本文主要是介绍分布式存储GlusterFS与分布式一致性算法Raft,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、分布式存储GlusterFs
1、GlusterFs简介
Glusterfs是一个开源的分布式文件系统,它是将多个服务器的磁盘资源,通过网络互连成一个并行的网络文件系统。它具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千个客户端。它是无中心节点(所有节点全部平等),让整个服务器没有单点故障的隐患,具有配置方便、高性能、高可用性、可扩展性等特点。
当客户端访问GlusterFS存储时,首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地还是在远程服务器上。读写操作将会被交给VFS(Virtual File System)来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client的计算,并最终经过网络将请求或数据发送到GlusterFS Server上。
2、GlusterFs常用卷类型
分布式卷(distributed):
将文件随机分布在存储卷中的各个块(Bricks)中,使用哈希算法随机存储。分布式卷具有良好的扩展性,但不具备数据冗余能力,该能力需借助服务器软硬件(raid卡)实现。未指定任何卷类型的情况下,默认创建的卷的类型。
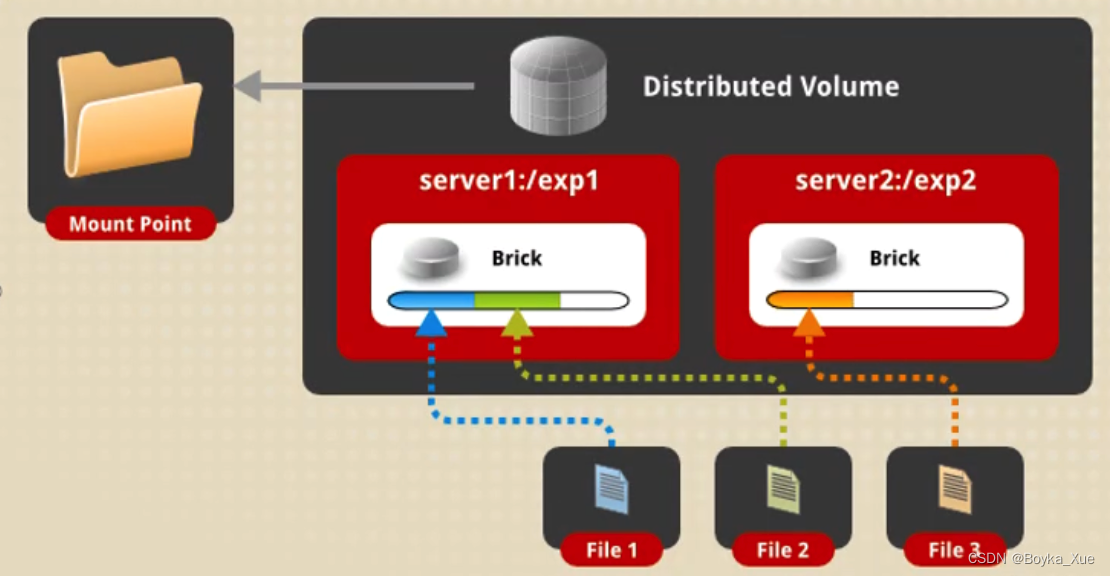
优点:读写性能好
缺点:如果存储或服务器故障,该brick上的数据将丢失
应用场景:大量小文件
创建分布式卷命令格式如下:
#gluster volume create test-volume server1:/exp1 server2:/exp2
复制卷(Replicated):
通过存储卷中的多个块(Bricks)建立文件的副本。在创建复制卷时,块数量应当等于副本数量,为防止服务器及磁盘故障,每个块都应当分布在独立的服务器上。复制卷提供数据的高可用性和高可靠性。
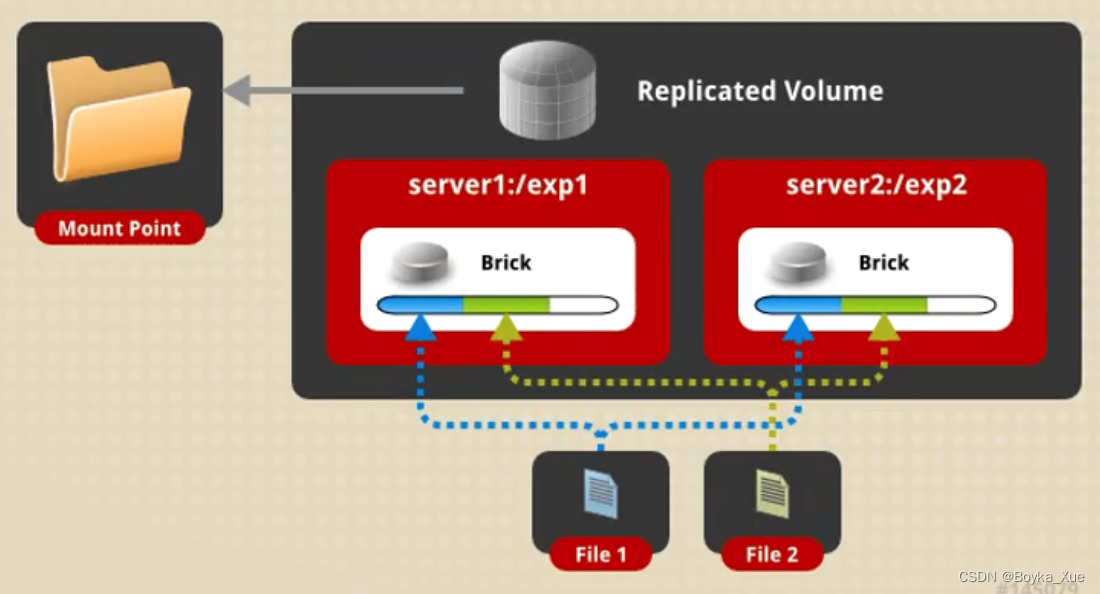
优点:读性能好
缺点:写性能差
应用场景:对可靠性高和读性能要求高的场景
创建复制卷命令格式如下:
#gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2
分布式复制卷(Distributed Replicated):
分布式卷和复制卷的集合,在创建分布式副本卷时,块(Bricks)数量最小应当为指定副本数量的整数倍。分布式副木卷可以提高文件读取性能。(企业中最长用的)
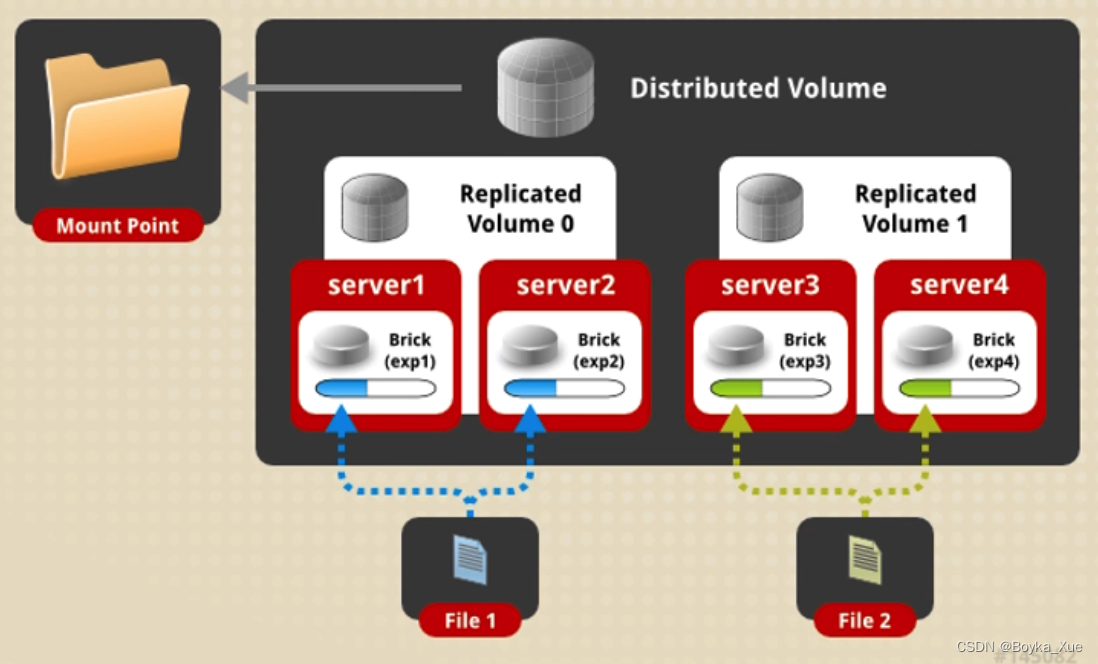
优点:高可靠、读性能高
缺点:牺牲存储空间、写性能差
应用场景:大量文件读和可靠性要求高的场景
创建分布式复制卷命令格式如下:
#gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
分散卷(Dispersed):基于纠错码,将文件编码后条带化分收存储在卷的多个块中,并提供一定冗余性。
分散卷可以提高磁盘存储利用率,但性能有所下降。分散卷中的元余值表示允许多少块失效而不中断对卷的读写操作。分散卷中的冗余值必须大于0,总块数应当大于2倍的元余值,也就意味着分散卷至少要由3个块组成。在创建分散卷时如果未指定冗余值,系统将自动计算该值并提示。
分散卷可用存储空间计算公式如下:
= * (#Bricks - Redundancy)
创建分散卷命令格式如下:
# gluster volume create test-volume [disperse [<COuNT>J] [disperse-data <COUNT>] redundancy <COUNT>] [transport tcp I rdma tcp,rdmal <NEW-BRICK>
以下为实机操作过程
服务器环境规划
| 主机名 | IP地址 | 操作系统 | 硬盘数量 |
|---|---|---|---|
| glusterfs01 | 192.168.81.240 | centos7.6 | /dev/sdb(10G) /dev/sdc(10G) |
| glusterfs02 | 192.168.81.250 | centos7.6 | /dev/sdb(10G) /dev/sdc(10G) |
| glusterfs03 | 192.168.81.136 | centos7.6 | /dev/sdb(10G) /dev/sdc(10G) |
3、安装GlusterFs
1)yum安装
[root@192 ~]# yum install centos-release-gluster -y
[root@192 ~]# yum install glusterfs-server -y2)启动glusterfs
所有节点都进行如下操作
[root@192 ~]# systemctl start glusterd.service
[root@192 ~]# systemctl enable glusterd.service
[root@192 ~]# mkdir -p /gfs/test1
[root@192 ~]# mkdir -p /gfs/test23)配置hosts解析
所有节点都进行如下操作
[root@glusterfs01 ~]# cat /etc/hosts
192.168.81.240 glusterfs01
192.168.81.250 glusterfs02
192.168.81.136 glusterfs03
4、关闭服务器防火墙
为了能让节点上的gluster进程可以相互通信,需要关闭防火墙。
[root@192 ~]# systemctl status firewalld.service 用于查看防火墙的状态
[root@192 ~]# systemctl stop firewalld.service 用于停止防火墙
[root@192 ~]# systemctl disable firewalld.service 用于禁止防火墙开机自启动
5、格式化硬盘并挂载
所有节点都进行以下操作
1.格式化
[root@192 ~]# mkfs.xfs /dev/sdb
[root@192 ~]# mkfs.xfs /dev/sdc2.获取磁盘UUID
这里我们将uuid写入fstab文件中,而不是磁盘名,防止下次重启机器读错盘符
[root@192 ~]# blkid /dev/sdb /dev/sdc
/dev/sdb: UUID="8835164f-78ab-4f6f-a156-9d3afd0132eb" TYPE="xfs"
/dev/sdc: UUID="6f86c2be-56cc-4e98-8add-63eb43852d65" TYPE="xfs"3.编辑/etc/fstab文件
[root@192 ~]# vim /etc/fstab
UUID="8835164f-78ab-4f6f-a156-9d3afd0132eb" /gfs/test1 xfs defaults 0 0
UUID="6f86c2be-56cc-4e98-8add-63eb43852d65" /gfs/test2 xfs defaults 0 04.挂载
[root@192 ~]# mount -a
[root@192 ~]# df -hT | grep gfs
/dev/sdb xfs 10G 33M 10G 1% /gfs/test1
/dev/sdc xfs 10G 33M 10G 1% /gfs/test2
6、添加存储资源池
资源池就相当于集群,往里面添加节点,默认有一个localhost
其中之一节点操作
查看当前的资源池列表
[root@glusterfs01 ~]# gluster pool list
UUID Hostname State
a2585b8c-7928-4480-9376-25c0d6e88cc0 localhost Connected增加glusterfs02和glusterfs03节点
[root@glusterfs01 ~]# gluster peer probe glusterfs02
peer probe: success.
[root@glusterfs01 ~]# gluster peer probe glusterfs03
peer probe: success. 增加完再查看
[root@glusterfs01 ~]# gluster pool list
UUID Hostname State
07502cd5-4c18-4bde-9bcf-7f29f2a68af7 glusterfs02 Connected
5c76e19c-6141-4e95-9446-b3a424cd5f6e glusterfs03 Connected
a2585b8c-7928-4480-9376-25c0d6e88cc0 localhost Connected
7、创建一个卷(以分布式复制卷为例)
企业中用的最多的就是分布式复制卷
分布式复制卷可以设置复制的数量,如replica设置的是2,那么就表示上传的文件会复制2份,比如上传10个文件实际上是上传了20个文件,起到一定的备份作用,这20个文件会随机分布在各个节点。
创建一个分布式复制卷
[root@glusterfs01 ~]# gluster volume create web_volume01 replica 2 glusterfs01:/gfs/test1 glusterfs01:/gfs/test2 glusterfs02:/gfs/test1 glusterfs02:/gfs/test2 force
volume create: web_volume01: success: please start the volume to access data[root@glusterfs01 ~]# gluster volume list
web_volume01// 上述命令行含义解释
gluster 命令关键字
volume 对卷进行操作
create 创建一个卷
web_volume01 卷名
replica 2 副本数
glusterfs01:/gfs/test1 表示glusterfs01节点上的/gfs/test1这个目录加入到卷里
force 强制生成
删除一个卷
先停止在删除
[root@glusterfs01 ~]# gluster volume stop web_volume01
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: web_volume01: success[root@glusterfs01 ~]# gluster volume delete web_volume01
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
项目演示,使用glusterfs01和glusterfs02创建一个分布式复制卷,并挂载在客户端glusterfs03上
1)添加存储资源
[root@glusterfs01 ~]# gluster peer probe glusterfs02
peer probe: success.
[root@glusterfs01 ~]# gluster peer probe glusterfs03
peer probe: success.
[root@glusterfs01 ~]# gluster pool list
UUID Hostname State
07502cd5-4c18-4bde-9bcf-7f29f2a68af7 glusterfs02 Connected
5c76e19c-6141-4e95-9446-b3a424cd5f6e glusterfs03 Connected
a2585b8c-7928-4480-9376-25c0d6e88cc0 localhost Connected 2)创建一个分布式卷
创建
[root@glusterfs01 ~]# gluster volume create web_volume01 replica 2 glusterfs01:/gfs/test1 glusterfs01:/gfs/test2 glusterfs02:/gfs/test1 glusterfs02:/gfs/test2 force
volume create: web_volume01: success: please start the volume to access data
查看
[root@glusterfs01 ~]# gluster volume list
web_volume01
启动这个卷
[root@glusterfs01 ~]# gluster volume start web_volume01
volume start: web_volume01: success3)查看卷的信息
[root@glusterfs01 ~]# gluster volume info web_volume01
Volume Name: web_volume01
Type: Distributed-Replicate
Volume ID: 4327e3a1-c48d-4442-9230-f0f53b04b35c
Status: Started //表示可用
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: glusterfs01:/gfs/test1
Brick2: glusterfs01:/gfs/test2
Brick3: glusterfs02:/gfs/test1
Brick4: glusterfs02:/gfs/test2
Options Reconfigured:
transport.address-family: inet
storage.fips-mode-rchecksum: on
nfs.disable: on
performance.client-io-threads: off4)客户端挂载
[root@glusterfs03 ~]# mount -t glusterfs 192.168.81.240:/web_volume01 /data_gfs[root@glusterfs03 ~]# df -hT | grep '/data_gfs'
192.168.81.240:/web_volume01 fuse.glusterfs 20G 270M 20G 2% /data_gfs
这里显示20G是因为咱们是复制型的卷容量会减半
8、验证文件在系统中的分布情况
上传几个文件到客户端
[root@glusterfs03 ~]# cp /etc/yum.repos.d/* /data_gfs/主节点去查看文件存放位置,会发现每一个文件都有备份
[root@glusterfs01 ~]# ls /gfs/*
/gfs/test1:
Centos-7.repo epel.repo/gfs/test2:
Centos-7.repo epel.repo
[root@glusterfs01 ~]# ssh 192.168.81.250 "ls /gfs/*"
root@192.168.81.250's password:
/gfs/test1:
CentOS-Base.repo
CentOS-Gluster-7.repo
CentOS-Storage-common.repo/gfs/test2:
CentOS-Base.repo
CentOS-Gluster-7.repo
CentOS-Storage-common.repo
9、Gluster卷扩容
1)扩容
[root@glusterfs01 ~]# gluster volume add-brick web_volume01 glusterfs03:/gfs/test1 glusterfs03:/gfs/test2 force
volume add-brick: success2)查看信息
[root@glusterfs01 ~]# gluster volume info web_volume01
Volume Name: web_volume01
Type: Distributed-Replicate
Volume ID: 4327e3a1-c48d-4442-9230-f0f53b04b35c
Status: Started
Snapshot Count: 0
Number of Bricks: 3 x 2 = 6 #3x2表示有3个节点,每个节点由2块盘,共6个盘
Transport-type: tcp
Bricks:
Brick1: glusterfs01:/gfs/test1
Brick2: glusterfs01:/gfs/test2
Brick3: glusterfs02:/gfs/test1
Brick4: glusterfs02:/gfs/test2
Brick5: glusterfs03:/gfs/test1
Brick6: glusterfs03:/gfs/test2
Options Reconfigured:
transport.address-family: inet
storage.fips-mode-rchecksum: on
nfs.disable: on
performance.client-io-threads: off3)客户端刷新
重新执行df命令即可
[root@glusterfs03 ~]# df -hT | grep '/data_gfs'
192.168.81.240:/web_volume01 fuse.glusterfs 30G 404M 30G 2% /data_gfs
10、扩容后刷新卷的分布情况
[root@glusterfs01 ~]# gluster volume rebalance web_volume01 start
volume rebalance: web_volume01: success: Rebalance on web_volume01 has been started successfully. Use rebalance status command to check status of the rebalance process.
ID: c8e0f0cf-e1d1-4da5-ae79-90ec6e9db72e
11、Gluster卷缩容
缩容后会将所有文件迁移走
[root@glusterfs01 ~]# gluster volume remove-brick web_volume01 glusterfs03:/gfs/test1 glusterfs03:/gfs/test2 start
It is recommended that remove-brick be run with cluster.force-migration option disabled to prevent possible data corruption. Doing so will ensure that files that receive writes during migration will not be migrated and will need to be manually copied after the remove-brick commit operation. Please check the value of the option and update accordingly.
Do you want to continue with your current cluster.force-migration settings? (y/n) y
volume remove-brick start: success
ID: b7ba1075-3bf0-40b3-adaf-9496beee2afc
二、分布式一致性算法Raft
1、Raft算法简介
当我们只有一个服务节点的情况下,是不存在节点共识的问题的,当存在多个不同服务节点时,才会引入分布式一致性的问题。
Raft是一种实现分布式共识的协议。所谓共识,就是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。
主要应用场景:
- Redis Sentinel的选举Leader
- Etcd 主要是共享配置和服务发现,实现一致性使用了Raft算法
- 加密货币(比特币、区块链)的共识算法
主要解决问题:
分布式存储系统通常通过维护多个副本来提高系统的可用性,带来的代价就是分布式存储系统的核心问题之一:维护多个副本的数据一致性。
2、Raft算法实现流程和角色分类
Raft将一致性算法分为了几个部分,包括领导选取(leader selection)、日志复制(log replication)、安全(safety),并且使用了更强的一致性来减少了必须需要考虑的状态。
Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选人(Candidate):
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
- Candidate:Leader选举过程中的临时角色。

Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。
Raft算法角色状态转换如下:

Follower只响应其他服务器的请求。如果Follower超时没有收到Leader的消息,它会成为一个Candidate并且开始一次Leader选举。收到大多数服务器投票的Candidate会成为新的Leader。Leader在宕机之前会一直保持Leader的状态。
Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
3、Leader选举
Raft 使用心跳(heartbeat)触发Leader选举。当服务器启动时,初始化为Follower。Leader向所有Followers周期性发送heartbeat。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。
Follower将其当前term加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送 RequestVote。结果有以下三种情况:
- 赢得了多数的选票,成功选举为Leader;
- 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader;
- 没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。

选举出Leader后,Leader通过定期向所有Followers发送心跳信息维持其统治。若Follower一段时间未收到Leader的心跳则认为Leader可能已经挂了,再次发起Leader选举过程。
Raft保证选举出的Leader上一定具有最新的已提交的日志,这一点将在四、安全性中说明。
4、日志同步
Leader选出后,就开始接收客户端的请求。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起 AppendEntries RPC (RPC细节参见八、Raft算法总结)复制日志条目。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。

某些Followers可能没有成功的复制日志,Leader会无限的重试 AppendEntries RPC直到所有的Followers最终存储了所有的日志条目。
日志由有序编号(log index)的日志条目组成。每个日志条目包含它被创建时的任期号(term),和用于状态机执行的命令。如果一个日志条目被复制到大多数服务器上,就被认为可以提交(commit)了。

Raft日志同步保证如下两点:
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们之前的所有条目都是完全一样的。
第一条特性源于Leader在一个term内在给定的一个log index最多创建一条日志条目,同时该条目在日志中的位置也从来不会改变。
第二条特性源于 AppendEntries 的一个简单的一致性检查。当发送一个 AppendEntries RPC 时,Leader会把新日志条目紧接着之前的条目的log index和term都包含在里面。如果Follower没有在它的日志中找到log index和term都相同的日志,它就会拒绝新的日志条目。
一般情况下,Leader和Followers的日志保持一致,因此 AppendEntries 一致性检查通常不会失败。然而,Leader崩溃可能会导致日志不一致:旧的Leader可能没有完全复制完日志中的所有条目。

上图阐述了一些Followers可能和新的Leader日志不同的情况。一个Follower可能会丢失掉Leader上的一些条目,也有可能包含一些Leader没有的条目,也有可能两者都会发生。丢失的或者多出来的条目可能会持续多个任期。
Leader通过强制Followers复制它的日志来处理日志的不一致,Followers上的不一致的日志会被Leader的日志覆盖。
Leader为了使Followers的日志同自己的一致,Leader需要找到Followers同它的日志一致的地方,然后覆盖Followers在该位置之后的条目。
Leader会从后往前试,每次AppendEntries失败后尝试前一个日志条目,直到成功找到每个Follower的日志一致位点,然后向后逐条覆盖Followers在该位置之后的条目。
5、保证安全性的方式
Raft增加了如下两条限制以保证安全性:
-
拥有最新的已提交的log entry的Follower才有资格成为Leader。
这个保证是在RequestVote RPC中做的,Candidate在发送RequestVote RPC时,要带上自己的最后一条日志的term和log index,其他节点收到消息时,如果发现自己的日志比请求中携带的更新,则拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term更大,则term大的更新,如果term一样大,则log index更大的更新。 -
Leader只能推进commit index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index 小于 commit index的日志被间接提交)。
之所以要这样,是因为可能会出现已提交的日志又被覆盖的情况:

在阶段a,term为2,S1是Leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
在阶段b,S1离线,触发一次新的选主,此时S5被选为新的Leader,此时系统term为3,且写入了日志(term, index)为(3, 2);
S5尚未将日志推送到Followers就离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成Leader,此时系统term为4,此时S1会将自己的日志同步到Followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2,2)可以被提交了。;
在阶段d,S1又下线了,触发一次选主,而S5有可能被选为新的Leader(这是因为S5可以满足作为主的一切条件:1. term = 5 > 4,2. 最新的日志为(3,2),比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到Followers,于是S2、S3中已经被提交的日志(2,2)被截断了。
增加上述限制后,即使日志(2,2)已经被大多数节点(S1、S2、S3)确认了,但是它不能被提交,因为它是来自之前term(2)的日志,直到S1在当前term(4)产生的日志(4, 4)被大多数Followers确认,S1方可提交日志(4,4)这条日志,当然,根据Raft定义,(4,4)之前的所有日志也会被提交。此时即使S1再下线,重新选主时S5不可能成为Leader,因为它没有包含大多数节点已经拥有的日志(4,4)。
6、日志压缩
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。Raft采用对整个系统进行snapshot来解决,snapshot之前的日志都可以丢弃。
每个副本独立的对自己的系统状态进行snapshot,并且只能对已经提交的日志记录进行snapshot。
Snapshot中包含以下内容:
日志元数据。最后一条已提交的 log entry的 log index和term。这两个值在snapshot之后的第一条log entry的AppendEntries RPC的完整性检查的时候会被用上。
系统当前状态。
当Leader要发给某个日志落后太多的Follower的log entry被丢弃,Leader会将snapshot发给Follower。或者当新加进一台机器时,也会发送snapshot给它。发送snapshot使用InstalledSnapshot RPC(RPC细节参见八、Raft算法总结)。
做snapshot既不要做的太频繁,否则消耗磁盘带宽, 也不要做的太不频繁,否则一旦节点重启需要回放大量日志,影响可用性。推荐当日志达到某个固定的大小做一次snapshot。
做一次snapshot可能耗时过长,会影响正常日志同步。可以通过使用copy-on-write技术避免snapshot过程影响正常日志同步。
这篇关于分布式存储GlusterFS与分布式一致性算法Raft的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








