本文主要是介绍神经网络水印(文章解读Dataset Inference: Ownership Resolution in Machine Learning),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇发在ICPR上。介绍了一种数据集推理的方法(dataset inference)。实际上也是模型水印方法,但是却属于完全不同的大类。之前介绍的模型水印的方法,其实大概就两种,一种是白盒,包括在训练的时候直接加入惩罚项使得最终模型参数变成一个特定的“形状”,或者是在顶会上发了很多次的passport layers。在验证阶段需要打开模型,计算参数向量与特定的向量之间的距离。这样的验证是比较难实现的,一般需要有足够的证据才好实施指控。于是催生了另一种水印模式,黑盒水印。
黑盒其实是利用模型的后门(backdoor)。也就是利用一小部分的数据,添加上特意设计的“错误”水印,加入训练。小部分错误的数据既不会影响模型性能,在验证的时候,还能通过验证这些数据来申明所有权。但是这样的行为也有弊端,随意篡改的数据(拿图片分类来说),是比较明显能被发现的,比如可以通过查询输出然后修正标签,或者reverse engine之类的方法。针对这个,后面又做了一些,比如对抗样本,边界数据作为水印等等。
这两个之外,还有比如密码学的方式做的水印,外部特征等等。
这篇文章属于,当外部用户直接访问模型的输入输出,根据这些数据来重新训练一个模型,这些数据其实已经是包含了很多模型所有者的“隐私”了(model extraction)。这样子的防御模式其实也只能从数据的输出下手。
“Dataset Inference: Ownership Resolution in Machine Learning” 出发点就是盗取者和模型所有者的在数据上是不对等的,关键怎么能说明私人的知识是自己的呢?注意到,用于训练的数据往往比其他任意的数据在模型上要overfit,所以可以考虑观察训练数据集在疑似偷窃模型上的表现。也就是“prediction certainty”:对于给定的数据到其邻居类别的距离。出于数据集的推理,文章给这个方法取了个名字:Dataset Inference (Dataset inference is the process of determining whether a victim’s private knowledge has been directly or indirectly incorporated in a model trained by an adversary.)
主要内容: 对于一般的分类器,在训练时,会最大化训练数据到边界的距离。利用这点,当出现疑似模型的时候,可以检查对比训练数据集以及公共数据集在双方的边界距离,来判断侵权行为是否存在。整个流程如下:
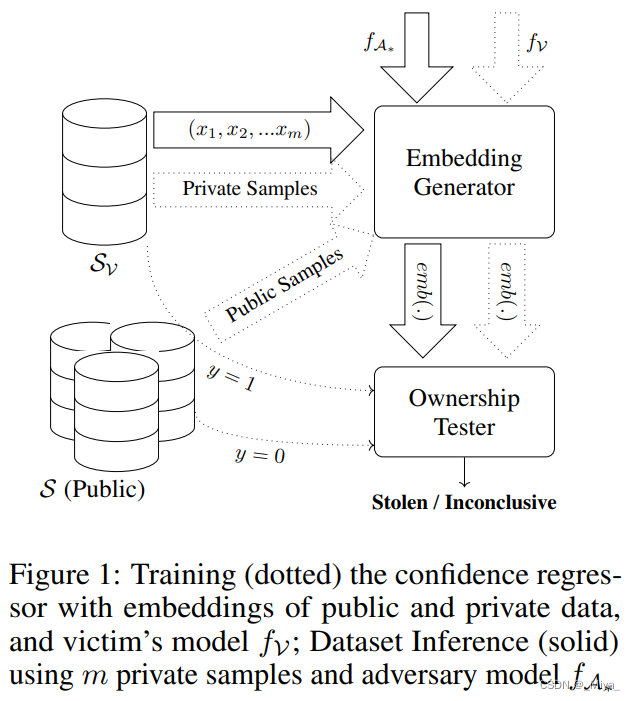
所以本文做的是如何计算边界距离,作者在这里提出了两种方法:
白盒设定(White-Box Setting: MinGD)白盒是在双方的模型结构,参数都能够被第三方所知道的情况下 建立起来的,差不多是一个权威的court。对比的数据集是victim(疑似被侵权者)的训练集以及测试集 , 使用梯度下降(gradient descent optimization) 优化
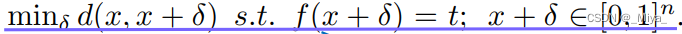
d(x,y)就是二者之间的距离(δ),可以是1,2,∞范数。t可以是任意的label,这个距离就是我们插入的embedding vector。
黑盒设定(Black-Box Setting: Blind Walk) 实际的操作中,我们很难找到一个100%公平公正且没有恶意的第三方,并且大概出于信任危机,也很难相信他的诚意。所以黑盒的检验(只能得到label query access)更加可行。在训练集里面随机挑选一个数据(x,y),挑选一个合适的距离还有随机一个方向,超这个方向走k步,直到标签更改。
这里的黑盒设定,邻居类别我认为也不是一定要是相同的类别(在victim和偷窃者的模型上),只需要朝一个方向走直到类别发生就行,非要规定相同类别错误率才会更加大。而且偷窃者在训练的时候也不一定能刚刚好保持和原来模型一样的分类类别。

后面就是一些所有权说明的介绍了,这里为了避免私人数据集被过多泄露(每一次验证都会泄露一部分),作者将所有权的验证分为了两部分(这也是和membership inference不一样的地方),在正式的判断距离embedding前面加了一步假设,也就是Confidence Regressor。这一步所有者先利用个人模型和外部(非训练)数据集训练一个regression model,用于判断某个输入的样本是否来自于个人模型。当得到一个较大的可能之后,我们才开始正式检验边界数据。
从名字其实也能看出来点,这篇文章其实方法和membership inference有点相似,在距离计算上的核心思想都差不多。这文章的结果也是非常漂亮的,

偷窃者由于不能获取训练数据集,基本上无法复刻模型在训练数据集上的表现,而即使在验证的阶段中遇见了偷窃者用于训练的数据集,是更能说明偷窃行为存在的。这里偷窃者在训练的时候同时用自己的训练集加上数据增强之后的数据一起作为输入,后面再用这个方法计算出来的距离(这个方法给的距离)应该都会大。但是本质上victim的模型,在自己训练集上的准确率肯定是高的,离错误类别的距离很大,即使偷窃者训练加噪声也比不上。只不过文中用这样添加δ的方法,测算出来的也不完全能代表“到错误类别的距离”,添加噪声直接拉大距离感觉理论上是能行的。还是要实验了才知道这样行不行,感觉神经网络确实有点点盲,得看实践才行。
这篇关于神经网络水印(文章解读Dataset Inference: Ownership Resolution in Machine Learning)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





