 30.87 ... 4.83 13
2012-04-01 11.97 30.73 ... 5.33 3
2012-05-01 14.18 29.99 ... 15.49 10[5 rows x 14 columns]

三、数据预处理
# 划分数据集
all_data = soil_humidity_10cm.values
split_fraction = 0.8 # 设置80%为训练集
train_split = int(split_fraction * int(soil_humidity_10cm.shape[0])) # 获取数据集的行数,转换为整数,计算切分的训练集大小
train_data = all_data[:train_split, :] # 从all_data中取前train_split行作为训练集
test_data = all_data[train_split:, :] # 从all_data中取剩余的部分作为测试集# 数据集可视化
plt.figure(figsize=(8, 5))
plt.plot(np.arange(train_data.shape[0]), train_data[:, 0], label='train data')
plt.plot(np.arange(train_data.shape[0], train_data.shape[0] + test_data.shape[0]), test_data[:, 0], label='test data')
plt.title("数据集可视化", fontsize=14)
plt.xlabel("时间", fontsize=12)
plt.ylabel("10cm湿度(kg/m2)", fontsize=12)
plt.legend()
plt.show()# 归一化
scaler = MinMaxScaler(feature_range=(-1, 1)) # 归一化处理,将数据缩放到[-1, 1]之间
train_scal = scaler.fit_transform(train_data.reshape(-1, 1))
test_scal = scaler.fit_transform(test_data.reshape(-1, 1))# 划分卷积窗口与标签值
window_size = 12
train_scal = train_scal.reshape(-1)
train_scal = paddle.to_tensor(train_scal, dtype='float32') # 转换成 tensor# 定义数据输入函数,用于接受序列数据和窗口大小这俩个参数,用于CNN训练
def input_data(seq, ws):out = []L = len(seq)for i in range(L - ws):window = seq[i:i + ws]label = seq[i + ws:i + ws + 1]out.append((window, label))return out # 返回生成的训练样本列表train_scal_data = input_data(train_scal, window_size) # 归一化后的训练集数据,定义的窗口大小
# 打印一组数据集
print(train_scal_data[0])
train_scal_data[0] 这一组数据集的打印结果:
10cm湿度(kg/m2)
Datetime
2012-01-01 13.73
2012-02-01 13.00
2012-03-01 12.60
2012-04-01 11.97
2012-05-01 14.18
... ...
2021-11-01 13.91
2021-12-01 13.14
2022-01-01 12.45
2022-02-01 12.10
2022-03-01 14.96[123 rows x 1 columns]

四、模型组网
一维卷积层(convolution1d layer),根据输入、卷积核、步长(stride)、填充(padding)、空洞大小(dilations)一组参数计算输出特征层大小。
网络构造大体如下:
- 先经过一维卷积层 Conv1D
- 使用 ReLU 激活函数对其进行激活
- 然后经过第1层线性层 Linear1
- 再经过第2层线性层 Linear2
class CNNnetwork(paddle.nn.Layer):def __init__(self):super().__init__() # 调用父类函数self.conv1d = paddle.nn.Conv1D(1, 1, kernel_size=2) # 一维卷积层Conv1D(输入, 输出, 卷积核大小)self.relu = paddle.nn.ReLU() # 激活函数, 引入非线性性# 定义了线性层, 将输入维度为a的特征映射到输出维度为b的空间# 这是一个回归任务, 模型的输出是一个实数self.Linear1 = paddle.nn.Linear(11, 50)self.Linear2 = paddle.nn.Linear(50, 1)def forward(self, x):x = self.conv1d(x) # 通过一维卷积层处理输入数据,提取特征x = self.relu(x) # 将卷积层的输出通过 ReLU 激活函数, 进行非线性变换x = self.Linear1(x) # 第一个线性层,线性变换x = self.relu(x) # 将卷积层的输出通过 ReLU 激活函数, 进行非线性变换x = self.Linear2(x) # 第二个线性层,线性变换return x
五、模型训练
# 五、模型训练
paddle.seed(666)
model = CNNnetwork()
# 设置损失函数,这里使用的是均方误差损失
criterion = nn.MSELoss()
# 设置优化函数和学习率lr
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.001)
# 设置训练周期
epochs = 30# 划分训练集和验证集
split_idx = int(len(train_scal_data) * 0.8)
train_set = train_scal_data[:split_idx]
val_set = train_scal_data[split_idx:]model.train()
start_time = time.time()# 用于存储每轮的训练和验证损失
train_losses = []
val_losses = []for epoch in range(epochs):# 训练阶段model.train()train_loss = 0.0for seq, y_train in train_set:# 每次更新参数前都梯度归零和初始化optimizer.clear_grad()# 注意这里要对样本进行 reshape,转换成 conv1d 的 input size(batch size, channel, series length)seq = paddle.reshape(seq, [1, 1, -1])seq = paddle.to_tensor(seq, dtype='float32')y_pred = model(seq)y_train = paddle.to_tensor(y_train, dtype='float32')loss = criterion(y_pred, y_train)loss.backward()optimizer.step()train_loss += loss.numpy()[0]# 验证阶段model.eval()val_loss = 0.0with paddle.no_grad():for seq_val, y_val in val_set:seq_val = paddle.reshape(seq_val, [1, 1, -1])seq_val = paddle.to_tensor(seq_val, dtype='float32')y_val = paddle.to_tensor(y_val, dtype='float32')val_pred = model(seq_val)val_loss += criterion(val_pred, y_val).numpy()[0]avg_train_loss = train_loss / len(train_set)avg_val_loss = val_loss / len(val_set)# 存储训练和验证损失train_losses.append(avg_train_loss)val_losses.append(avg_val_loss)print('Epoch {}/{} - Train Loss: {:.4f} - Val Loss: {:.4f}'.format(epoch + 1, epochs, avg_train_loss, avg_val_loss))print('\nDuration: {:.0f} seconds'.format(time.time() - start_time))# 可视化训练和验证损失
plt.figure(figsize=(8, 5))
plt.plot(range(1, epochs + 1), train_losses, label='Train Loss')
plt.plot(range(1, epochs + 1), val_losses, label='Val Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('CNN_Loss')
plt.legend()
plt.show()

六、模型预测
将数据按 window_size 一组分段,每次输入一段后,会输出一个预测的值 y_pred,y_pred 与每段之后的 window_size + 1 个数据作为对比值,用于计算损失函数。例如前 5 个数据为 (1,2,3,4,5),取前 4 个进行 CNN 预测,得出的值与 (5) 比较计算 loss。这里使用每组 13 个数据,最后一个数据作评估值,即 window_size=12。
# 六、模型预测
"""
将数据按window_size一组分段,每次输入一段后,会输出一个预测的值y_pred
y_pred与每段之后的window_size+1个数据作为对比值,用于计算损失函数
例如前5个数据为(1,2,3,4,5),取前4个进行CNN预测,得出的值与(5)比较计算loss
这里使用每组13个数据,最后一个数据作评估值,即window_size=12
"""
# 选取序列最后12个值开始预测
preds = train_scal_data[-window_size:]
y_pred1 = []
model.eval() # 设置成eval模式
# 循环的每一步表示向时间序列向后滑动一格
for seq, y_train in preds:# 每次更新参数前都梯度归零和初始化# 转换成conv1d的input size(batch size, channel, series length)seq = paddle.reshape(seq, [1, 1, -1])seq = paddle.to_tensor(seq, dtype='float32')result = model(seq)y_pred1.append(result)print("当前预测值:", y_pred1)
y_pred1 = np.array(y_pred1)
y_pred1 = y_pred1.reshape(-1, 1)
print("完整预测值:", y_pred1)# 预测结果反归一化,还原真实值
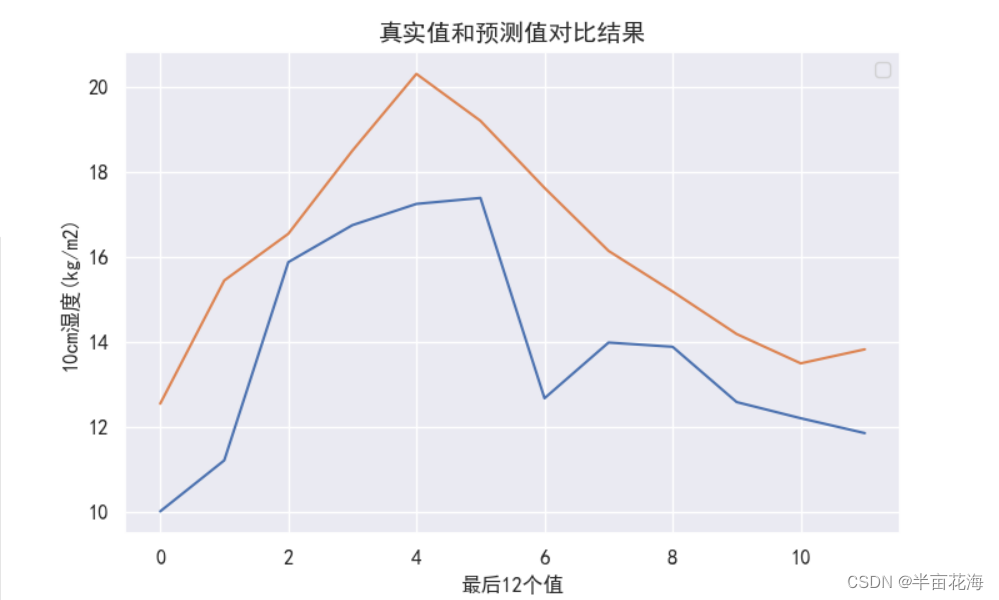
true_predictions = scaler.inverse_transform(y_pred1).reshape(-1, 1)# 预测结果可视化
sns.set(font='SimHei') # 设置Seaborn字体
plt.figure(figsize=(8, 5))
plt.plot(train_data[-window_size:]) # 绘制真实值
plt.plot(true_predictions) # 绘制预测值
plt.title("真实值和预测值对比结果", fontsize=14)
plt.xlabel("最后12个值", fontsize=12)
plt.ylabel("10cm湿度(kg/m2)", fontsize=12)
plt.yticks(fontsize=12)
plt.xticks(fontsize=12)
plt.grid(True)
plt.show()
完整预测值:
[[-0.8811799 ]
[-0.31046718]
[-0.09406683]
[ 0.29082218]
[ 0.64678204]
[ 0.4292445 ]
[ 0.11846957]
[-0.17343275]
[-0.36173454]
[-0.55860955]
[-0.6944711 ]
[-0.6295543 ]]
这篇关于神经网络 | 基于 CNN 模型实现土壤湿度预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






