本文主要是介绍sharding-jdbc-按日分表 解决它不支持部分sql,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
场景需求:
会话详情表(t_session_detail),单日数据非常大,所以我对会话详情表按日分表,今日的操作只入今日表,即按日分表.
实战:
1.导入sharding-jdbc依赖:
<!--shading-jdbc--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency>2.配置sharding-jdbc:
sharding-jdbc代码不需要写很多,几乎全部在配置上。
1. 让sharding-jdbc接管数据源
2. 指定要分那个表
3. 指定分表的策略(如按照这个表的哪个字段来分)
这是yaml配置方式:
# 定义sharding-jdbc数据源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost/test_shading_jdbc
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 333# 指定t_session_detail表的数据分布情况,配置数据节点. (由于是按日分表,所以表个数不固定,不能写死,于是采用表达式代替)
spring.shardingsphere.sharding.tables.t_session_detail.actual-data-nodes = m1.t_session_detail_$->{2020..2099}$->{(1..12).collect{t ->t.toString().padLeft(2,'0')}}$->{(1..31).collect{t ->t.toString().padLeft(2,'0')}}# 指定t_session_detail表的主键生成策略为SNOWFLAKE (由于t_session_detail是一种水平按日分表,所以不能采用自增等策略,这样会多表主键冲突。)
spring.shardingsphere.sharding.tables.t_session_detail.key-generator.column=id
spring.shardingsphere.sharding.tables.t_session_detail.key-generator.type=SNOWFLAKE# 指定t_session_detail表的分片策略,分片策略包括分片键和分片算法 (当指定分片键后,执行sql的时候sharding-jdbc会截取sql,判断本次sql是否有带分片键,如果带了就截取,按照您指定的分片策略算法重写sql)
spring.shardingsphere.sharding.tables.t_session_detail.table-strategy.standard.sharding-column = create_time
spring.shardingsphere.sharding.tables.t_session_detail.table-strategy.standard.precise-algorithm-class-name= com.dzh.shardingJdbc.config.DatabaseShardingAlgorithm# 打开sql输出日志
spring.shardingsphere.props.sql.show = true我们也可以用代码来配置,这样更加的灵活,可以再配置类上@Condition,动态开关。
@Configuration
# 满足这个条件才注入sharding-jdbc 的功能,所以这个condition可以自定义。
@Conditional(value = {ShardingJdbcCondition.class})
public class ShardingJdbcAutoConfiguration {@AutowiredDbproperty dbProperty; // 把你自己的数据库配置弄进来// 定义数据源public Map<String, DataSource> createDataSourceMap() {DruidDataSource dataSource1 = new DruidDataSource();dataSource1.setDriverClassName(dbProperty.getDriverClassName());dataSource1.setUrl(System.getProperty("spring.datasource.url"));dataSource1.setUsername(dbProperty.getUsername());dataSource1.setPassword(dbProperty.getPassword());Map<String, DataSource> result = new HashMap<>();result.put("给你的这个数据源起个名字", dataSource1);return result;}// 定义主键生成策略private static KeyGeneratorConfiguration getKeyGeneratorConfiguration() {KeyGeneratorConfiguration result = newKeyGeneratorConfiguration("SNOWFLAKE","表的主键名");return result;}// 指定表的分片策略TableRuleConfiguration getOrderTableRuleConfiguration() {TableRuleConfiguration result = new TableRuleConfiguration("逻辑表明,假设是session_detail","上明定义的数据源名.session_detail_$->{2022..2099}$->{(1..12).collect{t ->t.toString().padLeft(2,'0')}}$->{(1..31).collect{t ->t.toString().padLeft(2,'0')}}");result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("分片键,就是按照表中哪个字段来分。如:crete_time",精确分片算法,范围分片算法[可为空,额外提供的,一般用来做范围查询时用到]);result.setKeyGeneratorConfig(getKeyGeneratorConfiguration());return result;}// 定义sharding‐Jdbc数据源@BeanDataSource getShardingDataSource() throws SQLException {ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();// 给sharding-jdbc添加 分表策略(如果有多个,可以添加多个)shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());//spring.shardingsphere.props.sql.show = trueProperties properties = new Properties();//properties.put("sql.show","true");return ShardingDataSourceFactory.createDataSource(createDataSourceMap(),shardingRuleConfig,properties);}
}定义刚刚定义分片键的分片算法:如,我上面定create_time来分。那么我就会按照这个create_time重写表名.
精确分片算法(一般用来做insert):
public class DatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Date> {@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {String db_name = preciseShardingValue.getLogicTableName(); // t_session_detailtry {// 获取到分片键中的值(create_time), 重改表名Date date = preciseShardingValue.getValue();String year = String.format("%tY", date);String mon = String.format("%tm",date);String day = String.format("%td",date);db_name = db_name+"_"+year+mon+day;return db_name;} catch (Exception e) {e.printStackTrace();}throw new IllegalArgumentException();}
}范围分片算法(一般用来做查询):比如,需要查询会话的所有操作详情,那么这个会话的详情可能在1表中有,2表中有....这个时候sql上就需要create_time between xxx and xxx. 就会走范围分片算法,你就可以拿到范围时间,筛选出所有可能存在详情的表。
public class SessionDetailRangeShardingAlgorithm implements RangeShardingAlgorithm<Date> {@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Date> rangeShardingValue) {String db_name = rangeShardingValue.getLogicTableName(); // ogw_session_detailRange<Date> valueRange = rangeShardingValue.getValueRange();Date startDay = valueRange.lowerEndpoint();Date endDay = valueRange.upperEndpoint();Set<String> res = new HashSet<>();// 计算出这【startDay~endDay】日期之间的所有日期,同时转换成对应数据库表名Calendar calendar = Calendar.getInstance();while (startDay.getTime()<=endDay.getTime()){String year = String.format("%tY", startDay);String mon = String.format("%tm",startDay);String day = String.format("%td",startDay);res.add(db_name+"_"+year+mon+day);calendar.setTime(startDay);calendar.add(Calendar.DATE, 1);// 获取增加后的日期startDay = calendar.getTime();}/*为了确保,再次补充最后一天时间表名.比如: 会话开始于6月1日 晚上9点,持续到6月2日早上9点。此时上述while循环只收集了6月1日的表名,所以需要再次检测最后一天的表名。又比如:会话开始于6月1日晚上9点,持续到6月2日晚上10点。此时上述while循环收集了6月1日的和2日的表名,虽然此时会再次补充一次,也无需紧要。我们用的set集合。*/String day = String.format("%td",startDay);String ed = String.format("%td",endDay);if(day.equals(ed)){String year = String.format("%tY", startDay);String mon = String.format("%tm",startDay);res.add(db_name+"_"+year+mon+day);}return res;}
}那么以上就是sharding-jdbc 的配置,主要就是
1. 配置一下数据源,让sharding-jdbc接收数据源
2. 配置被分表的主键策略 & 分片策略(精确和范围等等)
数据库:
模拟建了两张日期表,当然可以写一个定时任务,凌晨时候将明天或者后天的创建出来。

测试代码:
1. 今日新增条会话详情:由于create_time字段是自动填充,填充今日的时间,所以会走分片策略,重写sql语句表名。
@Testpublic void testInsertSessionDetail() throws ParseException {SessionDetailDTO detailDTO = new SessionDetailDTO();detailDTO.setContent("会话详情asdsadsadsa");detailDTO.setSessionId(2L);sessionDetailMapper.insert(detailDTO);}逻辑sql是这样:
INSERT INTO t_session_detail ( create_time,content,session_id) VALUES ( ?,?,?)sharding-jdbc重写:
Actual SQL: m1 ::: INSERT INTO t_session_detail_20220529 (create_time, content, session_id, id) VALUES (?, ?, ?, ?) ::: [2022-05-29 16:41:13.749, 会话详情asdsadsadsa, 2, 737711275903025153]此时就实现了今日操作全入今日表,当然如果你这个时间是昨天的,肯定就入昨天的表。查询也是一样,sharding-jdbc 看是否命中分片,如果命中,按照分片策略重写sql。
当然,如果您的sql要是没有带分片键,那么sharding-jdbc就会根据你配置文件配置的所有数据表节点都执行一次这个sql语句,最终在汇总结果给你。这样就效率大大降低,所以使用sharding-jdbc 一定要带上这个分片键。
项目中运用分表照成的问题记录:
背景:
由于项目需要适配Oracle数据库,故本人在测试过程中,发现项目中许多涉及到数据库的sql都会报错,报一些Sharding-jdbc的sql语法解析错误。这个问题困扰了我大半天。一直在想mysql都没错,为什么换成oracle就不行。并且抛出的报错中,我把sql截取下来,丢到oracle数据库中执行,是可行的。说明sql本身是没有问题的。后来,我百度了下,发现shardingJdbc对许多sql不支持,比如left join xxx on (条件) , 对于on 后面不能有(),而我使用MybatisPlus框架,生成的sql会加(),就矛盾了。所以他在解析过程就会抛出错误,都到不了连接数据库流程。
如下图错误:

后来我就思考,shardingJdbc 既然需要先解析sql,如果不满足它框架的SQL语法,就要抛出错误,那我直接去修改源码,我将哪些语法限制全部注释,于是,我就直接重写了TableReferecesClauseParse类的parseJoinCondition(). 不让他校验。
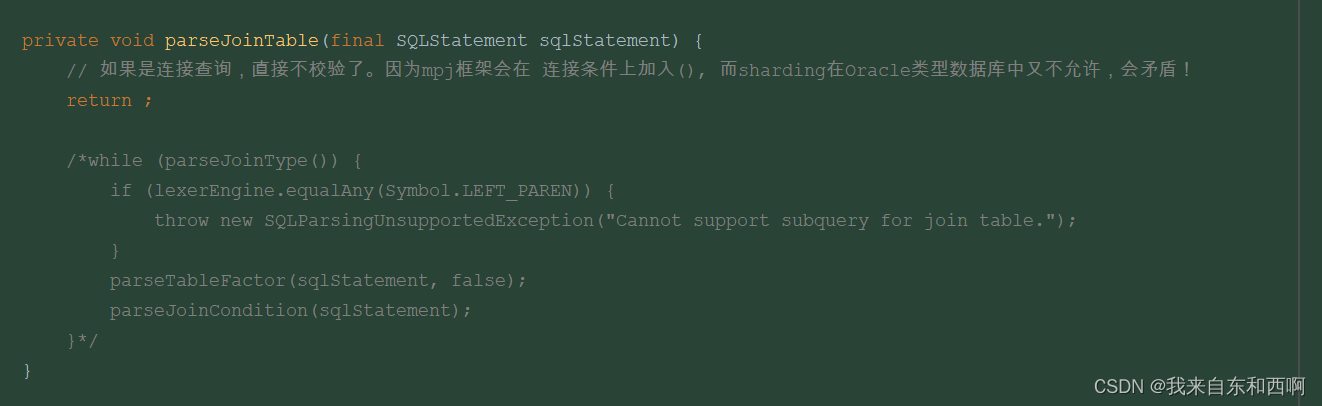
就在我松了一口气后,过了一天,小组群内又抛出错误了,还是sql解析异常,但不是连表错误,是其他的语法union。我又照葫芦画瓢,将UNION语法限制也注释掉。如下:
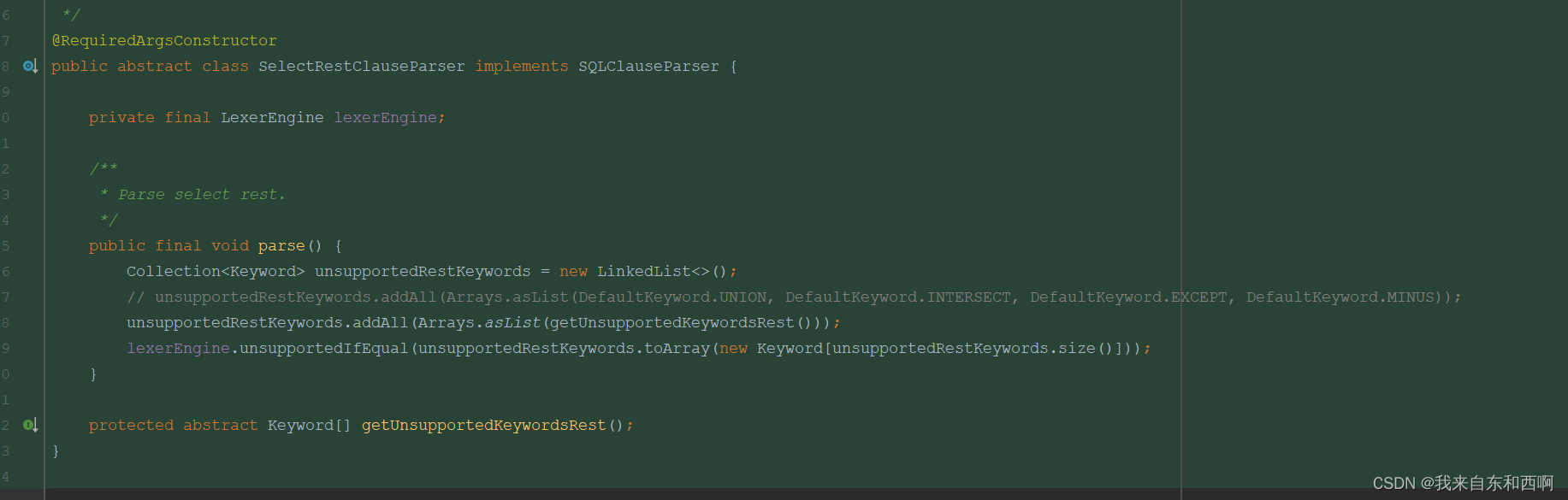
但是好景不长,越点系统,越多sql解析错误,等不知名异常。我直接奔溃了,大骂shardingJdbc。为什么mysql数据库没有问题,适配oracle这么多。这马上要发包了,给我来这一出。就在我实在无奈时,我直接百度了shardingJdbc 原理。发现它代理了JDBC所有流程。当我们使用shardingJdbc时,其实是使用了sharding数据源,mybatis框架在获取数据源时,其实获取的是shardingjdbc数据源,从这个数据源获取到的connection连接对象就是sharding连接对象了,当然后续Statement等JDBC对象都是sharding的。所以才会出现这么多问题。
于是,我大开杀戒,将sharding数据源 和 原生数据源 包装成Spring动态数据源。最终注入容器中就只有一个数据源,就是Spring的动态数据源。然后我利用Mybatis的Plus拦截插件机制,拦截Mybatis获取数据源流程,去判断本次流程的sql语句,如果是分表逻辑的sql,我直接给它sharding数据源,否则都采用原生数据源。后来就没有那么多七七八八的sql解析异常了。
代码如下:
1. 注入Spring动态数据源。
在项目的ShardingJdbc自动配置类中,之前这里是直接return sharding数据源,现在我return 动态数据源。
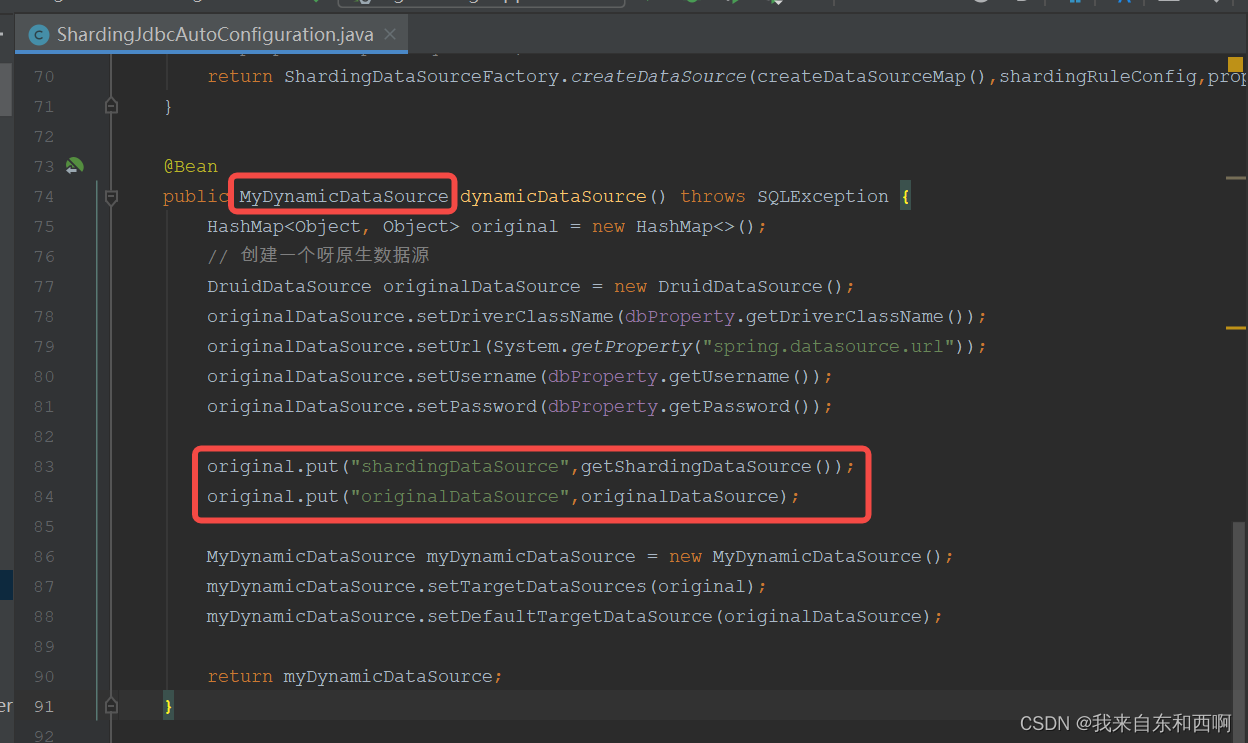
以下是 自定义动态数据源 (Spring 会回调 determineCurrentLookupKey(), 通过key 去map中找对应的数据源给你用。所以通常我们都是利用ThreadLocal去让当前线程选择使用key选择使用)
/*** 自定义路由数据源* 在ShardingJdbcAutoConfiguration中像ioc容器中注入了 MyDynamicDataSource* MyDynamicDataSource.targetDataSources中持有shardingDataSource & 普通DataSource* 最终Spring中就只有一个路由数据源MyDynamicDataSource。** Mybatis采用哪个数据源去连接数据库全靠DataSourceKeyHolder里面的ThreadLocal的value是什么。* 如果是originalDataSource---》就选择普通数据源* 如果是shardingDataSource---》就选择shardingDatasource* 从而去避免只使用shardingDataSource导致的一些sql语句不兼容问题。** 而DataSourceKeyHolder.ThreadLocal.value 我们是借助mybatis提供的Pluin插件机制来设置值。* 我们只需要在Mybatis获取数据源前,设置一下DataSourceKeyHolder.ThreadLocal.value即可。* 而这个时机,Mybatis提供的Pluin插件机制正好满足我们。** @author zihao.deng*/
public class MyDynamicDataSource extends AbstractRoutingDataSource {@Overrideprotected Object determineCurrentLookupKey() {return DataSourceKeyHolder.getKey();}
}public class DataSourceKeyHolder {private static final ThreadLocal<String> keyHolder = new ThreadLocal<>();public static void setKey(String key) {keyHolder.set(key);}public static String getKey() {String s = keyHolder.get();return s;}public static void clear(){keyHolder.remove();}
}2. 编写Mybatis 插件类
直接拦截Mybatis中的Executor体系,把CRUD都拦截主。判断sql语句是否走分表逻辑。如果走,就将ThreadLocal中的值变成 sharding数据源的key。
@Intercepts({@Signature(type = Executor.class, method = "update",args = {MappedStatement.class, Object.class}),@Signature(type = Executor.class, method = "query",args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),@Signature(type = Executor.class, method = "query",args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
@Slf4j
public class DynamicallyDataSourcePlugIn implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {Object[] args = invocation.getArgs();if(args[0] instanceof MappedStatement) {MappedStatement ms = (MappedStatement) args[0];BoundSql boundSql = ms.getBoundSql(wrapCollection(args[1]));String sql = boundSql.getSql();if(sql!=null && sql.contains("ogw_session_detail")){log.info("走分表...选择shardingDataSource...");DataSourceKeyHolder.setKey("shardingDataSource");}else{DataSourceKeyHolder.setKey("originalDataSource");}}return invocation.proceed();}private Object wrapCollection(final Object object) {return ParamNameResolver.wrapToMapIfCollection(object, null);}
}3. 补充下Mybatis插件机制原理:
在mybatis体系中,所有的curd都是通过sqlSession去操作。而sqlSession其实是委托给了Executor体系去完成。而Executor体系的实现类中,通常都是使用SimpleExeucutor。所以直接定位到SimpleExecutor类中。如本次以selectList() 查询为例子:
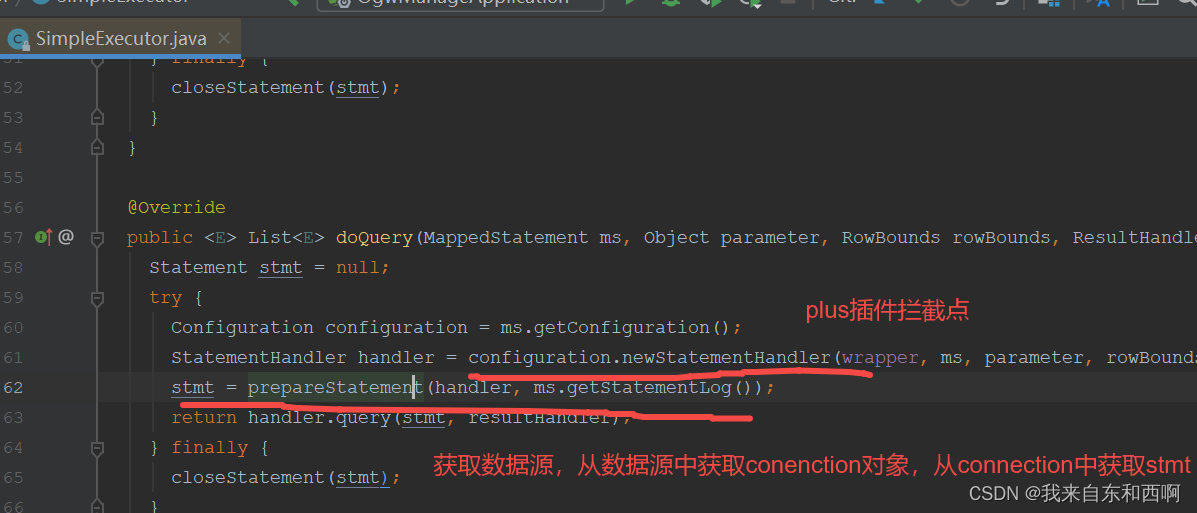
先看 prepareStatement(handler, ms.getStatementLog());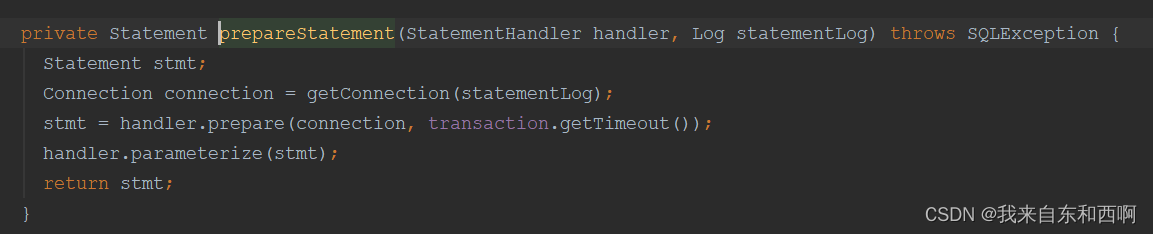
在prepareStatement() 中,会从Spring中获取一个数据源,在从数据源中获取connection连接对象,在通过Connection对象获取stamt对象。(里面逻辑不看了,就是这么个理)所以我们只需要在此处拦截,做一个获取数据源的判断即可。
在看 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
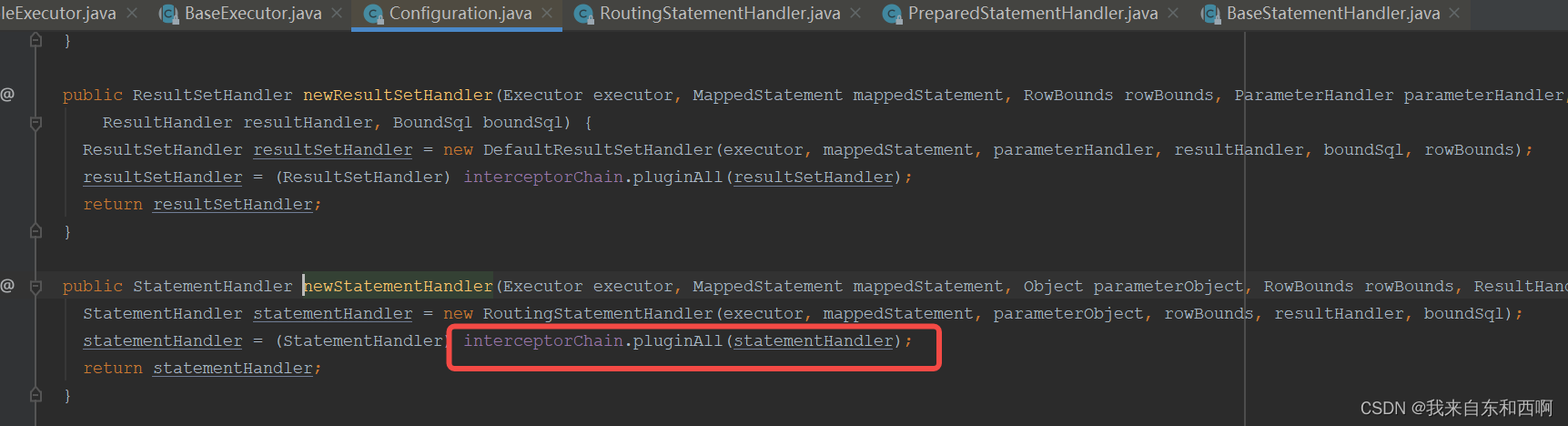
正好满足我们的需求,在获取数据源前应用插件机制。
其实插件机制的切入点,不止在这里,还有后续Statement执行时切入等,我都忘记了。只是突然想到了这里。
所以对于这些技术,原理真的非常重要,如果不去学习,出现这种问题,压根无从下手,学了源码等,就会知道很多扩展点,有多问题都是可以通过扩展点去解决的。
这篇关于sharding-jdbc-按日分表 解决它不支持部分sql的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






