本文主要是介绍实战教学:用Semantic Kernel框架集成腾讯混元大模型应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导语 | 众所周知,Semantic Kernel 主要支持国外的两款大模型,但这对于开发者而言,显然是不够的,尤其是当我们希望对接国内的大模型时,我们应该怎么做呢?如何用 Semantic Kernel 通过 oneapi 来集成腾讯混元大模型应用?今天,我们特邀智用人工智能应用研究院 CTO 张善友老师,他将为我们带来手把手实战教学。
作者简介

张善友,智用人工智能应用研究院 CTO,毕业于兰州大学数学系,专注于云原生开发,推崇开源文化, 使用开源软件构建云原生软件系统,运营微信公众号“dotNet 跨平台”和 "新一代智能应用",推广和普及云原生技术在企业业务开发的应用。 从事 .NET 平台开发 20 年,业余爱好写作,在个人技术博客上撰写了大量的系列技术文章,并在腾讯云开发者社区开设专栏。
引言
腾讯混元大模型(Tencent Hunyuan)是由腾讯研发的大语言模型,具备强大的中文创作能力,复杂语境下的逻辑推理能力,以及可靠的任务执行能力。具体参见:腾讯混元大模型-腾讯云 (http://tencent.com)。
一、Semantic Kernel的功能特性
Semantic Kernel(简称SK)是一个轻量级的 SDK(软件开发工具包),旨在实现人工智能大型语言模型(LLM)与传统编程语言的集成。
这个工具包允许开发者将传统的编程语言与最新的大型语言模型相结合,以创建更智能、更强大的应用程序, SK 目前支持三种主流的编程语言 C#、Python 和 Java,其中 C# 的核心 API 已经发布了 1.0 版本,详见
https://github.com/microsoft/semantic-kernel
Semantic Kernel 提供了以下功能和特性:
● 模板和链接:它提供开箱即用的模板和链接,使开发者能够轻松地将大型语言模型的"提示"(suggestion)整合到其应用程序中。
● 深度集成:Semantic Kernel允许开发者在应用程序中充分利用与 Microsoft 365 Copilot 和 Bing 相同的人工智能协调模式,从而提高应用程序的智能程度。
● 应用程序集成:开发者可以将 Semantic Kernel 用于将语言模型与应用程序的开发技能和积累进行集成,从而增强应用程序的功能。
● 在使用语义内核开发解决方案时,我们可以使用一系列组件来为我们的应用程序提供更好的体验。并非所有这些都是强制性的,但建议熟悉它们。下面列出了符合语义内核的组件:
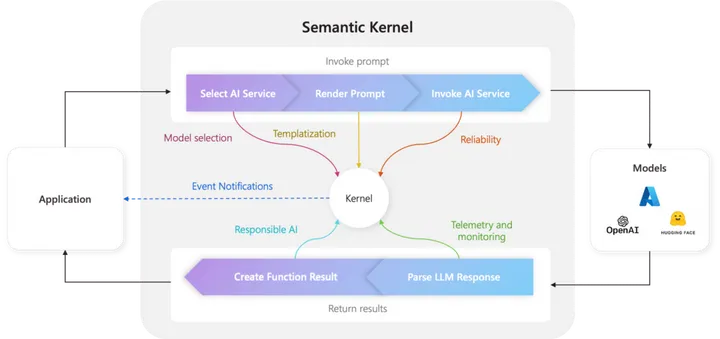
○ 内核(kernel): 在内核中,我们将注册所有连接器和插件,此外还要配置运行程序所需的内容。此外,我们还可以添加对日志和遥测的支持,以检查程序的状态和性能,并在必要时协助调试。
○ 记忆(memory): 我们来到允许我们为用户问题提供上下文的组件。这意味着我们的插件可以回忆过去与用户的对话,为他们提出的问题提供背景信息。
○ 计划器(planner): 计划器是一个函数,它接受用户的提示并返回执行计划来执行请求。计划器是SK 扩展性最强的一个组件,也是实现 Agent 的关键组件。
○ 连接(connector):连接器在 SK 中起着非常重要的作用,因为它们充当不同组件之间的桥梁,使它们之间能够交换信息。这些连接器可以被开发为与外部系统交互,例如与腾讯混元模型交互或使用 SQLite 数据库作为我们开发的内存。
○ 插件(plugin):插件可以被描述为一组函数,无论是原生的还是语义的,都暴露给 AI 服务和应用程序。
二、手把手配置One-API系统
Semantic kernel 可以支持各种大模型,今天我们就来看一看如何把 SK 和腾讯混元大模型集成起来。我们使用 MIT 协议的开源项目“one-api”:以 OpenAI 接口管理&分发系统,支持现有大模型场景,可用于二次分发管理 key,仅单可执行文件,已打包好 Docker 镜像,一键部署,开箱即用,
https://github.com/songquanpeng/one-api
简单而言,我们使用 Semantic kernel 的 OpenAI connector 连接到 oneapi,这样就可以使用 OpenAI 的接口访问腾讯混元大模型。
OneAPI 支持使用 docker 部署,操作简单,fork one-api 仓库,使用仓库里提供的 docker-compose.yml 搭建就很简单。具体命令如下:docker-compose up -d
等待应用启动完成后,在浏览器中输入 IP+端口,例如:
http://192.168.10.12:3000
,系统本身是开箱即用,直接使用默认的 root 用户登录系统即可。初始账号用户名为 root,密码为 123456。在登录系统后,我们需要立刻到用户管理中将密码修改成其它的。
而渠道则可以简单理解为各个大模型厂商,可以是原始厂商,也支持代理厂商,每家厂商又可以支持多种模型,点击渠道,然后点击添加新的渠道。
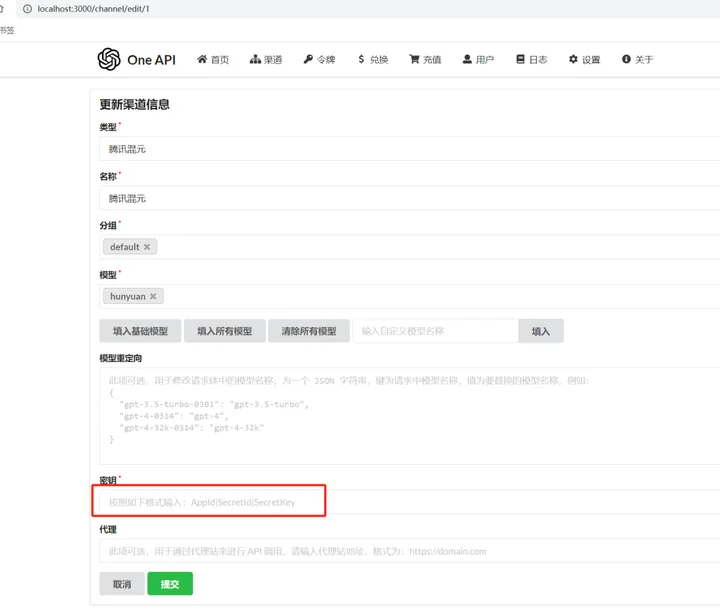
类型:选择 腾讯混元,会自动带出下面的模型:hunyuan
名称:自己自拟名字即可,一个代号
分组:模型分组使用,支持多选。目前仅支持内置的 3 种分组,分别是:default、vip、svip
模型:选完类型后会自动弹出来,支持多选,也支持自己填写
模型重定向:假如用户传入的模型是 A,系统可以自动改成 B
密钥:从大模型厂商获得的 API Key,每家厂商的填写格式可能都不一样,选完类型以后会有提示,按照提示填写,填写密钥为腾讯云的密钥管理— API 密钥管理里获取 APPID、SecretId 和 Secretkey

接着,我们创建令牌,供客户端或调用方使用,其作用跟大模型厂商的令牌或密钥的概念和作用是一样的。点击令牌,然后点击添加新的令牌,如图添加即可,过期时间可以选择永不过期。
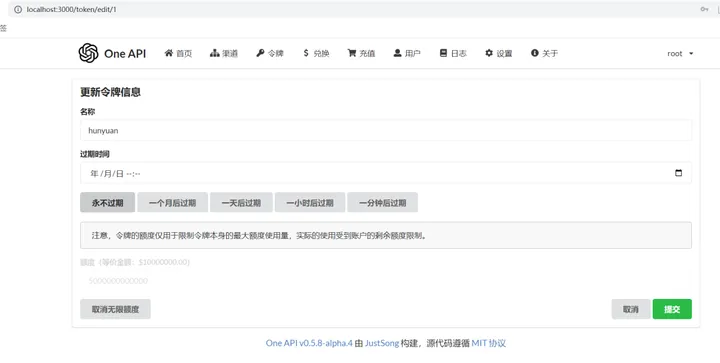
如图,然后点击复制即可:

这个令牌相当于 OpenAI 的 apikey:
sk-1Ib4X0HmR4HzXXZ644D1DdCa96934f0199Dc2b0e162b524d
日志展示用户充值和额度消耗记录,普通用户与管理员用户查看的范围不一样,普通用户只能看到自己的。

以上我们便已经安装并配置好了 One API 系统,那么如何给终端使用呢?其实很简单,使用客户端或编程的方式调用 One API 的 API 接口就行了,使用方式与OpenAI API 一致。相当于只需要将 OpenAI 的网址改成你部署的 One API 系统的网址、将 OpenAI 的 API Key 改成你的令牌即可。One API 将代理用户向实际的大模型发出请求并接收响应,如下图所示:
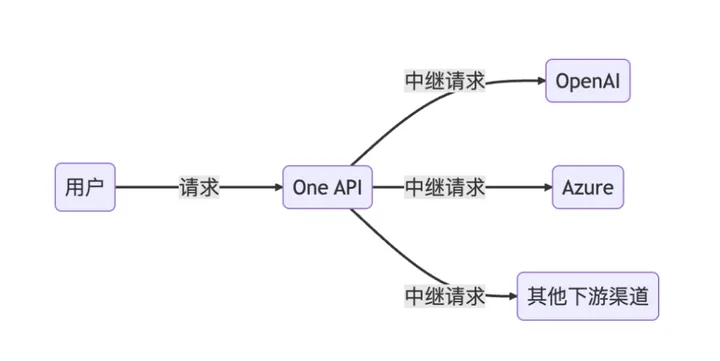
另外需要特殊说明下,前面我们提到每个用户分组是可以支持多个渠道的(即多个模型负载均衡),如果你在客户端想指定使用某个渠道,可以通过在令牌后面添加渠道 ID 的方式指定使用哪一个渠道处理本次请求,例如:Authorization: Bearer ONE_API_KEY-CHANNEL_ID。 注意,需要是管理员用户创建的令牌才能指定渠道ID。
三、SK+one-api+openai connector集成腾讯混元大模型
通过 oneapi 我们将腾讯混元大模型转换为 OpenAI 的格式,通过 SK 的 OpenAI 的 Connector 访问,这里需要做的是把 openai 的 Endpoint 指向 oneapi,这个我们可以通过一个自定义的 HttpClient 来完成这项工作,例如下面的这个示例:
internal class OpenAIHttpclientHandler : HttpClientHandler
{private KernelSettings _kernelSettings;public OpenAIHttpclientHandler(KernelSettings settings){this._kernelSettings = settings;}protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken){if (request.RequestUri.LocalPath == "/v1/chat/completions"){UriBuilder uriBuilder = new UriBuilder(request.RequestUri){Scheme = this._kernelSettings.Scheme,Host = this._kernelSettings.Host,Port = this._kernelSettings.Port};request.RequestUri = uriBuilder.Uri;}return await base.SendAsync(request, cancellationToken);}
}上面我们做好了所有的准备工作,接下来就是要把所有的组件组装起来,让它们协同工作。因此打开 Visual studio code 创建一个 c# 项目 sk-csharp-hello-world,其中 Program.cs 内容如下:
using System.Reflection;
using config;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using Microsoft.SemanticKernel.PromptTemplates.Handlebars;
using Plugins;var kernelSettings = KernelSettings.LoadSettings();
var handler = new OpenAIHttpclientHandler(kernelSettings);
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddLogging(c => c.SetMinimumLevel(LogLevel.Information).AddDebug());
builder.AddChatCompletionService(kernelSettings,handler);
builder.Plugins.AddFromType<LightPlugin>();Kernel kernel = builder.Build();// Load prompt from resource
using StreamReader reader = new(Assembly.GetExecutingAssembly().GetManifestResourceStream("prompts.Chat.yaml")!);
KernelFunction prompt = kernel.CreateFunctionFromPromptYaml(reader.ReadToEnd(),promptTemplateFactory: new HandlebarsPromptTemplateFactory()
);// Create the chat history
ChatHistory chatMessages = [];// Loop till we are cancelled
while (true)
{// Get user inputSystem.Console.Write("User > ");chatMessages.AddUserMessage(Console.ReadLine()!);// Get the chat completionsOpenAIPromptExecutionSettings openAIPromptExecutionSettings = new(){};var result = kernel.InvokeStreamingAsync<StreamingChatMessageContent>(prompt,arguments: new KernelArguments(openAIPromptExecutionSettings) {{ "messages", chatMessages }});// Print the chat completionsChatMessageContent? chatMessageContent = null;await foreach (var content in result){System.Console.Write(content);if (chatMessageContent == null){System.Console.Write("Assistant > ");chatMessageContent = new ChatMessageContent(content.Role ?? AuthorRole.Assistant,content.ModelId!,content.Content!,content.InnerContent,content.Encoding,content.Metadata);}else{chatMessageContent.Content += content;}}System.Console.WriteLine();chatMessages.Add(chatMessageContent!);
}首先,我们做的第一件事是导入一堆必要的命名空间,使一切正常(第 1 行到第 9 行)。
然后,我们创建一个内核构建器的实例(通过模式,而不是因为它是构造函数),这将有助于塑造我们的内核。
IKernelBuilder builder = Kernel.CreateBuilder();
你需要知道每时每刻都在发生什么吗?答案是肯定的!让我们在内核中添加一个日志。我们在第 14 行添加了日志的支持。
我们想使用 Azure,OpenAI 中使用 Microsoft 的 AI 模型,以及我们腾讯混元的 AI 模型,我们可以将它们包含在我们的内核中。正如我们在 15 行看到的那样:
/// <summary>/// Adds a chat completion service to the list. It can be either an OpenAI、 Azure OpenAI or tencent hunyuan backend service ./// </summary>/// <param name="kernelBuilder"></param>/// <param name="kernelSettings"></param>/// <exception cref="ArgumentException"></exception>internal static IKernelBuilder AddChatCompletionService(this IKernelBuilder kernelBuilder, KernelSettings kernelSettings, HttpClientHandler handler){switch (kernelSettings.ServiceType.ToUpperInvariant()){case ServiceTypes.AzureOpenAI:kernelBuilder = kernelBuilder.AddAzureOpenAIChatCompletion(kernelSettings.DeploymentId, endpoint: kernelSettings.Endpoint, apiKey: kernelSettings.ApiKey, serviceId: kernelSettings.ServiceId, kernelSettings.ModelId);break;case ServiceTypes.OpenAI:kernelBuilder = kernelBuilder.AddOpenAIChatCompletion(modelId: kernelSettings.ModelId, apiKey: kernelSettings.ApiKey, orgId: kernelSettings.OrgId, serviceId: kernelSettings.ServiceId);break;case ServiceTypes.HunyuanAI: kernelBuilder = kernelBuilder.AddOpenAIChatCompletion(modelId: kernelSettings.ModelId, apiKey: kernelSettings.ApiKey, httpClient: new HttpClient(handler));break;default:throw new ArgumentException($"Invalid service type value: {kernelSettings.ServiceType}");}return kernelBuilder;}
}我们可以为内核中导入在不同模型后端使用的插件,如第 16 行所示。为此,我们导入第 21 行到第 25 行中的语义函数。我们所做的是传递 yaml 文件编写的语义提示词。之后我们的内核和我们的插件就可以使用了。
接下来开启一个聊天循环,使用 SK 的流式传输 InvokeStreamingAsync,如第 42 行到 46 行代码所示,运行起来就可以体验下列的效果:
结语
有了 Semantic kernel 这个新框架,无论我们是在桌面上使用 AvaloniaUI 构建应用,还是在服务器上使用 http://ASP.NET Core 构建后端服务,都为未来将人工智能集成到我们的开发中奠定了基础。也许最重要的是,我们更应该关注使用其公司数据将新的人工智能服务集成到其应用程序中,并始终确保该数据的隐私合规性。
在「腾讯云TVP」公众号后台回复「大模型」,即可下载本文完整的源代码~
这篇关于实战教学:用Semantic Kernel框架集成腾讯混元大模型应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







