本文主要是介绍深度学习-使用Labelimg数据标注,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据标注是计算机视觉和机器学习项目中至关重要的一步,而使用工具进行标注是提高效率的关键。本文介绍了LabelImg,一款常用的开源图像标注工具。用户可以在图像中方便而准确地标注目标区域,为训练机器学习模型提供高质量的标注数据。LabelImg已经成为研究者和开发者在计算机视觉项目中不可或缺的工具之一。
一、安装Labelimg
1、切换虚拟环境
为了确保 LabelImg 能够与项目环境兼容,首先需要切换到相应的虚拟环境。
例如,可以使用 conda 激活 yolov5 虚拟环境:
conda activate yolov5 #切换到yolov5虚拟环境2、安装Labelimg
在虚拟环境中,通过 pip 安装 LabelImg:
pip install labelimg
二、打开Labelimg
在安装完成后,可以通过以下命令在命令行中打开 LabelImg:
labelimg #在命令行中输入labelimg即可打开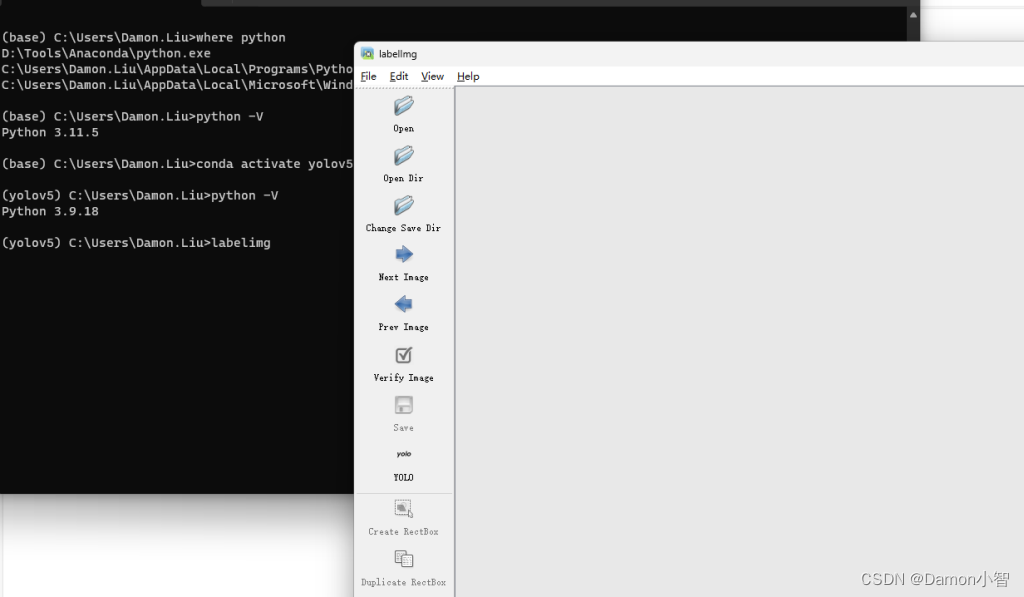
三、进行图片标注
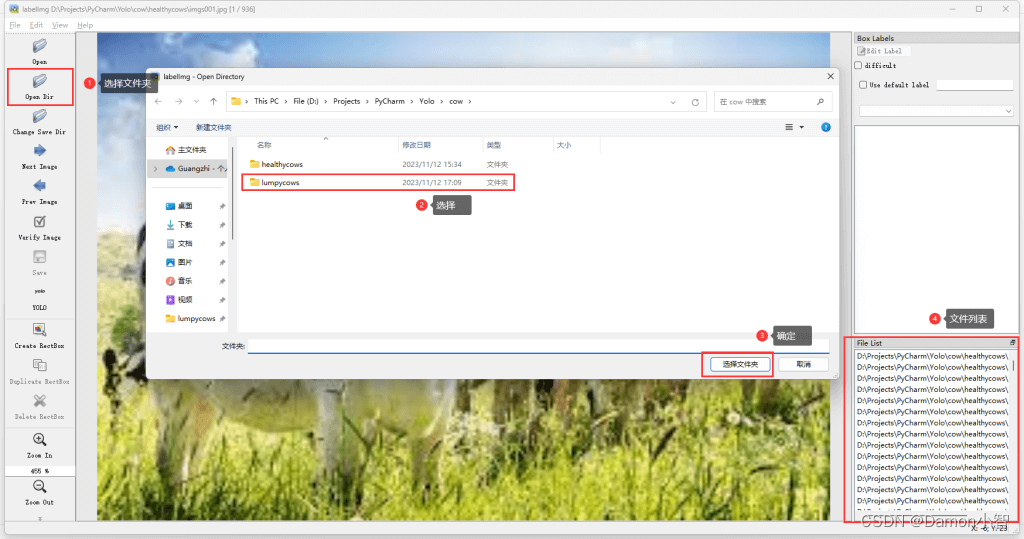
1、导入图片
通过 LabelImg 的 Open Dir 按键打开需要进行标注的图片所在的文件夹,文件夹内的图片会被自动导入,在右下角的框体里我们可以看到这些图片,从而选择它们进行标注。
2、切换为yolo模式
在 LabelImg 中,可以选择不同的标注模式。
切换到 yolo 模式有助于生成符合 yolo 模型训练需求的标注文件。

3、拖拽画框进行标注
使用鼠标在图像上拖拽画框,准确框选目标区域。
LabelImg 提供直观的界面和交互方式,使标注过程更加便捷。
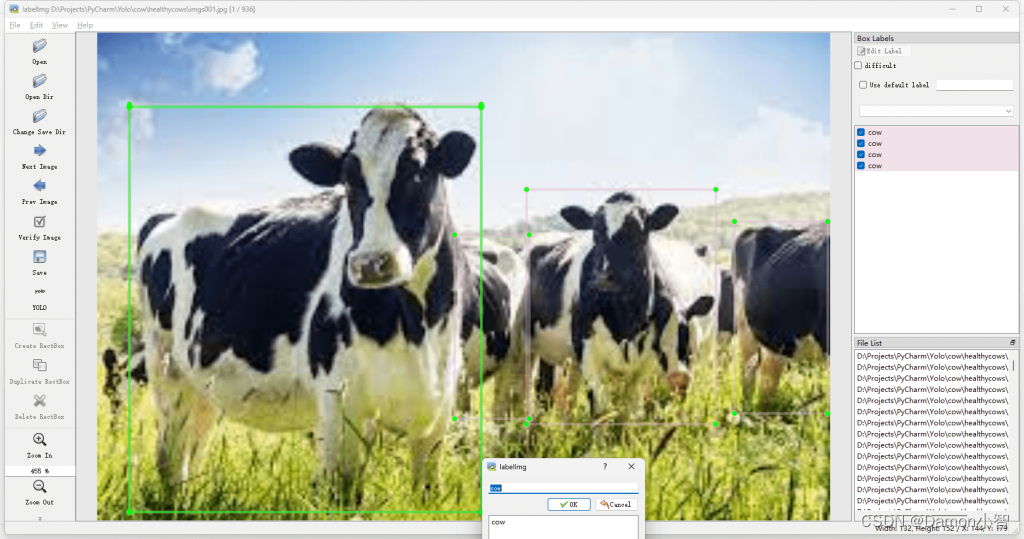
为了训练的结果更加精准,我们需要更准确地标注。
在使用 LabelImg 进行拖拽画框进行标注时,需要注意一些事项:
| 注意点 | 注意点描述 |
| 精准拖拽 | 尽量保持拖拽画框的精准,确保框选的区域紧密贴合目标,以提高标注的准确性。 |
| 适当留白 | 在框选目标时,适当留白目标周围,不要贴得太紧,以免过于靠近目标边缘导致模型难以学习。 |
| 避免遮挡 | 注意避免目标被遮挡或部分遗漏。 标注的目的是为了让模型准确识别目标,因此要确保标注框完整地覆盖目标物体。 |
| 多边形标注 | 对于不规则形状的目标,LabelImg支持多边形标注。 在需要的情况下,可以使用多边形标注工具进行更灵活的标注。 |
| 避免重叠 | 避免在同一区域标注多个框,除非目标本身是多个紧密相连的部分。 重叠的标注可能导致模型难以解释目标的准确位置。 |
| 合理分割 | 如果一个目标被遮挡或部分消失,可以尝试合理地将其分割为多个框。 合理的分割图片可以更好地捕捉目标的形状。 |
| 调整大小 | 标注框的大小应该适当,不要过大也不要过小。确保框选的区域足够表达目标的特征。 |
| 标签一致性 | 在整个数据集中,确保相同类别的目标都使用相同的标签,保持标签的一致性。 |
4、保存数据集txt文件
在完成图像标注后,保存数据集是至关重要的一步,这一步骤将产生一个包含框体和标签信息的数据集文件,为机器学习模型的训练提供了必要的输入。
点击 LabelImg 界面上方的 Save 按钮,或者使用快捷键 Ctrl + S,将触发保存数据集的操作。这个操作会在标注的图片文件夹目录下生成与图片文件同名的 txt 文件,该文件包含了每个框体的位置和对应标签的信息。
保存的txt文件的格式通常是每一行代表一个目标框,具体格式可能如下:
class x_center y_center width height
其中:
class表示目标的类别。x_center和y_center是目标框中心的相对坐标。width和height是目标框的相对宽度和高度。
这样的格式便于模型训练时读取和理解数据。在训练阶段,这些标注信息将被用来调整模型参数,使其能够准确地检测和识别相应类别的目标。
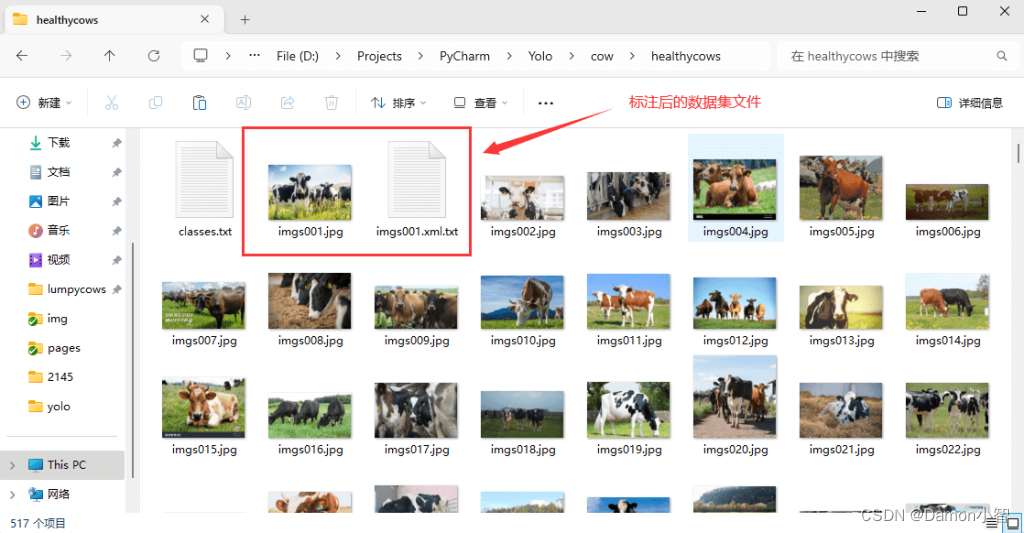
这些数据集文件包含框体和标签的信息,将在训练模型时被自动加载。使用 LabelImg,数据标注变得简单而高效,为计算机视觉项目提供了强大的支持。
这篇关于深度学习-使用Labelimg数据标注的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





