本文主要是介绍中科星图——MODIS/006/MYD13A1的MYD13A1.006类数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据名称:
MYD13A1.006
Modis
16天
Aqua
500m
数据来源:
NASA
时空范围:
2000-2022年
空间范围:
全国
数据简介:
MOD13A1 V6数据集是由Aqua星搭载的中分辨率成像光谱仪获取的L3级植被指数产品,空间分辨率为500米,具备两个主要的植被层,分别是栅格归一化植被指数(NDVI)和增强型植被指数(EVI)。产品遵循低云、低视角和最高NDVI/EVI值的原则,从获取的16天数据中选择最佳值作为影像的像素值。可用于检测植被状态和土地覆盖利用变化,并且,能够进一步用于生物化学、水循环过程和全球及区域性的气候研究,还有LAI、GPP等参数的反演。前言 – 人工智能教程
L3级植被指数产品是通过中分辨率成像光谱仪在Aqua星上获取的数据进行处理得到的。植被指数是一种用于评估植被生长状况的指标,通常使用的植被指数包括归一化植被指数(Normalized Difference Vegetation Index,NDVI)等。
L3级植被指数产品是通过对Aqua星获取的数据进行校正和处理得到的。首先,原始数据需要进行辐射校正,以消除大气影响。然后,根据已有的植被指数算法,计算每个像素点的植被指数数值。最后,将植被指数数值按照一定的空间分辨率进行聚合,得到L3级植被指数产品。
L3级植被指数产品通常包括NDVI和其他相关的植被指数,以及植被指数的时间序列数据。这些产品可以用于监测和评估植被的生长状况,例如农作物监测、森林管理、草原监测等。同时,L3级植被指数产品还可以用于分析植被的时空变化特征,帮助研究者和决策者了解植被的生态环境。
引用代码:
MODIS/006/MYD13A1
波段
| 名称 | 波段 | 单位 | 最小值 | 最大值 | 比例因子 | 波长 | 描述 |
|---|---|---|---|---|---|---|---|
| NDVI | B1 | NDVI | -2000 | 10000 | 0.0001 | Normalized Difference Vegetation Index | |
| EVI | B2 | EVI | -2000 | 10000 | 0.0001 | Enhanced Vegetation Index | |
| VIQ | B3 | Bit Field | VI quality indicators | ||||
| RR | B4 | 0 | 10000 | 0.0001 | 645nm | Red surface reflectance | |
| NIRR | B5 | 0 | 10000 | 0.0001 | 858nm | NIR surface reflectance | |
| BR | B6 | 0 | 10000 | 0.0001 | 469nm | Blue surface reflectance | |
| MIRR | B7 | 0 | 10000 | 0.0001 | 2130nm/2105-2155nm | MIR surface reflectance | |
| VZA | B8 | Degree | 0 | 18000 | 0.01 | View zenith angle | |
| SZA | B9 | 0 | 18000 | 0.01 | Solar zenith angle | ||
| RAA | B10 | -18000 | 18000 | 0.01 | Relative azimuth angle | ||
| CDOY | B11 | Julian day | 1 | 366 | Julian day of year | ||
| PR | B12 | Rank | Quality reliability of VI pixel |
代码
/*** @File : MYD13A1.006* @Time : 2023/06/06* @Author : GEOVIS Earth Brain* @Version : 0.1.0* @Contact : 中国(安徽)自由贸易试验区合肥市高新区望江西路900号中安创谷科技园一期A1楼36层* @License : (C)Copyright 中科星图数字地球合肥有限公司 版权所有* @Desc : 数据集key为MODIS/006/MYD13A1的MYD13A1.006类数据集* @Name : MYD13A1.006数据集
*/
//指定检索数据集,可设置检索的空间和时间范围,以及属性过滤条件
var imageCollection = gve.ImageCollection("MODIS/006/MYD13A1").filterDate('2022-01-01','2022-01-15').select(['NDVI']).limit(10);print("imageCollection",imageCollection);var img = imageCollection.first();print("first", img);var visParams = {
// gamma: 1,
// brightness: 1,min: 0,max: 10000,palette: {"band_rendering": {"pseudocolor": {"colormap": ['#FCD163','#66A000','#3E8601','#004C00','#023B01']}}}
};Map.centerObject(img);
Map.addLayer(img,visParams);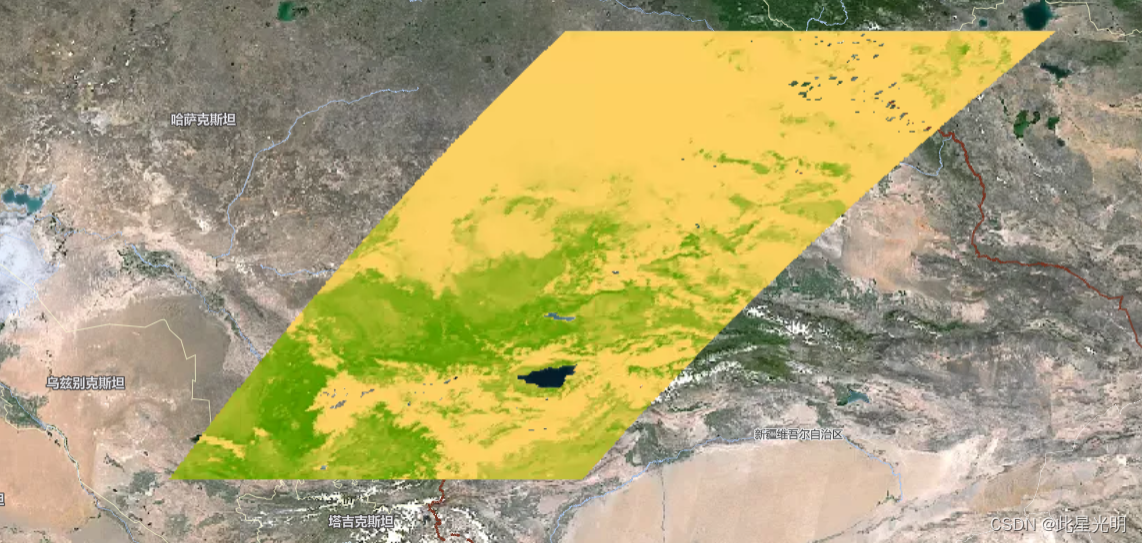
通过LP DAAC获得的MODIS数据和产品在后续使用,销售或再分发没有任何限制,具体请参阅https://lpdaac.usgs.gov/data/data-citation-and-policies/
这篇关于中科星图——MODIS/006/MYD13A1的MYD13A1.006类数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





