本文主要是介绍视觉Mamba:基于双向状态空间模型的高效视觉表征学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
https://arxiv.org/pdf/2401.09417v1.pdf
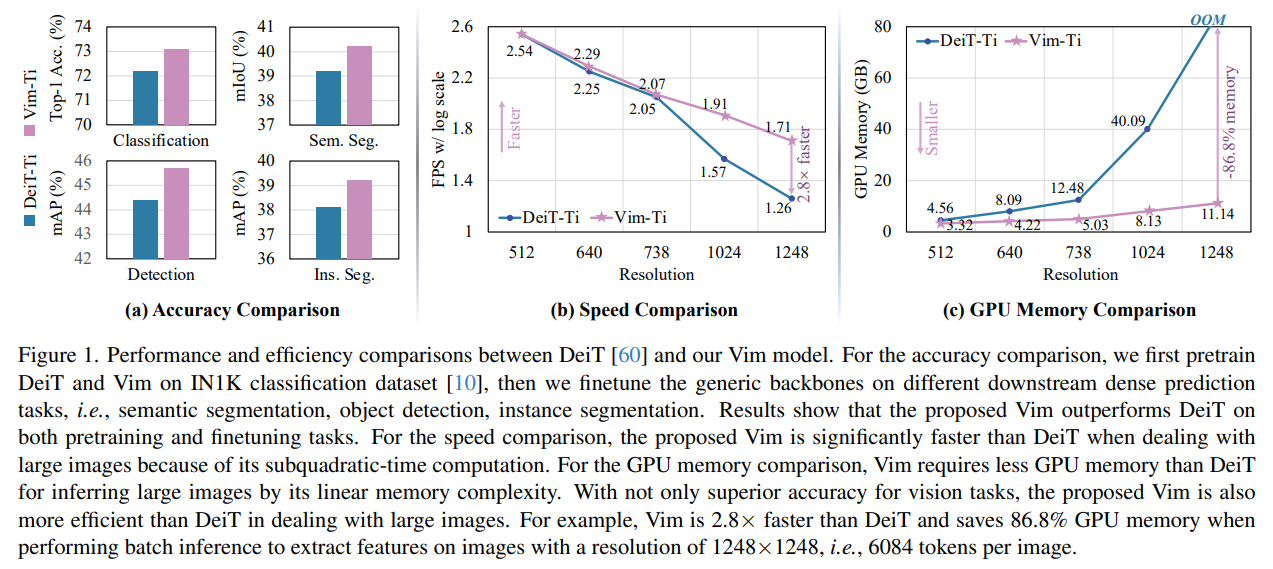
最近,具有高效硬件感知设计的状态空间模型(SSMs),例如Mamba,在长序列建模方面展现出了巨大潜力。纯粹基于SSMs构建高效和通用的视觉骨干网络是一个吸引人的方向。然而,由于视觉数据的空间敏感性和视觉理解的全局上下文需求,用SSMs表示视觉数据是一项挑战。本文表明,视觉表示学习对自注意力的依赖不是必需的,并提出了一个新的通用视觉骨干网络,该网络使用双向Mamba块(Vim),通过位置嵌入标记图像序列,并使用双向状态空间模型压缩视觉表示。在ImageNet分类、COCO目标检测和ADE20k语义分割任务上,Vim与DeiT等完善的视觉变换器相比性能更高,同时还显著提高了计算和内存效率。例如,Vim比DeiT快2.8倍,在执行批量推理以提取分辨率为1248×1248的图像特征时节省了86.8%的GPU内存。结果表明,Vim能够克服在执行高分辨率图像的Transformer风格理解时的计算和内存限制,并且有潜力成为下一代视觉基础模型的骨干网络。
1. 引言
最近的研究进展引发了对状态空间模型(SSM)的极大兴趣。源自经典的状态空间模型[30],现代的SSM在捕捉长距离依赖方面表现出色,并受益于并行训练。一些基于SSM的方法,如线性状态空间层(LSSL)[22]、结构化状态空间序列模型(S4)[21]、对角线状态空间(DSS)[24]和S4D[23],被提出用于处理各种任务和模式的序列数据,特别是在建模长距离依赖方面。由于卷积计算和近线性计算,它们在处理长序列时效率很高。2-D SSM [2]、SGConvNeXt [37]和ConvSSM [52]将SSM与CNN或Transformer架构相结合,用于处理2-D数据。最近的工作,Mamba [20],将时间变化参数纳入SSM,并提出了一个硬件感知算法,以实现高效的训练和推理。Mamba的优良扩展性能表明,它是语言建模中Transformer的有前途的替代品。然而,针对视觉任务的纯SSM基础骨干尚未被探索。
视觉Transformer(ViTs)在视觉表示学习方面取得了巨大成功,在大规模自监督预训练和下游任务的高性能方面表现出色。与卷积神经网络相比,其核心优势在于ViT可以通过自注意力为每个图像块提供与数据/补丁相关的全局上下文。这不同于使用相同参数(即卷积滤波器)的所有位置的卷积网络。另一个优势是模态无关的建模,将图像视为一系列没有2D归纳偏置的补丁,使其成为多模态应用的优选架构[3, 36, 40]。同时,Transformer中的自注意力机制在处理长距离视觉依赖关系时,例如处理高分辨率图像时,在速度和内存使用方面带来了挑战。
受到Mamba在语言建模方面取得成功的启发,我们可以将这一成功从语言转移到视觉,即设计一个使用先进SSM方法的通用且高效的视觉骨干网络,这非常吸引人。然而,Mamba面临两个挑战:单向建模和缺乏位置意识。为了解决这些挑战,我们提出了Vision Mamba(Vim)块,该块结合了双向SSM来进行数据依赖的全局视觉上下文建模,并使用位置嵌入进行位置感知的视觉识别。我们首先将输入图像分割成补丁,并将其线性投影为向量传递给Vim。在Vim块中,图像补丁被视为序列数据,通过提出的双向选择性状态空间有效地压缩视觉表示。此外,Vim块中的位置嵌入提供了对空间信息的感知,使Vim在密集预测任务中更加鲁棒。在目前阶段,我们在ImageNet数据集上使用监督图像分类任务训练Vim模型,然后使用预训练的Vim作为骨干来执行下游密集预测任务的视觉表示学习,例如语义分割、目标检测和实例分割。与Transformers一样,Vim可以在大规模无监督视觉数据上进行预训练以获得更好的视觉表示。由于Mamba的效率更高,Vim的大规模预训练可以以更低的计算成本实现。
与针对视觉任务的其他基于SSM的模型相比,Vim是一种纯SSM方法,以序列方式对图像进行建模,这对于通用且高效的骨干网络来说更有前途。由于具有位置意识的双向压缩建模,Vim是第一个用于处理密集预测任务的纯SSM基础模型。与最令人信服的基于Transformer的模型(即DeiT [60])相比,Vim在ImageNet分类方面取得了优越的性能。此外,Vim在GPU内存和推理时间方面更加高效,对于高分辨率图像而言,这使得Vim能够直接进行顺序视觉表示学习,而无需依赖于2D先验(例如ViTDet [38]中的2D局部窗口)来完成高分辨率视觉理解任务,同时实现了比DeiT更高的准确性。
我们的主要贡献可以总结如下:
• 我们提出了Vision Mamba(Vim),该模型结合了双向SSM进行数据依赖的全局视觉上下文建模,并使用位置嵌入进行位置感知的视觉理解。
• 无需注意力机制,提出的Vim具有与ViT相同的建模能力,同时具有亚二次时间复杂度和线性内存复杂度。具体来说,我们的Vim比DeiT快2.8倍,在执行批量推理以提取分辨率为1248×1248的图像特征时,可节省86.8%的GPU内存。
• 我们对ImageNet分类和下游密集预测任务进行了大量实验。结果表明,与完善的优化普通视觉Transformer(即DeiT)相比,Vim实现了优越的性能。
• 由于Mamba的高效硬件感知设计,Vim在处理高分辨率计算机视觉任务(例如视频分割、航空图像分析、医学图像分割和计算病理学)时比基于自注意力的DeiT更加高效。
2、相关研究
通用视觉骨干网络架构。在早期阶段,ConvNet [34]成为计算机视觉的默认标准网络设计。许多卷积神经架构[25, 26, 33, 50, 51, 56–58, 63, 72]已被提出作为各种视觉应用的视觉骨干网络。具有开创性的工作,Vision Transformer(ViT) [14]改变了这一领域。它将图像视为一系列平坦的2D补丁,并直接应用纯Transformer架构。ViT在图像分类及其扩展能力方面的出色结果激发了许多后续工作 [16, 59, 61, 62]。一方面的工作专注于通过将2D卷积先验引入ViT来设计混合架构 [9, 13, 15, 69]。PVT [66]提出了一个金字塔结构Transformer。Swin Transformer [42]在移位窗口内应用自注意力。另一方面的研究工作侧重于通过更先进的设置改进传统的2D ConvNets [41, 67]。ConvNeXt [43]回顾了设计空间并提出了纯ConvNets,这些ConvNets可以像ViT及其变种一样可扩展。RepLKNet [12]提出了将现有ConvNets的核大小扩大,以带来改进。
尽管这些主导的后续工作通过引入2D先验在ImageNet [10]和各种下游任务[39, 74]上展示了优越的性能和更高的效率,但随着大规模视觉预训练[1, 5, 17]和多模态应用[3, 29, 35, 36, 40, 49]的兴起,原始的Transformer风格模型重新回到了计算机视觉的中心舞台。较大的建模能力、统一的多元表示、对自监督学习的友好性等的优势,使其成为首选架构。然而,由于Transformer的二次复杂性,视觉令牌的数量有限。有许多工作[7, 8, 11, 32, 48, 55, 65]来解决这一长期存在的突出挑战,但其中很少关注视觉应用。最近,LongViT [68]通过膨胀注意力为计算病理学应用构建了一个高效的Transformer架构。LongViT的线性计算复杂性允许它编码极长的视觉序列。在这项工作中,我们受到Mamba [20]的启发,探索构建一个基于纯SSM的模型作为通用视觉骨干网,而无需使用注意力,同时保留了ViT的顺序、模态无关建模优点。
对于长序列建模的状态空间模型。 [21] 提出了一种结构化状态空间序列(S4)模型,这是CNN或Transformer之外的一种新颖替代方案,用于建模长距离依赖关系。线性序列长度扩展的有前途的特性吸引了进一步的探索。 [53] 通过引入MIMO SSM和高效的并行扫描,提出了一种新的S5层。 [18] 设计了一个新的SSM层H3,几乎填补了SSM和Transformer注意力在语言建模方面的性能差距。 [46] 通过引入更多的门控单元来提高表达性,在S4上构建了门控状态空间层。最近,[20] 提出了一种数据依赖的SSM层,并构建了一个通用的语言模型骨干网Mamba,它在大型真实数据上对各种规模的Transformer具有更好的性能,并享有线性序列长度扩展。在本工作中,我们探索将Mamba的成功转移到视觉领域,即构建一个基于SSM的通用视觉骨干网,而无需使用注意力。
视觉应用中的状态空间模型。 [27] 使用1D S4处理视频分类中的长时序依赖关系。 [47] 将1D S4进一步扩展到处理包括2D图像和3D视频在内的多维数据。 [28] 结合S4和自注意力的优点构建了TranS4mer模型,在电影场景检测方面达到了最先进的性能。 [64] 向S4引入了一种新颖的选择性机制,在长格式视频理解方面大幅提高了S4的性能,同时大大降低了内存占用。 [73] 用更可扩展的基于SSM的骨干网取代了注意力机制,以生成高分辨率图像并在可负担的计算下处理精细的表示。 [45] 提出了U-Mamba,这是一种混合CNN-SSM架构,用于处理生物医学图像分割中的长时序依赖关系。上述工作要么将SSM应用于特定的视觉应用,要么通过将SSM与卷积或注意力相结合来构建混合架构。与它们不同,我们构建了一个基于纯SSM的模型,它可以作为一个通用的视觉骨干网。
3、方法
Vision Mamba(Vim)的目标是将先进的SSM(即Mamba [20])引入计算机视觉。本节首先介绍了SSM的预备知识。随后概述了Vim。接着详细介绍了Vim块如何处理输入令牌序列,并继续说明了Vim的架构细节。最后对所提Vim的效率进行了分析。
3.1、预备知识
基于SSM的模型,即结构化状态空间序列模型(S4)和Mamba,受到了连续系统的启发,该系统通过隐藏状态h(t)将1-D函数或序列x(t)映射到y(t)。这个系统使用 A ∈ R N × N {A} \in \mathbb{R}^{\mathrm{N} \times \mathrm{N}} A∈RN×N作为演化参数,使用 B ∈ R N × 1 {B} \in \mathbb{R}^{\mathbb{N} \times 1} B∈RN×1和 C ∈ R 1 × N \mathbf{C} \in \mathbb{R}^{1 \times \mathrm{N}} C∈R1×N作为投影参数。
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ( t ) . \begin{aligned} h^{\prime}(t) & =\mathbf{A} h(t)+\mathbf{B} x(t), \\ y(t) & =\mathbf{C} h(t) . \end{aligned} h′(t)y(t)=Ah(t)+Bx(t),=Ch(t).
S4和Mamba是连续系统的离散版本,包括时间尺度参数 Δ \Delta Δ,用于将连续参数 A , B A,B A,B转换为离散参数 A , B A,B A,B。常用的转换方法是零阶保持(ZOH),其定义如下:
A ‾ = exp ( Δ A ) , B ‾ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B . \begin{array}{l} \overline{\mathbf{A}}=\exp (\boldsymbol{\Delta} \mathbf{A}), \\ \overline{\mathbf{B}}=(\boldsymbol{\Delta} \mathbf{A})^{-1}(\exp (\boldsymbol{\Delta} \mathbf{A})-\mathbf{I}) \cdot \boldsymbol{\Delta} \mathbf{B} . \end{array} A=exp(ΔA),B=(ΔA)−1(exp(ΔA)−I)⋅ΔB.
在离散化 A , B A,B A,B之后,使用步长 Δ \Delta Δ的方程(1)的离散化形式可以重写为:
h t = A ‾ h t − 1 + B
这篇关于视觉Mamba:基于双向状态空间模型的高效视觉表征学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





