本文主要是介绍将xyz格式的GRACE数据转成geotiff格式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们需要将xyz格式的文件转成geotiff便于成图,或者geotiff转成xyz用于数据运算,下面介绍如何实现这一操作,采用GMT和matlab两种方法。
1.GMT转换
我们先准备一个xyz文件,这里是一个降水文件。在gmt中采用以下的语句实现xyz转grd网格文件
xyz2grd DJF.txt -R-180/180/-90/90 -JN12c -I5 -Gm1.grdgmt grdsample m1.grd -Gm11.grd -I0.5语句实现了将xyz转成grd文件,然后在Global mapper中打开,导出为geotiff格式即可,然后可以用于绘图和地理信息处理显示。

2.matlab程序实现
我们现在matlab中读取一个geotiff文件以观察其组成要素。
[A1,R] = geotiffread('Tibet_1000.tif');A1(A1<=0)=0;

可以看到,其由两部分组成,一个是数值矩阵(A1),另一个是投影信息(R)。因此我们如果想要将xyz数据转成geotiff格式的文件,同样需要准备两个信息:一个是数据矩阵,另一个是投影信息(当然需要自己设置)。
[A1,R] = geotiffread('Tibet_1000.tif');A1(A1<=0)=0;
lon = linspace(65.0042,109.9958,5400);
lat = linspace(20.0042,49.9958,3600);
[lon,lat] = meshgrid(lon,lat);O1.lon = lon;O1.lat = lat;O1.rg = flipud(double(A1));
rg_plot(O1),title('10 km DEM'),colorbar
需要注意的是,一般我们所说的xyz数据是三列的,分别是

如果要转成geotiff文件,需要提前转成数值矩阵,即通常需要reshape一下(这针对于转换的影响为矩形)。

接下来,我们实现一个xyz转成geotiff的例子。
(1)先准备一个xyz数据,这里以MSSA插值的GRACE level03数据集为例,数据参考以下专栏:
分享一个月份连续的MSSA插值的GRACE level03数据集_grace数据集-CSDN博客
matlab先读取xyz数据,然后绘图,可见reshape的正确性:
% % load data
A = load('GRACE_MSSA_2022_01.xyz');%% reshape
O.lon = reshape(A(:,1),181,361);
O.lat = reshape(A(:,2),181,361);
O.rg = reshape(A(:,3),181,361);wzq_plot(O)
wzq_plot函数如下,其中缺失的报错文件参加B站的置顶评论:
绘图函数的使用wzq_plot - 哔哩哔哩 (bilibili.com)
function wzq_plot(wzq)
pcolor(wzq.lon,wzq.lat,wzq.rg)
shading interp
hold on;
if max(wzq.lon(:)) < 200coast=load('coastline-from-GMT-WNI.dat');
elsecoast=load('coastline-from-GMT-WNI-0-360.dat');
end
plot(coast(:,1),coast(:,2),'k')
hold off;
colorbar
colormap jet
end (2)配置投影信息
这里我们借用其他读取的geotiff文件的投影信息,然后按照实际情况进行修改配置,这里我们采用一个DEM的投影信息,我们需要修改的地方包括:
X Y的范围 采样分辨率 经纬度范围 栅格数量
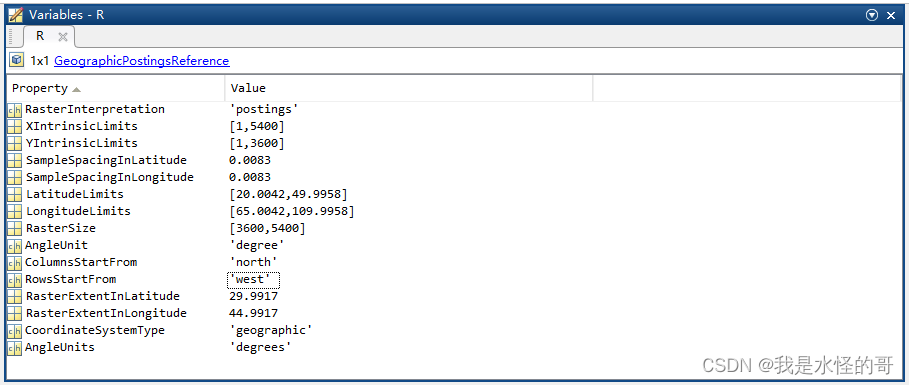
然后我们得到配置好的新的投影信息,但是实际上有更简单的配置方法:
[A1,R] = geotiffread('Tibet_1000.tif');A1(A1<=0)=0;
% % load data
A = load('GRACE_MSSA_2022_01.xyz');%% reshape
O.lon = reshape(A(:,1),181,361);
O.lat = reshape(A(:,2),181,361);
O.rg = reshape(A(:,3),181,361);wzq_plot(O)%% setting new projection info
R1.RasterInterpretation = 'Postings';
R1.XIntrinsicLimits = [1,361];
R1.YIntrinsicLimits = [1,181];
R1.SampleSpacingInLatitude = 1;
R1.SampleSpacingInLongitude = 1;
R1.LatitudeLimits = [-90,90];
R1.LongitudeLimits = [0,360];
R1.RasterSize = [181,361];
R1.AngleUnit = 'degree';
R1.ColumnsStartFrom = 'north';
R1.RowsStartFrom = 'east';
R1.CoordinateSystemType = 'geographic';
R1.AngleUnits = 'degrees';latlim = [-90,90];
lonlim = [0,360];
R0 = georefcells(latlim,lonlim,size(O.rg)); % 设置一个地理坐标
geotiffwrite('GRACE_xyz2tiff.tif', O.rg, R0); %
然后我们可以得到GRACE_xyz2tiff.tif文件,需要注意的是,再次运行前需要删除之前生成的文件。

在global mapper中可以打开

这篇关于将xyz格式的GRACE数据转成geotiff格式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





