本文主要是介绍Mysql-InnoDB-数据落盘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概念
1 什么是脏页?
对于数据库中页的修改操作,则首先修改在缓冲区中的页,缓冲区中的页与磁盘中的页数据不一致,所以称缓冲区中的页为脏页。
2 脏页什么时候写入磁盘?
脏页以一定的频率将脏页刷新到磁盘上。页从缓冲区刷新回磁盘的操作并不是在每次页发生更新时触发,而是通过一种称为CheckPoint的机制刷新回磁盘。
3 什么是CheckPoint?
Checkpoint要做的事情是将缓冲池中的脏页数据刷到磁盘上。CheckPoint决定了脏页落盘的时机、条件及脏页的选择,不同的CheckPoint做法并不相同。
保证数据的安全性
落盘的流程图:
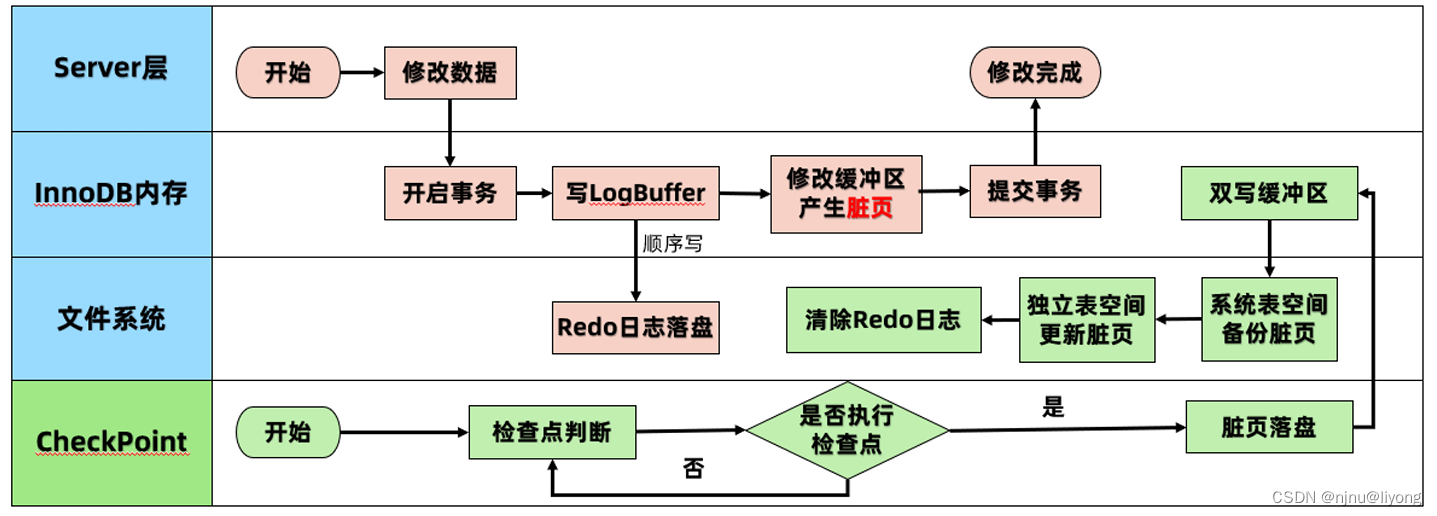
脏页产生了肯定是有一个时间要进行落盘,那么怎么保证修改内存到落盘整个过程中不发生任何的问题呢?
InnoDB采用了Write Ahead Log(WAL)策略和Force Log at Commit机制实现事务级别下数据的持久性。
Force Log at Commit机制:当事务提交时,所有事务产生的日志都必须刷到磁盘。如果日志刷新成功后,缓冲池中的数据刷新到磁盘前数据库发生了宕机,那么重启时,数据库可以从日志中恢复数据,这样可以保证数据的安全性.
Write Ahead Log(WAL)策略:要求数据的变更写入到磁盘前,首先必须将内存中的日志写入到磁盘;InnoDB 的 WAL(Write Ahead Log)技术的产物就是 redo log,对于写操作,永远都是日志先行,先写入 redo log 确保一致性之后,再对修改数据进行落盘。
从上面两个机制来看,Redo log 起着关键作用,我们需要保证Redo Log 能够安全落盘
为了确保每次日志都写入到redo日志文件,在每次将redo日志缓冲写入redo日志后,调用一次fsync操作(从系统的缓存真正刷新到磁盘),将缓冲文件从文件系统缓存中真正写入磁盘。
之所以可以这样做是因为,日志只记录更新操作的也和行信息,大小相对较小。同时日志的写入是顺序的,就是继续往后写。再有日志的刷盘和事务是有关联的,事务提交后刷盘策略可以通过innodb_flush_log_at_trx_commit 来控制,日志记录的是事务中执行的一系列操作,不是单条就会触发更新。
innodb_flush_log_at_trx_commit 这个参数相信也不陌生了:
-
0时:事务提交时,不会立即把 log buffer里的数据写入到redo log日志文件的。而是等待主线程每秒写入一次。
特点:
如果MySQL崩溃或者服务器宕机,此时内存里的数据会全部丢失,最多会丢失1秒的事务。
写入效率最高,但是数据安全最低; -
1时:每次事务提交时,会将数据将从log buffer写入redo日志文件与文件系统缓存,并同时
fsync刷新到磁盘中。
特点:
系统默认配置为1,MySQL崩溃已经提交的事务不会丢失,要完全符合ACID必须使用默认设置1。
写入效率最低,但是数据安全最高; -
2时:事务提交时,也会将数据写入redo日志文件与文件系统缓存,但是不会调用fsync,而是让
操作系统自己去判断何时将缓存写入磁盘。
特点:
事务提交都会将数据刷新到操作系统缓冲区,可以认为是已经持久化到磁盘,但没有真正意义
上持久化到磁盘。
如果MySQL崩溃已经提交的事务不会丢失。但是如果服务器宕机或者意外断电,操作系统缓存内的数据会丢失,所以最多丢失1秒的事务。
有了上面的准备工作,真正决定数据什么时候落盘的时机是检查点机制,下面我们来看看检查点是怎样工作的,解决了什么问题?
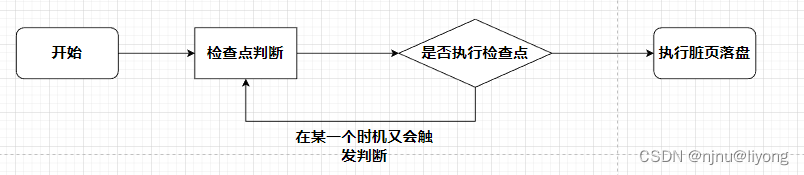
1 从这个流程来看,首先它可以避免Redo log日志的堆积。因为我们当前检查点执行以后,数据已经落盘了,那么之前的Redo log就没有作用了可以清理掉不可能再使用到的日志。同时如果数据库发了宕机,这个时候也只需要执行上一个检查点到现在的Redo Log就可以恢复数据。
2 可以解决缓冲池不够用问题,缓冲池不够用时,将脏页刷新到磁盘当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
3 redo日志不可用时,刷新脏页当redo日志出现不可用时,Checkpoint将缓冲池中的页至少刷新到当前redo日志的位置。这样就算RedoLog不可用也可以保证不丢失更新。
那么具体的检查点又有所不同
1 可以分为两类
sharp checkpoint:在关闭数据库的时候,将buffer pool中的脏页全部刷新到磁盘中。
fuzzy checkpoint:数据库正常运行时,在不同的时机,将部分脏页写入磁盘。仅刷新部分脏页到磁盘,也是为了避免一次刷新全部的脏页造成的性能问题。
Fuzzy Checkpoint:默认方式,只刷新一部分脏页,不是刷新所有脏页;
主要有以下几种情况:
- Master Thread Checkpoint :在Master Thread中,会以每秒或者每10秒一次的频率,将部分
脏页从内存中刷新到磁盘,这个过程是异步的。正常的用户线程对数据的操作不会被阻塞。 - FLUSH_LRU_LIST Checkpoint:缓冲池不够用时,根据LRU算法会淘汰掉最近最少使用的页,如
果该页是脏页的话,会强制执行CheckPoint,将该脏页刷回磁盘(由Page Cleaner Thread完
成); - Async/Sync Flush Checkpoint:重做日志不可用的情况,需要强制从脏页列表中选取一些脏页
刷盘(由Page Cleaner Thread完成)。由于磁盘是一种相对较慢的存储设备,内存与磁盘的交互
是一个相对较慢的过程。innodb_log_file_size定义的是一个相对较大的值,正常情况下,由前面两
种checkpoint刷新脏页到磁盘,在前面两种checkpoint刷新脏页到磁盘之后,脏页对应的redo log
空间随即释放,一般不会发生Async/Sync Flush checkpoint。 - Dirty Page too much:即脏页数量太多,导致强制进行Checkpoint。由参数
innodb_max_dirty_pages_pt 来控制,默认75(即75%)。当脏页数量占据75%缓冲池时,刷新一部分脏页到磁盘。(由Page Cleaner Thread完成)
在检查点落盘的过程中也可能会发生异常,这个时候就需要Double Write双写来保证不写失效
所谓的写失效就就比如我们一页的数据为16K,但是我们这个页只写了一半数据库就发生了异常,这个时候页就被损坏了。
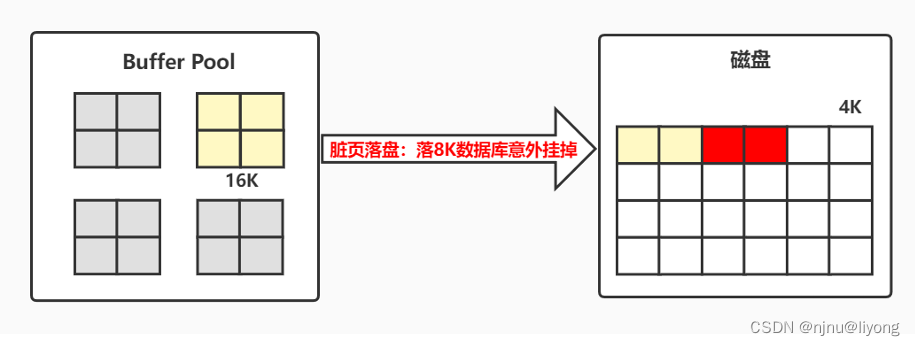
这个时候我们不能通过Redo log来恢复,重做日志中记录的是对页的物理操作,而不是页面的全量记录,而如果发生partial page write(部分页写入)问题时,出现问题的是未修改过的数据,此时重做日志(Redo Log)无能为力。因此引入了双写机制:
Double Write分两个部分:
内存中的Doublewrite buffer,大小为2MB
磁盘上的Doublewrite buffer,大小为2MB,连续的128个页,相当于两个extent
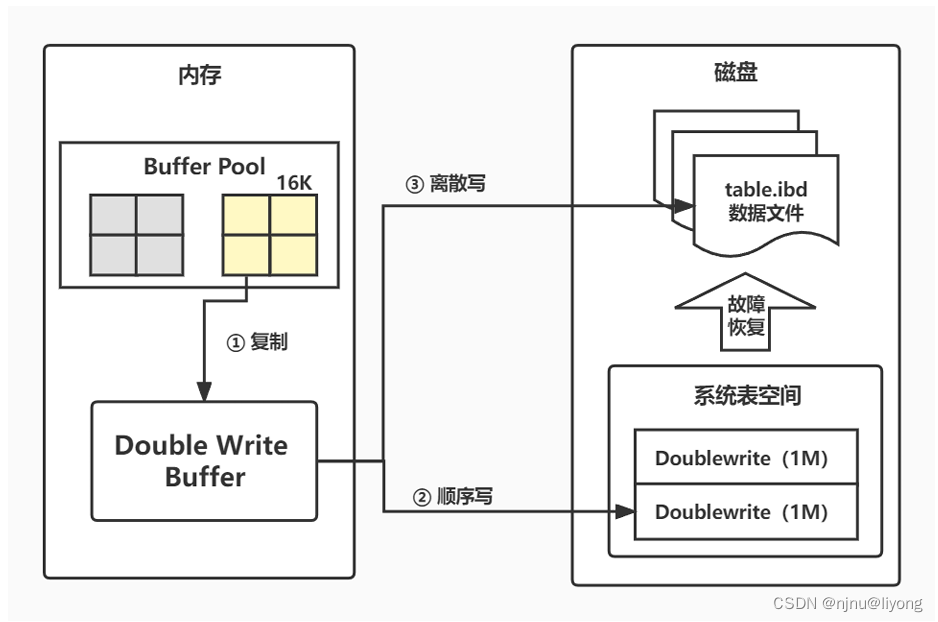
Double write脏页刷新流程:
1 首先复制:脏页刷新时不直接写磁盘,而是先将脏页复制到内存的Doublewrite buffer。
2 再顺序写:内存的Doublewrite buffer分两次,每次1MB顺序地写入共享表空间的物理磁盘上,会立即调用fsync函数同步OS缓存到磁盘中,顺序写性能好。
3 最后离散写:内存的Doublewrite buffer最后将页写入各自表空间文件中,离散写较顺序写入差一些。
如果操作系统在将页写入磁盘的过程中发生了崩溃,其恢复过程如下:
1 首先InnoDB存储引擎从系统表空间中的Double write中找到该页的一个副本
2 然后将其复制到独立表空间
3 再应用重做日志。
相关配置
innodb_doublewrite:Doublewrite Buffer是否启用开关,默认是开启状态,InnoDB将所有数据存储两次,首先到双写缓冲区,然后到实际数据文件。
Innodb_dblwr_pages_written:记录写入到DWB中的页数量。
Innodb_dblwr_writes:记录DWB写操作的次数。
参考资料:极客时间课件资料
这篇关于Mysql-InnoDB-数据落盘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







