本文主要是介绍我们分析了100个拿到数据岗位Offer的留学生案例, 发现....,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当今IT届,除了软件工程师,最火热的职位非数据科学岗位(Data Science)莫属了:
据预测,未来3年企业对Data类岗位需求量将猛增28%
在薪资上,Data岗位平均年收入超过11万美元。其中,多个数据科学岗位平均年收入超过16万美元
在《H1B申请职位Top 10》中,跟data相关的职位占了4个
那么问题来了:
如何才能找到一份data岗位的工作呢?
”我们随机从硅谷IT黄埔军校 —— 来Offer的发布的真名实姓offer榜中,筛选出了100位成功拿到data岗位offer的优秀学员,并分析了他们的背景。

此为offer榜节选。查看完整offer榜单 (1-145周),欢迎登陆来Offer官方网站: www.laioffer.com

想知道:
他们都有什么共同点?
他们是如何拿到offer的?
那就继续看下去吧!
Q1: 他们都拿到了哪些公司的offer?
进入美国一线科技公司的同学占24%,进入银行、咨询、金融行业的同学占14%。
加入新兴独角兽的同学占11%,回国加入国内名企的同学占21%。
剩下的30%的同学也拿到了美国大中型公司的offer。
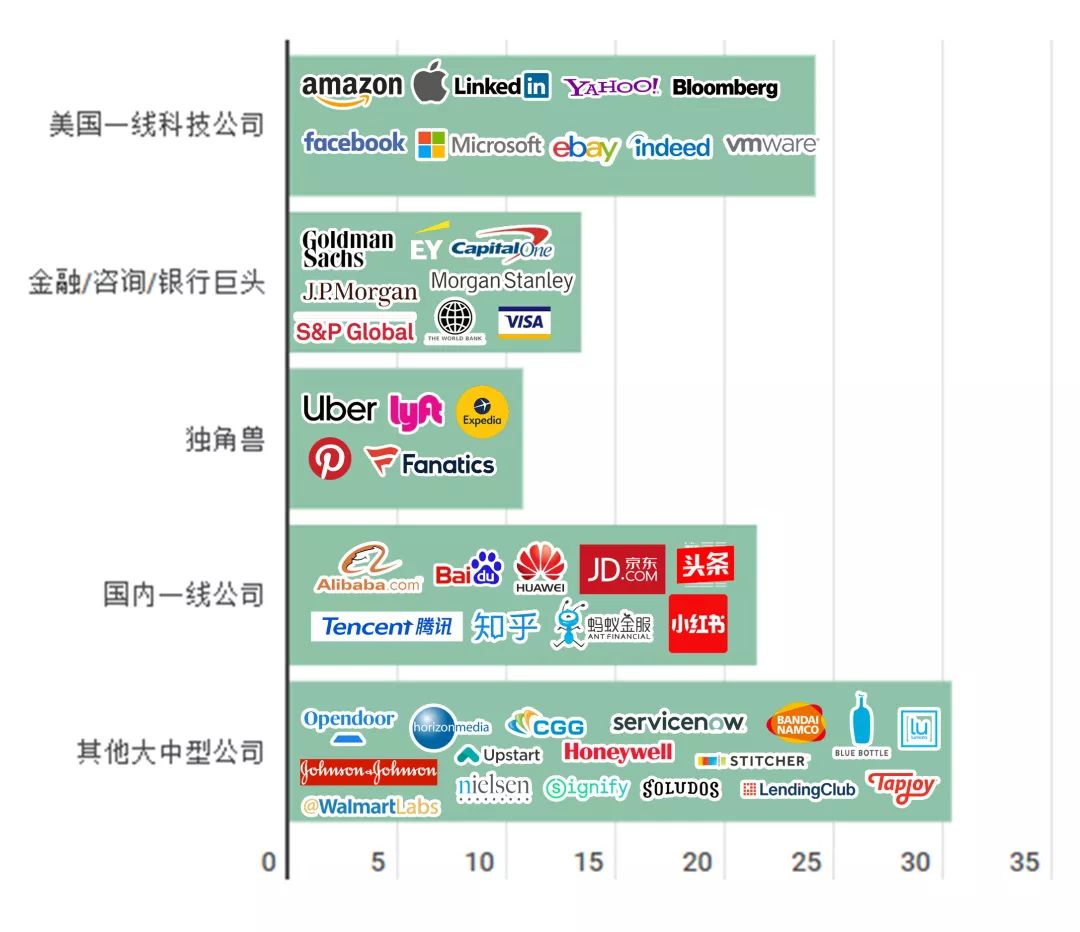
(数据来源:来Offer真名实姓offer榜)
Q2: 拿了这么多名企的offer,他们是否都是名校出身?
如果我们把US NEWS排名前30的学校算作名校,那么有一半的同学是非名校出身:
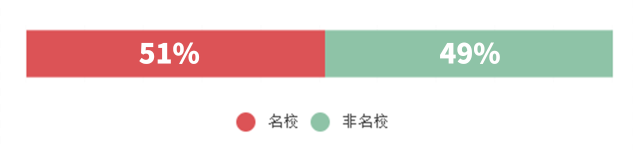
也许名校光环在找工作中会有锦上添花的作用,但这并非是能否加入一线公司的决定性因素。
Q3: 他们都获得了哪些职位的offer?
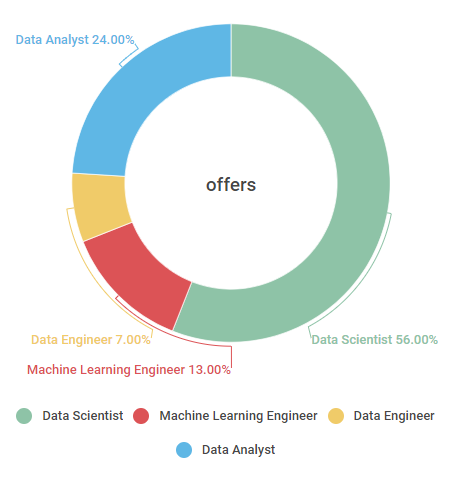
拿到Data Scientist offer的同学,居然占了56%!
要知道,Data Scientist可是被评为“the Sexist Job of 21st Century",在data行业里算求职难度比较高的岗位。
在剩下的同学中,
24%的同学拿到了Data Analyst offer,
13%的同学拿到了炙手可热的Machine Learning engineer的offer,
还有7%的同学拿到了Data Engineer offer
Q4: 这些职位有什么区别?
Data Scientist 数据科学家
数据科学家是这个行业中最高精尖的岗位。这个职位的工作主要是通过建立模型,做一些预测和推荐。
平均年薪:$141,317
Skill: Python\R\Stata\SQL\Matlab\Tableau\Rapidminer等
热门招聘行业:互联网\金融\医药等
Data Engineer 数据工程师
通过应用层和平台之间的数据管道进行数据库或大型处理系统的开发,测试,维护和处理大规模的大量数据。
平均年薪:$144,522
Skill: Java\Scala\C\Spark\Python\MapReduce\NoSQL…
热门招聘行业:软件\互联网\航空\信息技术等
Data Analyst 数据分析师
数据分析师涵盖了商业分析师(Business Analyst)和市场分析师(Marketing Analyst)的职责内容。
平均年薪:$91,507
Skill: Excel\SPSS\SAS\R\SQL\Tableau等
热门招聘行业:咨询\金融\快消\互联网等
Q5: 只有PhD才能做Data Scientist吗?
Data Scientist职位一直是很多名校PhD找工作时的首选,因此很多同学就误以为这个职位的门槛很高。
事实上,只要你掌握这个职位的技能,有这方面的实践经验,任何人都可以成为Data Scientist。
来Offer的offer榜就是最好的证明:
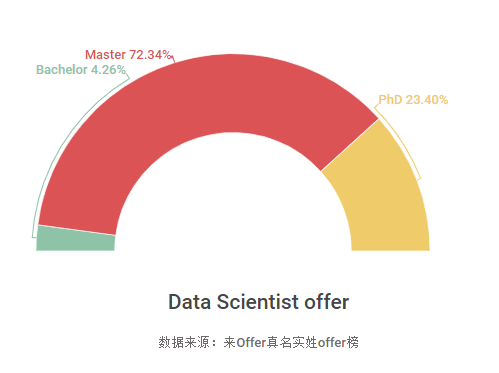
拿到DS offer的同学中,最主力的是Master学位的同学(72.34%),其次才是PhD。而且还有一些Bachelor degree的同学也拿到了DS offer!
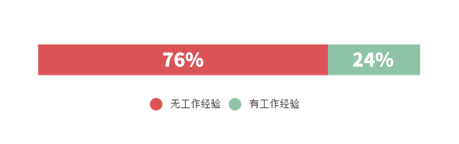
Q6. 无工作经验也能找到data工作吗?
根据来Offer offer榜上的数据显示,无工作经验但成功拿到offer的同学,占76%。
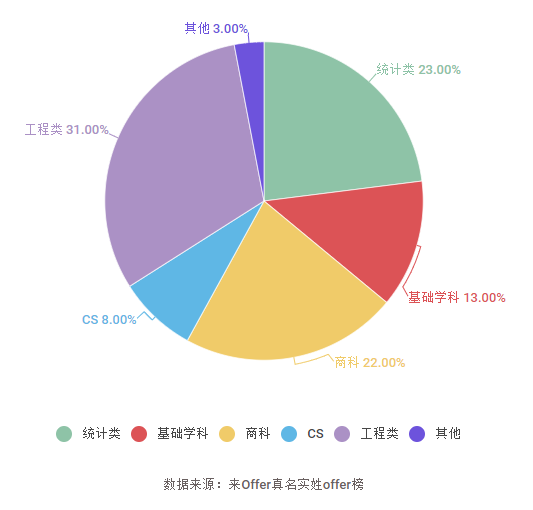
Q7. Data岗位对专业有什么要求?一定得是CS专业吗?
在成功拿到offer的学员里,CS专业的学生,只占7%!

任何专业的同学,都可以做Data类的工作:
Q8. 如何获得Data Science的offer?
这些榜单上的同学
他们都有一大共同点:
他们都报名了
【人工智能与数据科学强化课程】

Q9. 为什么这节课能帮助他们斩获那么多offer?
1
分track教学,双倍资源
全面攻破data所有岗位
不同于市面上其他培训机构,来Offer的data课程的教授内容,几乎覆盖了data行业所有岗位的考点和知识点。
学生可根据自己的职业目标,选择 Business Analyst Track 或 Data Scientist Track,也可以两个track的课一起上!
每个track,还有各自对应的project,提升同学们的专业技能:
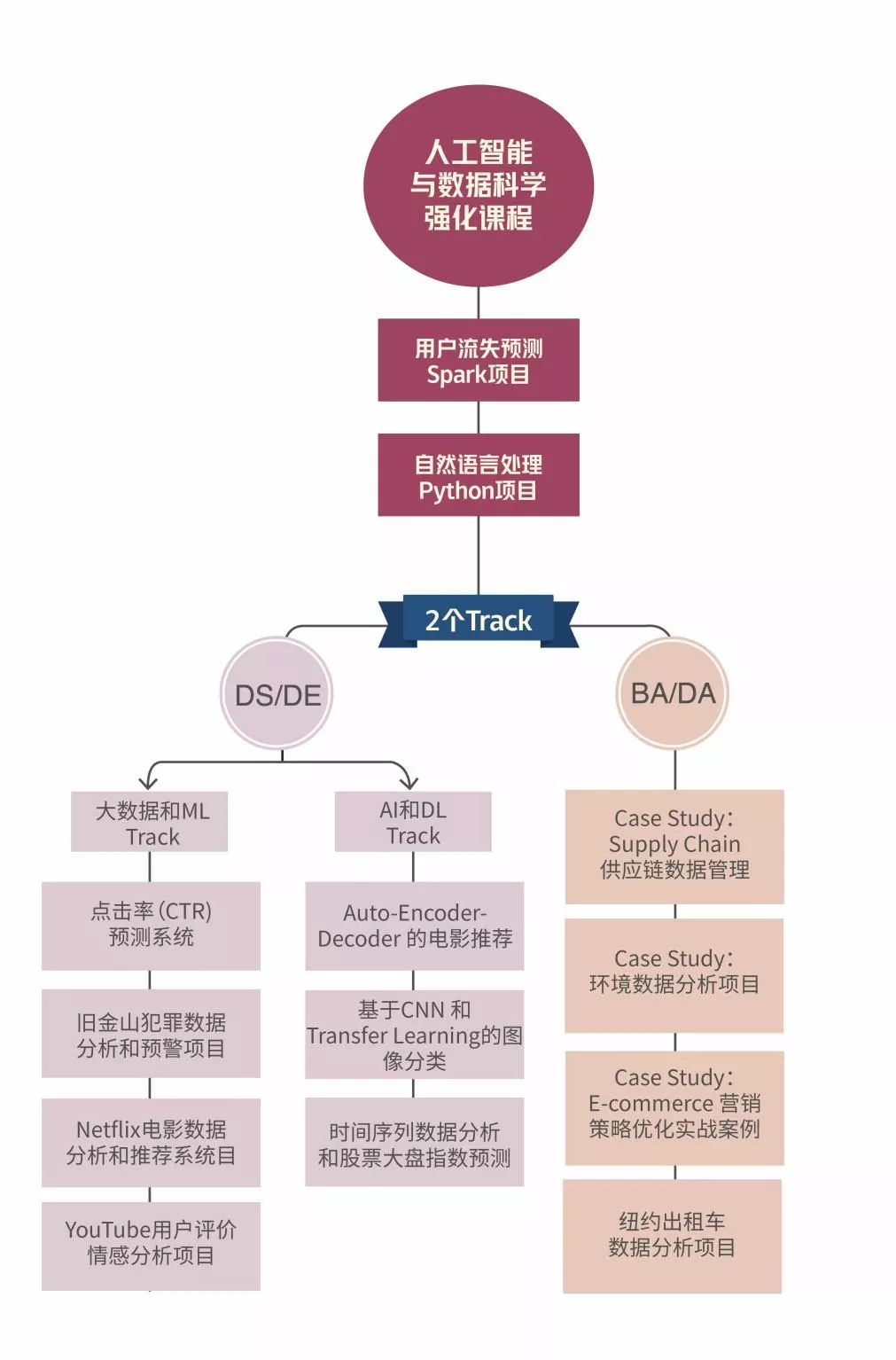
查看详细项目介绍,请登录官网:www.laioffer.com,或扫描下方二维码咨询

2
手把手coding,
消除你对编程的恐惧
很多同学会对data行业有这样的误解:
Data上手门槛低,
还不用接触编程?
诚然,如果你的目标是成为Business Analyst的话,这个职位对编程的要求确实比较低,可另一方面,BA也是data行业竞争人数最多且最激烈的领域。
而data行业的其他岗位如Data Engineer,Data Scientist等,在面试时,都对编程会有不同程度的考察。
在本课程中,为了拓宽同学的求职道路,老师们会教给同学们最实际、业界最受用的编程知识和技能:
30余节coding、算法与数据结构课程
10余种数据分析与机器学习模型精讲
老师会手把手带着同学们coding,课程还结合硅谷一线公司面试特点,加入了大量的数据结构训练、数据系统设计等内容,加强学生技术专业性。
3
谷歌/麦肯锡等精英老师,
是你坚强后盾

本课程由来自一线互联网企业、华尔街顶级咨询公司的20余位Manager级别的老师,3位TA共同授课。
➤ Data Scientist Track的授课团队由Google, Facebook, Airbnb等一线科技资深Data Scientist、Machine Learning Engineer组成。
➤ Business Analyst Track的授课团队由McKinsey, Hortonworks等顶级科技/咨询公司的资深Data Analyst、Business Analyst组成。
还有Apache Spark、Apache Hadoop的代码贡献者和管理者委员会成员亲自授课!
4
简历修改、模拟面试、
内推资源,一条龙服务

线上线下全线答疑
本课程采取线上直播授课形式,老师会积极与学员互动,随时解答学员们提出的疑问。
在课后,授课教师还会为每一名学生提供:
不限次数1对1简历修改
不限次数1对1模拟面试
不限次数多对1内推资源
1对1的简历修改辅导和Mock Interview, 并通过来Offer强大的内推团队为学生提供Job referral。
这么棒的课,现在提供免费试听啦!
就在11月28日,美西时间7PM!
课程咨询
添加来Offer课程顾问为好友
直接进行课程报名咨询
如需电话咨询,请发送简历至
ask@laioffer.com
老师将会在24小时内与你联系。
求职,你只需要一门课程

这篇关于我们分析了100个拿到数据岗位Offer的留学生案例, 发现....的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






