本文主要是介绍基于遗传算法的BWM方法(最优最差方法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
BWM方法介绍
基本原理
权重计算
遗传算法
算法简介
原理
参考程序
程序测试
参考文献
前言
荷兰学者 Jafar Rezaei 于 2015 年提出了一种新的多准则决策方法——最优最劣法(Best-worst Method),相较于层次分析法,该方法可以更为简便的确定出每一个准则的权重。本文将使用遗传算法来实现该方法。
BWM方法介绍
基本原理
BWM方法在保留两两对比思想的前提下对层次分析法(AHP)进行了算法改进,不是直接比较所有成对指标,而是先判定最优、最劣指标,再分别比较最优指标和其余指标、其余指标和最劣指标的相对重要性程度。因此对于个指标来说,层次分析法需要
个比较数据,而在 BWM 中,只需要将最优、最劣指标分别与
个其余指标进行比较,得到
个比较数据即可计算权重分布,基本原理如下图所示。
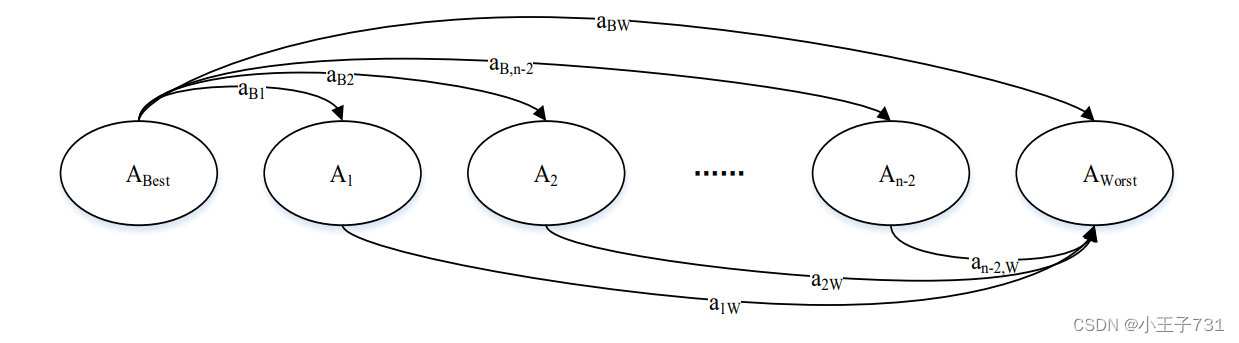
权重计算
假设现在有个准则,即
个评价对象:
其中,、
分别表示最优准则和最差准则。
将最优、最差准则分别与其他准则进行比较,将最优指标 对其余指标
的相对重要性程度用 1-9 标度表示,得到评分向量:
显然,。
再将最劣最劣(最不重要、最不理想)指标 相对于其余指标
的相对重要性程度用 1-9 标度表示,得到评分向量:
显然。
在此规则下,所有的专家打分均大于或等于 1。
设最优权重向量为:
因此,最优化问题目标函数与约束条件如下:
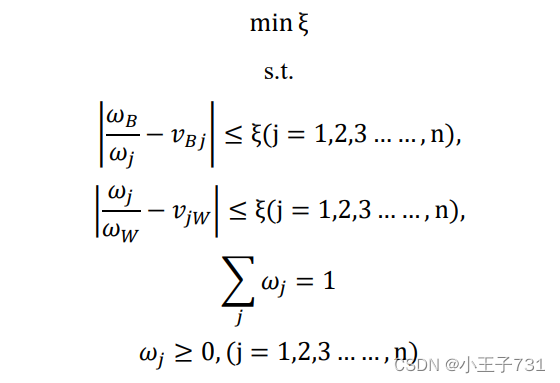

因此,使用遗传算法对一致性指标 的最小值进行优化,即可确定最优权重以及的对应的一致性指标。
遗传算法
总体思路
首先要清楚一点,就是遗传算法是一种随机优化算法,用一组随机数带入适应度函数中计算,按照一定的规则进行多次迭代,最后在多个适应值中找到最大的一个。在本算法中,生成n个随机数,之和为1,当做权重来计算ξ,对结果进行取倒数操作,多次迭代后找到的最大值再取倒数之后就是最小值了。
算法简介
遗传算法是模仿生物遗传学和自然选择机理,通过人工方式所构造的一类优化搜索算法,是对生物进化过程进行的一种数学仿真,是进化计算的最重要的形式。这是一种一种新的全局优化搜索算法,以其简单通用、鲁棒性强、适合并行处理及应用范围广等显著特点,奠定了它作为21世纪关键智能计算之一的地位。
原理
1. 编码与解码:将问题结构变换为位串形式编码表示的过程。本例中待优化参数有个,可以将每一个个体的二进制编码分为
组,解码时对每一个参数单独解码即可
2. 适应度函数
(1)适应度(fitness)就是借鉴生物个体对环境的适应程度,而对问题中的个体对象所设计的表征其优劣的一种测度。
(2)适应度函数(fitness function)就是问题中的全体个体与其适应度之间的一个对应关系。它一般是一个实值函数。该函数就是遗传算法中指导搜索的评价函数。
(3)体现染色体的适应能力,对问题中的每一个染色体都能进行度量的函数,叫适应度函数。
(4)对优化问题,适应度函数就是目标函数。
在本例中所设计的适应度函数是计算一致性指标,对其进行取倒数操作,对倒数最大值的优化就是对一致性指标最小值的优化。
3. 遗传、选择、交叉、变异
该部分的具体操作可以参考:
【精选】遗传算法原理及其matlab程序实现_遗传算法实例matlab-CSDN博客
参考程序
1. 主函数
clear;clc;close all
UnknowNum = input("需要优化的权重的数目为:");
mic = input("最优准则为:");
lic = input("最差准则为:");
popsize = 20; %群体大小
PartLen = 7; % 每一部分的码长(可以不改)
N = 20000; % 遗传迭代次数chromlength = UnknowNum*PartLen; %字符串长度(个体长度)
pc = 0.6; %交叉概率,只有在随机数小于pc时,才会产生交叉
pm = 0.001; %变异概率
pop = initpop(popsize,chromlength); %随机产生初始群体
VBi = repmat(mic,popsize,1);
VjW = repmat(lic,popsize,1);
Best = find(mic == 1,2);
Worst = find(lic == 1,2);
y = zeros(1,N);% 初始化
x = cell(1,N);
for i=1:N % 遗传代数objvalue = calobjvalue(pop,PartLen,popsize, ...UnknowNum,Best,Worst,VBi,VjW); %计算目标函数fitvalue = calfitvalue(objvalue); %计算群体中每个个体的适应度newpop = selection(pop,fitvalue); %复制newpop1 = crossover(newpop,pc); %交叉newpop2 = mutation(newpop1,pm); %变异objvalue = calobjvalue(newpop2,PartLen,popsize, ...UnknowNum,Best,Worst,VBi,VjW); %计算目标函数fitvalue = calfitvalue(objvalue); %计算群体中每个个体的适应度[bestindividual,bestfit]=best(newpop2,fitvalue);%求出群体中适应值最大的个体及其适应值y(i)=bestfit; %返回的 y 是自适应度值,而非函数值x{i}=decode(bestindividual,UnknowNum,PartLen);%将自变量解码成十进制pop=newpop2;
end
[z,index]=max(y);
w = cell2mat(x(index));
for i=1:UnknowNumB(i) = abs(w(Best)./w(i)-VBi(i));W(i) = abs(w(i)./w(Worst)-VjW(i));
end
kesi = 1/max([B,W]);
disp("最优权重为:");
disp(w);
disp("最优一致性数量指标:");
disp(kesi);2. 群体初始化
%初始化
function pop = initpop(popsize,chromlength) pop=round(rand(popsize,chromlength));
end3. 适应度函数
%实现目标函数的计算,将二值域中的数转化为变量域的数
function objvalue = calobjvalue(pop,PartLen,popsize,UnknowNum,Best,Worst,VBi,VjW) temp = zeros(popsize,UnknowNum);for i=1:UnknowNumtemp(:,i) = decodechrom(pop,PartLen*(i-1)+1,PartLen);%将pop每行的每一部分转化成十进制数endtemp = temp./repmat(sum(temp,2),1,UnknowNum); % 归一化d1 = abs((temp(:,Best)./temp)-VBi);d2 = abs((temp./temp(:,Worst))-VjW);dmax = max([d1,d2],[],2);objvalue = 1./dmax; %计算目标函数值
end4. 计算个体适应度
function fitvalue = calfitvalue(objvalue)[px,py]=size(objvalue); %目标值有正有负for i=1:pxif objvalue(i)>0 temp=objvalue(i); elsetemp=0.0;endfitvalue(i)=temp;endfitvalue=fitvalue';
end5. 选择
function newpop = selection(pop,fitvalue)
[px,py] = size(pop);
totalfit=sum(fitvalue); %求适应值之和
fitvalue=fitvalue/totalfit; %单个个体被选择的概率
fitvalue=cumsum(fitvalue);
ms=sort(rand(px,1)); %从小到大排列
fitin=1;
newin=1;
while newin<=px if(ms(newin))<fitvalue(fitin)newpop(newin,:)=pop(fitin,:);newin=newin+1;elsefitin=fitin+1;end
end6. 交叉
function newpop = crossover(pop,pc) [px,py]=size(pop);newpop=ones(size(pop));for i=1:2:px-1 if(rand<pc)cpoint=round(rand*py);newpop(i,:)=[pop(i,1:cpoint),pop(i+1,cpoint+1:py)];newpop(i+1,:)=[pop(i+1,1:cpoint),pop(i,cpoint+1:py)];elsenewpop(i,:)=pop(i,:);newpop(i+1,:)=pop(i+1,:);endend
end7. 变异
function newpop = mutation(pop,pm)[px,py]=size(pop);newpop=ones(size(pop));for i=1:pxif(rand<pm)mpoint=round(rand*py); %产生的变异点在1-10之间if mpoint<=0mpoint=1; %变异位置endnewpop(i,:)=pop(i,:);if any(newpop(i,mpoint))==0newpop(i,mpoint)=1;elsenewpop(i,mpoint)=0;endelsenewpop(i,:)=pop(i,:);endend
end
8. 群体最大适应值及个体
function [bestindividual,bestfit]=best(pop,fitvalue)
[px,py]=size(pop);
bestindividual=pop(1,:);
bestfit=fitvalue(1);
for i=2:pxif fitvalue(i)>bestfitbestindividual=pop(i,:);bestfit=fitvalue(i);end
end9. 染色体解码
function pop2=decodechrom(pop,spoint,length)%1 10pop1=pop(:,spoint:spoint+length-1);pop2=decodebinary(pop1);
end
解码子函数
function pop2=decodebinary(pop)
[px,py]=size(pop); %求pop行和列数
for i=1:py
pop1(:,i)=2.^(py-i).*pop(:,i);
end
pop2=sum(pop1,2); %求pop1的每行之和10. 最终权重解码
function w = decode(bestindividual,UnkonwNum,PartLen)w = zeros(1,UnkonwNum);for i = 1:UnkonwNumw(i) = decodechrom(bestindividual,PartLen*(i-1)+1,PartLen);endw = w/sum(w);
end
程序测试
需要优化的权重的数目为:4
最优准则为:[1,5,3,9]
最差准则为:[3,5,1,7]
最优权重为:0.4248 0.1842 0.2444 0.1466最优一致性数量指标:0.4167声明:
1. 本文代码参考了本站的一位博主,由于时间久远未找到原文,如果原博主看到可以联系我。
2. 本文所有图片均剪切自参考文献。
参考文献
[1]蒋嘉.公共资源交易平台运行绩效评价研究.2022.东南大学,MA thesis.
这篇关于基于遗传算法的BWM方法(最优最差方法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





