本文主要是介绍【详细教程】一文参透MongoDB聚合查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

MongoDB聚合查询
什么是聚合查询
聚合操作主要用于处理数据并返回计算结果。聚合操作将来自多个文档的值组合在一起,按条件分组后,再进行一系列操作(如求和、平均值、最大值、最小值)以返回单个结果。
MongoDB的聚合查询
聚合是MongoDB的高级查询语言,它允许我们通过转化合并由多个文档的数据来生成新的在单个文档里不存在的文档信息。MongoDB中聚合(aggregate)主要用于处理数据(例如分组统计平均值、求和、最大值等),并返回计算后的数据结果,有点类似sql语句中的 count(*)、group by。
在MongoDB中,有两种方式计算聚合:Pipeline 和 MapReduce。Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复杂的聚合逻辑。MongoDB不允许Pipeline的单个聚合操作占用过多的系统内存。
聚合管道方法
MongoDB 的聚合框架就是将文档输入处理管道,在管道内完成对文档的操作,最终将文档转换为聚合结果,MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作是可以重复的。
最基本的管道阶段提供过滤器,其操作类似查询和文档转换,可以修改输出文档的形式。其他管道操作提供了按特定字段对文档进行分组和排序的工具,以及用于聚合数组内容(包括文档数组)的工具。
此外,在管道阶段还可以使用运算符来执行诸如计算平均值或连接字符串之类的任务。聚合管道可以在分片集合上运行。
聚合流程
db.collection.aggregate()是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
聚合管道方法的流程参见下图
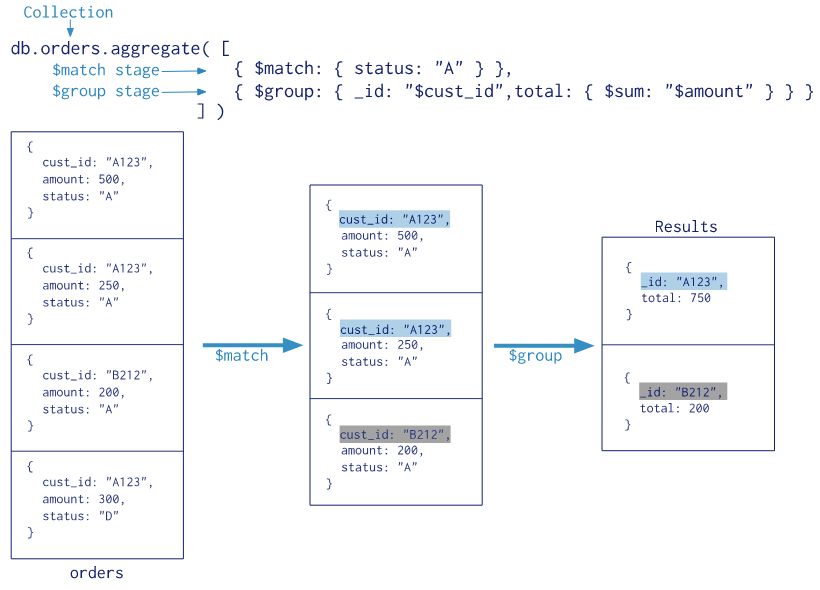
上图的聚合操作相当于 MySQL 中的以下语句:
select cust_id as _id, sum(amount) as total from orders where status like "%A%" group by cust_id;
详细流程
db.collection.aggregate()可以用多个构件创建一个管道,对于一连串的文档进行处理。这些构件包括:筛选操作的match、映射操作的project、分组操作的group、排序操作的sort、限制操作的limit、和跳过操作的skip。db.collection.aggregate()使用了MongoDB内置的原生操作,聚合效率非常高,支持类似于SQL Group By操作的功能,而不再需要用户编写自定义的JavaScript例程。- 每个阶段管道限制为100MB的内存。如果一个节点管道超过这个极限,MongoDB将产生一个错误。为了能够在处理大型数据集,可以设置
allowDiskUse为true来在聚合管道节点把数据写入临时文件。这样就可以解决100MB的内存的限制。 db.collection.aggregate()可以作用在分片集合,但结果不能输在分片集合,MapReduce可以 作用在分片集合,结果也可以输在分片集合。db.collection.aggregate()方法可以返回一个指针(cursor),数据放在内存中,直接操作。跟Mongo shell 一样指针操作。db.collection.aggregate()输出的结果只能保存在一个文档中,BSON Document大小限制为16M。可以通过返回指针解决,版本2.6中:DB.collect.aggregate()方法返回一个指针,可以返回任何结果集的大小。
聚合语法
db.collection.aggregate(pipeline, options)
参数说明
| 参数 | 类型 | 描述 |
|---|---|---|
| pipeline | array | 一系列数据聚合操作或阶段。详见聚合管道操作符 在版本2.6中更改:该方法仍然可以将流水线阶段作为单独的参数接受,而不是作为数组中的元素;但是,如果不将管道指定为数组,则不能指定options参数 |
| options | document | 可选。 aggregate()传递给聚合命令的其他选项。 2.6版中的新增功能:仅当将管道指定为数组时才可用。 |
注意事项
使用db.collection.aggregate()直接查询会提示错误,但是传一个空数组如db.collection.aggregate([])则不会报错,且会和find一样返回所有文档。
常用聚合管道
与mysql聚合类比
为了便于理解,先将常见的mongo的聚合操作和mysql的查询做下类比
| SQL 操作/函数 | mongodb聚合操作 |
|---|---|
| where | $match |
| group by | $group |
| having | $match |
| select | $project |
| order by | $sort |
| limit | $limit |
| sum() | $sum |
| count() | $sum |
| join | $lookup |
$count
返回包含输入到stage的文档的计数,理解为返回与表或视图的find()查询匹配的文档的计数。db.collection.count()方法不执行find()操作,而是计数并返回与查询匹配的结果数。
语法
{ $count: <string> }
c o u n t 阶段相当于下面 count阶段相当于下面 count阶段相当于下面group+$project的序列:
db.collection.aggregate([{"$group": {"_id": null,"count": {// 这里count自定义,相当于mysql的select count(*) as tables"$sum": 1}}},{"$project": {// 返回不显示_id字段"_id": 0}}
])
示例
查询人数是
100000以上的城市的数量
- $match:阶段排除pop小于等于100000的文档,将大于100000的文档传到下个阶段
- $count:阶段返回聚合管道中剩余文档的计数,并将该值分配给名为
count的字段。
db.zips.aggregate([{"$match": {"pop": {"$gt": 100000}}},{"$count": "count"}
])

$group
按指定的表达式对文档进行分组,并将每个不同分组的文档输出到下一个阶段。输出文档包含一个_id字段,该字段按键包含不同的组。
输出文档还可以包含计算字段,该字段保存由$group的_id字段分组的一些accumulator表达式的值。 $group不会输出具体的文档而只是统计信息。
语法
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
_id字段是必填的;但是,可以指定_id值为null来为整个输入文档计算累计值。- 剩余的计算字段是可选的,并使用
<accumulator>运算符进行计算。 _id和<accumulator>表达式可以接受任何有效的表达式。
accumulator操作符
| 名称 | 描述 | 类比sql |
|---|---|---|
| $avg | 计算均值 | avg |
| $first | 返回每组第一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序返回第一个文档。 | limit 0,1 |
| $last | 返回每组最后一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序返回最后一个文档。 | - |
| $max | 根据分组,获取集合中所有文档对应值的最大值。 | max |
| $min | 根据分组,获取集合中所有文档对应值的最小值。 | min |
| $push | 将指定的表达式的值添加到一个数组中。 | - |
| $addToSet | 将表达式的值添加到一个集合中(无重复值,无序)。 | - |
| $sum | 计算总和 | sum |
| $stdDevPop | 返回输入值的总体标准偏差(population standard deviation) | - |
| $stdDevSamp | 返回输入值的样本标准偏差(the sample standard deviation) | - |
g r o u p 阶段的内存限制为 100 M ,默认情况下,如果 s t a g e 超过此限制, group阶段的内存限制为100M,默认情况下,如果stage超过此限制, group阶段的内存限制为100M,默认情况下,如果stage超过此限制,group将产生错误,但是,要允许处理大型数据集,请将allowDiskUse选项设置为true以启用$group操作以写入临时文件。
注意:
- “$addToSet”:expr,如果当前数组中不包含expr,那就将它添加到数组中。
- “$push”:expr,不管expr是什么值,都将它添加到数组中,返回包含所有值的数组。
示例
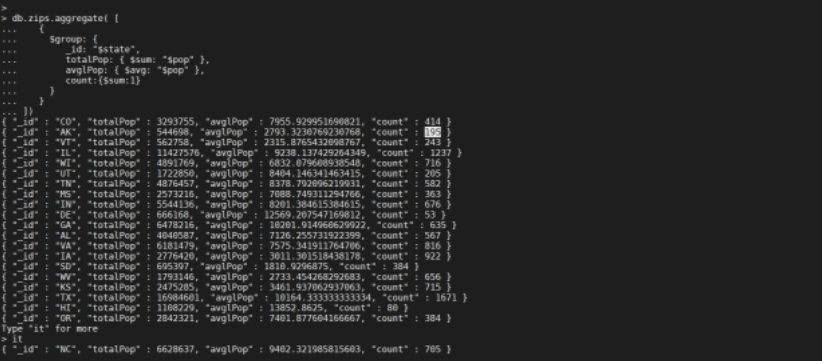
按照
state分组,并计算每一个state分组的总人数,平均人数以及每个分组的数量
db.zips.aggregate([{"$group": {"_id": "$state","totalPop": {"$sum": "$pop"},"avglPop": {"$avg": "$pop"},"count": {"$sum": 1}}}
])
查找不重复的所有的
state的值
db.zips.aggregate([{"$group": {"_id": "$state"}}
])

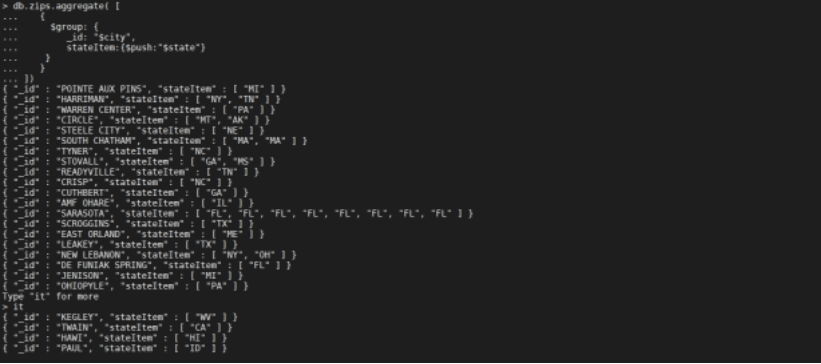
按照
city分组,并且分组内的state字段列表加入到stateItem并显示
db.zips.aggregate([{"$group": {"_id": "$city","stateItem": {"$push": "$state"}}}
])
下面聚合操作使用系统变量$$ROOT按item对文档进行分组,生成的文档不得超过BSON文档大小限制
db.zips.aggregate([{"$group": {"_id": "$city","item": {"$push": "$$ROOT"}}}
]).pretty();

$match
过滤文档,仅将符合指定条件的文档传递到下一个管道阶段。
$match接受一个指定查询条件的文档,查询语法与读操作查询语法相同。
语法
{ $match: { <query> } }
管道优化
m a t c h 用于对文档进行筛选,之后可以在得到的文档子集上做聚合, match用于对文档进行筛选,之后可以在得到的文档子集上做聚合, match用于对文档进行筛选,之后可以在得到的文档子集上做聚合,match可以使用除了地理空间之外的所有常规查询操作符,在实际应用中尽可能将$match放在管道的前面位置。这样有两个好处:
- 一是可以快速将不需要的文档过滤掉,以减少管道的工作量;
- 二是如果再投射和分组之前执行$match,查询可以使用索引。
使用限制
- 不能在
$match查询中使用$作为聚合管道的一部分。 - 要在
$match阶段使用$text,$match阶段必须是管道的第一阶段。 - 视图不支持文本搜索。
示例
使用 $match做简单的匹配查询,查询缩写是
NY的城市数据
db.zips.aggregate([{"$match": {"state": "NY"}}
]).pretty();

使用 m a t c h 管道选择要处理的文档,然后将结果输出到 match管道选择要处理的文档,然后将结果输出到 match管道选择要处理的文档,然后将结果输出到group管道以计算文档的计数
db.zips.aggregate([{"$match": {"state": "NY"}},{"$group": {"_id": null,"sum": {"$sum": "$pop"},"avg": {"$avg": "$pop"},"count": {"$sum": 1}}}
]).pretty();

$unwind
从输入文档解构数组字段以输出每个元素的文档,简单说就是 可以将数组拆分为单独的文档。
语法
要指定字段路径,在字段名称前加上$符并用引号括起来。
{ $unwind: <field path> }
v3.2+支持如下语法
{$unwind:{path: <field path>,#可选,一个新字段的名称用于存放元素的数组索引。该名称不能以$开头。includeArrayIndex: <string>, #可选,default :false,若为true,如果路径为空,缺少或为空数组,则$unwind输出文档preserveNullAndEmptyArrays: <boolean> } }
如果为输入文档中不存在的字段指定路径,或者该字段为空数组,则$unwind默认会忽略输入文档,并且不会输出该输入文档的文档。
版本3.2中的新功能:要输出数组字段丢失的文档,null或空数组,请使用选项preserveNullAndEmptyArrays。
示例
以下聚合使用$unwind为loc数组中的每个元素输出一个文档:
db.zips.aggregate([{"$match": {"_id": "01002"}},{"$unwind": "$loc"}
]).pretty();

$project
$project可以从文档中选择想要的字段,和不想要的字段(指定的字段可以是来自输入文档或新计算字段的现有字段),也可以通过管道表达式进行一些复杂的操作,例如数学操作,日期操作,字符串操作,逻辑操作。
语法
$project 管道符的作用是选择字段(指定字段,添加字段,不显示字段,_id:0,排除字段等),重命名字段,派生字段。
{ $project: { <specification(s)> } }
specifications有以下形式:
<field>: <1 or true> 是否包含该字段,field:1/0,表示选择/不选择 field
_id: <0 or false> 是否指定_id字段
<field>: <expression> 添加新字段或重置现有字段的值。 在版本3.6中更改:MongoDB 3.6添加变量REMOVE。如果表达式的计算结果为$$REMOVE,则该字段将排除在输出中。
<field>:<0 or false> v3.4新增功能,指定排除字段
- 默认情况下,_id字段包含在输出文档中。要在输出文档中包含输入文档中的任何其他字段,必须明确指定 p r o j e c t 中的包含。如果指定包含文档中不存在的字段, project中的包含。 如果指定包含文档中不存在的字段, project中的包含。如果指定包含文档中不存在的字段,project将忽略该字段包含,并且不会将该字段添加到文档中。
- 默认情况下,_id字段包含在输出文档中。要从输出文档中排除_id字段,必须明确指定$project中的_id字段为0。
- v3.4版新增功能-如果指定排除一个或多个字段,则所有其他字段将在输出文档中返回。 如果指定排除_id以外的字段,则不能使用任何其他$project规范表单:即,如果排除字段,则不能指定包含字段,重置现有字段的值或添加新字段。此限制不适用于使用REMOVE变量条件排除字段。
- v3.6版本中的新功能- 从MongoDB 3.6开始,可以在聚合表达式中使用变量REMOVE来有条件地禁止一个字段。
- 要添加新字段或重置现有字段的值,请指定字段名称并将其值设置为某个表达式。
- 要将字段值直接设置为数字或布尔文本,而不是将字段设置为解析为文字的表达式,请使用 l i t e r a l 操作符。否则, literal操作符。否则, literal操作符。否则,project会将数字或布尔文字视为包含或排除该字段的标志。
- 通过指定新字段并将其值设置为现有字段的字段路径,可以有效地重命名字段。
- 从MongoDB 3.2开始,$project阶段支持使用方括号[]直接创建新的数组字段。如果数组规范包含文档中不存在的字段,则该操作会将空值替换为该字段的值。
- 在版本3.4中更改-如果$project 是一个空文档,MongoDB 3.4和更高版本会产生一个错误。
- 投影或添加/重置嵌入文档中的字段时,可以使用点符号
示例
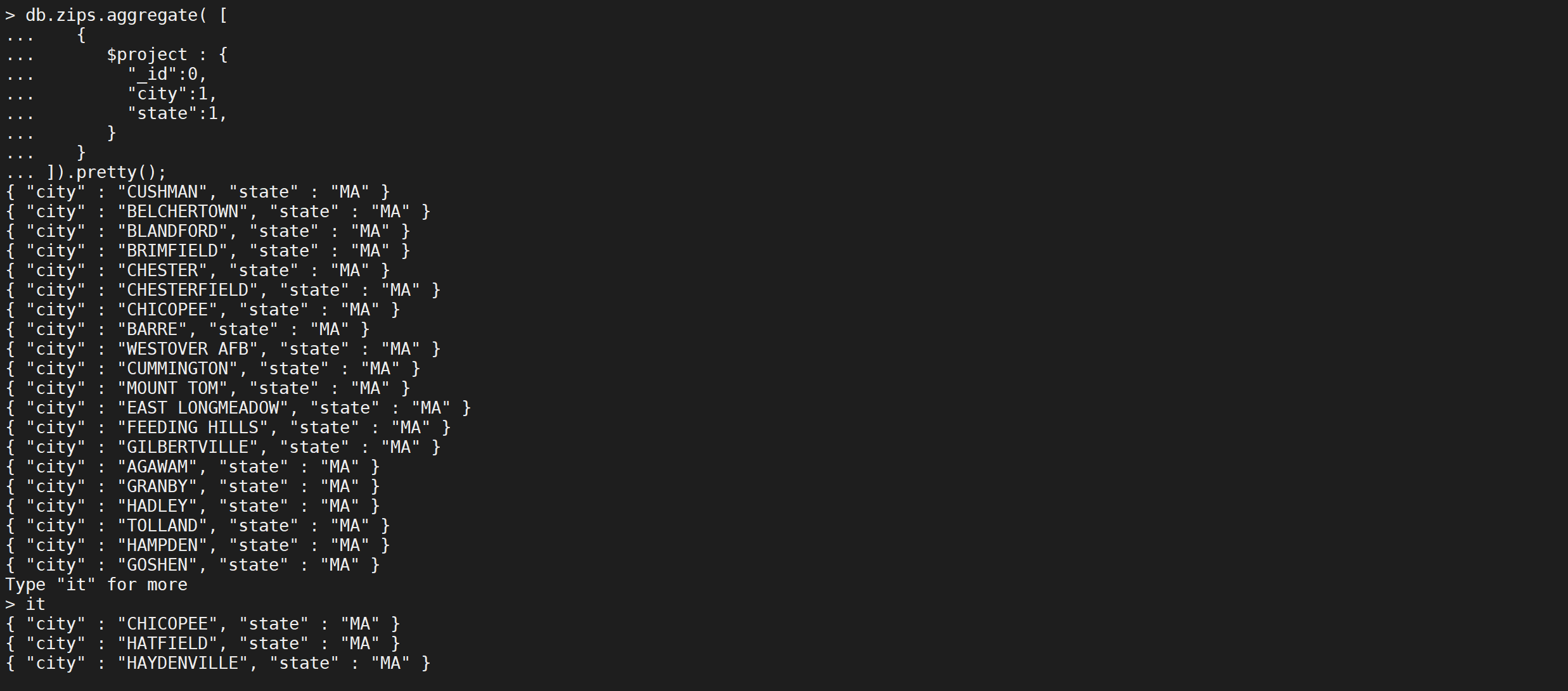
以下$project阶段的输出文档中只包含_id,city和state字段
db.zips.aggregate([{"$project": {"_id": 1,"city": 1,"state": 1}}
]).pretty();
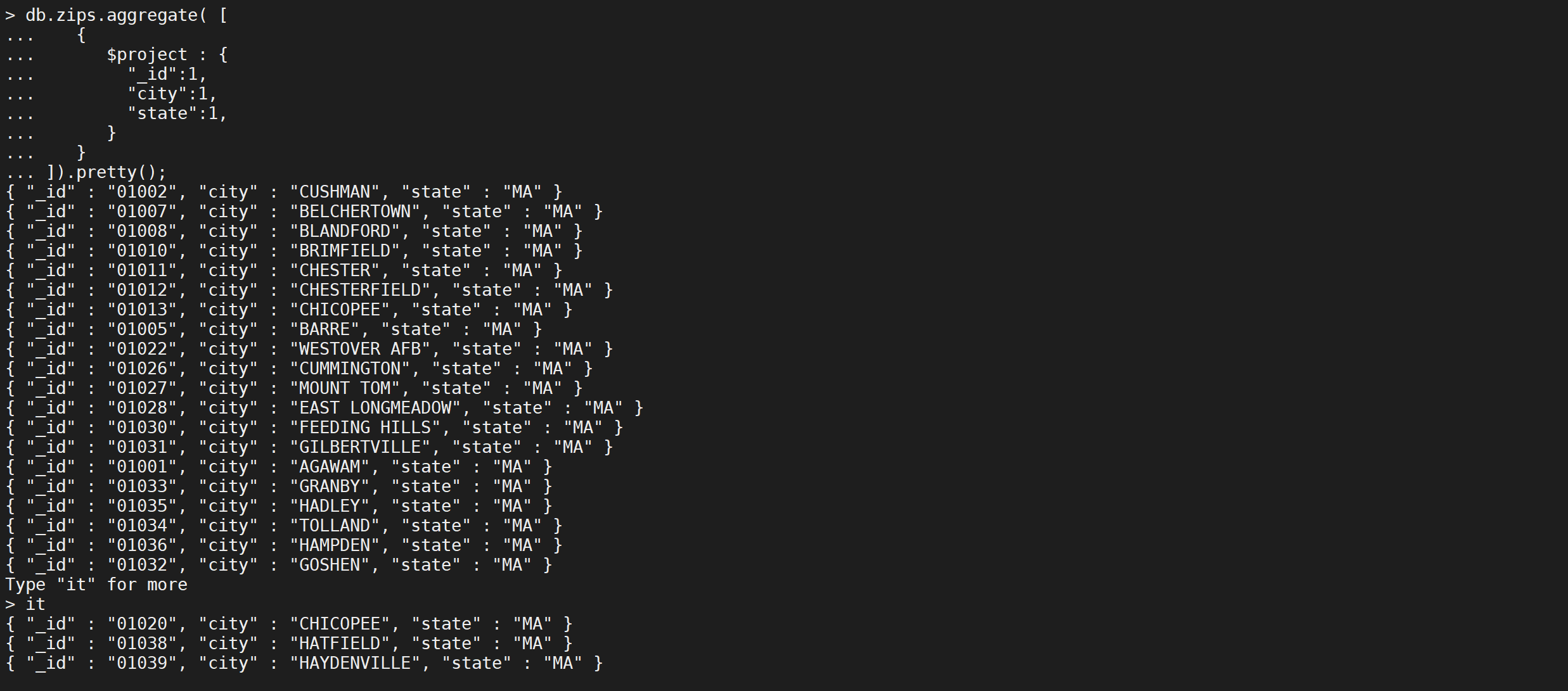
_id字段默认包含在内。要从$ project阶段的输出文档中排除_id字段,请在project文档中将_id字段设置为0来指定排除_id字段。
db.zips.aggregate([{"$project": {"_id": 0,"city": 1,"state": 1}}
]).pretty();
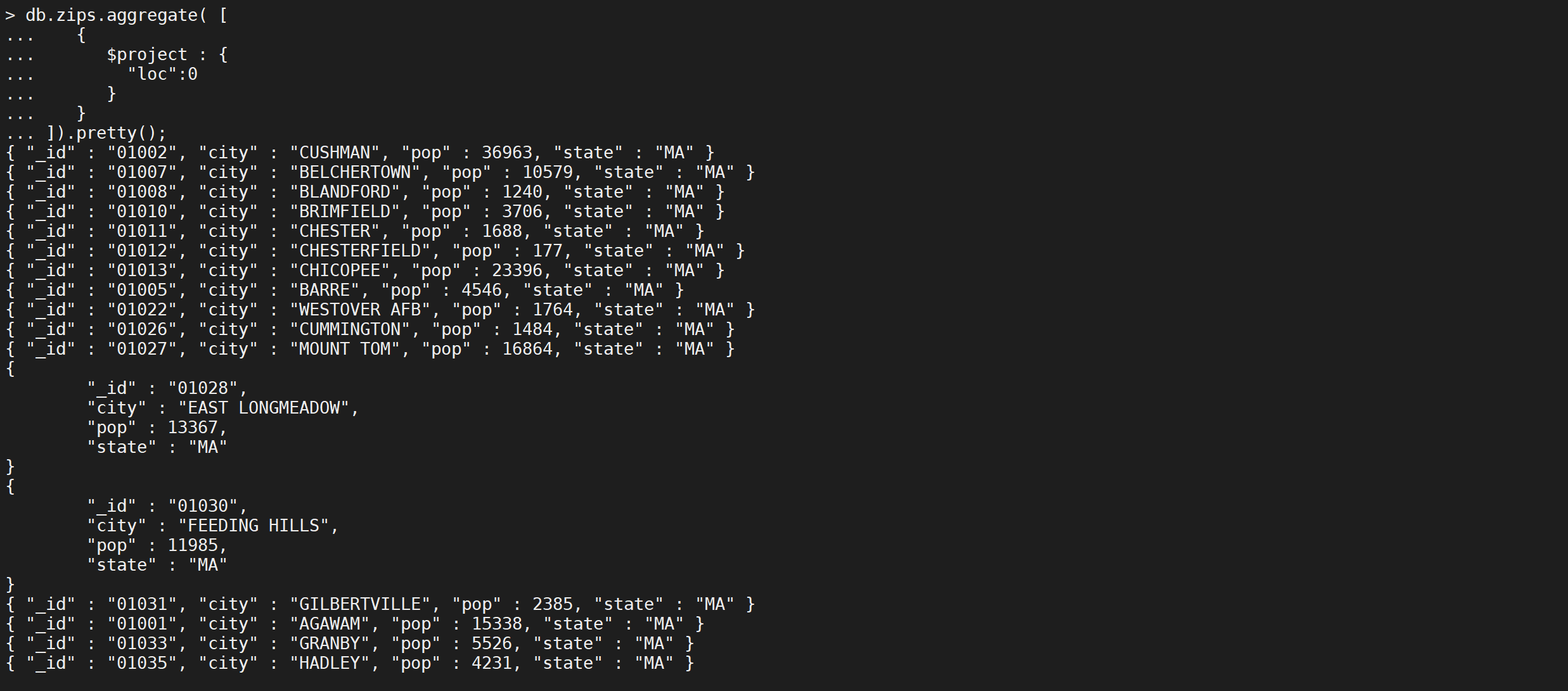
以下$ project阶段从输出中排除loc字段
db.zips.aggregate([{"$project": {"loc": 0}}
]).pretty();
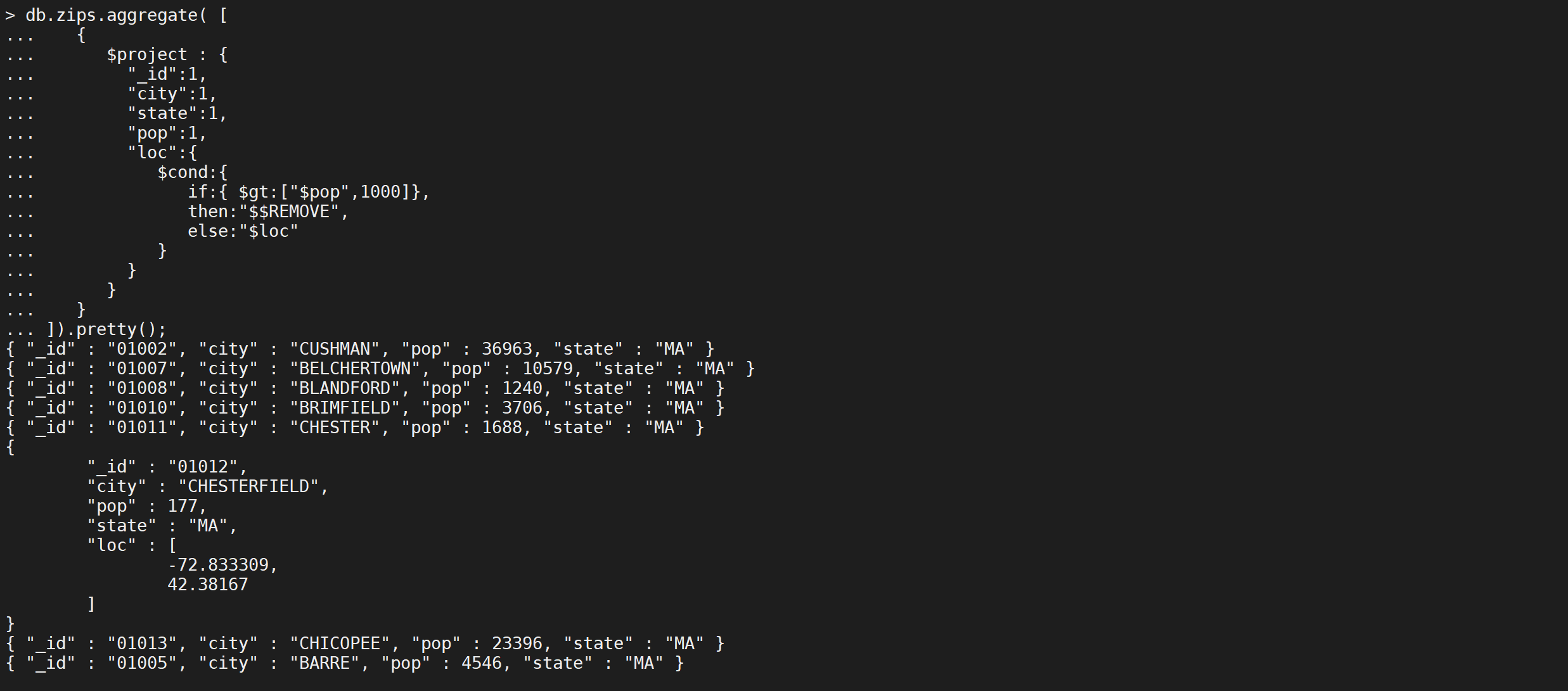
可以在聚合表达式中使用变量REMOVE来有条件地禁止一个字段,
db.zips.aggregate([{"$project": {"_id": 1,"city": 1,"state": 1,"pop": 1,"loc": {"$cond": {"if": {"$gt": ["$pop",1000]},"then": "$$REMOVE","else": "$loc"}}}}
]).pretty();
我们还可以改变数据,将人数大于1000的城市坐标重置为0
db.zips.aggregate([{"$project": {"_id": 1,"city": 1,"state": 1,"pop": 1,"loc": {"$cond": {"if": {"$gt": ["$pop",1000]},"then": [0,0],"else": "$loc"}}}}
]).pretty();

新增字段列
db.zips.aggregate([{"$project": {"_id": 1,"city": 1,"state": 1,"pop": 1,"desc": {"$cond": {"if": {"$gt": ["$pop",1000]},"then": "人数过多","else": "人数过少"}},"loc": {"$cond": {"if": {"$gt": ["$pop",1000]},"then": [0,0],"else": "$loc"}}}}
]).pretty();

$limit
限制传递到管道中下一阶段的文档数
语法
{ $limit: <positive integer> }
示例,此操作仅返回管道传递给它的前5个文档。 $limit对其传递的文档内容没有影响。
db.zips.aggregate({"$limit": 5
});
注意
当 s o r t 在管道中的 sort在管道中的 sort在管道中的limit之前立即出现时,$sort操作只会在过程中维持前n个结果,其中n是指定的限制,而MongoDB只需要将n个项存储在内存中。当allowDiskUse为true并且n个项目超过聚合内存限制时,此优化仍然适用。
$skip
跳过进入stage的指定数量的文档,并将其余文档传递到管道中的下一个阶段
语法
{ $skip: <positive integer> }
示例,此操作将跳过管道传递给它的前5个文档, $skip对沿着管道传递的文档的内容没有影响。
db.zips.aggregate({"$skip": 5
});
$sort
对所有输入文档进行排序,并按排序顺序将它们返回到管道。
语法
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
$sort指定要排序的字段和相应的排序顺序的文档。
<sort order>可以具有以下值之一:
- 1指定升序。
- -1指定降序。
- {$meta:“textScore”}按照降序排列计算出的textScore元数据。
示例
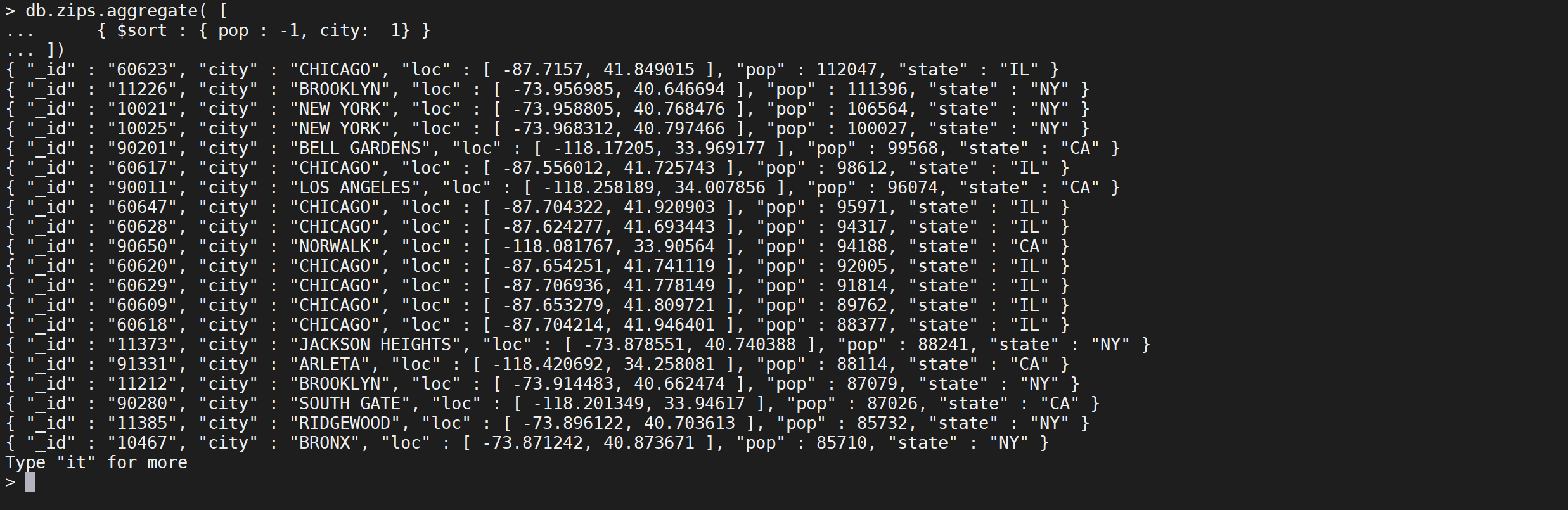
要对字段进行排序,请将排序顺序设置为1或-1,以分别指定升序或降序排序,如下例所示:
db.zips.aggregate([{"$sort": {"pop": -1,"city": 1}}
])
$sortByCount
根据指定表达式的值对传入文档分组,然后计算每个不同组中文档的数量。每个输出文档都包含两个字段:包含不同分组值的_id字段和包含属于该分组或类别的文档数的计数字段,文件按降序排列。
语法
{ $sortByCount: <expression> }
使用示例
下面举了一些常用的mongo聚合例子和mysql对比,假设有一条如下的数据库记录(表名:zips)作为例子:
统计所有数据
SQL的语法格式如下
select count(1) from zips;
mongoDB的语法格式
db.zips.aggregate([{"$group": {"_id": null,"count": {"$sum": 1}}}
])

对所有城市人数求合
SQL的语法格式如下
select sum(pop) AS tota from zips;
mongoDB的语法格式
db.zips.aggregate([{"$group": {"_id": null,"total": {"$sum": "$pop"}}}
])

对城市缩写相同的城市人数求合
SQL的语法格式如下
select state,sum(pop) AS tota from zips group by state;
mongoDB的语法格式
db.zips.aggregate([{"$group": {"_id": "$state","total": {"$sum": "$pop"}}}
])

state重复的城市个数
SQL的语法格式如下
select state,count(1) AS total from zips group by state;
mongoDB的语法格式
db.zips.aggregate([{"$group": {"_id": "$state","total": {"$sum": 1}}}
])

state重复个数大于100的城市
SQL的语法格式如下
select state,count(1) AS total from zips group by state having count(1)>100;
mongoDB的语法格式
db.zips.aggregate([{"$group": {"_id": "$state","total": {"$sum": 1}}},{"$match": {"total": {"$gt": 100}}}
])

专注Java技术干货分享,欢迎志同道合的小伙伴,一起交流学习
这篇关于【详细教程】一文参透MongoDB聚合查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








