本文主要是介绍数据可视化 pycharts实现时间数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自用版
数据格式为:

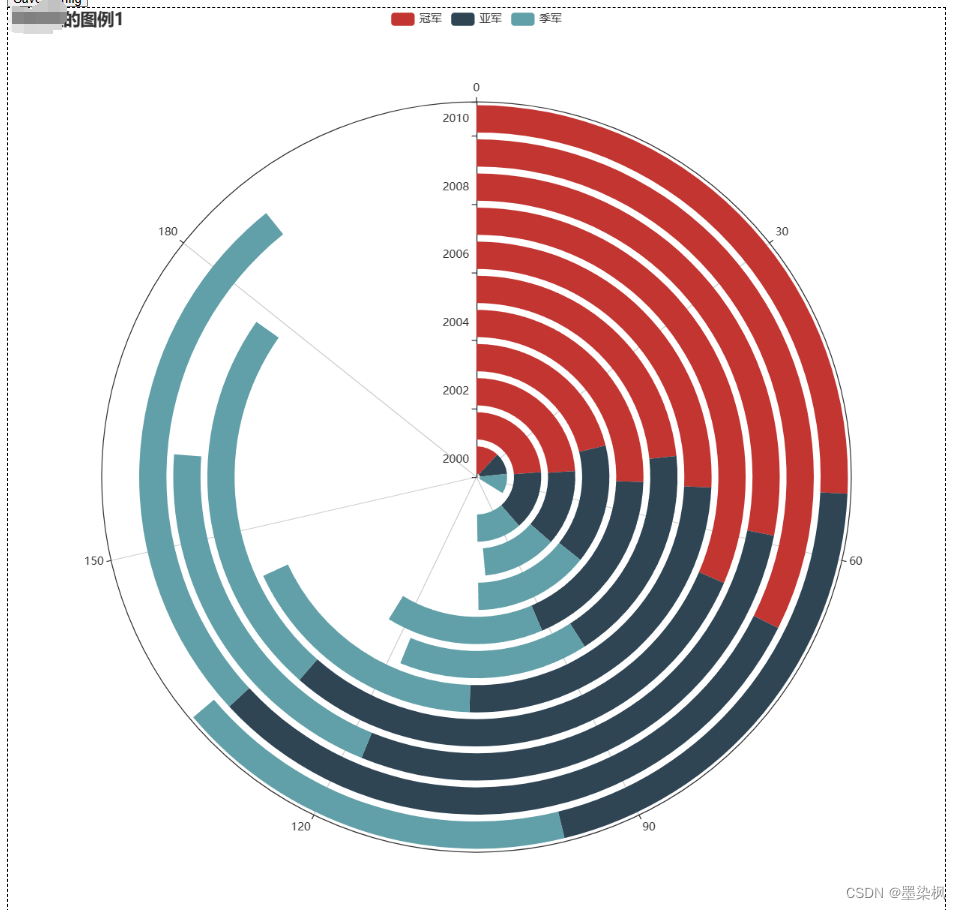
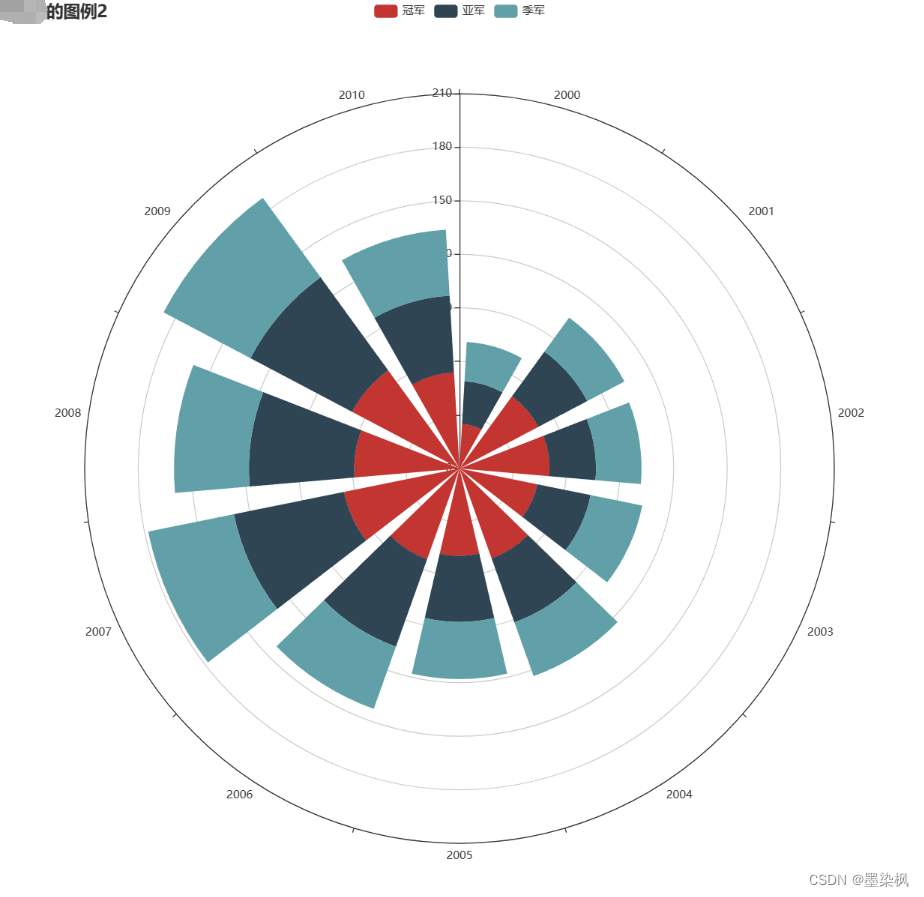
运行效果为:
from pyecharts import options as opts
from pyecharts.charts import Polar, Page
import csv
filename = "./hot-dog-places.csv"
data_x = []
data_y = []
with open(filename) as f:reader = csv.reader(f)for data_row in reader:data_x.append(data_row)
x = data_x[0]
y1 = data_x[1]
y1 = [float(i) for i in y1]
y2 = [float(i) for i in data_x[2]]
y3 = [float(i) for i in data_x[3]]
#作第一个图
def polar1() -> Polar:c1 = (Polar(init_opts=opts.InitOpts(width="1000px", height="1000px")).add_schema(radiusaxis_opts=opts.RadiusAxisOpts(data=x),angleaxis_opts=opts.AngleAxisOpts(is_clockwise=True)).add("冠军", y1, type_="bar", stack="stack0").add("亚军", y2, type_="bar", stack="stack0").add("季军", y3, type_="bar", stack="stack0").set_global_opts(title_opts=opts.TitleOpts(title="图例1"))
)return c1
#作第二个图
def polar2() -> Polar:c2 = (Polar(init_opts=opts.InitOpts(width="1000px", height="1000px")).add_schema(angleaxis_opts=opts.AngleAxisOpts(data=x, is_clockwise=True)).add("冠军", y1, type_="bar", stack="stack0").add("亚军", y2, type_="bar", stack="stack0").add("季军", y3, type_="bar", stack="stack0").set_global_opts(title_opts=opts.TitleOpts(title="图例2"))
)return c2
def creatPage():page = Page(layout=Page.DraggablePageLayout)page.add(polar1(),polar2())page.render("时间数据可视化实验.html")if __name__ == "__main__":creatPage()这篇关于数据可视化 pycharts实现时间数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



