本文主要是介绍whale-quant 学习 part6:量化择仓策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
量化择调仓策略
- 投资组合收益率衡量
- 投资组合收益率计算方法
- 投资组合的绝对收益率和相对收益率
- 投资组合的风险衡量
- 最优方法计算投资组合的最佳仓位
- 等权重
- 市场加权
- 最小方差组合
- 最大分散度
- 风险平价
- 均值方差优化(最经典与常用)
- 常见约束
- python实现最佳仓库控制
- 参考
投资组合收益率衡量
投资组合收益率计算方法
投资组合的收益率 = w 1 ∗ r 1 + w 2 ∗ r 2 + . . . + w n ∗ r n 投资组合的收益率=w_1*r_1+w_2*r_2+...+w_n*r_n 投资组合的收益率=w1∗r1+w2∗r2+...+wn∗rn
其中权重 w i w_i wi表示资产i在投资组合中的占比,满足 w 1 + w 2 + . . . + w n = 1 w_1+w_2+...+w_n=1 w1+w2+...+wn=1 r i r_i ri是资产i的收益率 投资组合的收益率是衡量投资组合的重要指标。
投资组合的绝对收益率和相对收益率
-
绝对收益率 指投资组合的实际收益和初始投资金额间的比率
绝对收益率 = 投资组合的实际收益 − 初始投资金额 初始投资金额 ∗ 100 % 绝对收益率=\frac{投资组合的实际收益-初始投资金额}{初始投资金额}*100\% 绝对收益率=初始投资金额投资组合的实际收益−初始投资金额∗100% -
相对收益率 指投资组合的实际收益与市场平均收益间的比率
相对收益率 = 投资组合的实际收益率 − 市场平均收益 市场平均收益 ∗ 100 % 相对收益率=\frac{投资组合的实际收益率-市场平均收益}{市场平均收益}*100\% 相对收益率=市场平均收益投资组合的实际收益率−市场平均收益∗100%
投资组合的风险衡量
- 风险定义
风险即指在未来可能发生的不确定性时间所带来的潜在损失。 - 投资组合的风险
投资组合的风险是指投资组合在未来可能出现的损失或波动的程度。 - 衡量投资组合的风险
有多种方法可以进行衡量投资组合的风险,以下是一些常见的方法:
1、方差和标准差 在投资领域方差和标准差常用于衡量资产或投资组合的波动性,即风险
import numpy as npdef portfolio_volatility(weights, returns):
"""计算投资组合的波动性(标准差):param weights: 投资组合中每个资产的权重:param returns: 每个资产的收益率:return: 投资组合的标准差"""portfolio_return = np.dot(weights, returns)portfolio_volatility = np.sqrt(np.dot(weights.T, np.dot(np.cov(returns), weights)))return portfolio_volatility
2、Beta系数:衡量投资组合相对于市场整体波动的指标,用投资组合与市场组合的协方差与市场组合的方差比值计算:
β i = C o v ( r i , r m ) V a r ( r m ) \beta_i=\frac{Cov(r_i,r_m)}{Var(r_m)} βi=Var(rm)Cov(ri,rm)
Beta系数为1表示投资组合的波动与市场整体波动相同
小于1表示波动小于市场整体波动
大于1表示波动大于市场整体波动
Beta系数的计算方法是将资产或投资组合的收益率与市场指数的收益率进行回归分析得到回归系数即为Beta系数。其值越高,表示资产或投资组合的风险越高,但同时回报也可能越高。
3、Value at Risk(VaR):VaR是衡量投资组合在一定置信水平下的最大可能损失指标
令 α ∈ ( 0 , 1 ) \alpha \in (0,1) α∈(0,1)而 F L F_L FL为时间L的分布函数,则VaR如下:
V a R α ( L ) = = i n f y ∈ R ∣ F L ( y ) ≥ α VaR_\alpha(L) == inf{y \in R|F_L(y) \ge \alpha} VaRα(L)==infy∈R∣FL(y)≥α
即VaR是满足使损失不超过y的概率大于等于 α \alpha α的最小的y值。
例如,一个10%的VaR表示在90%的时间内,投资组合的损失不会超过VaR的值。VaR通常用于衡量投资组合的风险水平,以便投资者能够更好地控制风险。
4、Conditional Value at Risk(CVaR)[^1]:CVaR是VaR的扩展,它衡量的是在VaR损失超过一定阈值时平均损失。即在一定的置信水平 1 − α 1-\alpha 1−α上,测算出损失超过VaR值的条件期望值:
C V a R 1 − α = − ∫ 0 1 − α V a R α ( L ) d r 1 − α CVaR_{1-\alpha}=-\frac{\int^{1-\alpha}_{0}VaR_\alpha(L)dr}{1-\alpha} CVaR1−α=−1−α∫01−αVaRα(L)dr
CVaR模型在一定程度上克服了VaR模型的缺点不仅考虑了超过VaR值的频率,而且考虑了超过VaR值损失的条件期望,有效的改善了VaR模型在处理损失分布的后尾现象时存在的问题,通常也被认为比VaR更加保守。
最优方法计算投资组合的最佳仓位
在之前的学习中,了解了如何分别从截面(多因子模型)和时序(择时策略)两个方面来对各个股票的未来收益率进行预测。其最终目标是在每一个时间截面上,输出股票对未来收益率的预测值,并在截面上不同股票间进行强弱比较。我们那个参考预测值来进行股票的买入和卖出,但市场中股票是很多的,同一时间点,符合条件的股票也不止一支,但我们的资金是有限的
常用数学符号约定:
| 符号 | 简述 |
|---|---|
| N N N | 组合内证券数量 |
| w w w | 权重向量( N × 1 N \times 1 N×1) |
| w i w_i wi | 证券 i i i的权重 |
| μ \mu μ | 预期收益率向量( N × 1 N \times 1 N×1) |
| σ \sigma σ | 证券波动率向量( N × 1 N \times 1 N×1) |
| σ i \sigma_i σi | 证券 i i i的波动率 |
| σ i j \sigma_{ij} σij | 证券 i i i和 j j j之间的协方差 |
| ∑ \sum ∑ | 方差协方差矩阵( N × N N \times N N×N) |
| σ p \sigma_p σp | 组合波动率 |
| μ p \mu_{p} μp | 组合收益率 |
| λ \lambda λ | 风险厌恶系数 |
| r f r_f rf | 无风险收益率 |
等权重
在没有任何信息或偏好时,赋予组合中每个证券相同的权重(等权重虽然简单,但往往很有效)
w i = 1 N w_i = \frac{1}{N} wi=N1
市场加权
对于股票组合而言,在没有任何信息或者偏好时,还有另外一种使用非常普遍的组合方法,即市值加权。通常地,小市值的股票收益率的日波动是大于大市值股票的,因为小市值股票和大市值股票能承载的资金量是不同的,令小市值股票涨/跌1%需要的资金可能远小于大市值的股票。
而如果我们希望在组合内各个股票平等的分配资金,由于大小市值这种属性,等权重组合可能需要非常频繁调仓。而市值加权,根据定义,对于选出的股票,按照其市值加权,即
w i = C a p i / ∑ i C a p i w_i = Cap_i/\sum_iCap_i wi=Capi/i∑Capi
C a p i 为股票 i 的市值 Cap_i为股票i的市值 Capi为股票i的市值
市值加权不需要频繁调仓,往往流动性也最强;不过,市值加权会给与高估值股票过多权重,给与低估值股票过少权重,因此结果在一些结构性行情下可能并不占优。
最小方差组合
对于风险厌恶的投资者,自然是希望投资者的风险是最小的。由于总体的风险是未知的,在组合优化中,我们常常用历史收益率的方差最为代理变量,追求组合整体的方差最小,数学表达为:
M i n σ p = w ′ ∑ w ⇒ w ∝ ∑ − 1 1 Min \sigma_p=w^{'}\sum w \Rightarrow w \propto {\textstyle \sum^{-1}}1 Minσp=w′∑w⇒w∝∑−11
最大分散度
从组合的方差-协方差矩阵我们可知,组合的整体风险一部分来源于各个证券自身的方差,另一部分来源于证券之间的协方差。因此,如果我们想降低组合风险,就应该尽量分散投资。最大分散度优化:
M a x D ( w ) = w ′ σ w ′ ∑ w ⇒ w ∝ ∑ − 1 σ Max D(w)=\frac{w^{'}\sigma}{\sqrt{w^{'}\sum w}} \Rightarrow w \propto {\textstyle \sum^{-1}}\sigma MaxD(w)=w′∑ww′σ⇒w∝∑−1σ
目标函数被称为分散比率,分母为组合波动率,分子为成分的波动率加权平均。该方法最大化资产线性加权波动率与投资组合波动率的比值,故称为最大分散化资产配置组合。
风险平价
风险平价(Risk Parity)从风险的角度进行均衡配置,以追求所有证券对组合的风险贡献相同。首先定义所谓的边际风险贡献,即每增加1单位证券i的权重 w i w_i wi 所引起的组合整体风险的变化:
M R C i = δ σ p δ w i = w i σ i 2 + ∑ j ≠ i w j ρ i j σ i σ j σ p = ∑ j = 1 N w j ρ i j σ i σ j σ p = ρ i j σ i σ p σ p = ( ρ i p σ i σ p ) σ p = β i σ p MRC_i = \frac{\delta\sigma_p}{\delta w_i}=\frac{w_i \sigma_i^2+\sum_{j \ne i}w_j \rho_{ij}\sigma_i\sigma_j}{\sigma_p} \\ =\frac{\sum^{N}_{j=1}w_j \rho_{ij} \sigma_i \sigma_j}{\sigma_p} \\ =\frac{\rho_{ij} \sigma_i\sigma_p}{\sigma_p} \\ = (\frac{\rho_{ip}\sigma_i}{\sigma_p})\sigma_p \\ = \beta_i\sigma_p MRCi=δwiδσp=σpwiσi2+∑j=iwjρijσiσj=σp∑j=1Nwjρijσiσj=σpρijσiσp=(σpρipσi)σp=βiσp
其中 β i \beta_i βi 表示证券i收益率相对于投资组合收益率的 β \beta β 系数;定义了证券的边际风险贡献后,乘以其权重我们既可以得到风险贡献:
R C i = w i × M R C i = w i δ σ p δ w i RC_i=w_i\times MRC_i = w_i\frac{\delta \sigma_p}{\delta w_i} RCi=wi×MRCi=wiδwiδσp
由Risk Parity的定义有:
R C i = R C j ⇒ w i δ σ p δ w i = w j δ σ p δ w j , ∀ i , j RC_i = RC_j \\ \Rightarrow w_i\frac{\delta \sigma_p}{\delta w_i} = w_j\frac{\delta\sigma_p}{\delta w_j}, \forall i,j RCi=RCj⇒wiδwiδσp=wjδwjδσp,∀i,j
因此,风险平价组合的目标函数为:
M i n ∑ j = 1 N ∑ j = 1 N ( R C i − R C j ) 2 ⇒ w i ∝ 1 β i Min \sum^{N}_{j=1}\sum^{N}_{j=1}(RC_i-RC_j)^2 \\ \Rightarrow w_i \propto \frac{1}{\beta_i} Minj=1∑Nj=1∑N(RCi−RCj)2⇒wi∝βi1
在 Risk Parity投资组合中,证券的权重和它相对于组合的 β 成反比;β 越高,其权重越低,从而有效的分散了风险,每个资产对组合的边际风险贡献相同。
均值方差优化(最经典与常用)
一个优秀的投资策略,往往是在给定风险水平下实现组合收益最大化,或者在给定收益水平实现组合风险最小化。均值方差优化,其目标函数为:
M a x w T μ − λ 2 w ′ ∑ w Max w^T \mu - \frac{\lambda}{2}w^{'}\sum w MaxwTμ−2λw′∑w
理论上来讲,组合成分间存在无数个混搭方式,每种方式得到一个收益风险对,将所有结果集合在一起,就形成了可行域,如图所示。可行域中并不是所有点都是“好结果”,只有处于可行域上侧边缘的点才是最优值,即MVO的解,如图中A到D之间连线,这条线称为有效前沿。任何异于有效前沿的点,均能找到相同风险(收益)下收益(风险)更高(低)的组合。
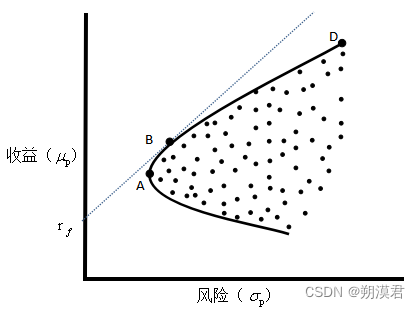
图片来源:CQR 其中,图上的A点即前文讨论过的最小方差组合,位于有效前沿的最左端;而如果我们自无风险收益率起做一条射线,与有效前沿相切于B点,改点即为所有可行域中夏普比率最大的点,因此也被称为最大夏普组合。故也有另外一种常见的,最大化组合夏普比率,其目标函数为。
M a x w ′ μ w ′ ∑ w Max \frac{w^{'}\mu}{\sqrt{w^{'}\sum w}} Maxw′∑ww′μ
因为引入更多参数,使其对预期收益率的估计,会使得优化结果对参数的输入非常敏感,结果就是优化出的权重在时序上换手较快;容易输出极端大或极端小的权重,最终组合时常在个别证券上集中度过高;基于历史数据的均值方差组合,由于估计误差,在样本外甚至很难超越等权重组合。
常见约束
在实际投资中,往往除了最现实的资金限制外,还会有各种各样的限制,比较常见的有:
- 约束1:单资产权重的范围限制
w l b ≤ w ≤ w u b w_{lb} \le w \le w_{ub} wlb≤w≤wub - 约束2:做空限制
w T 1 = 1 w ≥ 0 w^T1=1 \\ w \ge 0 wT1=1w≥0 - 约束3:行业中性化
( w − w b e n c h m a r k ) T I i n d u s t r y ∈ D = 0 (w-w_{benchmark})^TI_{industry \in D} = 0 (w−wbenchmark)TIindustry∈D=0
其中, w b e n c h m a r k w_{benchmark} wbenchmark是准指数内各成分股的权重向量, I i n d u s t r y I_{industry} Iindustry是代表行业的哑变量矩阵。 - 约束4:风险敞口限制
∣ ( w − w b e n c h m a r k ) T ∣ f ≤ f u b ∈ [ 0 , 1 ] |(w-w_{benchmark})^T|f\le f_{ub} \in [0,1] ∣(w−wbenchmark)T∣f≤fub∈[0,1]其中, w b e n c h m a r k w_{benchmark} wbenchmark是基准指数内各成分股的权重向量,f是风险因子暴露向量, f u b f_{ub} fub是因子的风险敞口上限。
python实现最佳仓库控制
主要使用scipy构建组合优化模型,来实现最佳仓位控制。
import akshare as ak
import datetime
import warnings
import pandas as pd
import numpy as np
from scipy.optimize import minimize
warnings.filterwarnings('ignore')# 定义一些辅助函数
def get_weights(df: pd.DataFrame, target='sharp', canshort=False) -> pd.Series:''':param df: 资产日度涨跌幅矩阵:param target: 优化目标 sharp→最大夏普比组合 rp→风险平价组合 var→最小风险组合:param canshort: 是否可以做空:return: 组合比率'''MeanReturn = df.mean().values # 期望收益Cov = df.cov() # 协方差# 定义优化函数、初始值、约束条件
# 负夏普比
def neg_sharp(w):R = w @ MeanReturnVar = w @ Cov @ w.Tsharp = R / Var ** 0.5return -sharp * np.sqrt(240)# 风险
def variance(w):Var = w @ Cov @ w.Treturn Var * 10000def RiskParity(w):weights = np.array(w) # weights为一维数组sigma = np.sqrt(np.dot(weights, np.dot(Cov, weights))) # 获取组合标准差# sigma = np.sqrt(weights@cov@weights)MRC = np.dot(Cov, weights) / sigma # MRC = Cov@weights/sigma# MRC = np.dot(weights,cov)/sigmaTRC = weights * MRCdelta_TRC = [sum((i - TRC) ** 2) for i in TRC]return sum(delta_TRC)# 设置初始值
w0 = np.ones(df.shape[1]) / df.shape[1]
# 约束条件 w之和为1
cons = [{'type': 'eq', 'fun': lambda w: np.sum(w) - 1}]
bnds = tuple((0, 1) for w in w0) # 做多的约束条件,如果可以做空,则不传入该条件if target == 'sharp':fc = neg_sharp
elif target == 'rp':fc = RiskParity
elif target == 'var':fc = varianceif canshort:res = minimize(fc, w0, method='SLSQP', constraints=cons, options={'maxiter': 100})
else:res = minimize(fc, w0, method='SLSQP', constraints=cons, options={'maxiter': 100}, bounds=bnds)# if target == 'sharp':
# print('最高夏普:', -res.fun)
# elif target == 'rp':
# print('风险平价:', res.fun)
# elif target == 'var':
# print('最低风险:', res.fun)# print('最优比率:', res.x)
# print('年化收益:', ReturnYearly(res.x) * 100, "%")
weight = pd.Series(res.x, index=df.columns)
return weight
借助akshare 下载股票的复权收盘价,计算日收益率
def get_ret(code,start_date,end_date):data = ak.stock_zh_a_hist(symbol=code, period="daily", start_date=start_date, end_date=end_date, adjust="hfq")data.index = pd.to_datetime(data['日期'], format='%Y-%m-%d') # 设置日期索引close = data['收盘'] # 日收盘价close.name = coderet = close.pct_change() # 日收益率return retend_date = datetime.datetime.now().strftime('%Y%m%d')
index_stock_cons_weight_csindex_df = ak.index_stock_cons_weight_csindex(symbol="000016")
stock_codes = index_stock_cons_weight_csindex_df['成分券代码'].to_list()
start_date =(index_stock_cons_weight_csindex_df['日期'].iat[0] - pd.Timedelta(days=365*1)).strftime('%Y%m%d')ret_list = []
for code in stock_codes:ret = get_ret(code,start_date=start_date,end_date=end_date)ret_list.append(ret)
df_ret = pd.concat(ret_list,axis=1).dropna()
数据和模型都准备好后,我们就可以在时间轴上滚动计算最优化模型的权重,注意不要使用未来数据。
records = []
for trade_date in df_ret.loc[index_stock_cons_weight_csindex_df['日期'].iat[0]:].index.to_list():df_train = df_ret.loc[:trade_date].iloc[-1-240:-1]df_test = df_ret.loc[trade_date]StockSharpDf = get_weights(df_train, target='sharp') # 最大夏普组合StockRPDf = get_weights(df_train, target='rp') # 风险平价组合StockVarDf = get_weights(df_train, target='var') # 最小风险组合records.append([trade_date,(df_test.mul(StockSharpDf)).sum(),(df_test.mul(StockRPDf)).sum(),(df_test.mul(StockVarDf)).sum(),df_test.mean()])
df_record = pd.DataFrame(records,columns=['日期','最大夏普组合','风险平价组合','最小风险组合','等权重组合'])
df_record = df_record.set_index('日期')
参考
Datawhale 202401 whale-quant 开源学习
这篇关于whale-quant 学习 part6:量化择仓策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





