本文主要是介绍中文短文本关键词抽取方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 前言
- 2. 数据
- 3. 方案
- 3.1 SIFRank
- 3.2 NegSamplingNER
- 4. 代码
1. 前言
本文提出一种中文短文本关键词抽取方案,适用于无监督语料场景。
无监督关键词抽取算法虽然无需标注语料,但是效果一般。有监督学习方法效果好但是需要标注数据,很多业务场景下并没有标注好的数据。能否结合无监督学习方法和有监督学习方法的长处,用无监督方法标注语料,然后用于训练有监督方法?为此我们用实验证明了该方案是可行的,文末给出代码地址。
2. 数据
我们选用联通问答数据集中的问题数据,从问题中提取联通业务关键词。下载地址
3. 方案
首先使用SIFRank方法标注语料,然后训练NegSamplingNER命名实体识别模型。

3.1 SIFRank
无监督关键词抽取算法选用SIFRank。原方法使用ELMO语言模型得到词向量和句向量,我们将其替换为RoBerta模型。原方法使用清华的分词工具thulac,我们对比了jieba、thulac、百度lac和哈工大LTP四种工具,发现LTP效果最好,于是我们选用LTP作为分词和词性标注工具。
SIFRank将名词和形容词+名词的组合视为候选关键词,使用语言模型得到每个词的向量,关键词中各个词向量加权得到关键词向量,同理句子中各个词向量加权得到句向量。关键词向量和句向量的cos值作为关键词得分。
SIFRank提取关键词的重要一点是词权重,可以使用他提供的词权重文件,也可以自行计算词权重。收集大规模问题语料,计算词频,再计算领域语料中的词频,可按照TFIDF方法计算词权重,也可以直接将词频倒数加上平滑项作为权重。
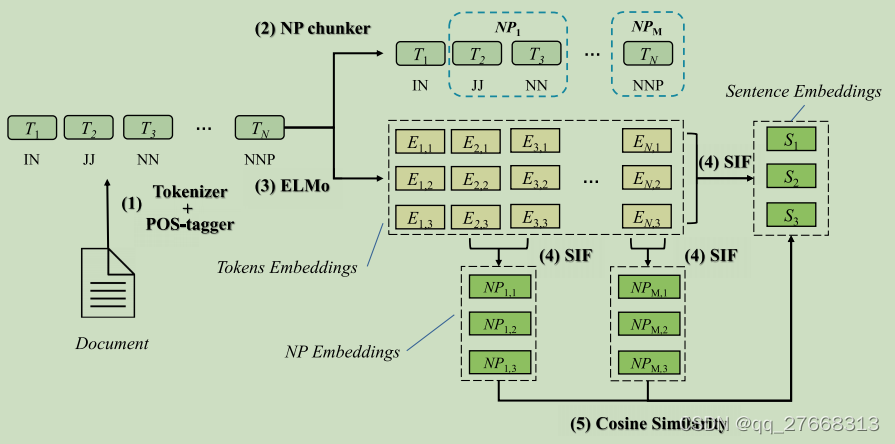
SIFRank流程如下图。
(1)分词+标词性。
(2)获取候选关键词列表:利用正则表达式确定名词短语(例如:形容词+名词),将名词短语作为候选关键短语。
(3)通过预训练语言模型,得到关键词的embedding。
(4)同样地,得到句子或文档的embedding。
(5)计算(3)与(4)结果的余弦相似度,选取topN作为其最终提取的关键词。
3.2 NegSamplingNER
用SIFRank去标注数据,为了让标注的词尽可能是正确的,每个句子我们只选取一个SIFRank输出的关键词。这样保证了标注的精确率,但是会导致很多漏标数据,这些漏标数据可视为噪声,用这样的数据去训练常规的命名实体识别模型显然是不可行的。
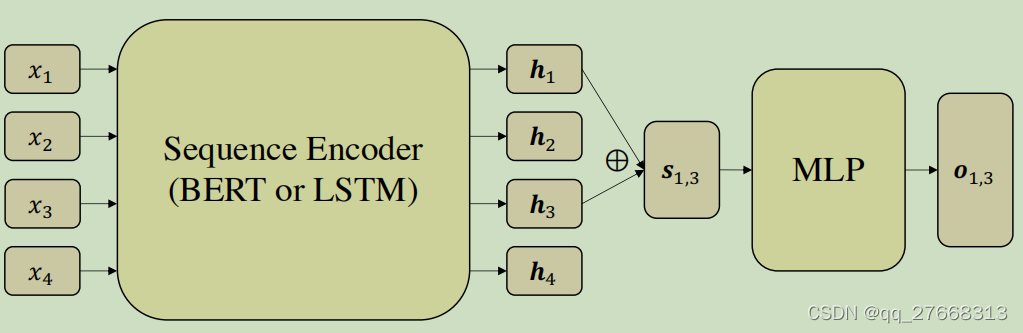
为此我们选择适用于远程监督数据的NER模型NegSamplingNER,该论文来自ICLR 2021。远程监督生成的NER数据集有个特点,标注的实体基本正确,但是存在大量漏标实体,这和我们用SIFRank生成的数据非常类似。NegSamplingNER采用BERT+span classifier结构,负样本通过随机采样片段得到,因此有很大概率噪声不会被采样,这也就避免了噪声影响。
NegSamplingNER结构如下图。编码器的输入输出和常规方法相同。采样过程就是随机挑选一个起始位置和一个结束位置,作为一个负样本,将起始位置和结束位置的向量拼接得到负样本表征。正样本的表征也是将起始位置和结束位置的向量拼接得到。将正负样本向量表征输入MLP分类,得到每个样本的类型,负样本的类型为‘O’。
4. 代码
本文开源代码:https://github.com/wjx-git/KeyWordsExtraction,需要自行下载预训练语言模型RoBerta。
这篇关于中文短文本关键词抽取方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







