本文主要是介绍BTC的数据结构Merkle Tree和Hash pointer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
比特币是一种基于区块链技术的加密数字货币,其底层数据结构被设计为分布式,去中心化的。它的核心数据结构是一个链式的区块,每个区块都包含了多笔交易记录和一个散列值。
比特币的底层数据结构使用了两个关键概念:hash pointer和 Merkle Tree
-
Hash pointer
在介绍hash pointer之前,先回顾下普通的指针。
在程序运行过程中,需要用到数据。最简单的是直接获取数据,但当数据本身较大,需要占用较大空间时,明显会造成一定麻烦。因此,可以引入指针这一概念。当需要获取数据时,只需要按照指针所给的地址,去对应的位置读取数据即可,这样大大节省了内存空间。
这个很好理解。
哈希指针是用于链接数据块并保证其数据的完整性。每个数据块的哈希值包含其上一个数据块的哈希值,因此如果对数据块进行修改,哈希值也会发生变化,其他节点就可以检测到不匹配并防止任何对历史数据的篡改。
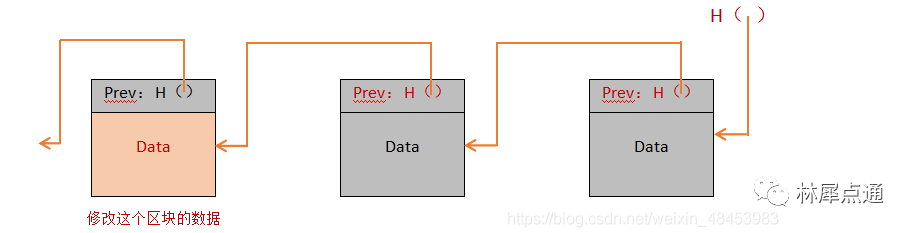
例如,我篡改了第一个区块中的数据,那么第二个区块的H()的值就会变,像多米诺骨牌一样,最终会传导到最后一个区块,所以你只需要记住最后一个区块的hash值,就可以知道前面的区块是否被篡改过。
从这里也不难看出,区块链和普通的单向链表最大区别是,区块链使用的是hash pointer来链接两个区块。
-
Merkle Tree
Merkle Tree翻译为默克尔树,是一种树形数据结构,和普通的tree相比,就是使用了哈希指针来代替普通的指针。
如下:为一个简单的Merkle Tree,其中A、B、C、D为数据块。A和B各有一个哈希值,将其合并放在一个节点中,C和D同样操作,而后,针对得到的两个节点分别取哈希,又可以得到两个新的哈希值,即为图中根节点。实际中,在区块块头中存储的是根节点的哈希值(对其再取一次哈希)。

该数据结构的优点在于:
只需要记住Root Hash(根哈希值),便可以检测出对树中任何部位的修改。
-
总结
比特币中网络节点是分为全节点和轻节点的,绝大多数的节点都是轻节点,轻节点只需要保存块头的数据,也就是上图中的Root Hash,而不需要存储ABCD节点的数据。轻节点的数据验证就很简单了。
当需要向轻节点证明某条交易是否被写入区块链,便需要用到Merkle proof。我们将交易到根节点这一条路径称为Merkle proof,全节点将整个Merkle proof发送给轻节点(如下图所示),轻节点即可根据其算出根哈希值,和自己保存的对比,从而验证该交易是否被写入区块链。只要沿着该路径,所有哈希值都正确,说明内容没有被修改过。
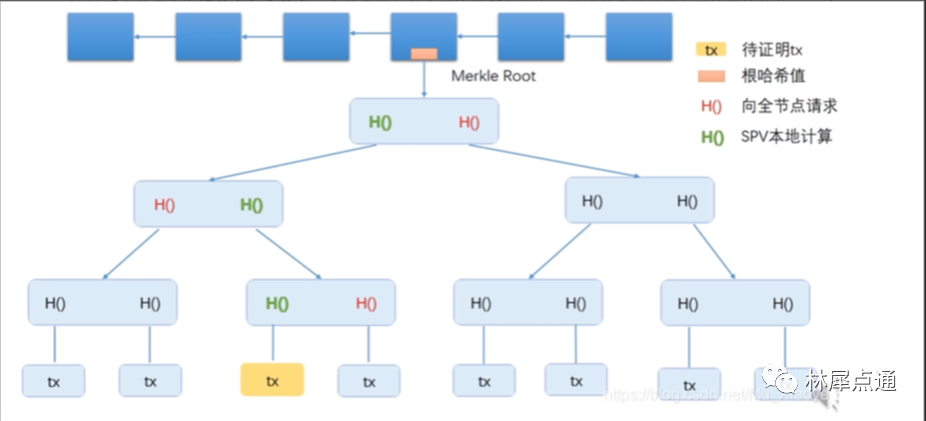
总之,哈希指针和 Merkle 树是比特币块链数据结构的两个重要组成部分,它们为比特币提供了安全可靠的数据管理方式,极大地提高了比特币的可靠性。
这篇关于BTC的数据结构Merkle Tree和Hash pointer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




