本文主要是介绍Linux---进程间通信 | 管道 | PIPE | MKFIFO | 共享内存 | 消息队列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
管道
管道是UNIX中最古老的进程间通信的形式,我们把从一个进程连接到另一个进程的数据流称为一个管道。
一个文件,可以被多个进程打开吗?可以,那如果一个进程打开文件,往文件里面写数据,另一个进程打开文件,读取文件里面的数据。这样可以把文件写到磁盘上,进行读写操作。在之前,我们就用过管道的操作。
ps -ajx | head -1比如说这个查看进程的指令。在进程那篇文章里进程使用。

ps -ajx是一个指令,在运行的时候就变成了一个进程。head -1也会变成一个进程。| 是管道。
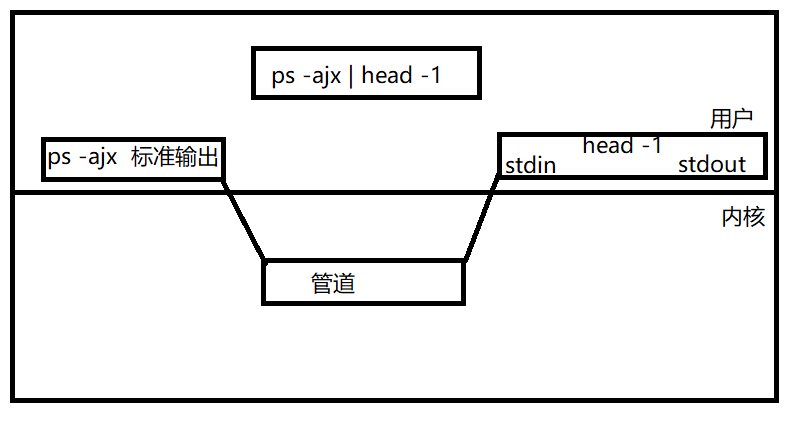
曾经我们说过,每一个进程都有一个tack_struct,每一个文件再打开的时候,会有文件描述符,文件描述符在文件描述符表中。task_struct 中会有指针指向文件描述符表。

进程打开文件的之后,都要有struct file对象。默认会打开三个文件---标准输入,标准输出,标准错误。
再打开一个新文件的时候,系统会自动的查找文件描述符表,将最小的文件描述符给新打开的文件。
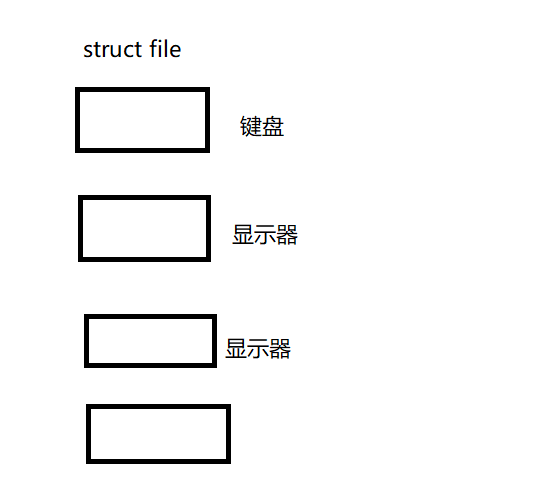
将新打开的文件的地址填入到文件描述符表中,然后将3号位置返回给fd。
进程间通信的本质前提是需要先让不同的进程,看到同一份资源。这样就可以完成进程间的通信了。
管道其实就是文件,只不过,这个文件不是磁盘文件。
既然父子进程之间资源是共享的,那么子进程关闭fd=0的文件,子进程会受到影响吗?其实不会,因为struct file中是存在一个引用计数器的概念的。
匿名管道
父进程想写数据,就把读端关掉了,子进程要读数据,就把写端关掉了,这样就形成了一个单项连同的管道了。
include <unistd.h>
功能:创建一无名管道
原型
int pipe(int fd[2]);
参数
fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码#include <iostream>
#include <unistd.h>int main()
{int fd[2];pipe(fd);pid_t id = fork();if (id > 0){close(fd[0]);std::string msg = "hello world";write(fd[1], msg.c_str(), msg.size());}else if (id == 0){close(fd[1]);char msg[1024];read(fd[0], msg, 1024);std::cout << std::string(msg) << std::endl;}return 0;
}
这样就能完成两个进程间的通信了。
但是,pipe只能完成具有血缘关系(父子,爷孙,兄弟,只不过常用来完成父子间的通信)的进程通信。因为父子间的资源是共享的,两个互不相干之间的资源可不是共享的。
代码中的管道是没有名字的,所以称他为匿名管道。
管道的特征
- 具有血缘关系的进程进行进程间通信
- 管道只能单向通信
- 父子进程是会进程协同的,同步与互斥的 --- 保护管道文件的数据安全
- 管道是面向字节流的
- 管道是基于文件的,而文件的生命周期是随进程的
管道的四种情况
- 读写端正常,管道如果为空,读端就要阻塞
- 读写段正常,管道如果被写满,写端就要阻塞
- 读端正常读,写端关闭,读端就会读到0,表明读到了文件pipe结尾,不会被阻塞
- 写端正常写入,读端关闭了。操作系统就要杀掉正在写入的进程。(通过信号杀掉)
命名管道
| 是一种管道,还有一种管道是 mkfifo
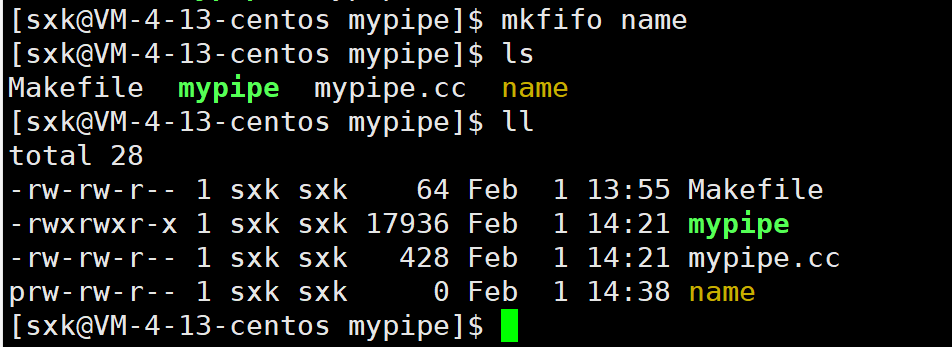
mkfifo可以完成两个互不相关进程间的通信。

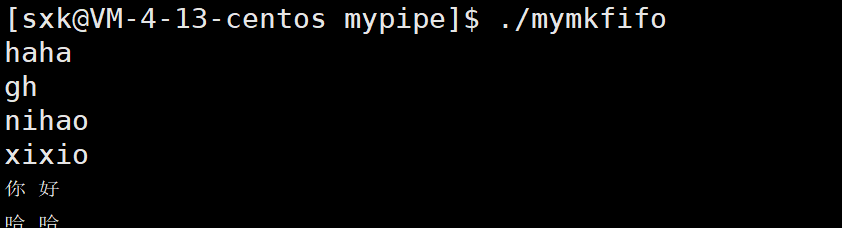
创建管道文件后往管道文件中写内容,会造成阻塞。

此时我们通过另一个窗口将管道中的数据读取出来,阻塞的那一端也会放开。

#include<sys/types.h>
#include<sys/stat.h>
int mkfifo(const char * pathname,mode_t mode);
参数一:创建管道的名字
参数二:文件的权限
返回值:成功0,失败-1#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>int main()
{// 创建管道文件int n = mkfifo("MYMKFIFO", 0664);if (n < 0){std::cerr << "mkfifo" << std::endl;exit(-1);}// 打开文件int fd = open("MYMKFIFO",O_RDWR);if (fd < 0){std::cerr << "open" << std::endl;}// 向管道文件中写入内容std::string line;while (true){std::cout << "Please Enter@ ";std::cin >> line;write(fd, line.c_str(), line.size());}close(fd);// 删除管道sleep(5);n = unlink("MYMKFIFO");if (n < 0){std::cerr << "unlink" << std::endl;exit(-1);}return 0;
}#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>int main()
{int fd = open("MYMKFIFO", O_RDWR);if (fd < 0){std::cerr << "open" << std::endl;exit(-1);}std::string line;while (true){char buf[1024];int n = read(fd, buf, 1024);if (n == -1){break;}std::cout << std::string(buf) << std::endl;}close(fd);return 0;
}.PHONY:all
all:mypipe mymkfifo
mypipe:mypipe.ccg++ -o $@ $^
mymkfifo:mymkfifo.ccg++ -o $@ $^.PHONY:clean
clean:rm mypipe mymkfifo
这样,就完成了两个进程间的通信。

共享内存
每一个进程都有自己对应的内核数据结构,内核数据结构中的指针指向一个页表,通过页表的映射关系来找到物理内存,另一个进程也是通过页表的映射,来找到物理内存,那么理论上这两个进程就可以找到物理内存中的同一块内存来完成共享内存。当然,这些操作不会是进程直接做的,是由操作系统来完成。如何管理共享内存呢?先描述,在组织。
这块共享内存有多少进程关联起来了?这块内存多大?这就由一个内核结构体来描述共享内存了,经过操作系统操作后,最后都会变成对某一个数据结构的增删查改。
下面就是对一些函数的理解了。
shmget(创建共享内存)
功能:用来创建共享内存
原型
int shmget(key_t key, size_t size, int shmflg);
参数
key:这个共享内存段名字
size:共享内存大小(单位是字节)
shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1IPC_CREAT(单独使用):如果你创建的共享内存不存在,就创建,存在,就获取并返回。IPC_CREAT | IPC_EXCL:如果你创建的共享内存不存在,就创建,存在,就出错返回。确保如果我们申请陈工了一个共享内存,这个共享内存一定是一个新的IPC_EXCL:不单独使用其实还有点问题,如何知道这个共享内存是否存在?如果保证让不同的进程看到同一个共享内存呢?
通过key这个参数可以完成。
- key是一个数字,这个数字是几,不重要。关键在于它必须在内核中具有唯一性,能够让不同的进程进行唯一性标识。
- 第一个进程可以通过key创建共享内存,第二个之后的进程,只要拿着同一个key 就可以和第一个进程看到同一个共享内存了。
- 对于一个已经创建好的共享内存,key在哪?共享内存是由操作系统创建的,操作系统要对共享内存进行管理,所以key在共享内存的描述对象中。
- 第一次创建的时候,必须有一个key了。如何形成一个key?通过ftok这个系统调用接口。
- key跟路径有点类似,是唯一的。

这个ftok不会在内存中去遍历key,找到一个没有使用过的key,它内置的有一套算法,由pathname和proj_id进行了数值计算即可。这两个参数由用户自己决定。
#include "comm.hpp"int main()
{int shmid = CreateShm();return 0;
}#ifndef __COMM_HPP__
#define __COMM_HPP__#include <iostream>
#include <string>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <cstring>
#include <unistd.h>
#include "/home/sxk/mylog/log.hpp"const std::string pathname = "/home/sxk";
const int proj_id = 0x777777;
const int size = 4096;key_t GetKey()
{/*通过ftok创建出一个唯一的key*/key_t k = ftok(pathname.c_str(), proj_id);if (k < 0){std::cerr << "ftok fail" << std::endl;exit(1);}std::cout << "ftok success, key :" << k << std::endl;return k;
}int GetShareMemHelper(int flag)
{/*用key创建出一块共享内存*/key_t k = GetKey();int shmid = shmget(k, size, flag);if (shmid < 0){std::cerr << "shmget fail" << std::endl;exit(2);}std::cout << "ftok success, shmid :" << shmid << std::endl;return shmid;
}int CreateShm()
{return GetShareMemHelper(IPC_CREAT | IPC_EXCL | 0666);
}int GetShm()
{return GetShareMemHelper(IPC_CREAT);
}#endif.PHONY:all
all:proca procbproca:proca.ccg++ -o $@ $^ -g -std=c++11
procb:procb.ccg++ -o $@ $^ -g -std=c++11.PHONY:clean
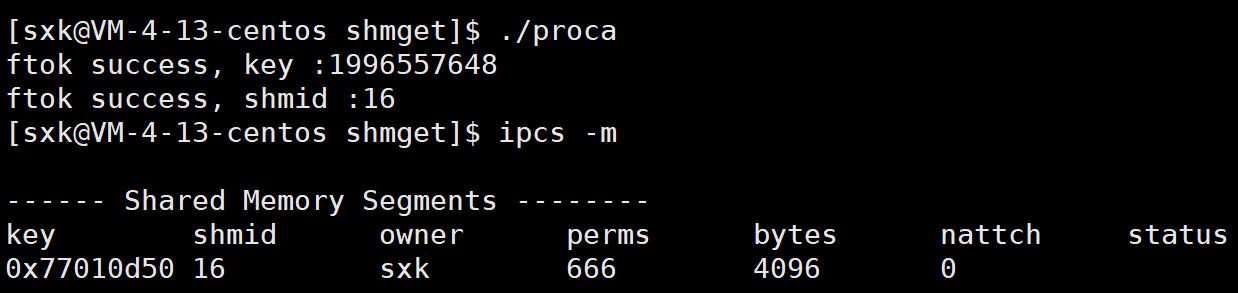
clean:rm -f proca procb运行之后可以发现,key为1996557648,操作系统内标定的唯一性,shmid为15,只在你的进程内,用来表示资源的唯一性。

当我们再次运行这个程序的时候,就会出现错误。

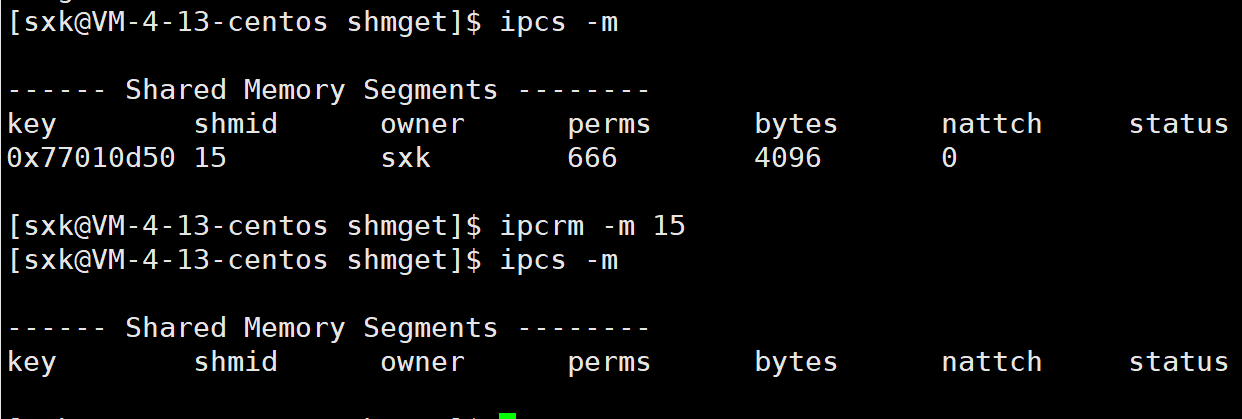
通过 ipcs -m可以查看共享内存资源。

此时可以看到,我们的进程已经退出了,但是资源还是存在。说明用户如果不主动关闭,共享内存会一直存在。除非内核重启或者用户关闭。
通过 ipcrm -m可以删除共享内存资源。 ipcrm -m shmid
关掉之后在运行代码。
共享内存在创建的时候还有一个权限的问题,毕竟总会存在不同的进程对数据有不同的需求。
所以在shmget的时候,可以shmget(k, size, IPC_CREAT | IPC_EXCL | 0666),0666跟open打开文件,若文件不存在则创建文件的权限设置一样。
共享内存的大小一般建议是4096的整数倍。如果大小给4097,实际上操作系统给你的是4096 * 2的大小。
shmat(挂接)
功能:将共享内存段连接到进程地址空间
原型
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数
shmid: 共享内存标识
shmaddr:指定连接的地址
shmflg:它的两个可能取值是SHM_RND和SHM_RDONLY
返回值:成功返回一个指针,指向共享内存第一个节;失败返回-1(跟malloc有点相似)---
shmaddr为NULL,核心自动选择一个地址(一般设置为null就行)
shmaddr不为NULL且shmflg无SHM_RND标记,则以shmaddr为连接地址。
shmaddr不为NULL且shmflg设置了SHM_RND标记,则连接的地址会自动向下调整为SHMLBA的整数倍。公式:shmaddr -
(shmaddr % SHMLBA)
shmflg=SHM_RDONLY,表示连接操作用来只读共享内存#include "comm.hpp"int main()
{int shmid = CreateShm();std::cout << "creat shm done" << std::endl;sleep(3);char * shmaddr = (char*)shmat(shmid, nullptr, 0);sleep(5);return 0;
}添加挂接之后。

会发现,nattch由0变成1,nattch代表的就是挂接数量。
shmdt(脱离)
功能:将共享内存段与当前进程脱离
原型
int shmdt(const void *shmaddr);
参数
shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段既然能挂接,那么也一定可以脱离。
#include "comm.hpp"int main()
{int shmid = CreateShm();std::cout << "creat shm done" << std::endl;sleep(3);char * shmaddr = (char*)shmat(shmid, nullptr, 0);sleep(3);int n = shmdt((void*)shmaddr);if (n < 0){std::cerr << "shmdt fail " << std::endl;}sleep(5);return 0;
}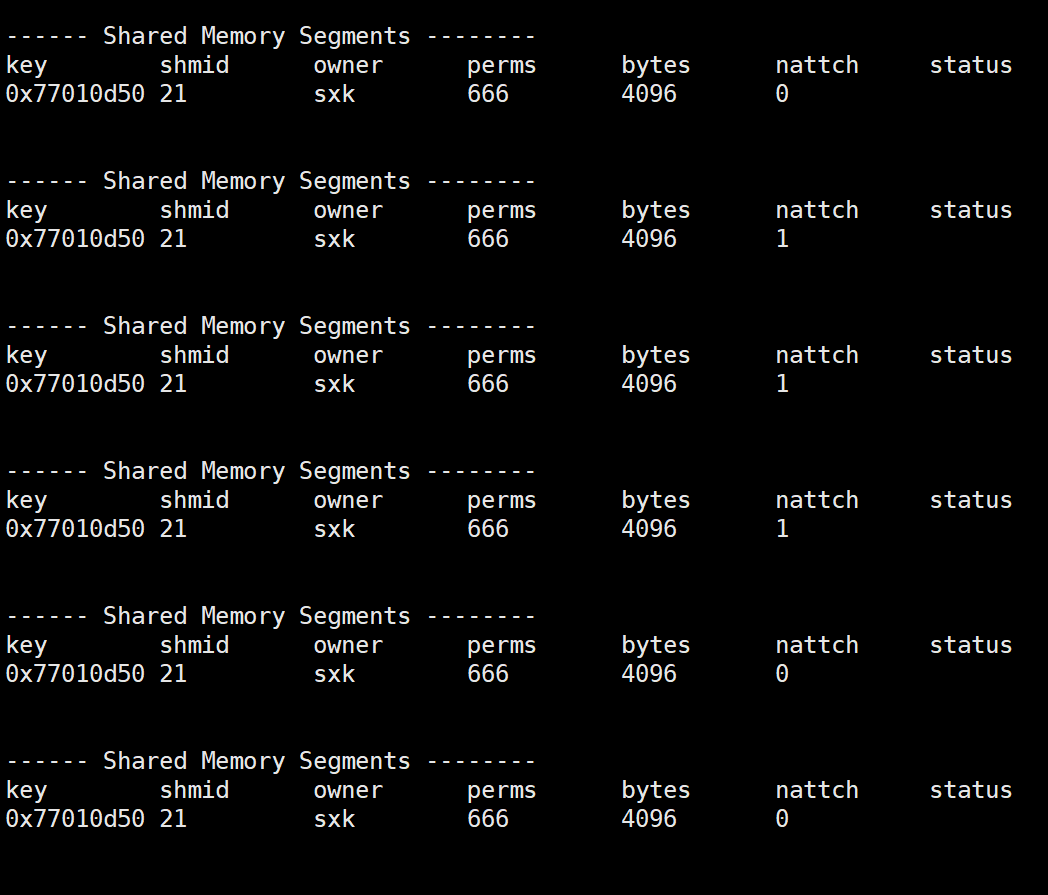
可以观察到,nattch由0->1->0。
shmctl
功能:用于控制共享内存
原型
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
shmid:由shmget返回的共享内存标识码
cmd:将要采取的动作(有三个可取值)
buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1| 命令 | 说明 |
| IPC_STAT | 把shmid_ds结构中的数据设置为共享内存的当前关联值 |
| IPC_SET | 在进程有足够权限的前提下,把共享内存的当前关联值设为shmid_ds数据结构中给出的值 |
| IPC_RMID | 删除共享内存段 |
#include "comm.hpp"int main()
{int shmid = CreateShm();std::cout << "creat shm done" << std::endl;sleep(3);char * shmaddr = (char*)shmat(shmid, nullptr, 0);sleep(3);int n = shmdt((void*)shmaddr);if (n < 0){std::cerr << "shmdt fail " << std::endl;}sleep(5);shmctl(shmid, IPC_RMID, nullptr);return 0;
}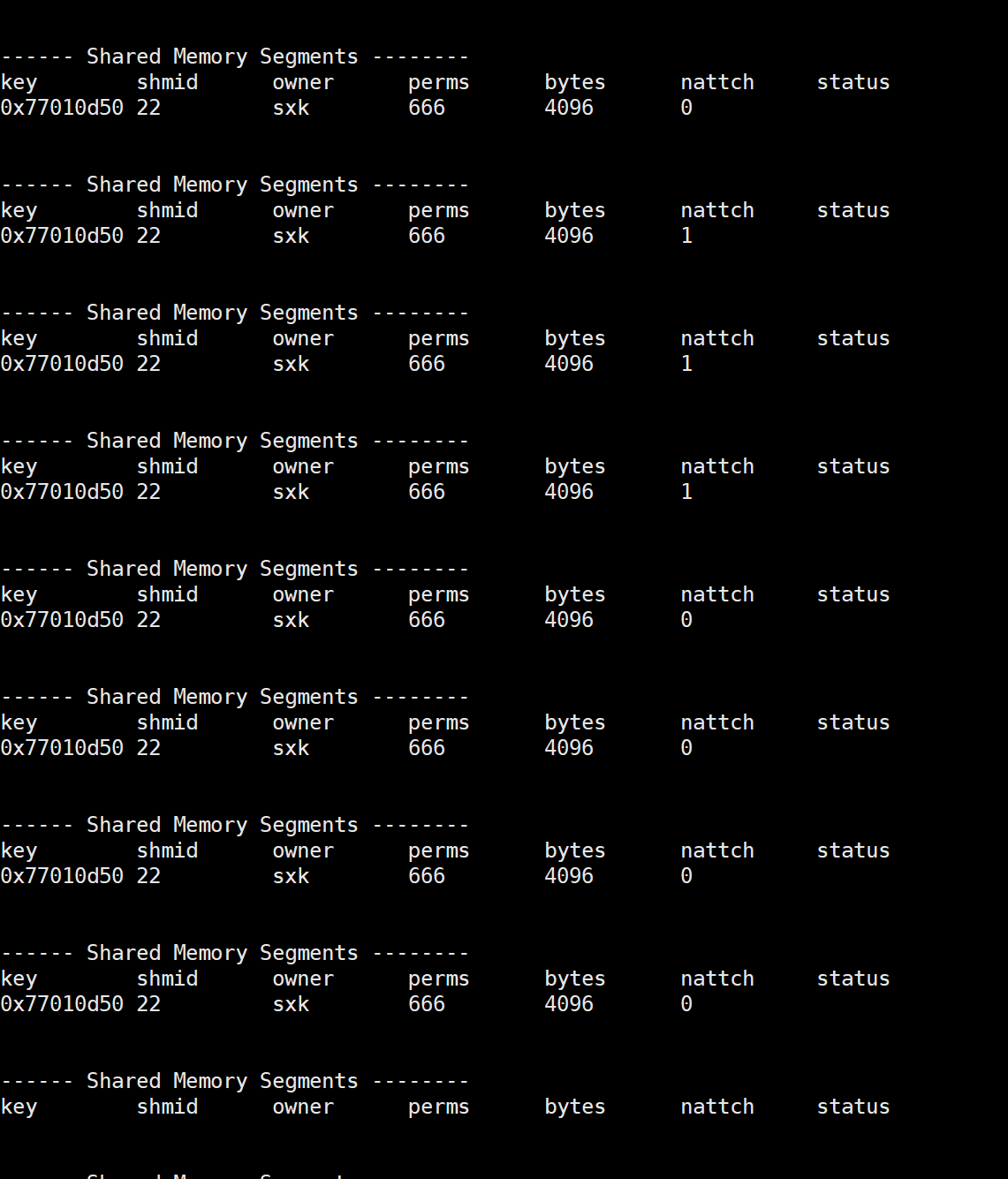
这样就完成了删除的操作。
实现两个进程间的通信
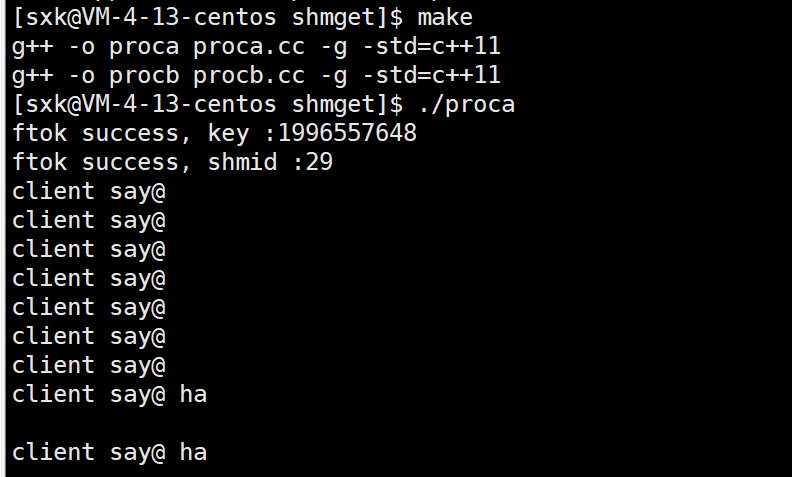
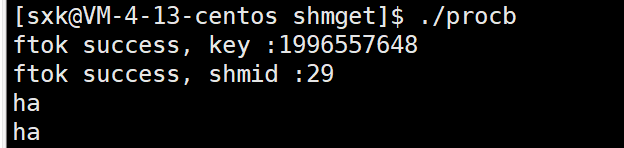
#include "comm.hpp"int main()
{int shmid = CreateShm(); char* shmaddr = (char*)shmat(shmid, nullptr, 0);if (*(int*)shmaddr == -1){perror("shmat");exit(-1);}while (true){std::cout << "client say@ " << shmaddr << std::endl;sleep(1);}shmdt((void*)shmaddr);shmctl(shmid, IPC_RMID, nullptr);return 0;
}#include "comm.hpp"int main()
{int shmid = GetShm(); char* shmaddr = (char*)shmat(shmid, nullptr, 0);if (*(int*)shmaddr == -1){perror("shmat");exit(-1);}while (true){fgets(shmaddr, 4096, stdin);}shmdt((void*)shmaddr);return 0;
}
共享内存的特性
- 共享内存没有同步互斥之类的保护机制
- 共享内存是进程间通信中,速度最快的
- 共享内存内部的数据,由用户自己维护
SISTEM V 消息队列
所谓的消息队列,还是由操作系统创建的。
要想通过消息队列进行通信,那么必须得先让两个进程看到同一份资源,这份资源可以是文件缓冲区或者内存块或者是队列。进程看到的资源不同,通信的方式也不同。
共享内存是先要让不同的进程看到同一块共享内存,也就是找到唯一的key,消息队列跟它一样,要先让两个不同的进程看到同一个队列。然后不同的进程可以向内核中发送数据块。那么,进程A发送数据块,进程B也发送数据块,如何区分AB进程的数据块呢?向内核中发送带类型的数据块。有了类型,就可以区分不同的进程了。这个队列是要由操作系统创建,当创建了n个消息队列之后,操作系统要对消息队列进行管理,其实就是对某一个数据结构的增删查改的管理。
msgget(创建)
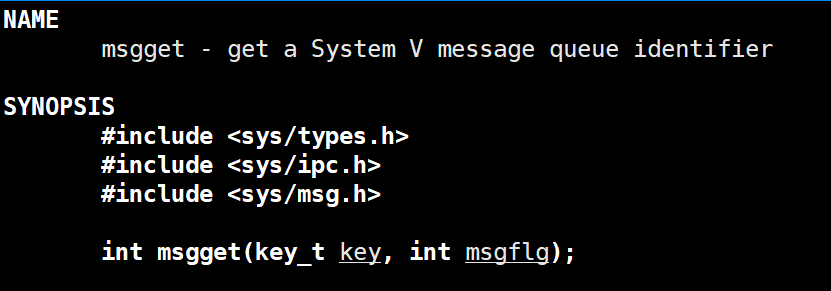
key如何来?还是通过ftok,msgflg的用法跟共享内存中的shmget参数中的msgflg用法一样。
返回值:
如果成功,返回所创建的消息队列的ID,失败则返回-1msgctl(删除)
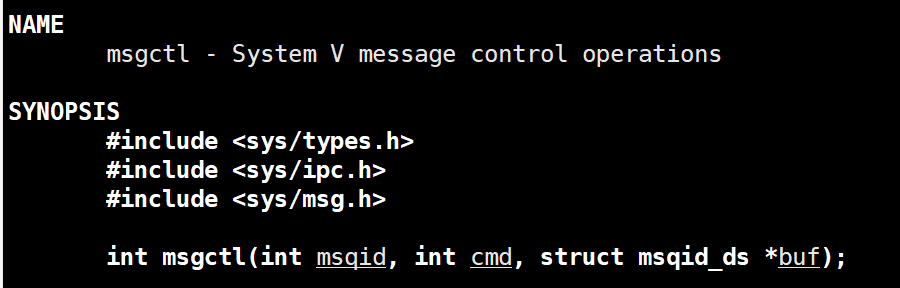
用法跟共享内存中的shmctl一样,用来删除共享内存的(第二个参数置为 IPC_RMID)。
msgsnd(发送数据块)
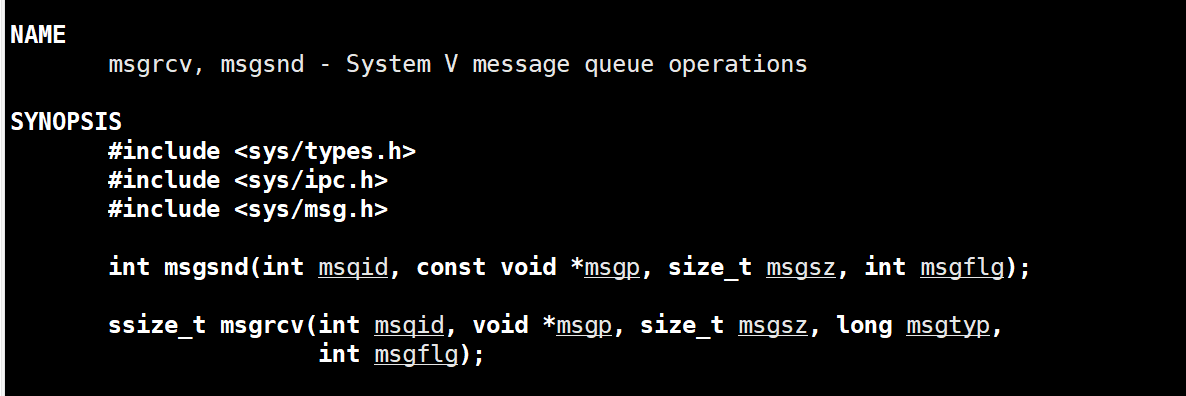
msgsnd
参数一:消息队列ID
参数二:提供对应的缓冲区,因为要发送数据
参数三:发送数据的大小
参数四:默认为0就行了msgrcv
参数一:消息队列ID
参数二:提供对应的缓冲区,因为要接受数据
参数三:接受数据的大小
参数四:对应的消息类型
参数四:默认为0就行了 消息队列的接口跟共享内存的接口用法基本类似。
通过 ipcs -q可以查看所创建的消息队列
通过 ipcrm -q可以删除所创建的消息队列
这篇关于Linux---进程间通信 | 管道 | PIPE | MKFIFO | 共享内存 | 消息队列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







