概述
前边我曾经写了一篇名为《语义分割之deeplab v3+ 》的文章,在那篇文章中我主要讲了deeplab v3+的原理--当然主要也就是论文上边的内容。因此在开始阅读本篇文章之前,建议首先阅读一下上边那篇文章。
本文我主要讲环境搭建以及pascal_voc_2012的训练以及可视化相关的内容。关于deeplab v3+迁移学习部分的内容--即如何使用deeplab v3+训练自己的个人数据,我后续后单独写一篇文章来讲。好,话不多少,我们下边正式开始。
环境搭建
关于环境搭建部分,其实官方给了一些说明,感兴趣可以参考官方说明《Installation》。虽然说官方给了环境搭建的 指南,但是某些细节部分它并没有具体进行说明,因此如果我们只是一味按照官方说明来搭建环境的话,中间也可能会出现这样或者那样的问题。因此,在该部分我会以官方的指南作为主体,结合自己在搭建环境过程中的一些细节问题,来记录deeplab v+环境搭建的整个过程。
第一步 创建python环境
使用conda创建python环境,应该是我们复现算法的时候必须先做的一步。通过conda创建的新环境我们事先和本地环境的隔离,可以更摆弄各种变量(😄 )。
关于conda安装的部分内容,我这里就不在进行详述,网上有许多相关的教程。在这里我就简单说一下如何使用conda创建满足deeplab v3+算法运行的基础环境。
执行如下命令,创建python3.6基础环境:
conda create -n deeplab python=3.6- 其中 -n后边的参数指的是环境的名称,此处我使用的是deeplab,你可以换成任意你喜欢的名称。
- 等号后边的3.6指的是创建python环境的版本,此处建议使用python3.6(因为我之前使用3.7总出现各种各样的错误)。
执行完成之后会出现如下执行结果
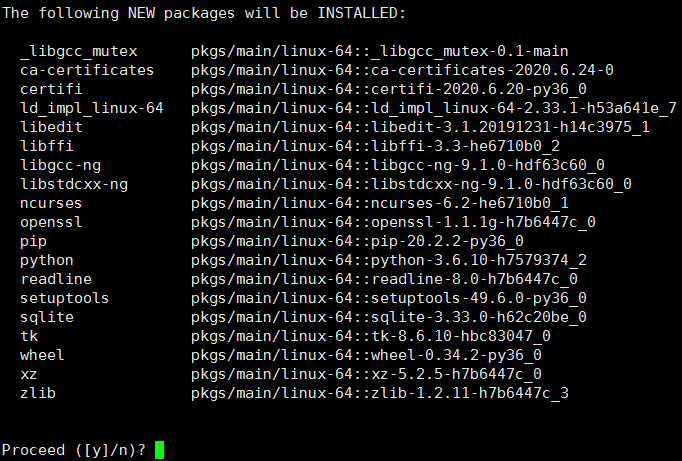
输入y之后基础环境就创建完成。
然后通过命令
conda activate deeplab进入到刚刚创建的名字为deeplab的环境中。
执行的结果如下:

从图中我们可以看到执行完成之后,括号里边的名称由base变成了环境名称(deeplab)。
至此python的基础环境搭建完成。
第二步 安装依赖
- Numpy
- Pillow 1.0
- tf Slim (which is included in the "tensorflow/models/research/" checkout)
- Jupyter notebook
- Matplotlib
- Tensorflow(建议使用1.14,不推荐使用2.0以上版本,否则后边总出各种问题)
安装TensorFlow:
执行如下命令(二选一):
# 使用cpu版本
pip install tensorflow==1.14
# 使用GPU版本
pip install tensorflow-gpu安装python依赖库(安装默认版本即可)
sudo apt-get install python-pil python-numpy
pip install --user jupyter
pip install --user matplotlib
pip install --user PrettyTable第三步 设置python的依赖路径
由于官方给的deeplab代码是在一个TensorFlow的model库中,因此它的代码使用了一些其他位置的代码文件。如果不进行环境变量的设置,在运行的过程中会报“slim模块或者deeplab模块找不到的错误”。因此我们需要执行如下命令对代码所用的依赖路径进行设置:
#进入代码的research目录里边
cd ~/models/research
# 将slim以及deeplab目录添加到python的依赖环境目录中
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim:`pwd`/deeplab首先执行命令之前必须要保证在代码的research目录中。
接着我们执行如下命令,来对环境进行测试,看环境是否已经满足要求。
# 进入/research/deeplab目录下
cd ~/models/research/deeplab
# 执行model_test.py
python model_test.py如果执行过程中没有出现错误或者异常,并且最终出现如下结果,则证明基础环境搭建成功。
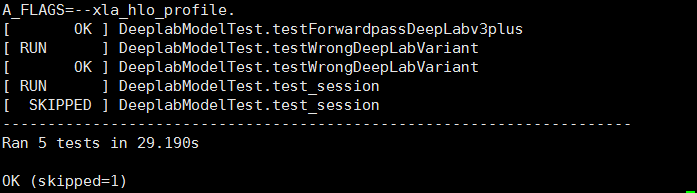
训练与可视化
在前边,我们基础环境搭建完成之后,我们便可以进行训练以及可视化操作。由于pascal voc 2012是官方认定的测试集之一,因此官方给了一个脚本,直接运行之后,可以自动下载预训练权重,训练,评估,以及对结果进行可视化等一系列步骤。
执行命令如下:
#在tensorflow/models/research/deeplab目录下执行
bash local_test.sh执行完成之后我们进入deeplab/datasets目录下

我们发现多了一个名为pascal_voc_seg的目录,该目录里面包含了pascal端原始数据集、预训练权重、导出的checkpoint文件、以及训练结果等。
下边我们对其常用的目录进行一些说明
tfrecord
| 目录名称 | 含义 |
|---|---|
| exp | 结果文件夹,包含训练后的权重、评估的结果、可视化后的图片等 |
| init_models | 下载的预训练权重位置 |
| tfrecord | 转换成的tfrecord文件所在目录 |
| VOCdevkit | pascal voc 2012原本的数据集 |
总结
本文主要写了关于deeplab v3+使用pascal voc 2012数据集进行训练的过程,并且在官方文档的基础结合自己在训练过程中所踩的坑来写了这篇文章。希望能给那些训练deeplab v3+模型的伙伴以帮助
扩展
同时我们学习一个模型之后,进行迁移学习可能也是一个必不可少的环节。因此在后续我也写一篇关于如何使用deeplabv3+训练自己数据集的文章--《deeplab v3+训练个人数据集》,欢迎诸位阅读、批评与指正。
引用
- https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/installation.md




