本文主要是介绍Hbase - regionserver存储过程(写过程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
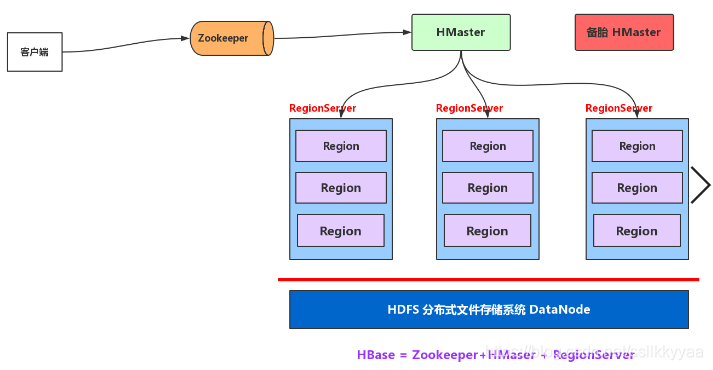
架构图
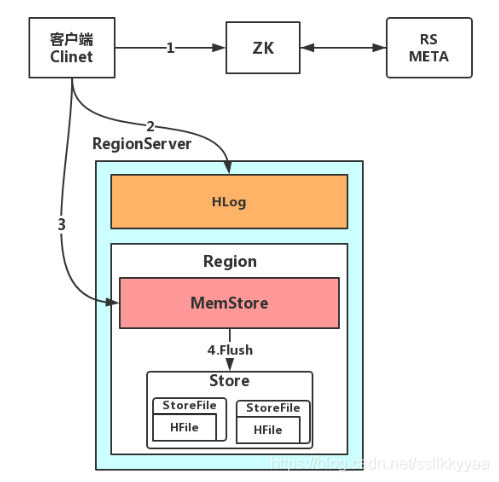
写入流程
Hadoop 生态圈
来源 Google 的三篇论文: 谷歌有三宝 计算(MapReduce) 存储(GFS)和 大表(BIgtable)
BigTable ---> HBase Hadoop DataBase
传统的关系型数据库 : Mysql Oracle 操作方式 : sql操作
什么叫做关系型数据库 : 基于关系模型提出来数据库,数据最终保存在一张二维表里面
HBase 是一个Nosql not only sql
简单对比 吞吐量
Mysql HBase
1000 + 100W+
关系型数据库 : 擅长的地方 增删改查 事务
非关系型数据库HBase : 擅长的地方 存储 和 读取 订单信息 历史数据
HBase基本架构模型
画 HBase 架构图方式
1. HBase 表结构
学校学生和成绩统计
Mysql 表 设计两张表 一张学生表 (年龄 ,姓名 ,性别....) 一张成绩表(语文,数学,英语,化学,物理..)
Hbase 只有一张表 , 以列族划分 数十亿行 数百万列
2. HBase 部署在庞大廉价的机器集群上面 阿里巴巴 12000
HBase工作机制
1.切分和分配大表
** 将一张大表切分,切分成一个个小单元(Region),分配到服务器集群上面,分别由每一台机器(RegionServer)托管一部分数据.一般情况下,RegionServer托管多个Region
2. 理论上可以把RegionServer当做HDFS 客户端 来对DataNode操作
3. 稀疏
4. 允许相同的行键存在
HBase的原理分析
1. HBase 写数据流程
* 请求Region所在的服务器
* 将数据写入 Hlog
* 将数据写入到 MemStore
* 经过累积Flush到Store ---> StoreFile ---> HFile
MemStore 什么时候刷盘
2. 寻找Region HBase meta
1. 找Zk 问 : Meta 表在哪 答 : 在 RS2
2. RS2 问 : 读取 XXX表里面的38行数据 在那个Region上面能找到,哪个RS为他提供服务 答 : RS1上面的Region3
3. 我要读取XXX表里面的38行数据 答案 : 好的那去吧
操作HBase
WebConsole : 端口号 16010
JavaAPI : 编写Java代码方式
命令行方式 :
启动HBase : start-hbase.sh
登入 : hbase shell
查看当前数据库的表 : list
创建表 : create '表名','列族名'
插入数据 : put '表名','行键','列族名:子项名称','值'
查看表描述 : desc '表名'
查看表数据 : scan '表名' get '表名','行键'
清空表 : truncate '表名' 禁用表disable table 删除表drop table 创建表 create table
删除表 : disable '表名' drop '表名' 删除表的时候不会立刻马上删除,先打上"墓碑",不能对表有任何操作
等到执行一次大合并的时候会进行删除.
这篇关于Hbase - regionserver存储过程(写过程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






