本文主要是介绍#从零开始# 在深度学习环境中,如何用 pycharm配置使用 pipenv 虚拟环境,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为Python项目创建虚拟环境
在深度学习环境和一般python环境中安装pipenv基本一致,只需要确认好pipenv指定的python版本即可,安装pipenv前,可以通过python --version来确认安装版本

快捷键:crtl + alt + S 查看interpreter,查看所有的python环境
(1)点击add 查看所有环境,选中系统python环境,注意一定要查看python的版本。如果python版本和你pipenv指定的python版本不一致,会出现报错。
比如我之前装的python 3.10,但由于我用的LLM应用的python版本为3.11,即pipenv python 版本为3.11,就会出现报错,但它默认需要python 3.11的版本,所以我移除了原本的3.10版本,选择了升级python 版本。然后才能进行pipenv配置。


为Python项目创建虚拟环境
1.1 安装 pipenv
pip install pipenv1.2 创建虚拟环境
跳转到项目文件夹打开cmd窗口并输入以下代码
pipenv install 1.3 为虚拟环境安装指定包
pipenv install numpy如果使用默认安装源,大多数情况下会卡在locking阶段,解决办法:
更改安装源,修改项目文件夹下的Pipfile文件中 url 后边的内容
使用 –skip-lock 参数跳过lock过程
激活虚拟环境
pipenv shell
2 在Pycharm端更改python解析器
进入pycharm 依次点击 File->Setting
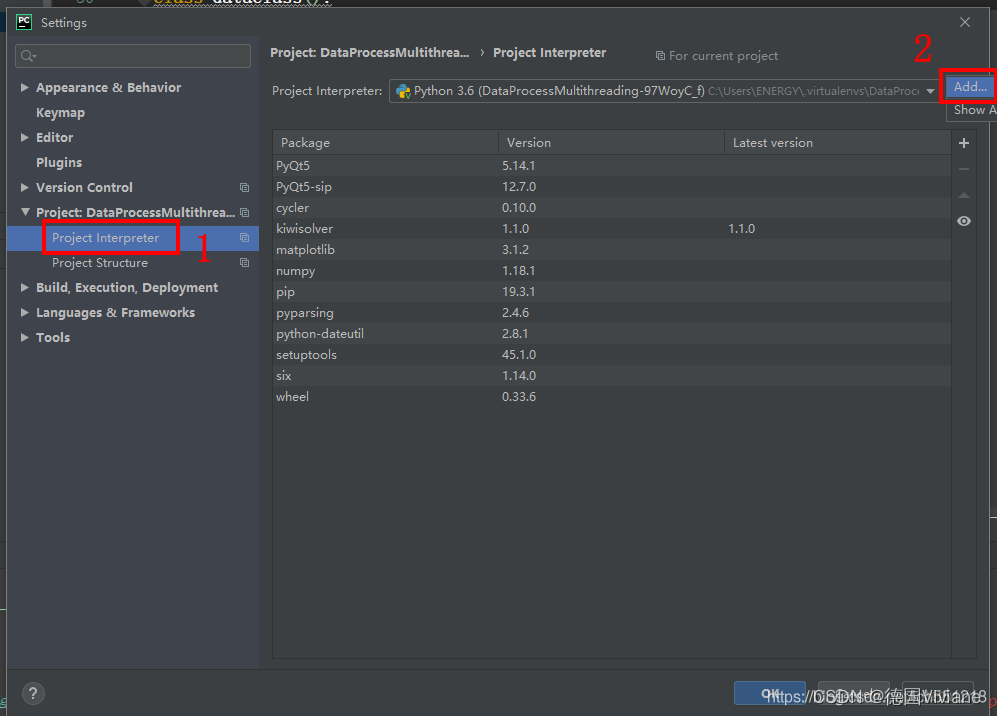
在跳出的页面依次选择 Virtualenv Environment->Existing environment
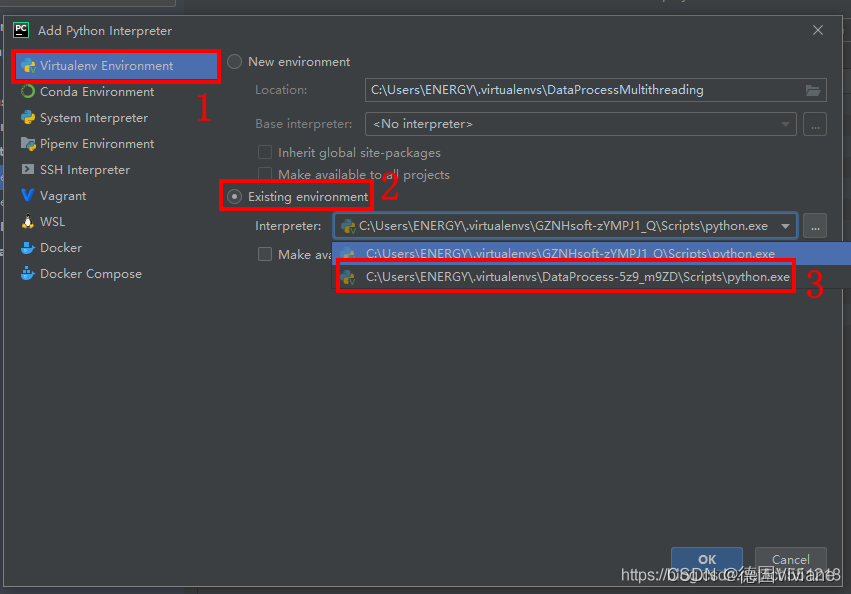
然后在Interpreter选择虚拟环境的解析器(默认系统会自动识别所有已经创建的虚拟环境解析器,如没有成功识别可以使用 pipenv --venv 查看虚拟环境解析器位置)
最后在Setting界面选择相应的虚拟环境即可
部分参考链接:https://blog.csdn.net/lch551218/article/details/104052993
拓展阅读:为甚麽要指定python版本?

这篇关于#从零开始# 在深度学习环境中,如何用 pycharm配置使用 pipenv 虚拟环境的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







