本文主要是介绍opencv0014 索贝尔(sobel)算子,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前面学习的滤波器主要是用来模糊图像,今天一起来了解关于边缘识别的滤波吧!嘿嘿

边缘
边缘是像素值发生跃迁的位置,是图像的显著特征之一,在图像特征提取,对象检测,模式识别等方面都有重要的作用。
人眼如何识别图像边缘?
比如有一幅图,图里面有一条线,左很亮,右边很暗,那人眼就很容易识别这条线作为边缘也就是图像的灰度值快速变化的地方.
soble算子

sobel算子对图像求一阶导数。一阶导数越大,说明像素在该方向的变化越大,边缘信号越强。
因为图像的灰度值都是离散的数字,sozbel算子采用离散差分算子计算图像像素点亮度值的近似梯度.
图像是二维的,即沿着宽度/高度两个方向.
我们使用两个卷积核对原图像进行处理


这样的话,,我们就得到了两个新的矩阵,分别反映了每一点像素在水平方向上的亮度变化情况和在垂直方向上的亮度变换情况.
综合考虑这两个方向的变化,我们使用以下公式反映某个像素的梯度变化情况.
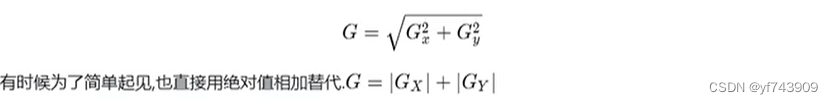
实例
计算x轴方向的梯度,只有垂直方向上的边缘
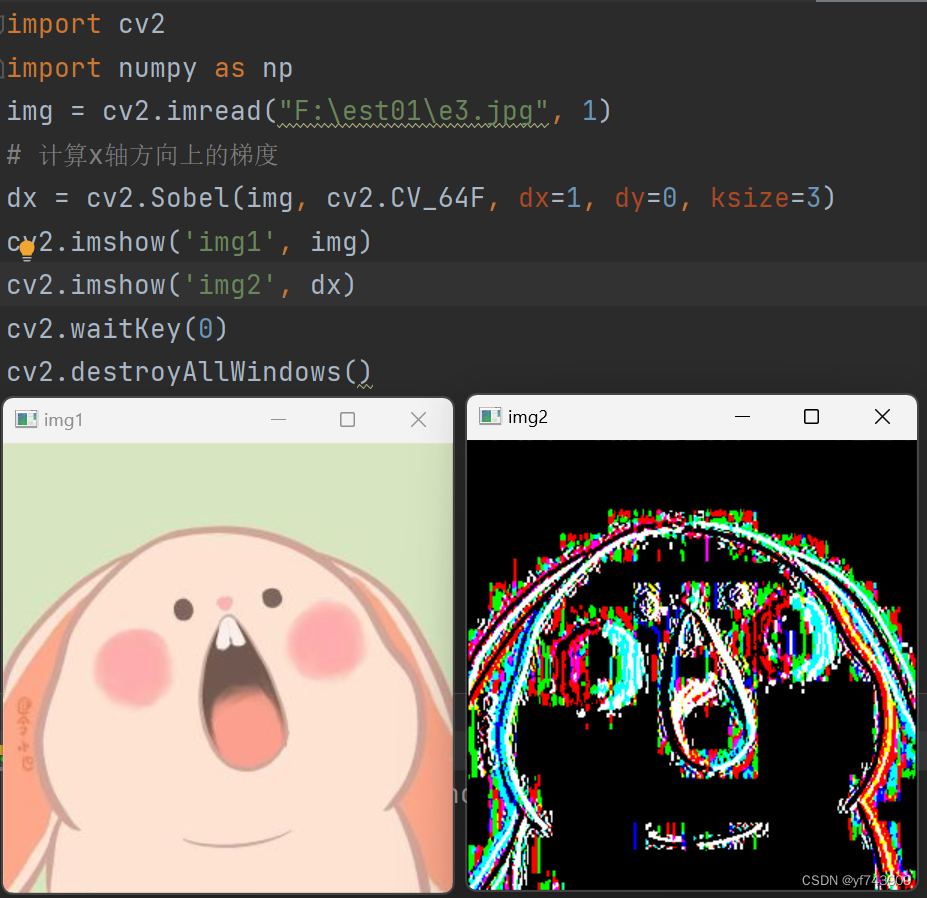
相似的,这是只有y轴的边缘
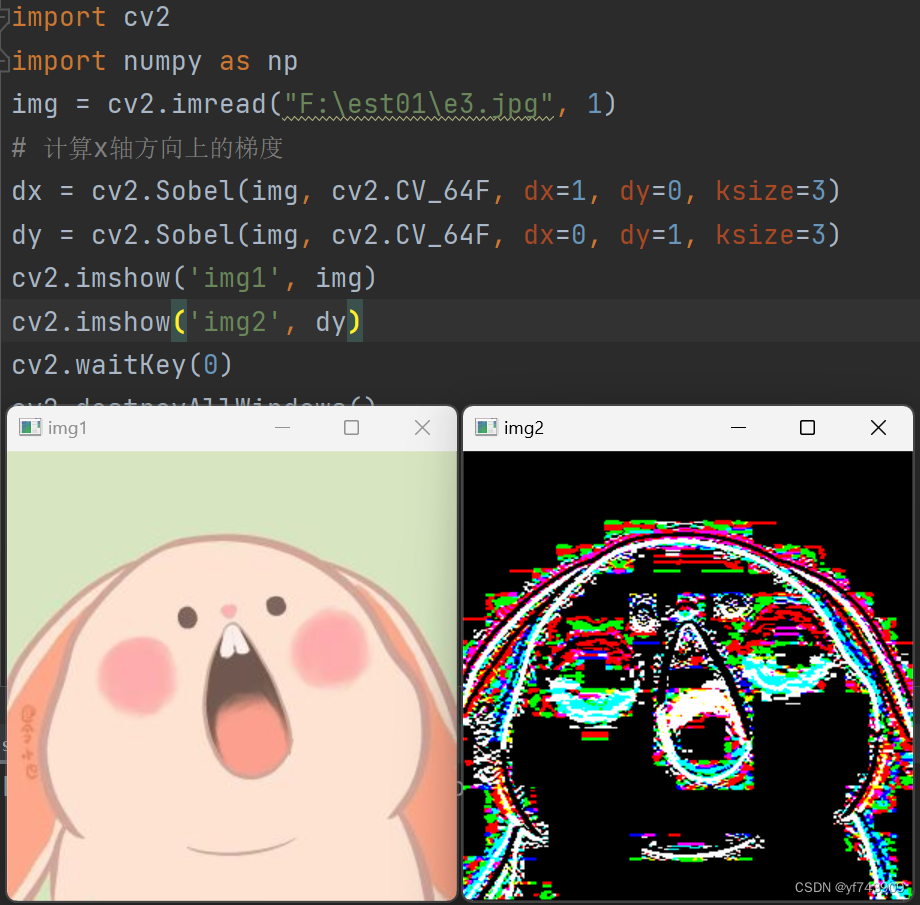
然后,把两个边缘拼到一起
这篇关于opencv0014 索贝尔(sobel)算子的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








