本文主要是介绍数据据库八之 视图、触发器、事务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【零】准备数据
【1】创建表
(1)部门表
- d_id是部门的编号
- d_name是部门的名字
# 确保表不存在
drop table if exists department;
# 创建表
create table department(
d_id int auto_increment primary key,
d_name varchar(6)
)auto_increment = 501 ;
(2)创建员工表
- id是员工的编号
- name是员工的姓名
- money是员工的金额,默认1000
- sex是员工性别默认男性
- department_id是所在部门的编号
# 确保表不存在
drop table if exists employee;
# 创建表
create table employee(
id int auto_increment primary key,
name varchar(10),
password varchar(20),
money int default 1000,
sex enum('female', 'male') default 'male',
department_id int
);
【2】插入数据
(1)部门信息
- 只插入3个部门信息
insert department (d_name) values("销售部"), ("技术部"), ("售后部");
+-----+-----------+
| id | name |
+-----+-----------+
| 501 | 销售部 |
| 502 | 技术部 |
| 503 | 售后部 |
+-----+-----------+
(2)员工信息
- 共5名员工
insert employee (name, sex, password, department_id)values
('John', 'male', '111', 501),
('Jane', 'female', '222', 503),
('Mike', 'male', '333', 502),
('Tom', 'male', 'aaa', 503),
('Amy', 'female', '999', 501);
+----+------+----------+-------+--------+---------------+
| id | name | password | money | sex | department_id |
+----+------+----------+-------+--------+---------------+
| 1 | John | 111 | 1000 | male | 501 |
| 2 | Jane | 222 | 1000 | female | 503 |
| 3 | Mike | 333 | 1000 | male | 502 |
| 4 | Tom | aaa | 1000 | male | 503 |
| 5 | Amy | 999 | 1000 | female | 501 |
+----+------+----------+-------+--------+---------------+
【一】视图
【1】说明
(1)什么是视图
- 视图是数据库中的一种虚拟表,其内容是一个或多个基本表的查询结果。
- 与基本表不同,视图不存储实际数据,而是根据查询语句在使用时进行实时计算。
- 视图可以通过定义查询语句来简化复杂的查询、隐藏敏感数据、实现数据安全性和完整性约束等。
- 用户可以对视图执行与表相同的查询操作,但是多用于查询,其他容易出错
- 视图可以是虚拟的,每次查询都会计算最新的结果,也可以是物化的,用于提高查询性能。
- 虚拟视图适用于经常变动的数据,而物化视图适用于查询频繁但数据变动较少的情况。
- 通过使用视图,用户可以以灵活且安全的方式访问和操作数据库中的数据,无需直接访问底层的基本表。
(2)作用
-
简化复杂查询:通过在视图中定义复杂的查询逻辑,包括连接多个表、过滤条件、聚合函数等,使用户能够以更简洁明了的方式进行数据检索。
-
数据安全性:通过限制用户对数据的访问权限,视图可以用于隐藏敏感数据或只提供部分数据给特定的用户。通过定义视图并设置相应的权限,可以保护数据的安全性,防止未经授权的用户访问敏感信息。
-
数据完整性:视图可以用于实现数据完整性约束,即对数据的有效性进行验证。通过定义视图并添加计算列、过滤条件等约束,可以确保所返回的数据满足一定的条件,提高数据的准确性和一致性。
-
逻辑数据独立性:通过解耦应用程序与底层数据表结构,视图使得应用程序不需要了解底层表结构的细节。这样,当底层数据库发生变化时,只需调整底层视图的定义而无需修改应用程序,提高系统的可维护性和扩展性。
-
性能优化:物化视图作为一种缓存机制,将视图的查询结果存储在磁盘上,提高查询性能。特别在基本表数据频繁变动时,物化视图可以减少查询的计算开销和响应时间,从而提升系统的性能。
【2】使用
- 联合多个表的时候,字段名不能重复
(1)创建视图
- 创建视图的模板
create view 视图名 as
select 字段名,...
from 表名
join 表名 on 条件
where 条件
- 创建视图
create view emp_dep as
select * from employee
left join department
on employee.department_id = department.d_id;
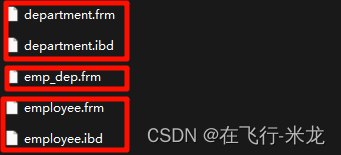
- 查看文件结构
- 只有frm文件,没有ibd文件
- 只有表结构,没有数据记录
(2)修改数据
- 先查看原本视图内容
select * from emp_dep;
+----+------+--------+---------------+------+-----------+
| id | name | sex | department_id | d_id | d_name |
+----+------+--------+---------------+------+-----------+
| 1 | John | male | 501 | 501 | 销售部 |
| 5 | Amy | female | 501 | 501 | 销售部 |
| 3 | Mike | male | 502 | 502 | 技术部 |
| 2 | Jane | female | 503 | 503 | 售后部 |
| 4 | Tom | male | 503 | 503 | 售后部 |
+----+------+--------+---------------+------+-----------+
- 员工表插入记录,并查看视图是否修改(修改了)
insert employee (name, sex, department_id)
values('lulu', 'female', 502);
select * from emp_dep;
+----+------+--------+---------------+------+-----------+
| id | name | sex | department_id | d_id | d_name |
+----+------+--------+---------------+------+-----------+
| 1 | John | male | 501 | 501 | 销售部 |
| 5 | Amy | female | 501 | 501 | 销售部 |
| 3 | Mike | male | 502 | 502 | 技术部 |
| 6 | lulu | female | 502 | 502 | 技术部 |
| 2 | Jane | female | 503 | 503 | 售后部 |
| 4 | Tom | male | 503 | 503 | 售后部 |
+----+------+--------+---------------+------+-----------+
- 视图表删除数据记录,查看视图表是否修改(不能)
delete from emp_dep
where id = 6;
ERROR 1288 (HY000): The target table emp_dep of the DELETE is not updatable
- 视图表修改数据记录,查看视图表是否修改(不能)
update emp_dep
set department_id = 502
where name = tom;
ERROR 1288 (HY000): The target table emp_dep of the UPDATE is not updatable
- 小结
- 视图表多用于查询
- 若要修改,在原表进行修改
(3)删除视图
- 查看方法:
- 和查看表一样
show tables;
+---------------+
| Tables_in_db4 |
+---------------+
| department |
| emp_dep |
| employee |
+---------------+
desc emp_dep;
+---------------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+-----------------------+------+-----+---------+-------+
| id | int(11) | NO | | 0 | |
| name | varchar(10) | YES | | NULL | |
| sex | enum('female','male') | YES | | male | |
| department_id | int(11) | YES | | NULL | |
| d_id | int(11) | YES | | 0 | |
| d_name | varchar(6) | YES | | NULL | |
+---------------+-----------------------+------+-----+---------+-------+
- 删除视图
- 关键字稍微不同
drop view id exists 触发器名;
drop view emp_dep;
【二】触发器
【1】说明
(1)什么是触发器
- 触发器是数据库管理系统中的一种特殊对象,用于在数据库表发生特定的数据变化时自动触发相关的操作或逻辑。
- 触发器通常与数据库表关联,监视表的增删改操作,当满足指定条件时,触发器会执行相应的响应行为。
(2)主要作用
- 自动执行操作: 触发器可以在表的数据发生变化时自动执行相关的操作,如插入、更新、删除或查询数据等。
- 维护数据一致性: 触发器可以用作一种约束,用于保证数据的完整性和一致性。通过在触发器中定义逻辑,可以确保数据库中的数据始终符合特定的规则或条件。
- 实现业务规则: 触发器可以用于实现特定的业务规则。例如,当某个表的特定列达到某个阈值时,触发器可以自动执行相应的业务逻辑。
- 记录操作历史: 触发器可以用于记录数据的修改历史,例如在表的某个字段发生变化时,触发器可以将变化记录到一个历史表中。
(3)使用场景
- 使用触发器可以实现很多功能
- 比如数据验证、数据补全、数据同步、日志记录等。
- 在增删改的前后都可以使用触发器,故有六种使用情况
- 增前、增后
- 删前、删后
- 改前、改后
【2】使用
(0)修改默认语句结束符
- sql语句默认结束符是
; - 但是在接下来的语句中会有
;出现 - 所以我们需要学会修改默认语句结束符
# 修改为 $$
delimiter $$
# 修改回来 ;
delimiter ;
(1)创建触发器
- 模板
delimiter $$
create trigger 触发器名
{before | after} {insert | update | delete} on 表名
for each row
begin--触发器执行的语句--new--old
end $$
delimiter ;
- 触发器的名字需要让人很容易的理解其含义
# 例如
tri_表名_after_insert
NEW:NEW用于引用触发器中正在处理的行的新值。在BEFORE INSERT和BEFORE UPDATE触发器中,NEW包含即将插入或更新到表中的数据。在AFTER INSERT、AFTER UPDATE和AFTER DELETE触发器中,NEW包含已经插入、更新或删除的数据。- 在
BEFORE INSERT和AFTER INSERT触发器中,NEW是唯一的,并包含即将或已经插入到表中的数据。
OLD:OLD用于引用触发器中正在处理的行的旧值。在BEFORE UPDATE和AFTER UPDATE触发器中,OLD包含即将或已经被更新的行的旧值。在BEFORE DELETE和AFTER DELETE触发器中,OLD包含即将或已经被删除的行的旧值。- 在
BEFORE UPDATE和AFTER UPDATE触发器中,OLD包含被更新的数据的旧值。在BEFORE DELETE和AFTER DELETE触发器中,OLD包含被删除的数据的旧值。
(2)删除触发器
- 删除语句很简单
- 和视图的删除差不多
drop trigger if exists 触发器名
(2)例一:部门检查
- 要求:在插入数据之前进行部门id校验
delimiter $$
create trigger tri_employee_before_insert before insert on employee
for each row
beginif new.department_id not in (select d_id from department) thensignal sqlstate '45000'set message_text = "部门id不存在";end if;
end $$
delimiter ;
- 检查检查(正确)
insert employee (name, sex, department_id) values('liuliu', 'male', 505);
ERROR 1644 (45000): 部门id不存在
minsert employee (name, sex, department_id) values('liuliu', 'male', 501);
Query OK, 1 row affected (0.00 sec)
(3)例二:密码安全性提醒
- 要求:每次在修改密码以后进行判断
- 如果密码是全新的密码,不做提醒
- 如果密码和之前的密码一样,提醒安全性较低
drop trigger if exists tri_employee_after_update;
delimiter $$
create trigger tri_employee_after_update after update on employee
for each row
beginif old.password = new.password thensignal sqlstate '01000'set message_text = '修改成功,但密码安全性较低,和之前一样';# 不允许返回值# select '修改成功,但密码安全性较低,和之前一样';end if;
end $$
delimiter ;
- 检查检查
# 查看id为2的员工密码
select password
from employee
where id=2;
+----------+
| password |
+----------+
| 222 |
+----------+
# 修改的密码和之前一样
update employee
set password = '222'
where id = 2;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
- 很遗憾,不会触发
- 但是可以修改错误代码为45000
- 验证逻辑是没有问题的
- 只不过这种应用并不适合
- 有待更改完善或者使用新的例子
(4)一些模板
- 插入数据之前,自动生成唯一标识符
CREATE TRIGGER generate_uuid_trigger BEFORE INSERT ON table_name
FOR EACH ROW
BEGINSET NEW.uuid = UUID();
END
- 更新数据时,更新最后修改时间
CREATE TRIGGER update_last_modified_trigger BEFORE UPDATE ON table_name
FOR EACH ROW
BEGINSET NEW.last_modified = NOW();
END
- 删除数据时,将记录添加到历史记录表
CREATE TRIGGER archive_deleted_record_trigger AFTER DELETE ON table_name
FOR EACH ROW
BEGININSERT INTO history_table (id, deleted_at)VALUES (OLD.id, NOW());
END
- 插入数据进行某个条件检查,不满足抛出异常
CREATE TRIGGER check_condition_trigger BEFORE INSERT ON table_name
FOR EACH ROW
BEGINIF NEW.column_name < 10 THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Value must be greater than 10';END IF;
END
- 日志模板
# 主要是为了区分错误执行语句和全局结束语句
create trigger tri_after_insert_cmd after insert on cmd
for each row
beginif NEW.success = "no" theninsert into errlog(err_cmd,err_time)values(NEW.cmd,NEW.sub_time);end if;
end
【三】事务
【1】说明
(1)什么是事务
- 事务是数据库管理系统中的一个概念,它表示一系列相关的数据库操作,这些操作要么全部成功执行,要么全部失败回滚,保证数据库的一致性和完整性。
(2)事务的四大特性
- 原子性(Atomicity): 事务被视为一个原子操作,不可再分割。要么所有的操作都成功执行,要么所有的操作都会被回滚到事务开始前的状态,确保数据的一致性。
- 一致性(Consistency): 事务执行前后,数据库应保持一致的状态。在事务开始之前和结束之后,数据库必须满足所有的完整性约束,如数据类型、关系等。
- 隔离性(Isolation): 事务的执行结果对其他并发执行的事务是隔离的。即一个事务的执行不应受到其他事务的干扰,各个事务之间应该相互独立工作,从而避免数据的不一致性。
- 持久性(Durability): **一旦事务被提交,其结果应该永久保存在数据库中,并且可以被系统故障恢复。**即使系统发生宕机或崩溃,事务提交后的更改也应该是永久性的。
(3)简单示例
-
用户提交订单的操作流程可以总结为以下步骤:
- 检查库存: 系统检查所需商品的库存是否足够。
- 库存充足: 如果库存足够,系统继续执行后续步骤;如果库存不足,系统提示用户库存不足,无法完成订单。
- 扣减库存: 系统减少所购商品对应的库存数量。
- 生成订单: 系统生成一个新的订单,包括订单号、商品信息、购买数量、价格等相关信息。
- 计算总价: 系统根据订单中的商品信息和购买数量计算订单的总价格。
- 更新用户账户: 根据用户选择的支付方式,在扣除相应金额后,系统更新用户账户余额或积分。
- 生成支付信息: 系统生成相应的支付信息,以便用户完成支付。
- 通知物流部门: 系统通知物流部门准备配送相关商品。
- 发送订单确认邮件/短信: 系统向用户发送订单确认的邮件或短信,包括订单详细信息、配送信息等。
- 监控商品配送: 系统跟踪订单的配送情况,并向用户提供订单状态更新。
- 完成订单: 当用户收到商品并确认满意后,订单状态会被更新为“已完成”。
-
这个流程确保了在用户提交订单后,系统进行了必要的检查、处理、通知和更新操作,以提供完整的购物体验。
【2】使用
(1)创建事务
- 模板
# 开启事务
start transaction;# 执行事务操作
......
......# 提交事务或者回滚事务
# 此时会结束事务
commit; | rollback;
(2)示例:转钱
-
任务
-
初始每个人都是1000元
-
让我们来试试一号给二号转100元试试
-
-
开启事务
start transaction;
- 1号员工扣钱、2号员工加钱
update employee
set money = money - 100
where id = 1;
update employee
set money = money + 100
where id = 2;
- 查看此时他们的金额
select id, money
from employee
where id in (1, 2);
+----+-------+
| id | money |
+----+-------+
| 1 | 900 |
| 2 | 1100 |
+----+-------+
- 回滚试试,看看会发生什么
- 金额变回来了
rollback;
select id, money
from employee
where id in (1, 2);
+----+-------+
| id | money |
+----+-------+
| 1 | 1000 |
| 2 | 1000 |
+----+-------+
- 再次转钱
update employee
set money = money - 100
where id = 1;
update employee
set money = money + 100
where id = 2;
- 提交事务
commit;
- 尝试回滚并查看数据
- 虽然回滚没有报错
- 但是数据并不会发生回滚了
- 因为事务在commit以后已经结束了
rollback;
select id, money
from employee
where id in (1, 2);
+----+-------+
| id | money |
+----+-------+
| 1 | 900 |
| 2 | 1100 |
+----+-------+
这篇关于数据据库八之 视图、触发器、事务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





