本文主要是介绍第93讲:MySQL主从复制集群延时从库的核心概念以及使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.延时从库的概念
- 2.配置从库延时
- 3.模拟主库误删除使用延时从库恢复数据
- 3.1.模拟主库误删除操作
- 3.2.利用从库延时恢复主库误删除的数据
1.延时从库的概念
延时从库和主从延时是两个概念,延时从库指的是认为手动配置一个从库延时复制主库的时间,当主库有新数据产生后,从而经过xxx时间后再进行复制同步。
可以通过延时从库,当主库有误删除操作时,由于从库配置了延时从库,可以避免误删除的指令也在从库中执行,我们可以利用从库去还原数据。
在企业生产环境中,延时从库的时间一般都在3~6小时左右。要有足够的延时事件供运维去排查问题。
2.配置从库延时
设置从库延时事件为300秒。
mysql> stop slave;
mysql> change master to master_delay = 300;
mysql> start slave;

3.模拟主库误删除使用延时从库恢复数据
模拟主库误删除使用延时从库恢复数据的思路:
- 首先配置好延时从库的时间。
- 然后模拟主库误删除故障。
- 迅速反应到主库误删除了,然后利用延时从库的时间,去恢复误删的数据:
- 首先停止从库的SQL线程,停止主库业务,避免新数据再写入。
- 模拟SQL线程,截取relaylog中误删除时的日志数据。
- 然后手动恢复截取的Binlog日志,验证数据的可用性。
3.1.模拟主库误删除操作
在主库中执行下面的SQL,创建一个数据库,创建一个表,写入几条数据,然后删除数据库。
mysql> create database db_test;
mysql> use db_test;
create table t1(id int);
insert into t1 values (1),(2),(3);
drop database db_test;
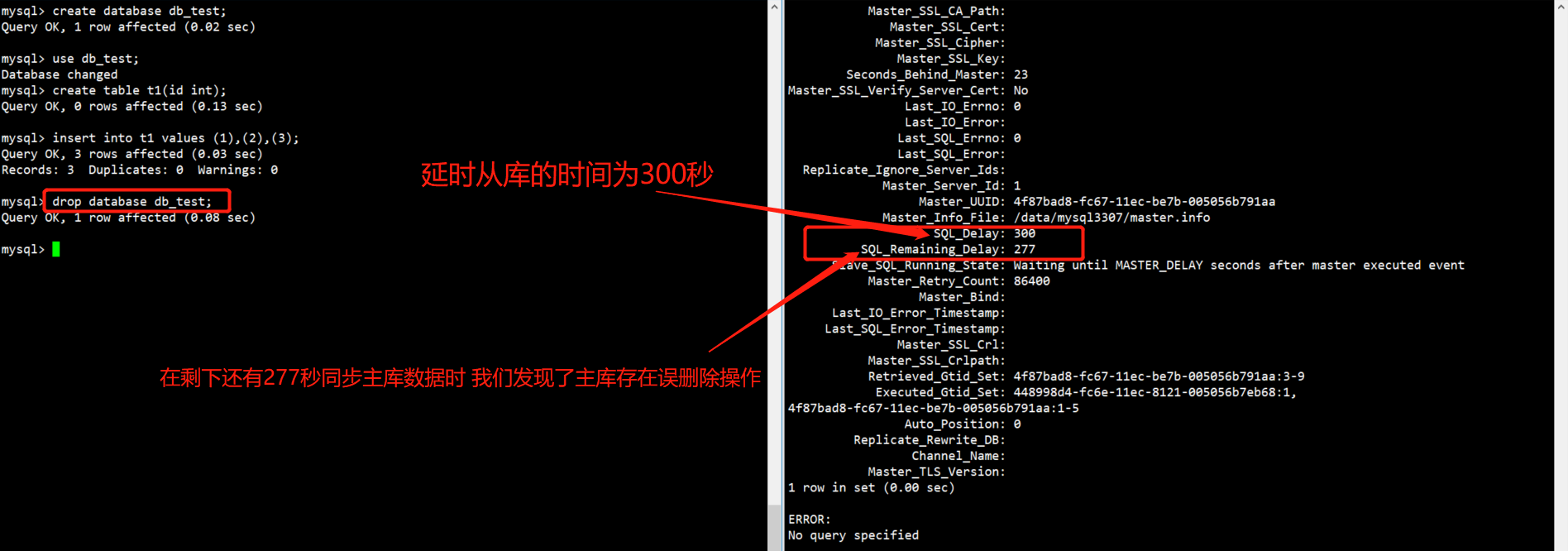
一系列操作完成后,主库的数据被误删除,在从库的状态中,我们可以看到还有277秒从库就会将主库的操作同步过来。
3.2.利用从库延时恢复主库误删除的数据
在还有277秒就要将主库操作同步到从库时,我们发现了主库的误操作行为,为了防止将从库的数据也误删除,我们决定先停止掉从库的SQL线程,然后通过从库延时还未执行的主库传来的Binlog日志,恢复主库误删除的数据。
1)停止从库的SQL线程
mysql> stop slave sql_thread;
2)截取从库未执行的Relaylog日志
延时从库指的是经过一段时间后,再执行主库传输的Binlog,主库传输的Binlog会写入到Relaylog中,我们要截取主库误删除操作之前的Binlog,通过Binlog去还原主库误删除的数据。
1.获取截取Relaylog日志的起点
#通过查看从库的状态就可以看-2到上次执行的Relay log位置号,这个号就可以作为Relay Log截取的起点。
mysql> show slave status\G;Relay_Log_File: mysql-2-relay-bin.000004Relay_Log_Pos: 360
#起点为3602.获取截取Relaylog日志的终点
#relaylog记录的就是Binlog日志,也有专门看relaylog中事件标识位的命令
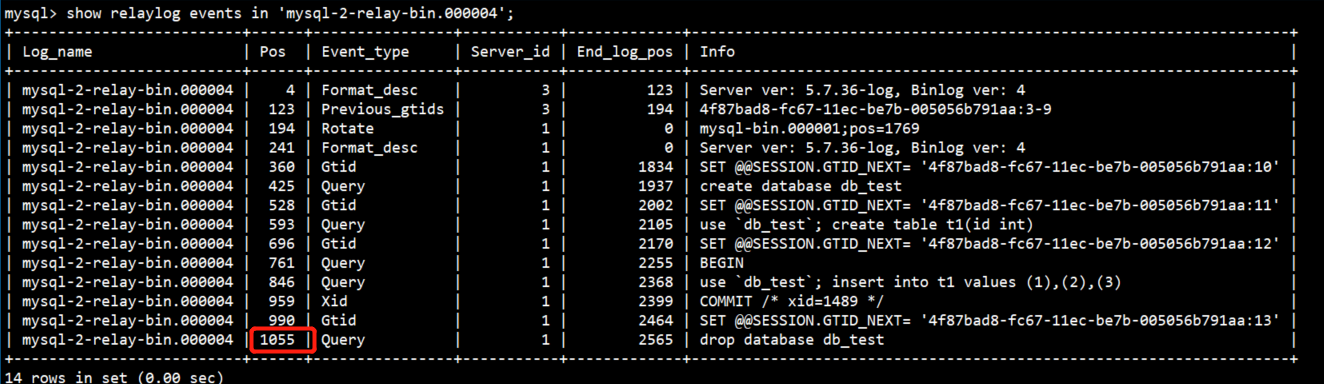
mysql> show relaylog events in 'mysql-2-relay-bin.000004';
#找到删除操作的标识位号,终点为1055
Relaylog事件中,End_log_pos一列不需要关注,这一列记录的是主库Binlog中该事件对应的Position号。
3.截取日志
[root@mysql-2 ~]# mysqlbinlog --start-position=360 --stop-position=1055 /data/mysql3307/mysql-2-relay-bin.000004 > wsc.sql4.将截取的Binlog传输到主库中还原数据
[root@mysql-2 ~]# scp -rp wsc.sql root@192.168.20.11:/root
mysql> source /root/wsc.sql5.启动从库SQL线程
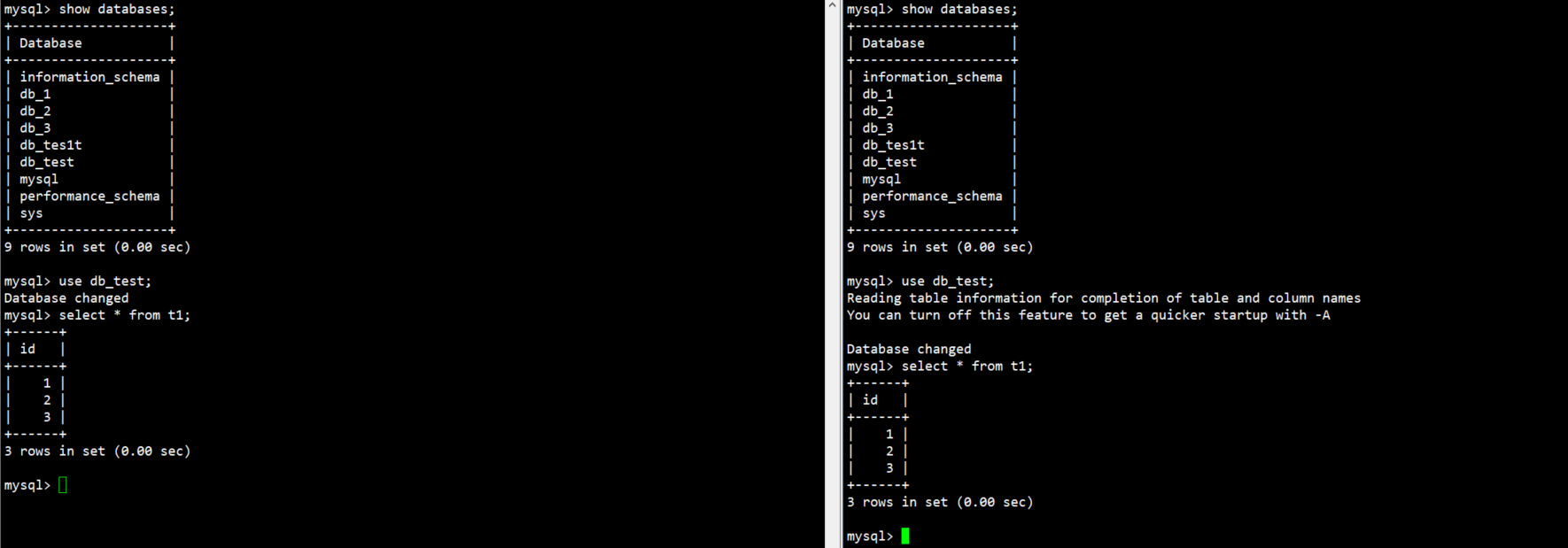
mysql> start slave;6.数据还原成功并且也复制到了从库
这篇关于第93讲:MySQL主从复制集群延时从库的核心概念以及使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




