本文主要是介绍【腾讯云 HAI域探秘】释放生产力:基于 HAI 打造团队专属的 AI 编程助手,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、HAI 产品介绍
- 二、HAI 应用场景介绍
- 三、HAI 生产力场景探索:基于 HAI 打造团队专属的 AI 编程助手
- 3.1 申请 HAI 内测资格
- 3.2 购买 HAI 实例
- 3.3 下载 CodeShell-7B-Chat 模型
- 3.4 部署 text-generation-inference(TGI)推理服务
- 3.4.1 下载 text-generation-inference 项目
- 3.4.2 安装 Rust 环境
- 3.4.3 安装 Protoc
- 3.4.4 编译安装 TGI
- 3.4.5 启动 TGI 服务
- 3.5 配置 HAI 安全组规则
- 3.6 配置 IDE 插件
- 3.7 效果展示
- 四、HAI 中 TGI 服务基准测试
- 4.1 安装 text-generation-benchmark
- 4.2 运行 text-generation-benchmark
- 4.3 查看基准测试报告
- 五、生产场景优化建议
- 5.1 基于自有代码集微调
- 5.2 TGI 服务访问安全优化
- 5.3 HAI 成本优化
- 5.4 HAI 开机自动启动 TGI 服务
- 六、总结&建议
前言
腾讯云高性能应用服务 HAI(Hyper Application Inventor) 是一款面向 AI 和科学计算的 GPU/NPU 应用服务产品,提供即插即用的强大算力和常见环境。它可以帮助中小企业和开发者快速部署 AI 大语言模型(LLM)、AI 绘图、数据科学等高性能应用,原生集成配套的开发工具和组件,大大提升应用层的开发生产效率。HAI 作为一款云服务产品,如何提升用户生产力是考虑其使用场景的第一要素。本文就将以此为目标,基于HAI为开发团队打造一款团队内部专属的AI编程助手,提升团队整体研发效率,探索 HAI 在生产力场景下的更多可能性。
基于 HAI 提供的可视化界面以及即插即用的强大算力和常见环境,非AI方向的普通开发者 也可以轻松阅读本文,并着手 打造自己的AI编程助手。
一、HAI 产品介绍
腾讯云高性能应用服务 HAI(Hyper Application Inventor) 是一款面向 AI 和科学计算的 GPU/NPU 应用服务产品,为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的 GPU 云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的 GPU 算力资源,以确保在数据科学、LLM、AI 作画等高性能应用中获得最佳性价比。此外,HAl 的一键部署特性可以在短短几分钟内构建如 StableDifusion、ChatGLM2 等热门模型的应用环境。而对于 AI 研究者,直观的图形界面大大降低了调试的复杂度,支持 jupyterlab、webui 等多种连接方式,助您轻松探索与创新。
高性能应用服务 HAI 的核心服务优势在于三点:智能选型、一键部署、可视化界面。

高性能应用服务 HAI 相比传统 GPU 云服务器的主要区别和优势可以参考下图:

二、HAI 应用场景介绍
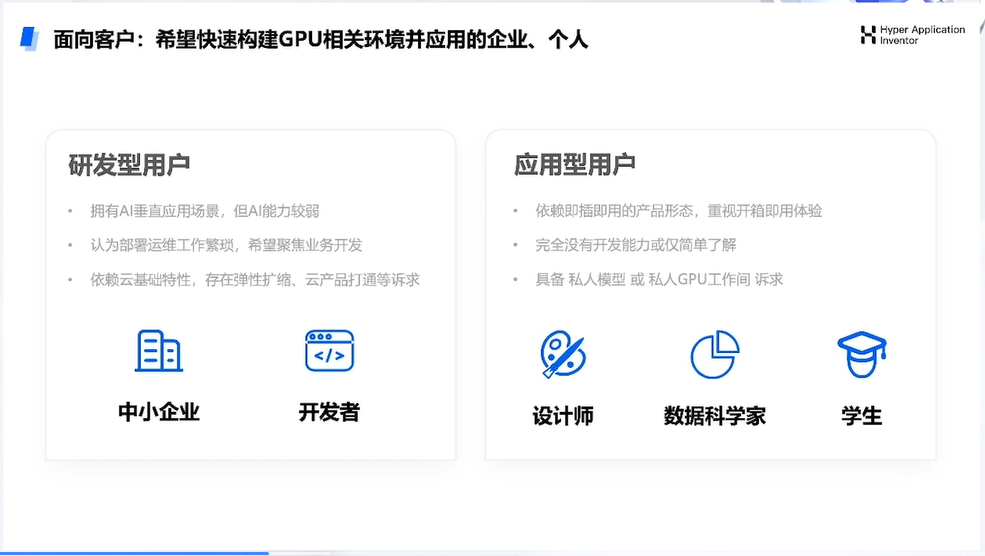
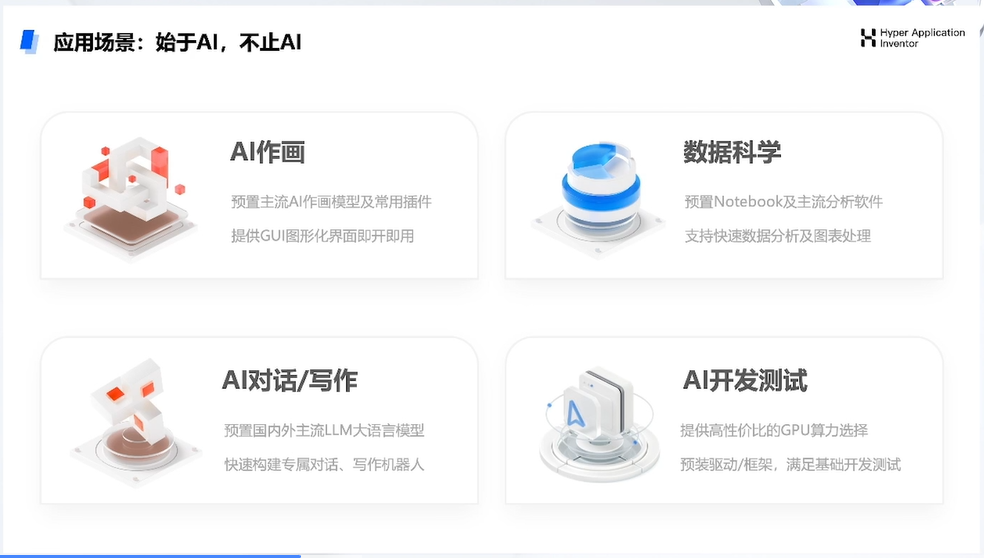
三、HAI 生产力场景探索:基于 HAI 打造团队专属的 AI 编程助手
CodeShell 是北京大学知识计算实验室联合四川天府银行 AI 团队研发的 多语言代码大模型基座。CodeShell 具有 70 亿参数,在五千亿 Tokens 进行了训练,上下文窗口长度为 8192。在权威的代码评估 Benchmark(HumanEval 与 MBPP)上,CodeShell 取得同等规模最好的性能。与此同时,CodeShell 提供了与大模型配套的部署方案与 IDE 插件。部署方案涵盖了基于团队 GPU 部署、个人 GPU 部署、个人 CPU 部署三个场景,IDE 插件支持 Python、Java、C++/C、JavaScript、Go 等多种编程语言,为开发者提供代码补全、代码解释、代码优化、注释生成、对话问答等功能。
本文将采用 CodeShell 提供的团队 GPU 部署方案,在 HAI 上进行部署实践。团队 GPU 部署方案基于 text-generation-inference(TGI) 实现服务器高效推理,使用 CodeShell-7B-Chat 模型文件来获得更好的软件工程领域的 AI 智能辅助体验。
按照 CodeShell 团队的公开演讲内容,团队 GPU 部署方案在 4090 上响应速率可达每秒 90Token。每块 4090 可支持上百人的团队日常使用。4090 显卡的显存规格是 24GB,而 HAI 进阶型算力方案 提供了 32GB+的显存。这意味着每小时 2.41 元的成本,即可让上百人的研发团队都使用上 AI 编程助手从而提高研发效率,性价比极高。
接下来,就让我们正式开始部署过程,整个部署过程拆解如下:
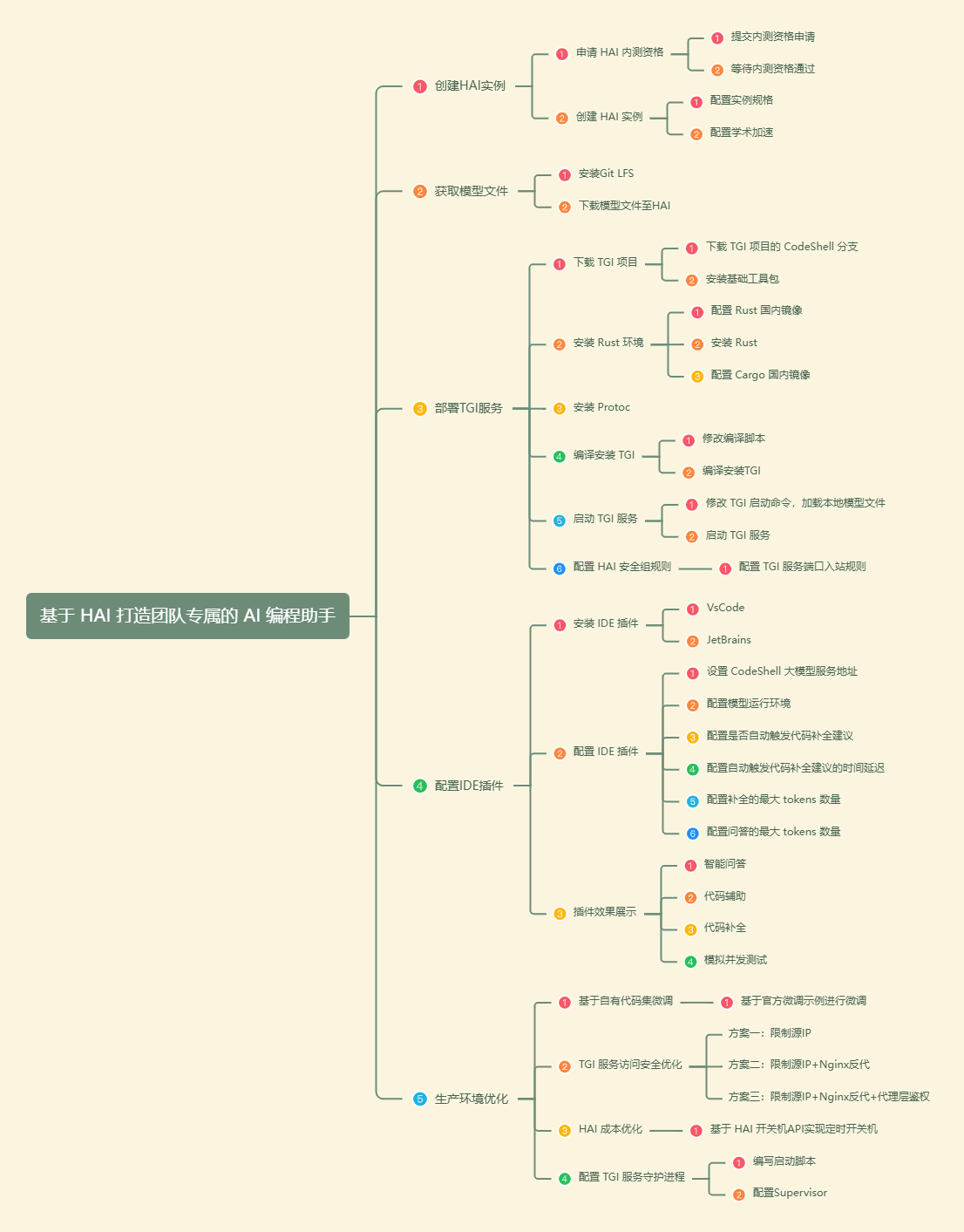
3.1 申请 HAI 内测资格
-
HAI 在本文发布之时还处于内测阶段,因此需先申请体验资格,可以点击链接进入 高性能应用服务 HAI 申请体验资格:
-
体验资格审核提交后,审核时间大概 1 天左右,审核通过后会有短信通知。审核通过后,点击链接登录进入 高性能应用服务 HAI 控制台 :
3.2 购买 HAI 实例
-
点击控制台的新建按钮,进入实例规格购买页面,相较于 GPU 服务器购买页眼花缭乱的配置项,HAI 可以根据用户所选的应用类型,自动匹配合适的算力,资源组合套餐。用户只需要根据自身所需关注核心的
应用类型、算力方案即可。本文所需的实例配置如下:序号 配置项 配置规格 说明 1 应用类型 AI 框架:Pytorch2.0.0 环境配置:Ubuntu20.04, Python 3.8, Pytorch 2.0.0, CUDA 11.7, cuDNN 8, JupyterLab 2 地域 广州 广州地区支持学术加速及关机不计费功能 3 算力方案 进阶型 本文使用非量化版本的 7B 模型+TGI 推理,因此选择进阶型算力方案;如果个人使用,可以选择基础型算力方案搭配 4Bit 量化模型+llama_cpp_for_codeshell 推理 4 硬盘 90G 默认的 80G 空间在后续部署完成后会出现空间不足的情况,适当增加磁盘大小 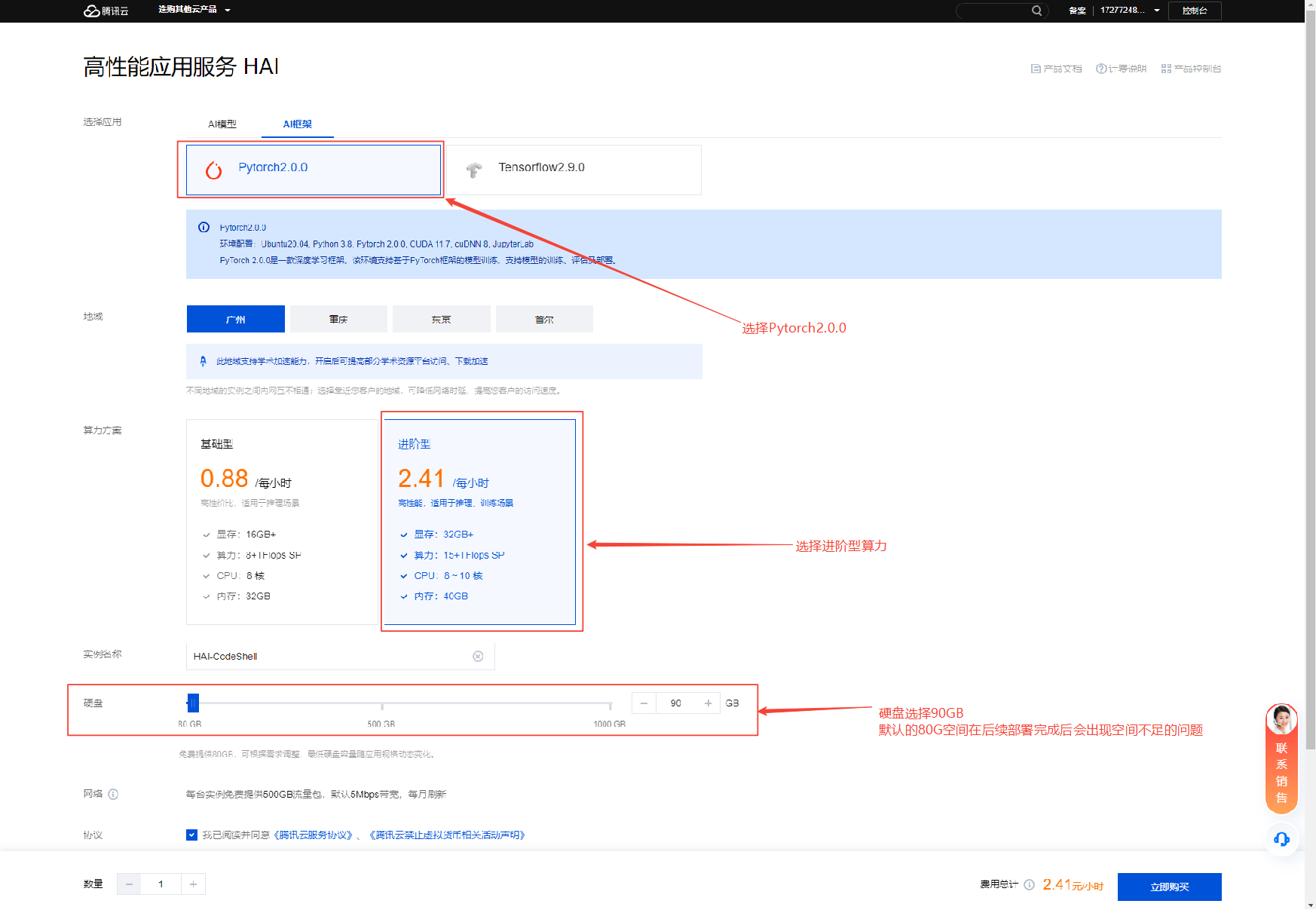
-
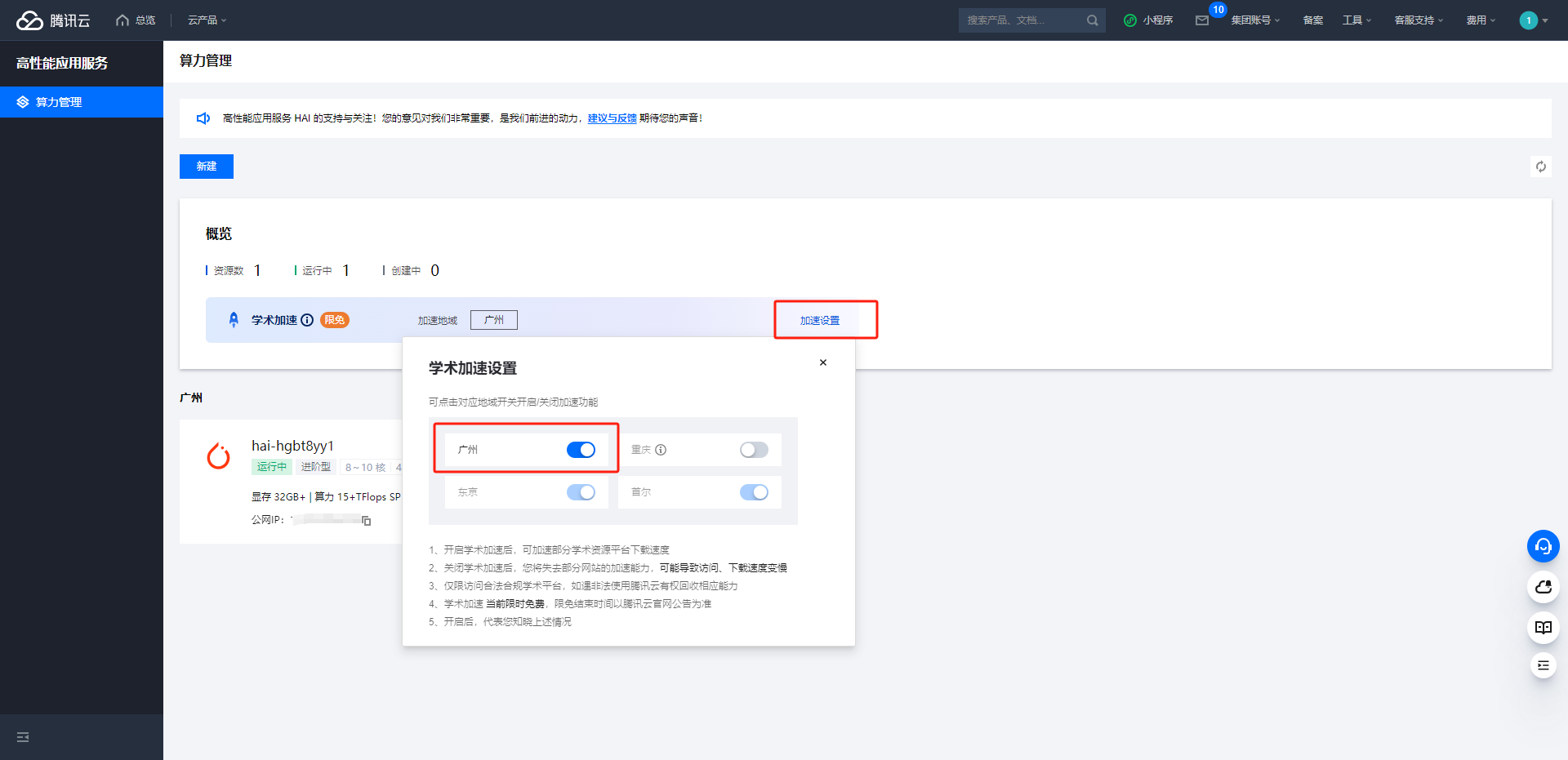
实例购买成功后,需要 10 分钟左右的时间创建实例,趁着这个无聊的等待时间,可以将学术加速设置打开,提高后续过程中访问 Github 等国外的网站的访问速度。
-
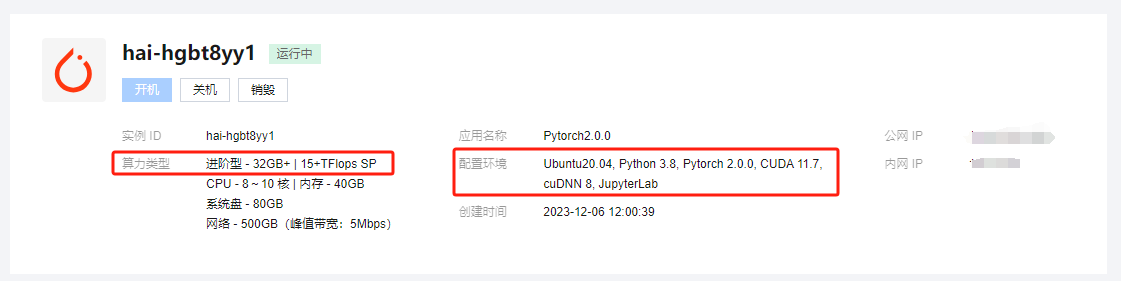
实例创建成功后,传统 GPU 服务器此时需要安装各种驱动、CUDA、conda 等基础环境,过程中一坑连一坑,坑坑不一样。而 HAI 已经将这些常用基础环境打包预置,因此,接下来可以直接开始部署我们的 AI 编程助手了。
3.3 下载 CodeShell-7B-Chat 模型
-
进入 HAI 预置的 JupyterLab 环境,选择 Terminal 标签进入终端

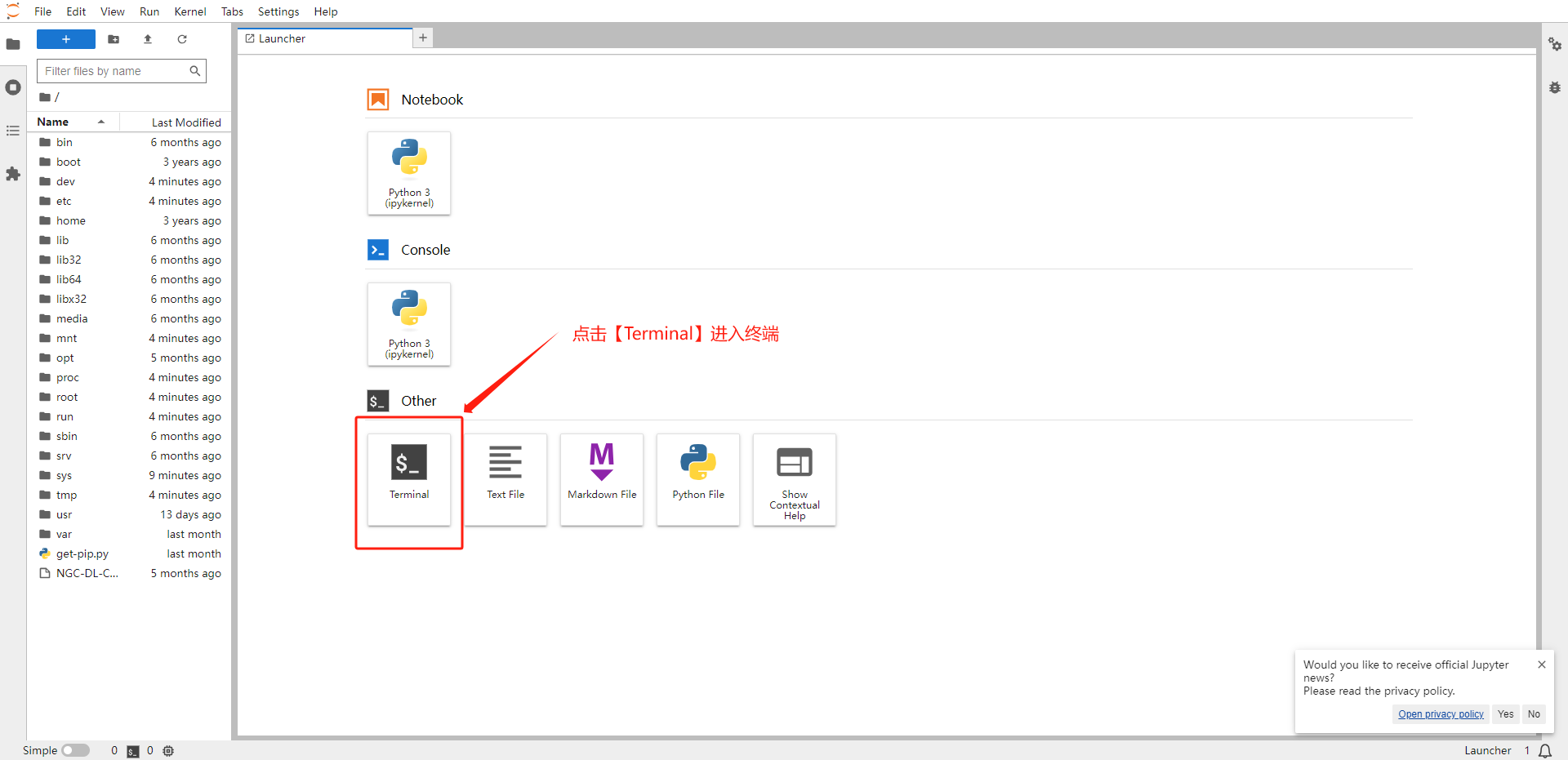
-
安装 git-lfs
# 安装git-lfs apt-get clean && apt-get update apt-get install git-lfs -y -
下载 CodeShell-7B-Chat 模型
# 进入root目录 cd /root # 初始化Git LFS,此处会有一个Error输出,忽略即可 git lfs install# 从国内镜像下载CodeShell-7B-Chat模型文件 # 备用链接:https://wisemodel.cn/WisdomShell/CodeShell-7B-Chat.git git lfs clone --depth 1 https://www.modelscope.cn/WisdomShell/CodeShell-7B-Chat.git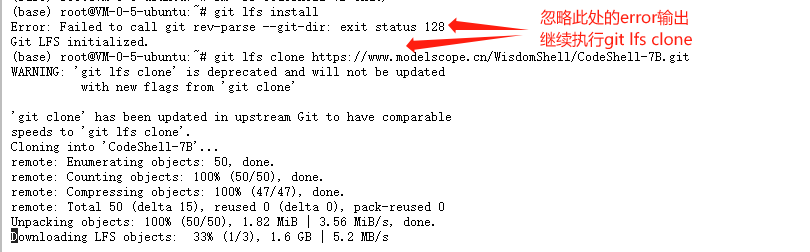
Tips:模型文件大概 14.5G 左右,在 HAI 提供的带宽只有 5M 的情况下,下载时间较久(50 分钟左右),因此可以新开一个终端窗口进行下一步:部署 TGI 服务
3.4 部署 text-generation-inference(TGI)推理服务
text-generation-inference(TGI)是 Hugging Face 发布的 LLM 开源推理部署框架,使用 Rust、Python 和 gRPC 构建。TGI 具备完整的 Web 体系,包括 Lanuchr(启动器)、Router(路由中间件)、Server(Python gRPC 服务),可以帮助用户完成启动、路由、调度请求、并发请求等相关操作。TGI 还提供了推理加速组件,包括 Flash-Attention、Page-Attention、Continuous Batching、模型并行。
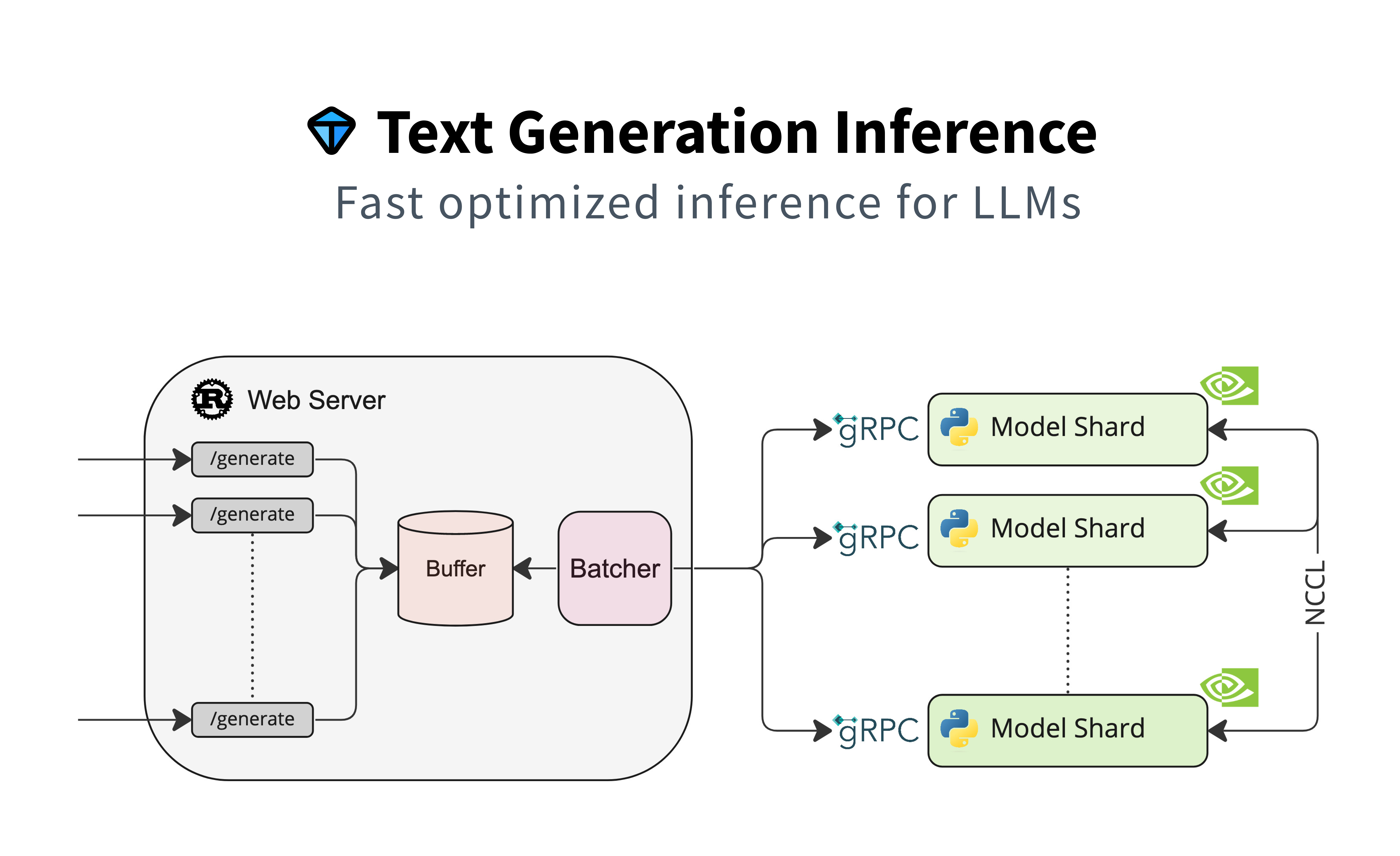
3.4.1 下载 text-generation-inference 项目
下载 text-generation-inference 项目的 CodeShell 分支
# Clone TGI
git clone https://github.com/WisdomShell/text-generation-inference.git
cd text-generation-inference
安装一些后续步骤需要用到的工具包
apt-get clean && apt-get update
apt-get install pkg-config openssl libssl-dev gcc curl -y
3.4.2 安装 Rust 环境
-
配置 Rust 国内镜像
vim ~/.bashrc # 设置rust镜像 export RUSTUP_DIST_SERVER="https://rsproxy.cn" export RUSTUP_UPDATE_ROOT="https://rsproxy.cn/rustup" export PATH="$HOME/.cargo/bin:$PATH" # 刷新环境变量 source ~/.bashrc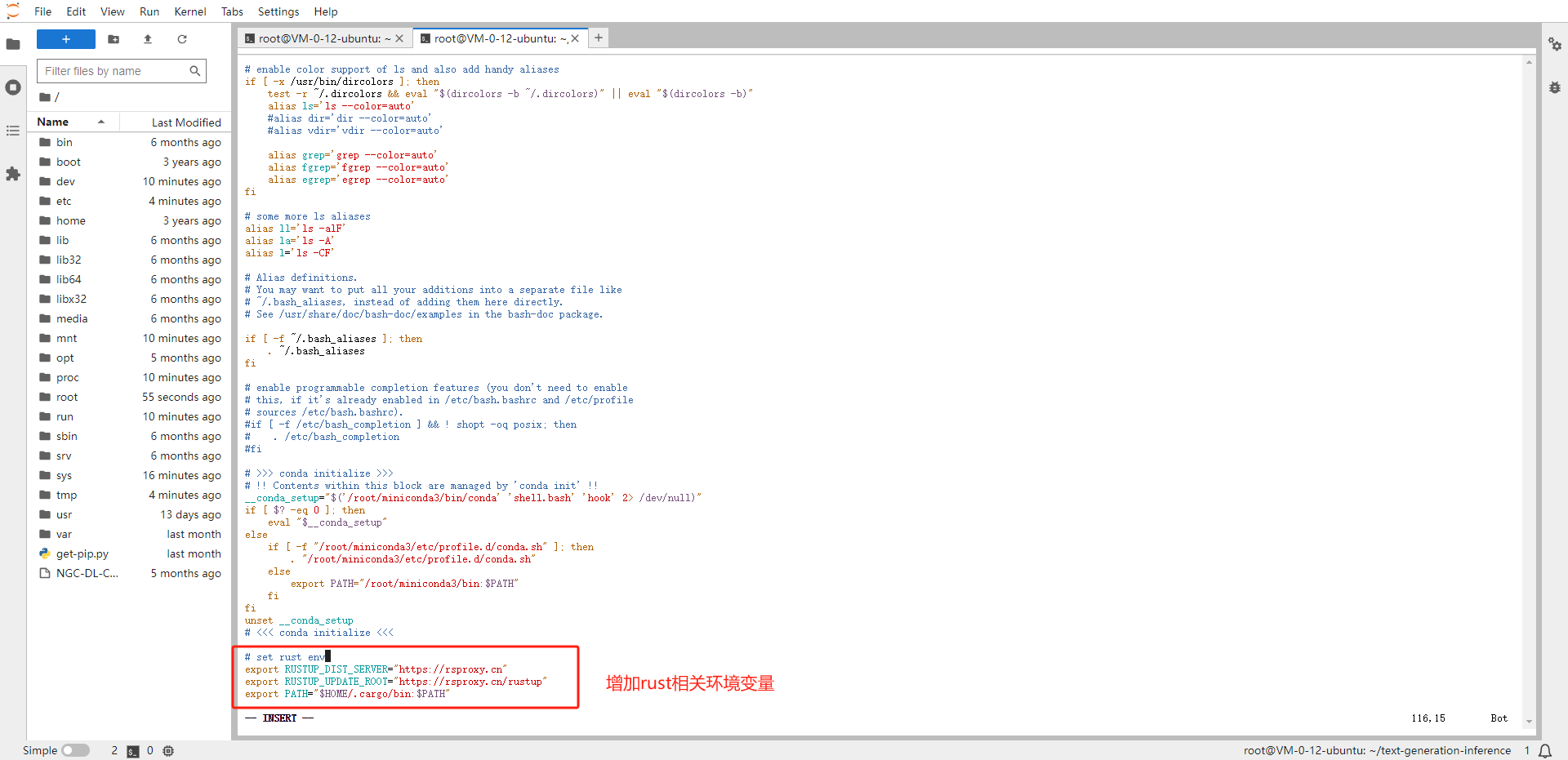
-
安装 Rust
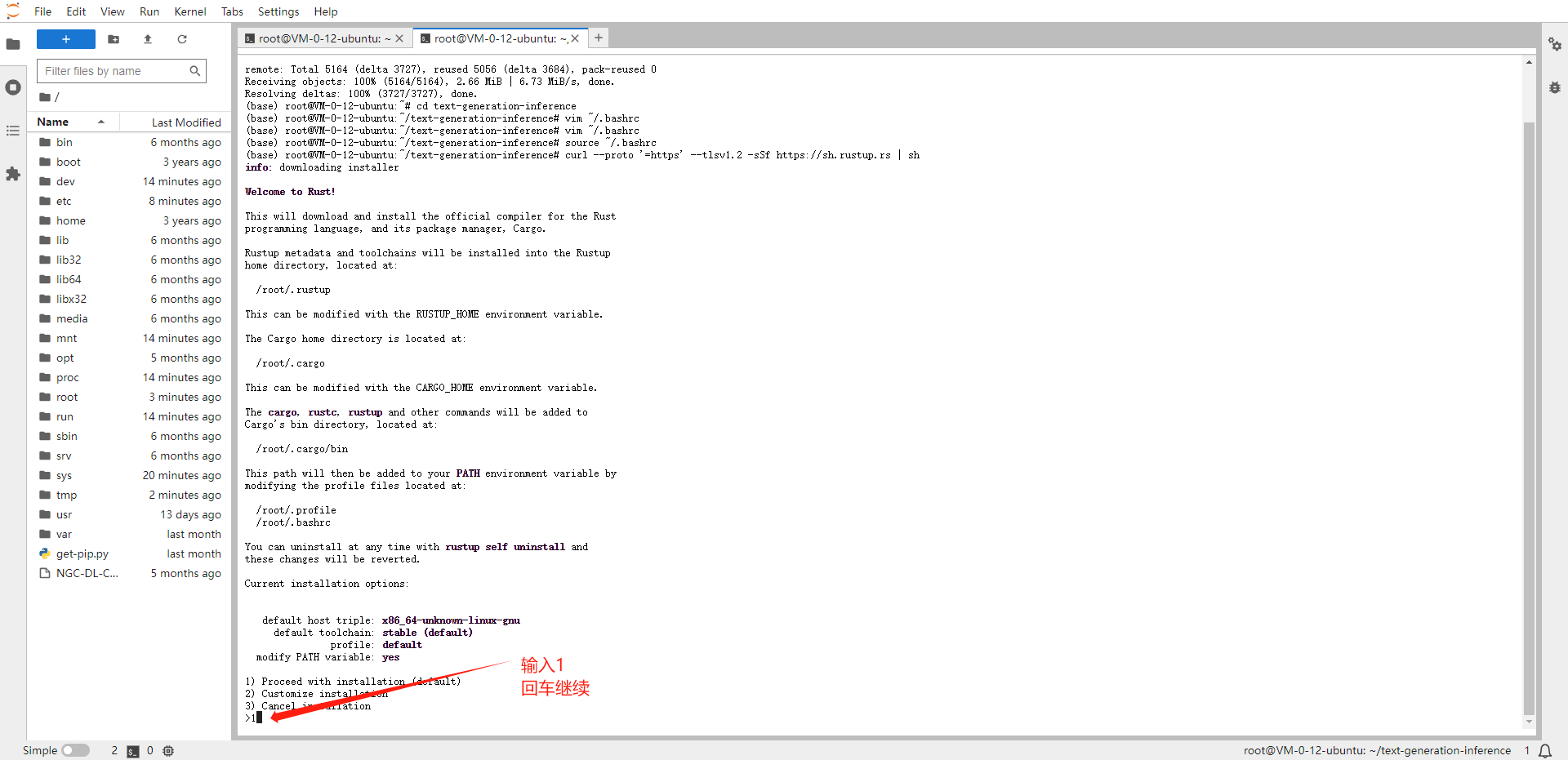
# 安装Rust环境 curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh中途会出现安装方案的选择提示,选择默认方案,输入 1,回车继续
# 安装成功后,手动执行命令使当前终端环境变量生效 source "$HOME/.cargo/env"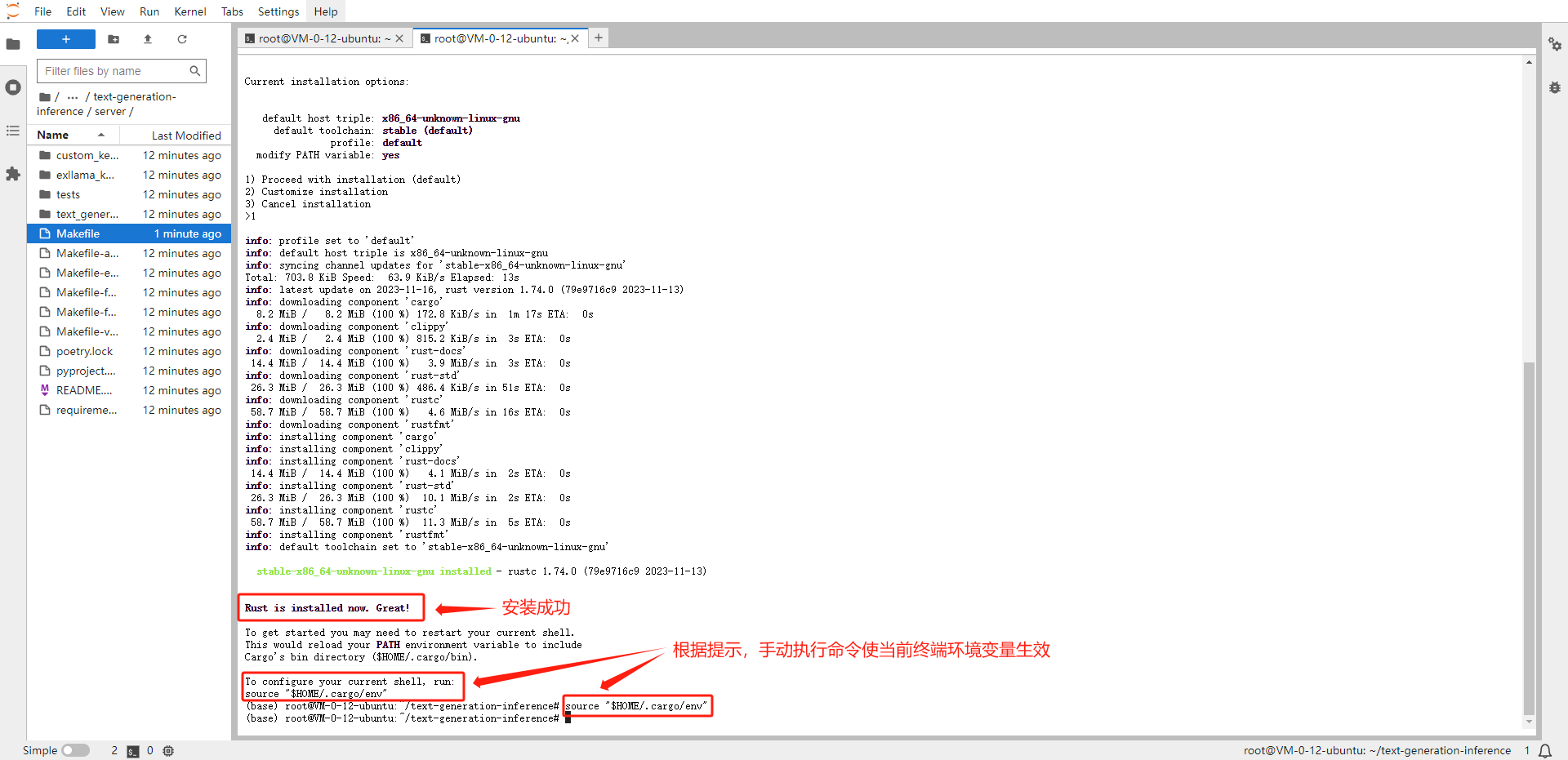
-
Cargo 是 Rust 的构建工具和包管理器,配置一下国内镜像源
vim ~/.cargo/config # 配置cargo镜像源 [source.crates-io] replace-with = 'rsproxy-sparse' [source.rsproxy] registry = "https://rsproxy.cn/crates.io-index" [source.rsproxy-sparse] registry = "sparse+https://rsproxy.cn/index/" [registries.rsproxy] index = "https://rsproxy.cn/crates.io-index" [net] git-fetch-with-cli = true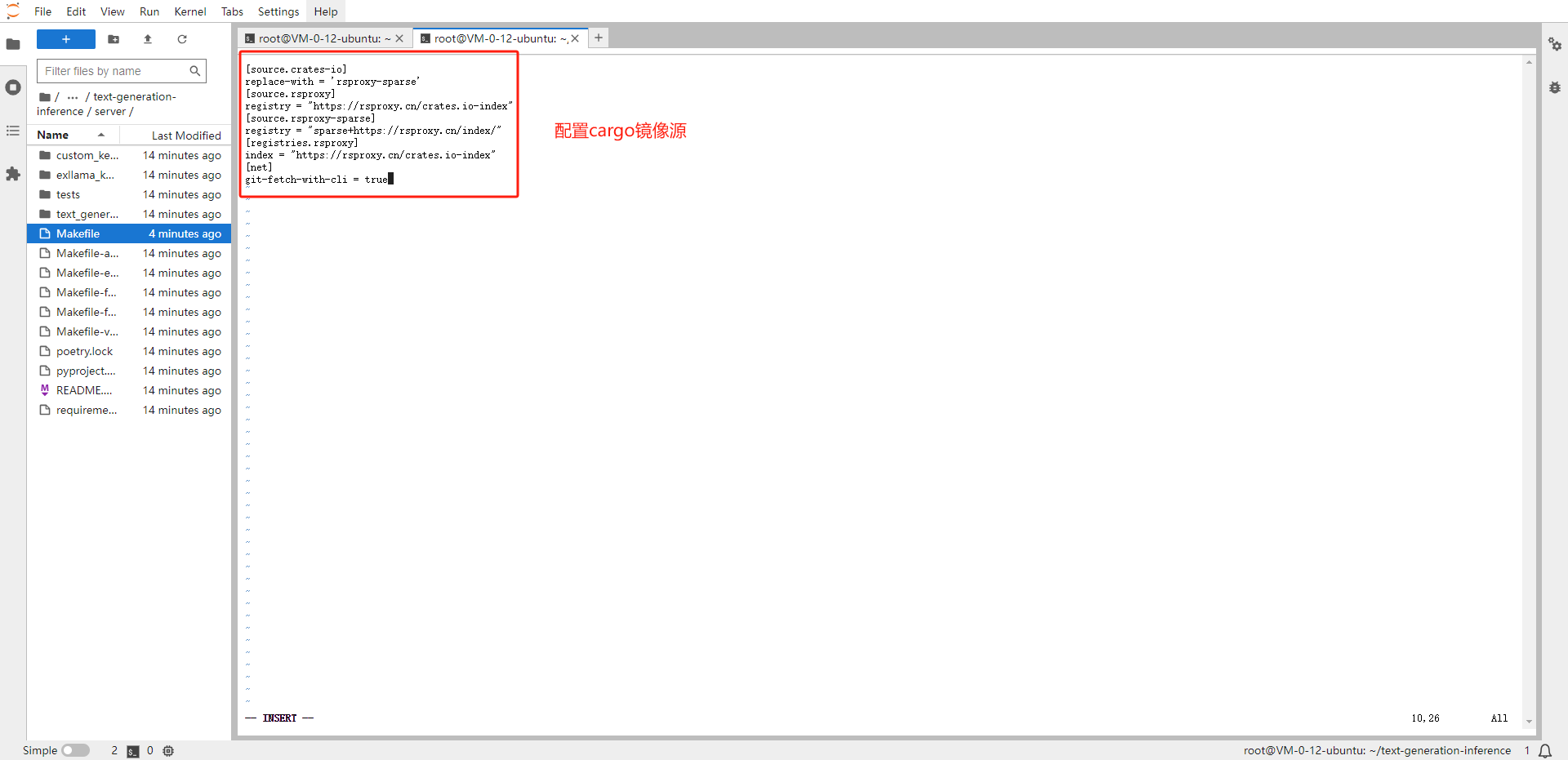
3.4.3 安装 Protoc
#安装Protoc
PROTOC_ZIP=protoc-21.12-linux-x86_64.zip
curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP
unzip -o $PROTOC_ZIP -d /usr/local bin/protoc
unzip -o $PROTOC_ZIP -d /usr/local 'include/*'
rm -f $PROTOC_ZIP
# 检查版本验证是否安装成功
protoc --version

3.4.4 编译安装 TGI
-
TGI 编译脚本中会自动从 Pytorch 官网下载最新版本的 Pytorch,速度较慢,修改编译脚本使其从国内镜像下载安装
# 从左侧文件管理器点击进入/root/text-generation-inference/server/目录 # 将Makefile文件的第21行替换为如下命令: pip install torch torchvision torchaudio -f https://mirror.sjtu.edu.cn/pytorch-wheels/cu118/torch_stable.html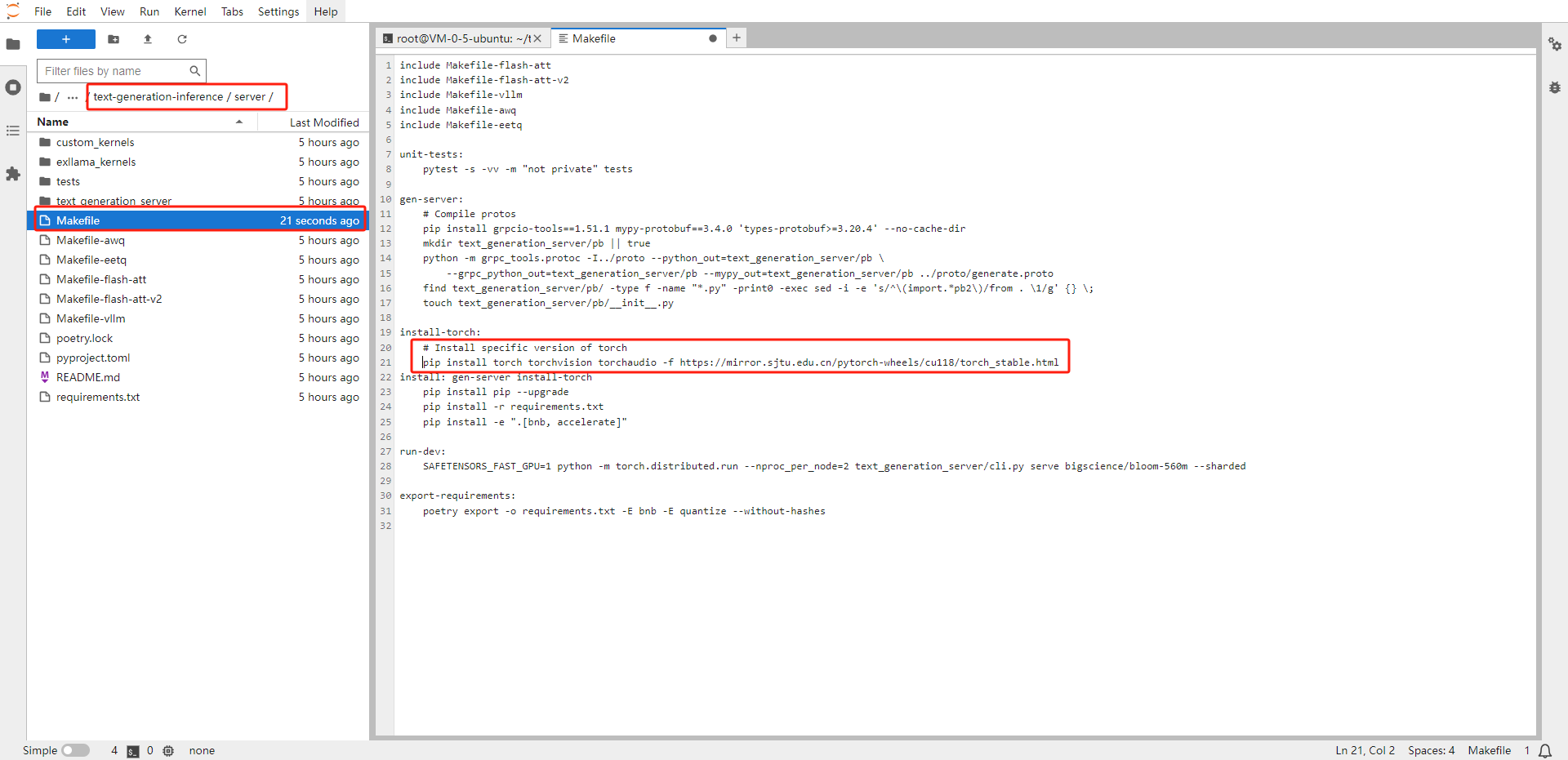
-
编译安装 text-generation-launcher
# 创建Python3.9环境 conda create -n text-generation-inference python=3.9 #激活环境 conda activate text-generation-inference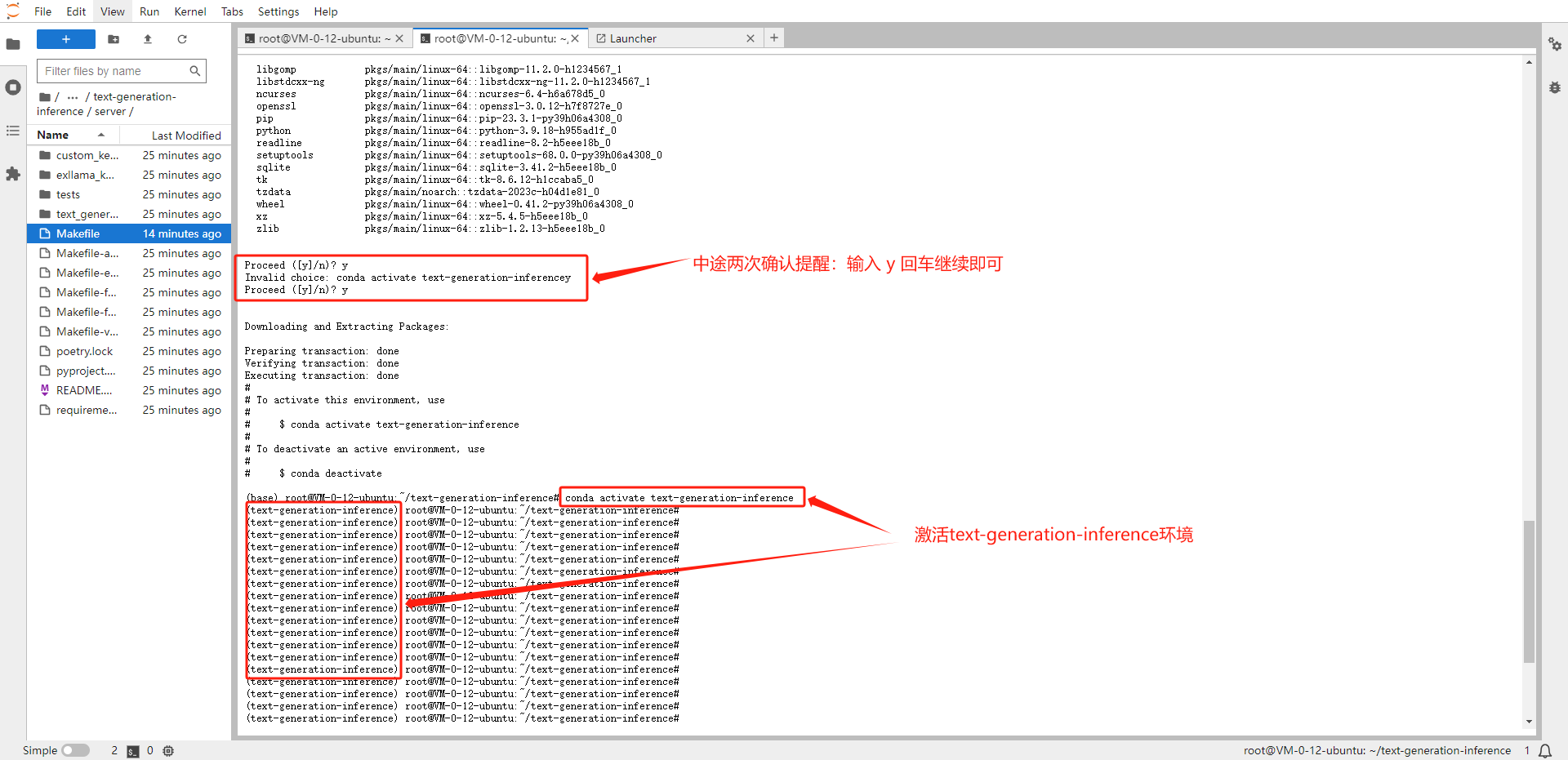
# 编译安装TGI,此过程耗时较久,请耐心等待~~ cd /root/text-generation-inference BUILD_EXTENSIONS=True make install# 查看版本检查是否安装成功 text-generation-launcher --version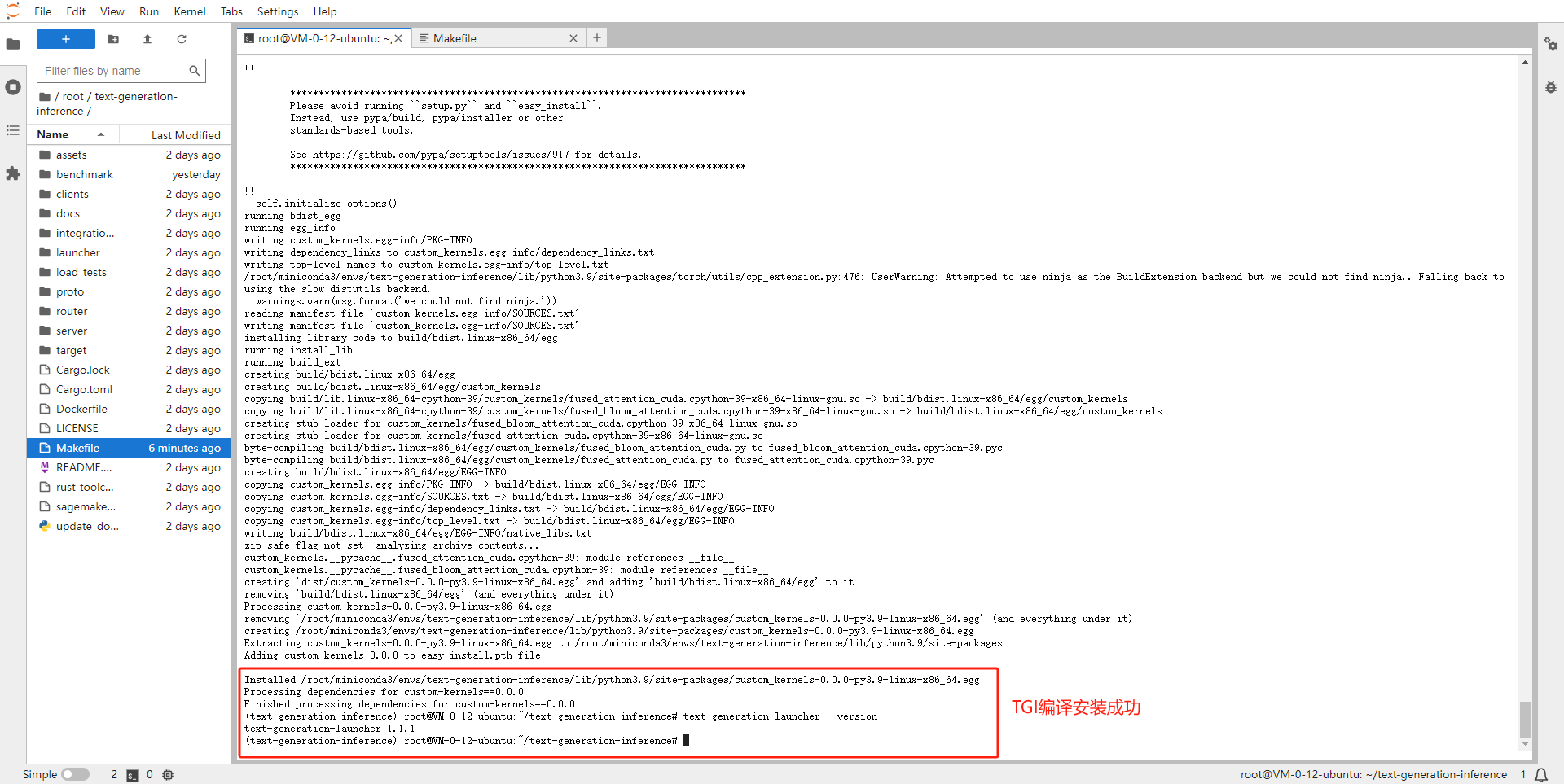
3.4.5 启动 TGI 服务
-
修改 TGI 启动命令,加载本地模型文件
# 从左侧文件管理器点击进入/root/text-generation-inference/目录 # 将Makefile文件的第52行替换为如下命令: text-generation-launcher --model-id /root/CodeShell-7B-Chat --port 3030 --num-shard 1 --max-total-tokens 5000 --max-input-length 4096 --max-stop-sequences 12 --trust-remote-code# --model-id为本地模型文件所在路径 # --port 为TGI服务端口 # 其余参数保持默认即可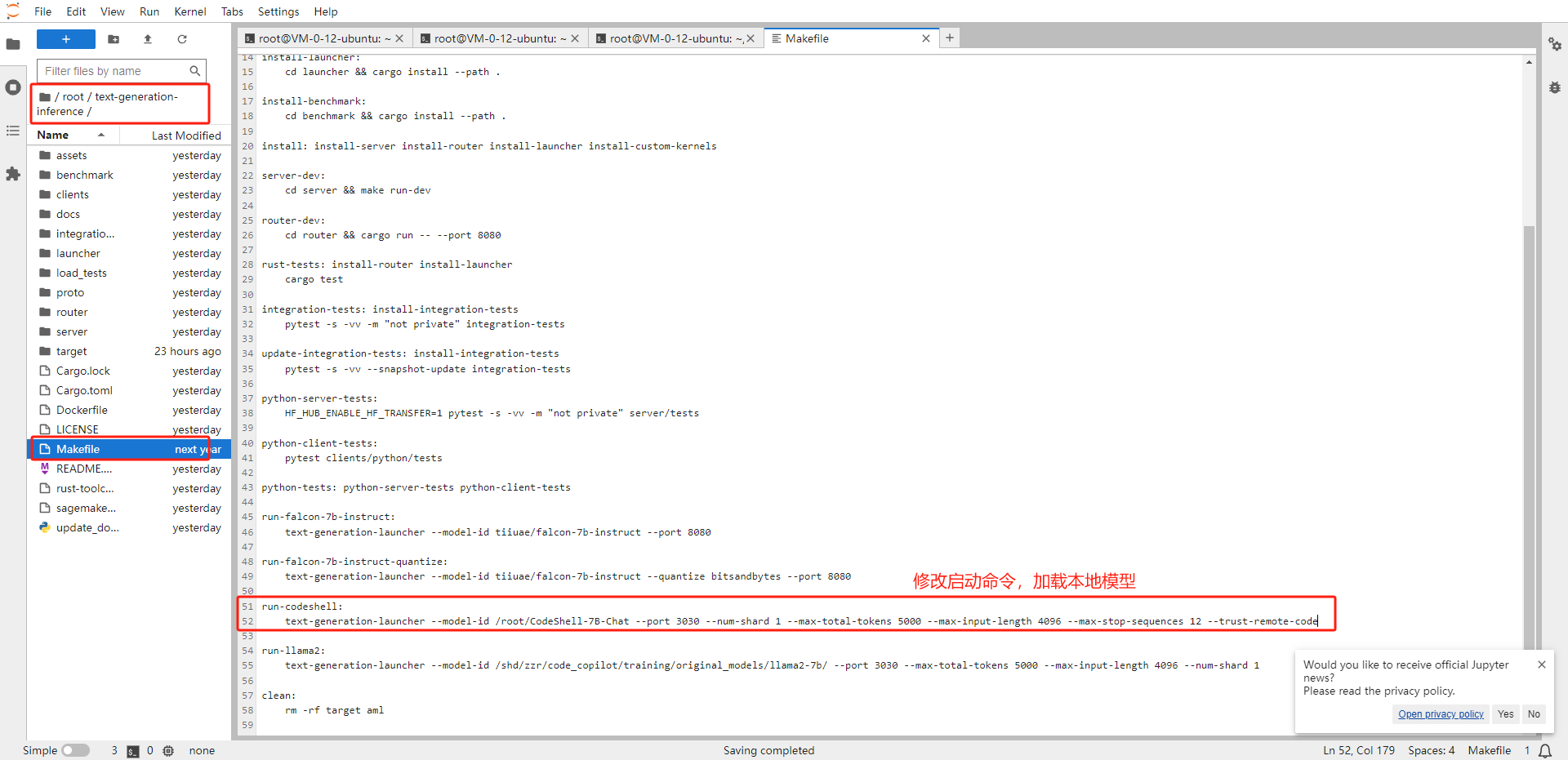
-
启动 TGI 服务
# 启动服务:大概需要5-10分钟左右才能启动成功 cd /root/text-generation-inference/ make run-codeshell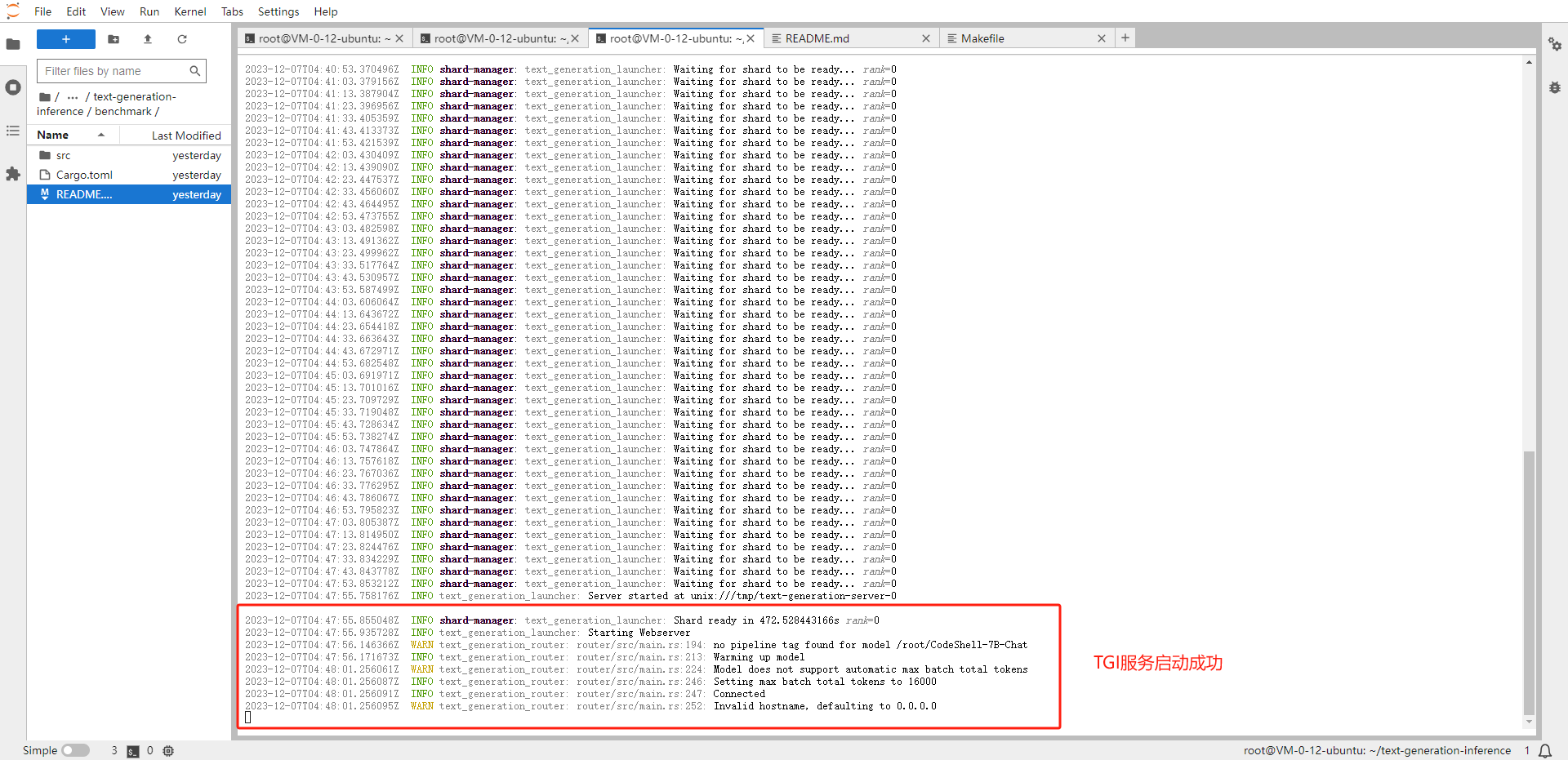
-
如果 HAI 实例关机后再次开机,可以使用如下命令直接启动 TGI 服务
#关机后再次开机 cd /root/text-generation-inference/ conda activate text-generation-inference make run-codeshell
3.5 配置 HAI 安全组规则
配置 HAI 安全组规则,将 TGI 服务的 3030 端口设置为允许公网访问。
注意:此处将 TGI 服务暴露于公网仅为了方便演示及测试。
直接将 TGI 服务向公网开放是不安全的操作,可能会引起一系列的安全问题。生产环境使用时请参考后文 5.2 章节进行相关安全优化
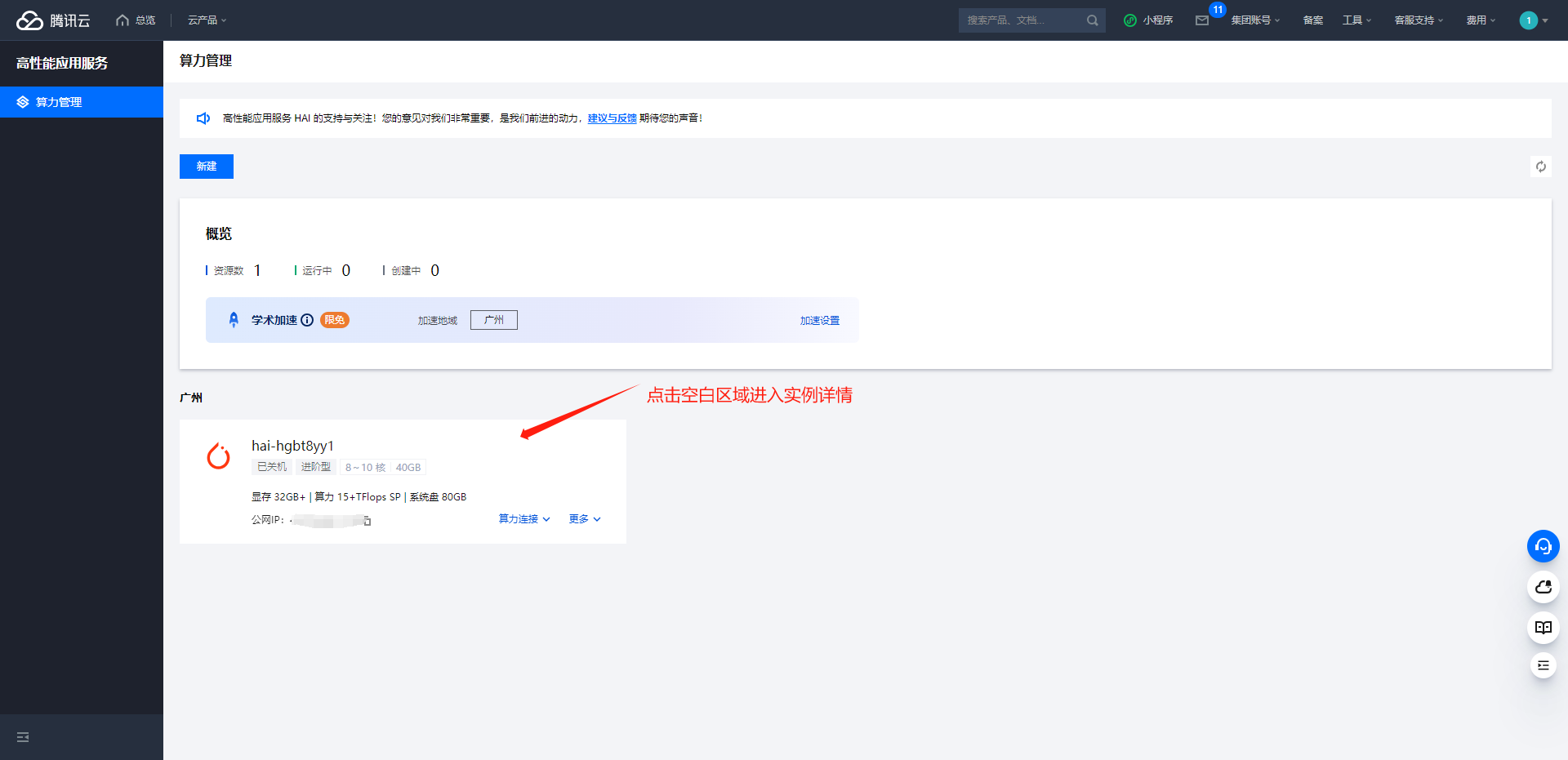
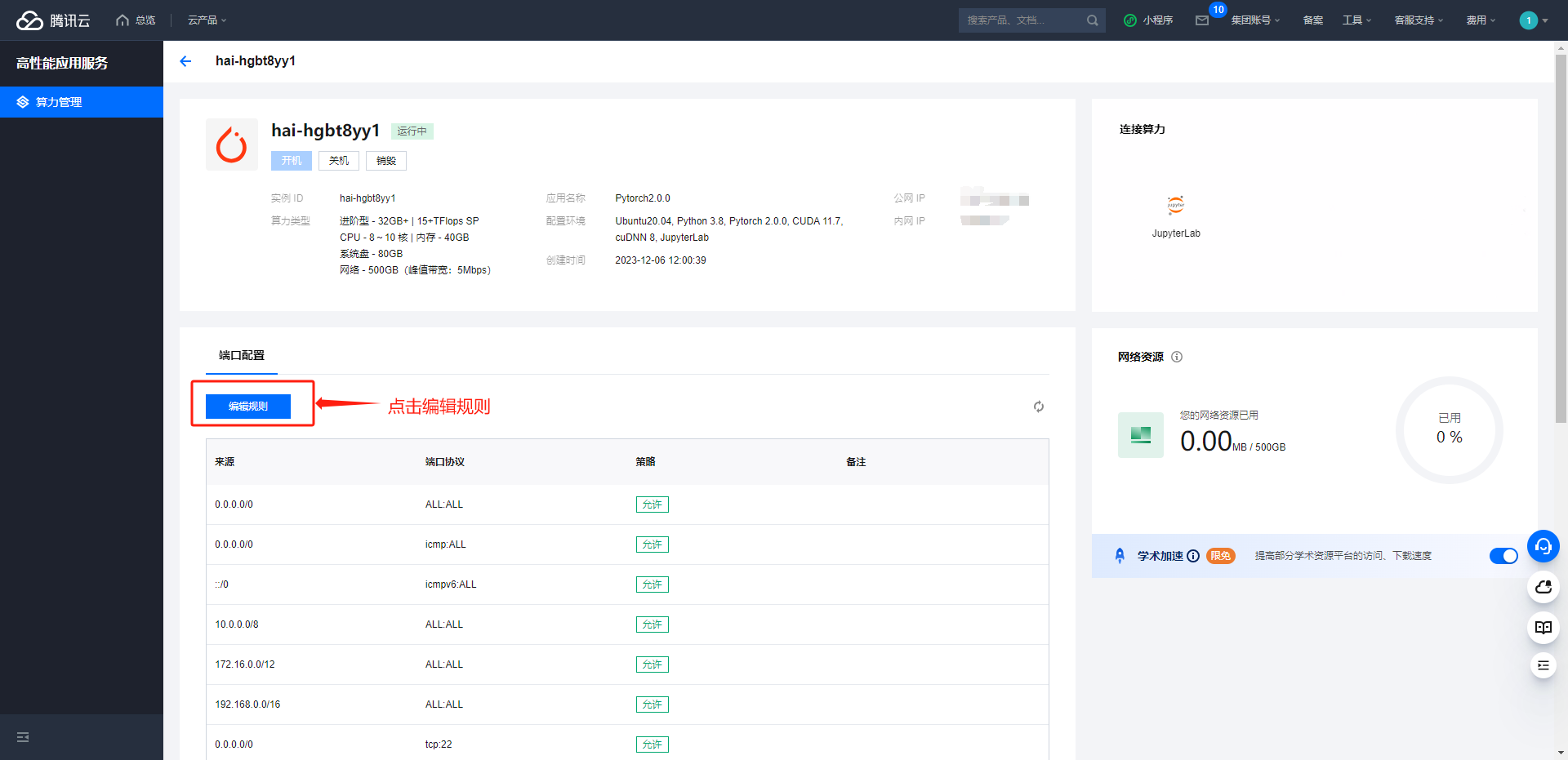
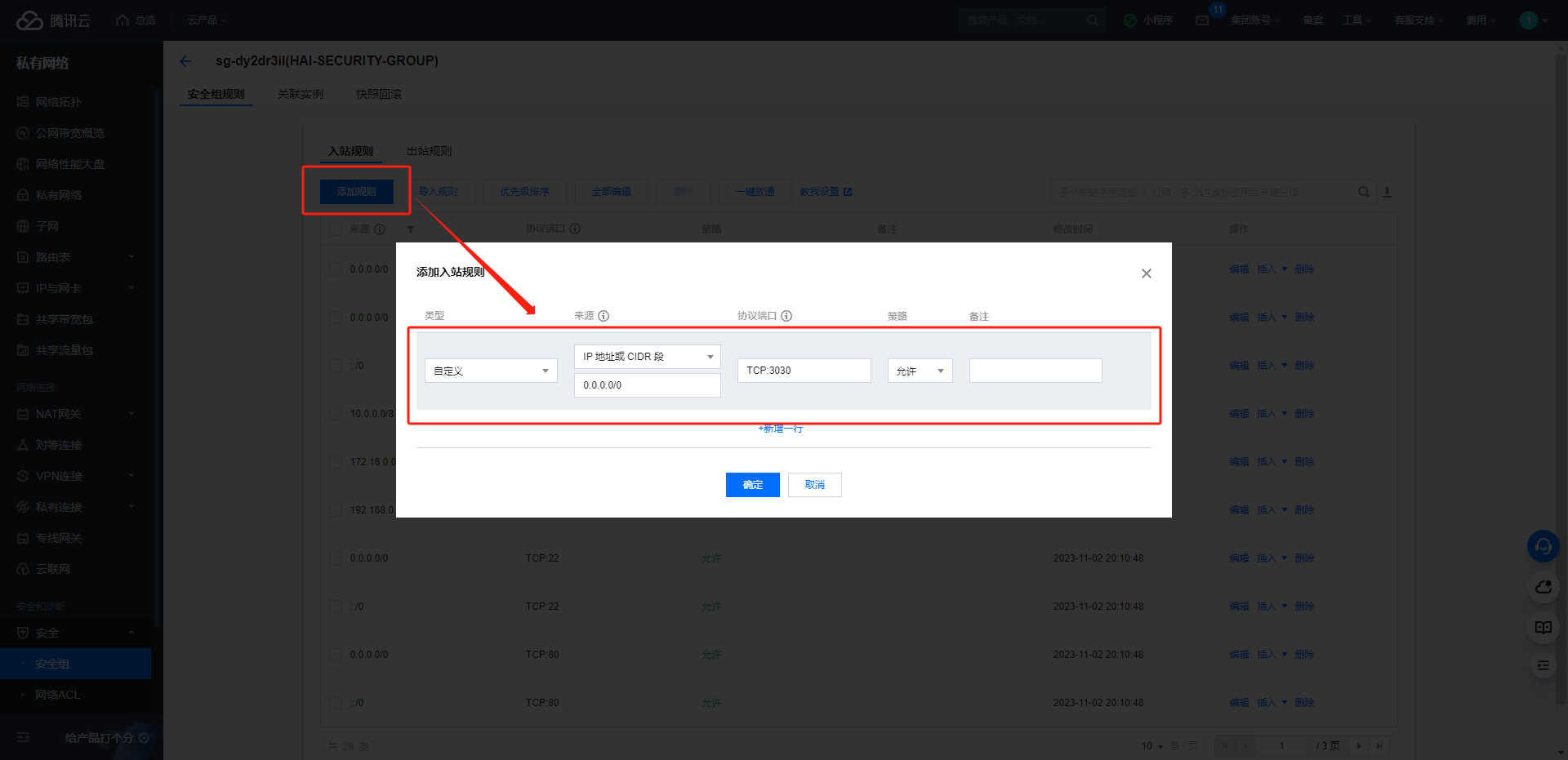
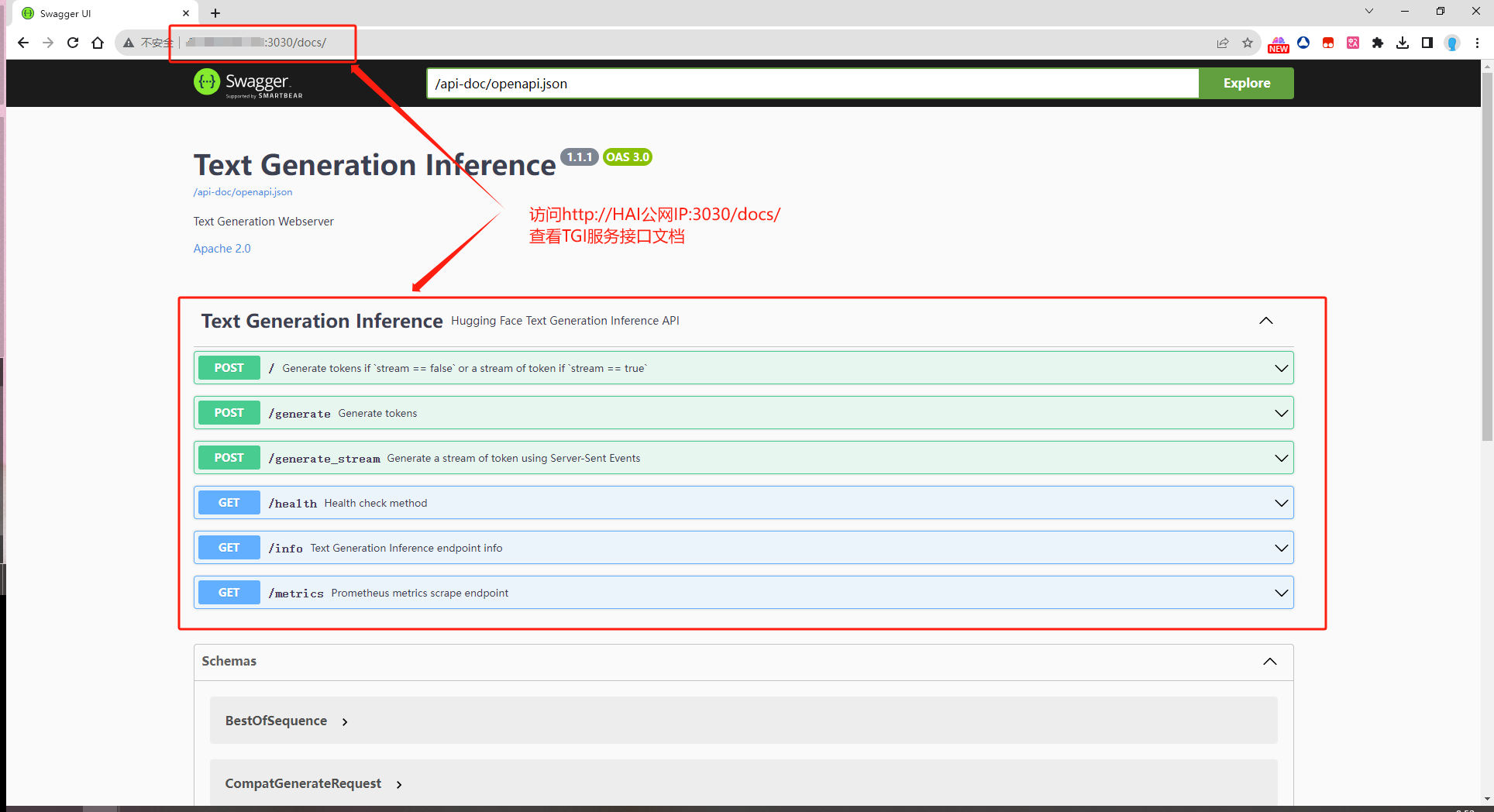
入站规则配置完成后,可以在浏览器打开 TGI 接口文档验证服务运行情况,TGI 接口文档地址:http://HAI公网IP:3030/docs/
3.6 配置 IDE 插件
Code Shell 实现并开源了 IDE(VS Code 与 JetBrains) 插件,打通了开发者使用大模型的“最后一公里”。开发者可以在 VS Code 与 JetBrains 的开发者商店中搜索“Code Shell”下载插件。
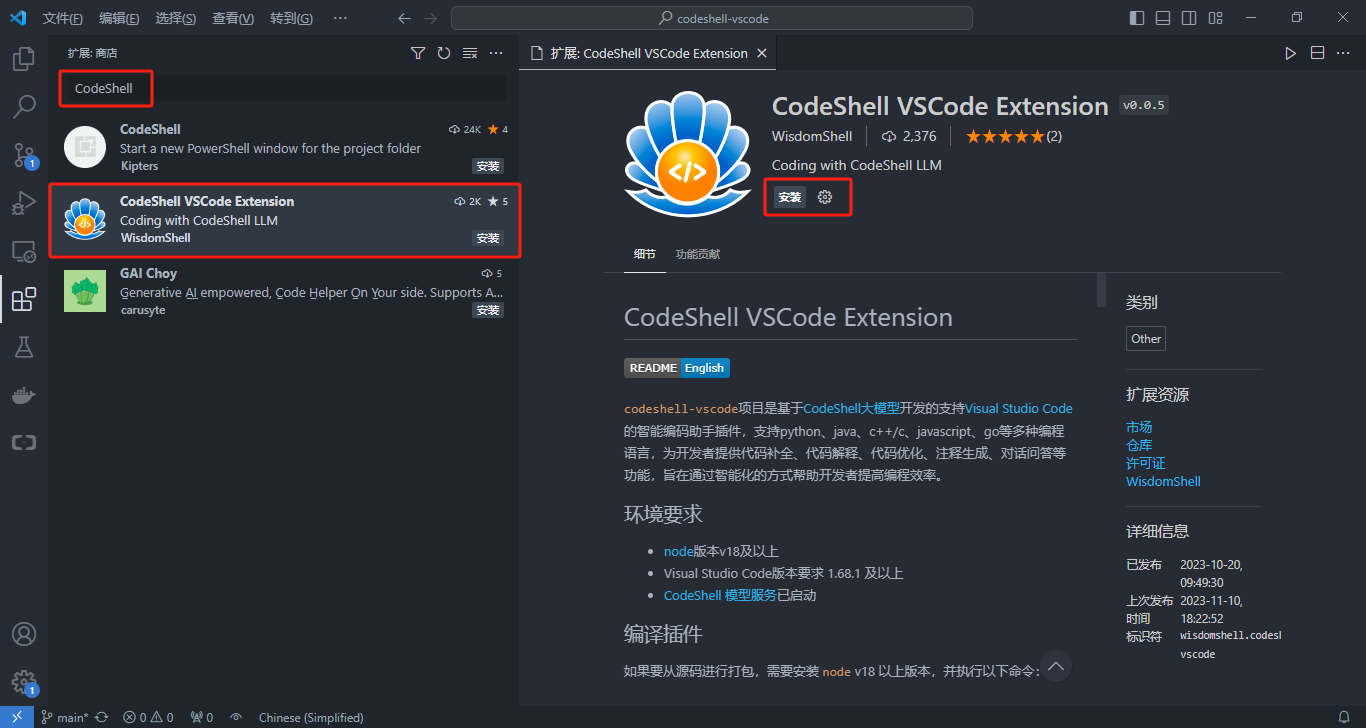
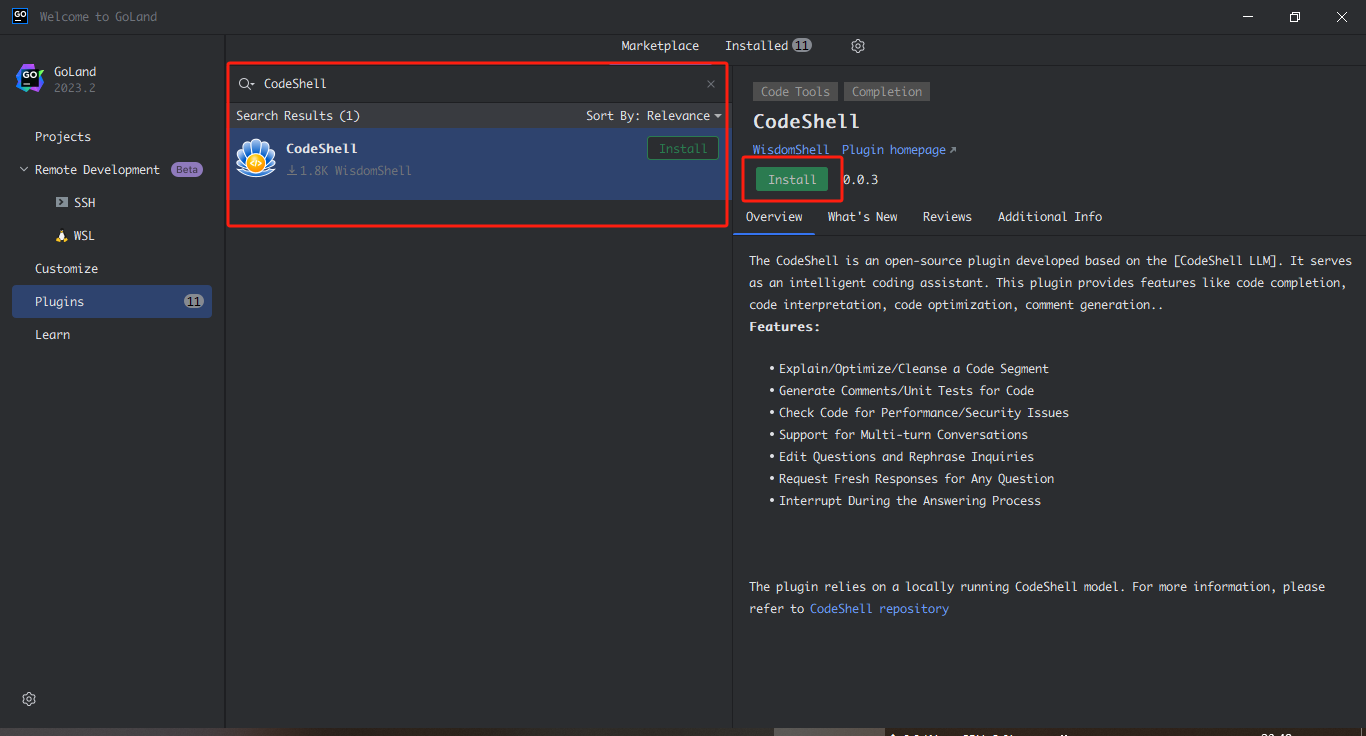
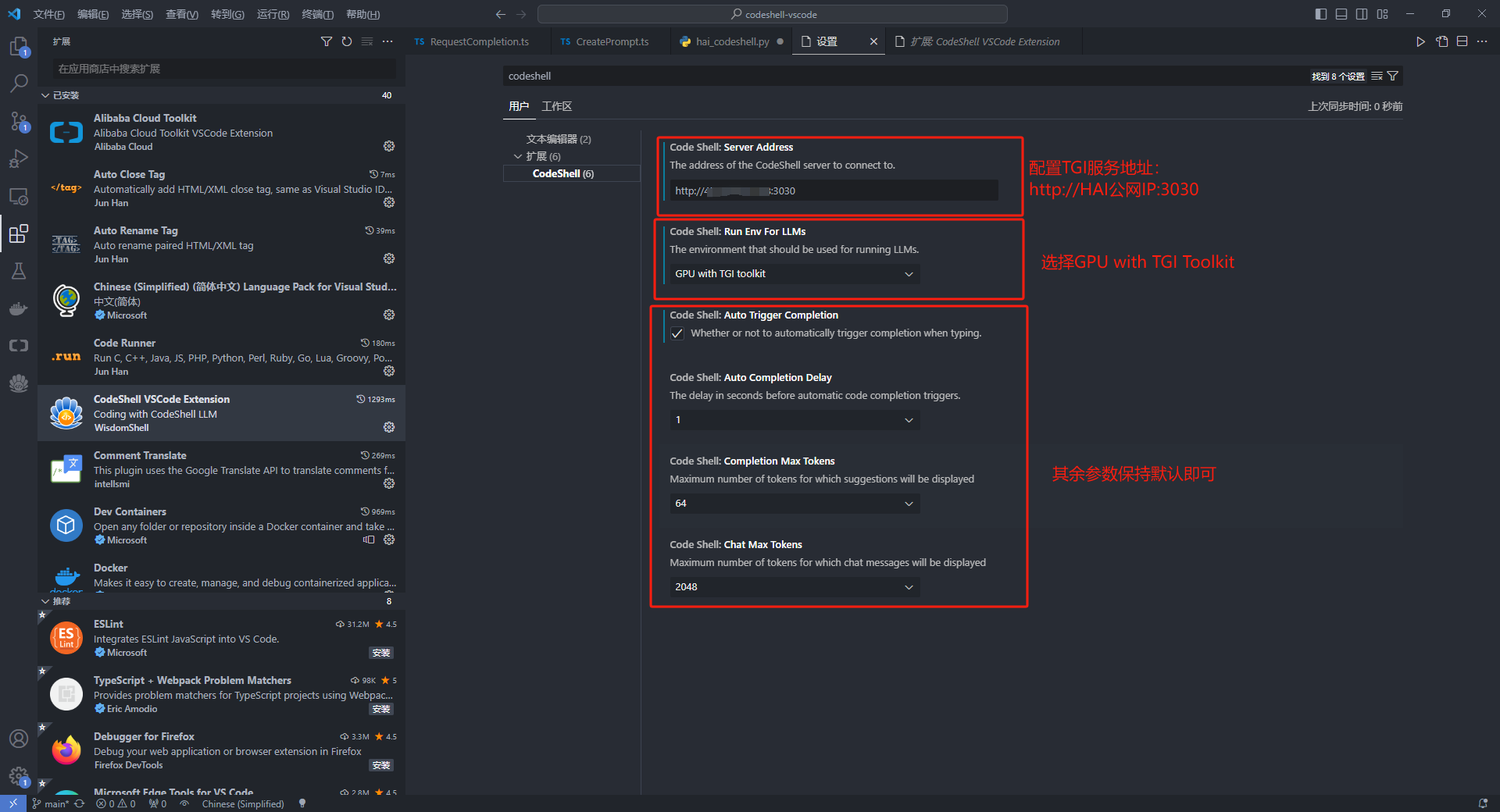
插件安装成功后,配置 TGI 服务地址等:
- 设置 CodeShell 大模型服务地址
- 配置模型运行环境
- 配置是否自动触发代码补全建议
- 配置自动触发代码补全建议的时间延迟
- 配置补全的最大 tokens 数量
- 配置问答的最大 tokens 数量
3.7 效果展示
-
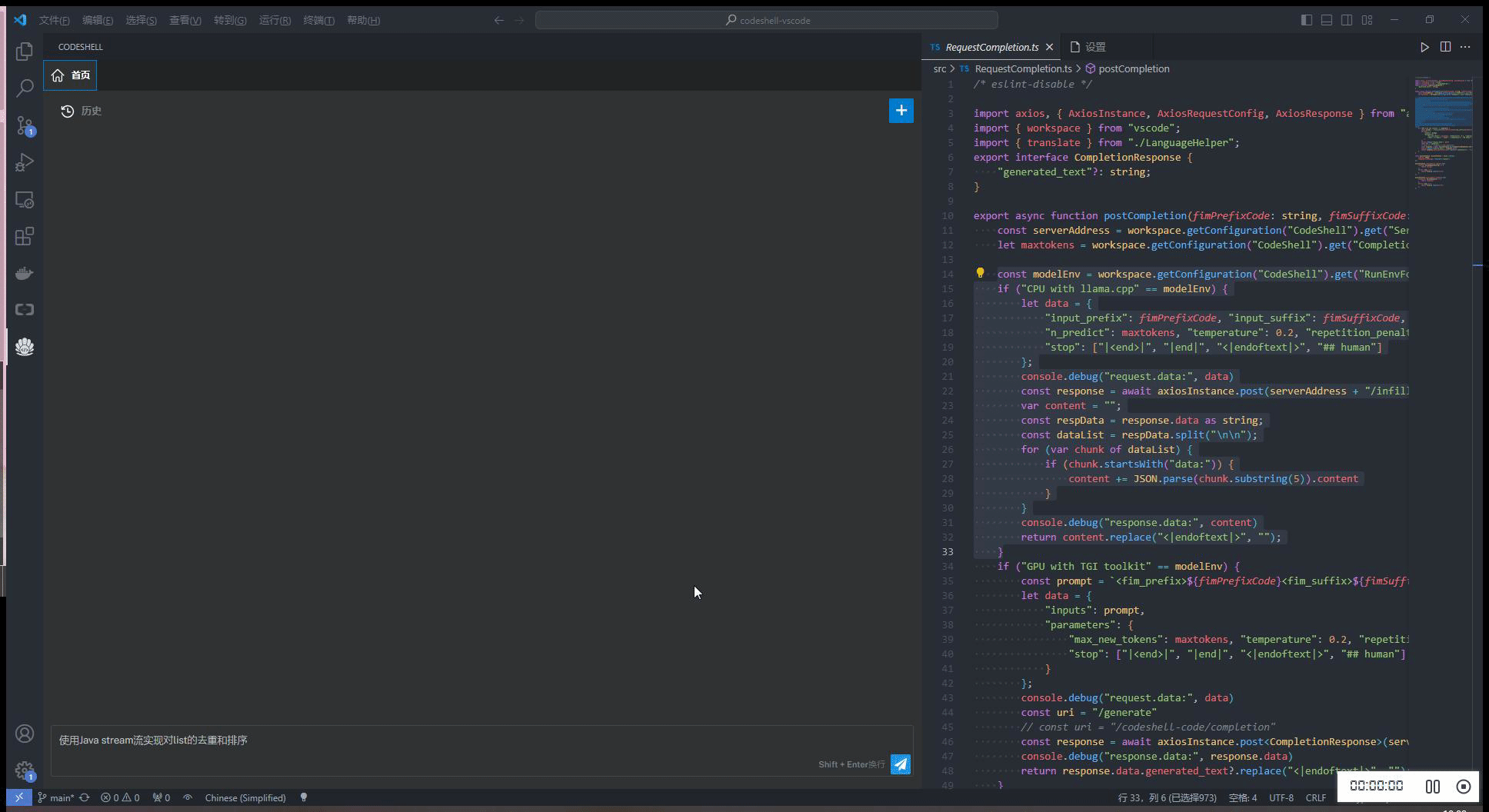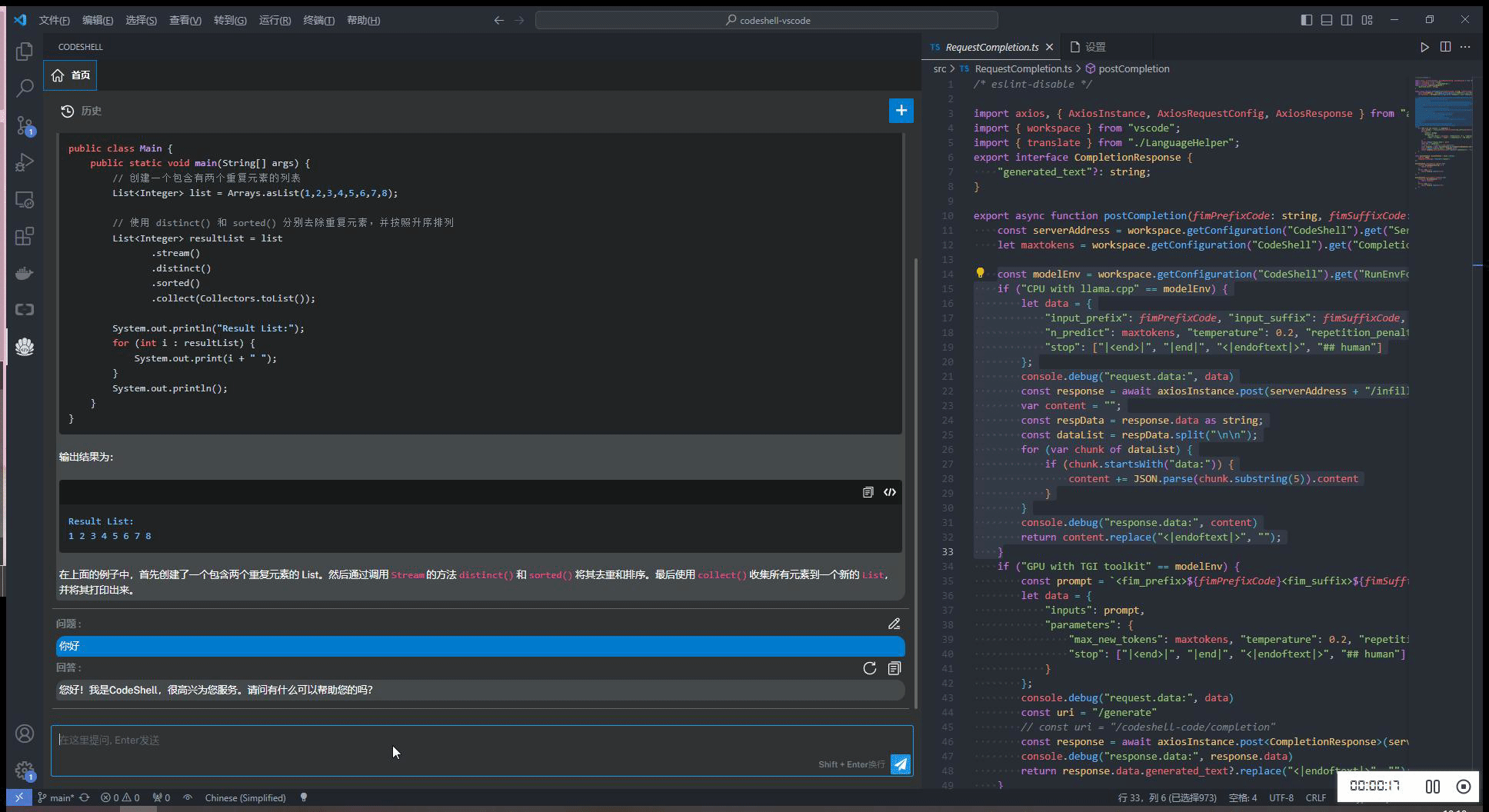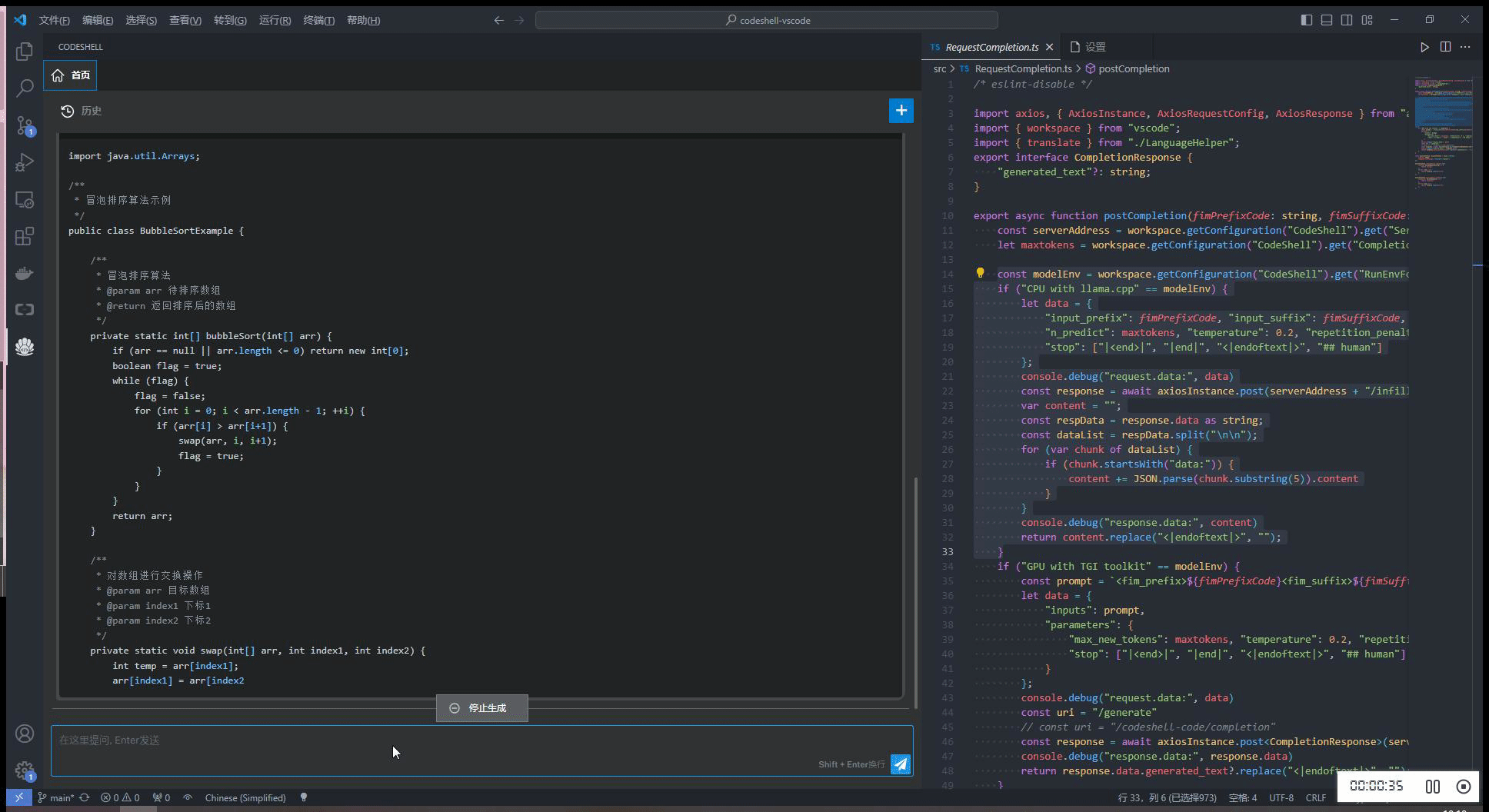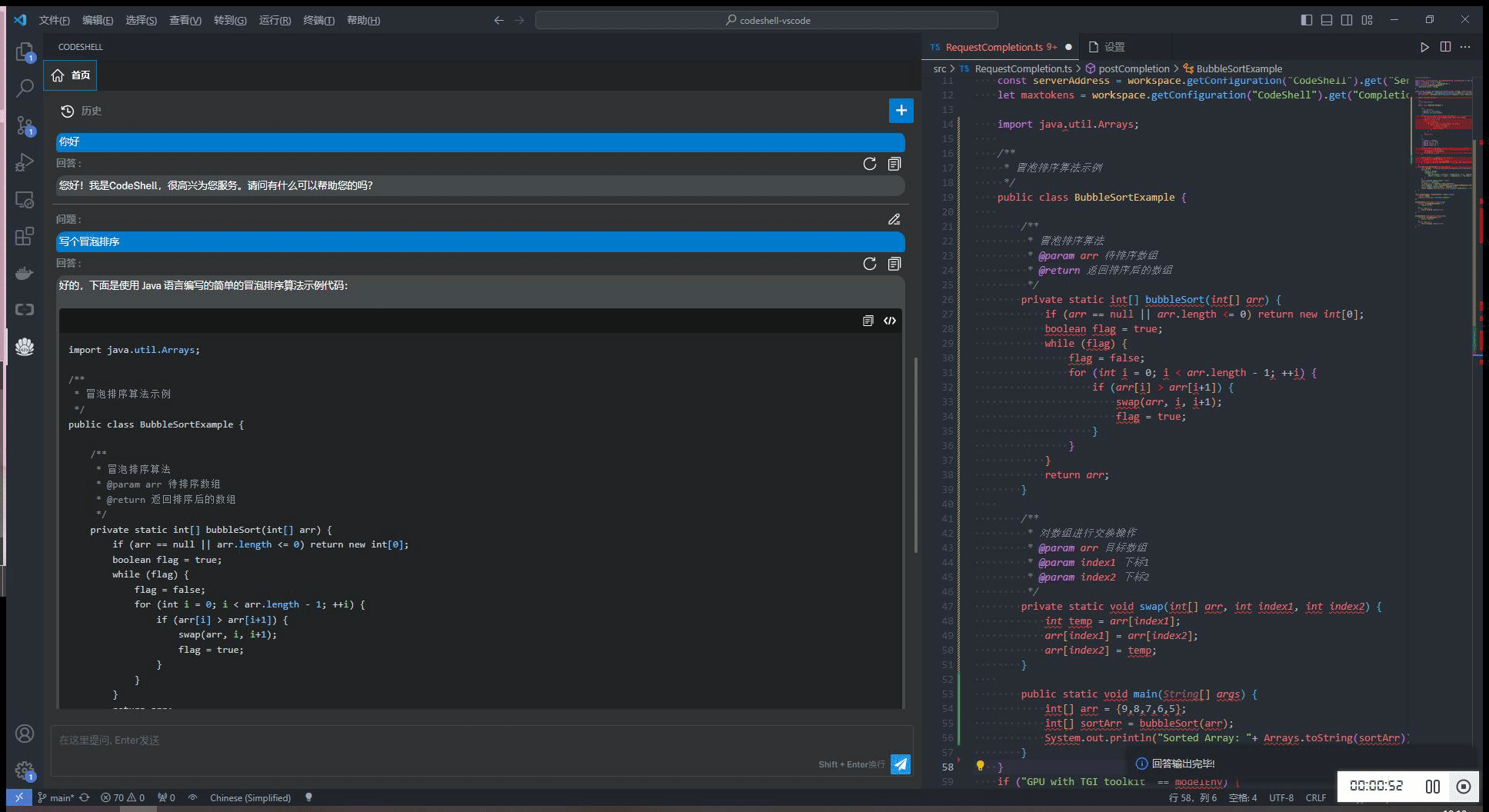
智能问答
- 支持多轮对话
- 支持会话历史
- 基于历史会话(做为上文)进行多轮对话
- 可编辑问题,重新提问
- 对任一问题,可重新获取回答
- 在回答过程中,可以打断
-
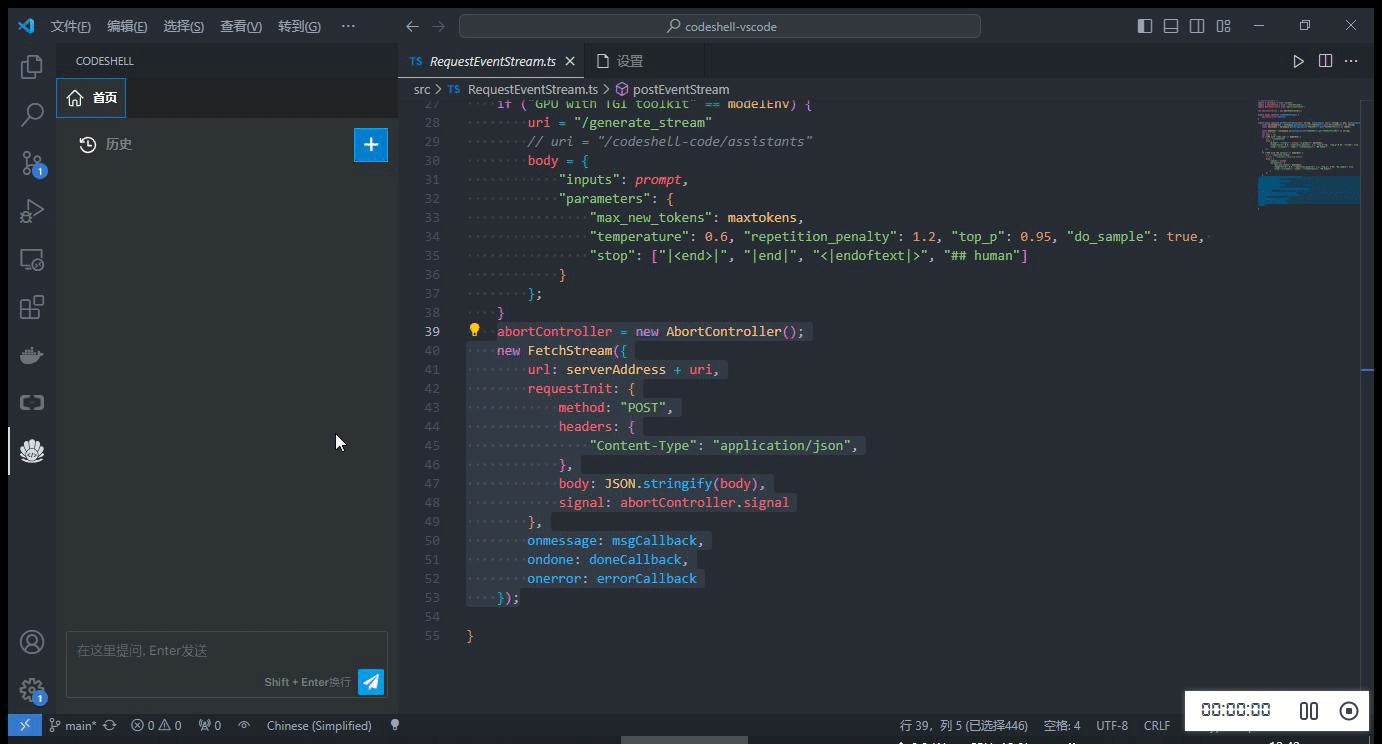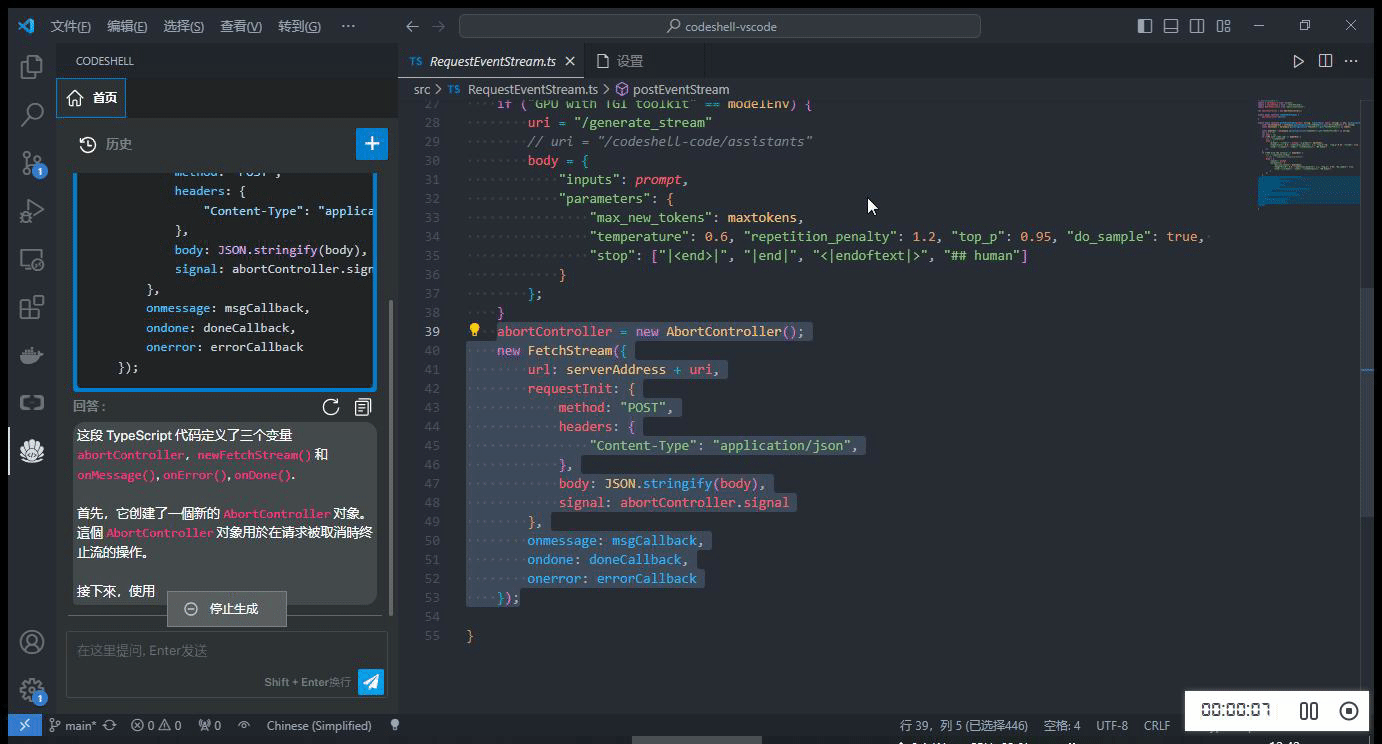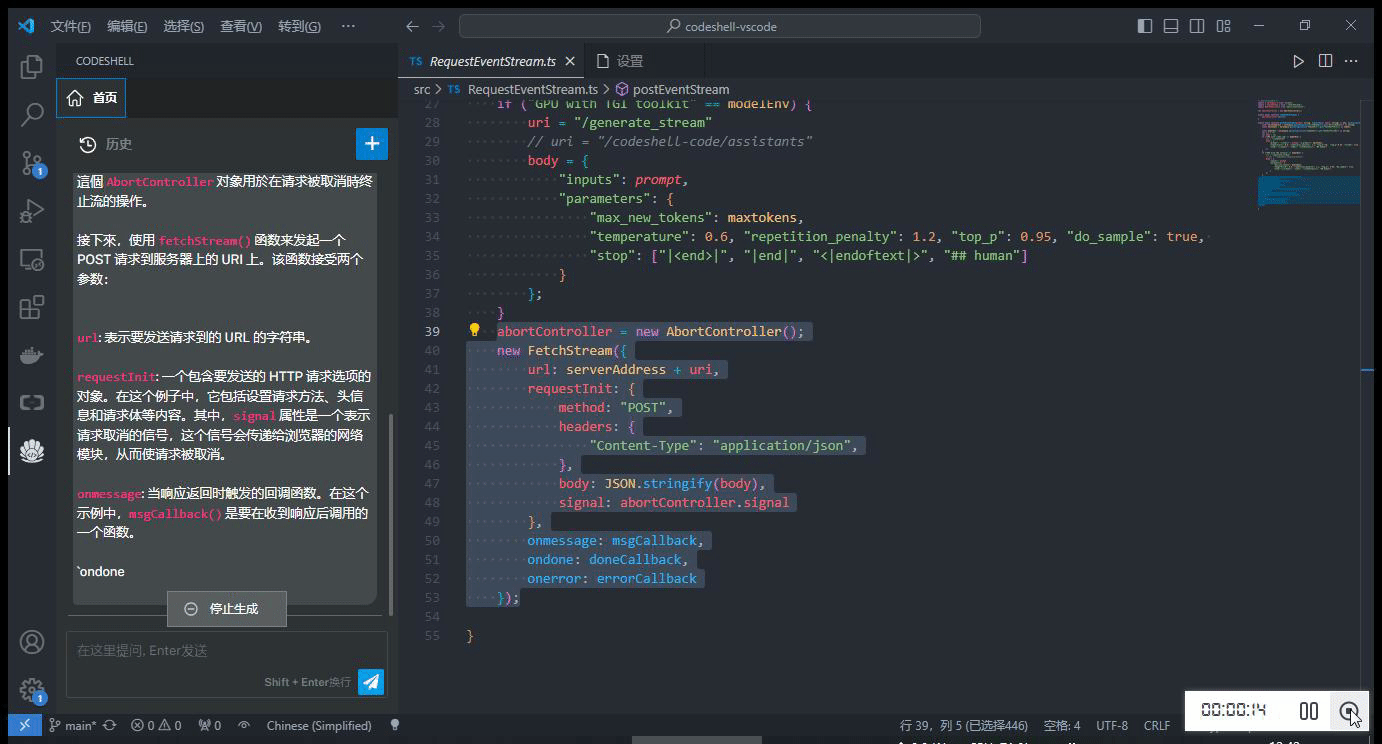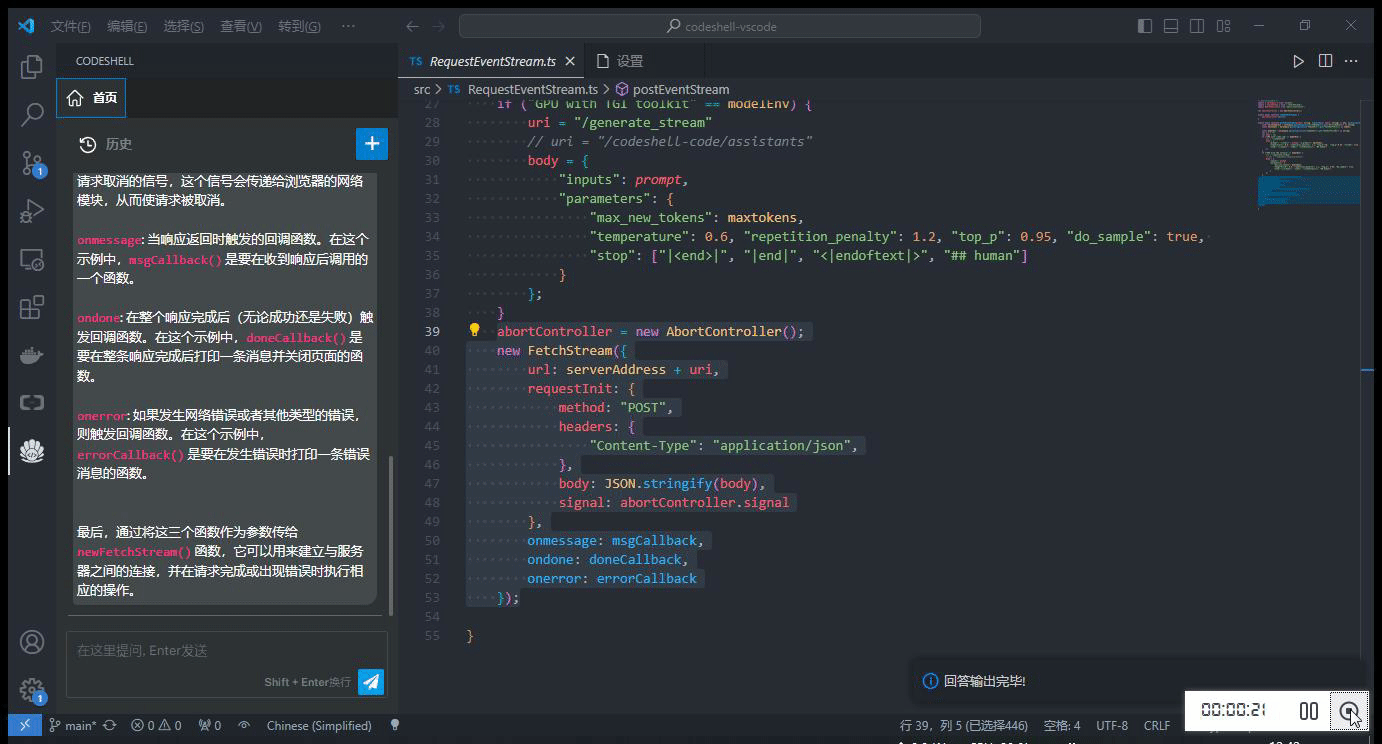
代码辅助
- 对一段代码进行解释/优化/清理
- 为一段代码生成注释/单元测试
- 检查一段代码是否存在性能/安全性问题
在编辑器中选中一段代码,在鼠标右键 CodeShell 菜单中选择对应的功能项,插件将在问答界面中给出相应的答复。
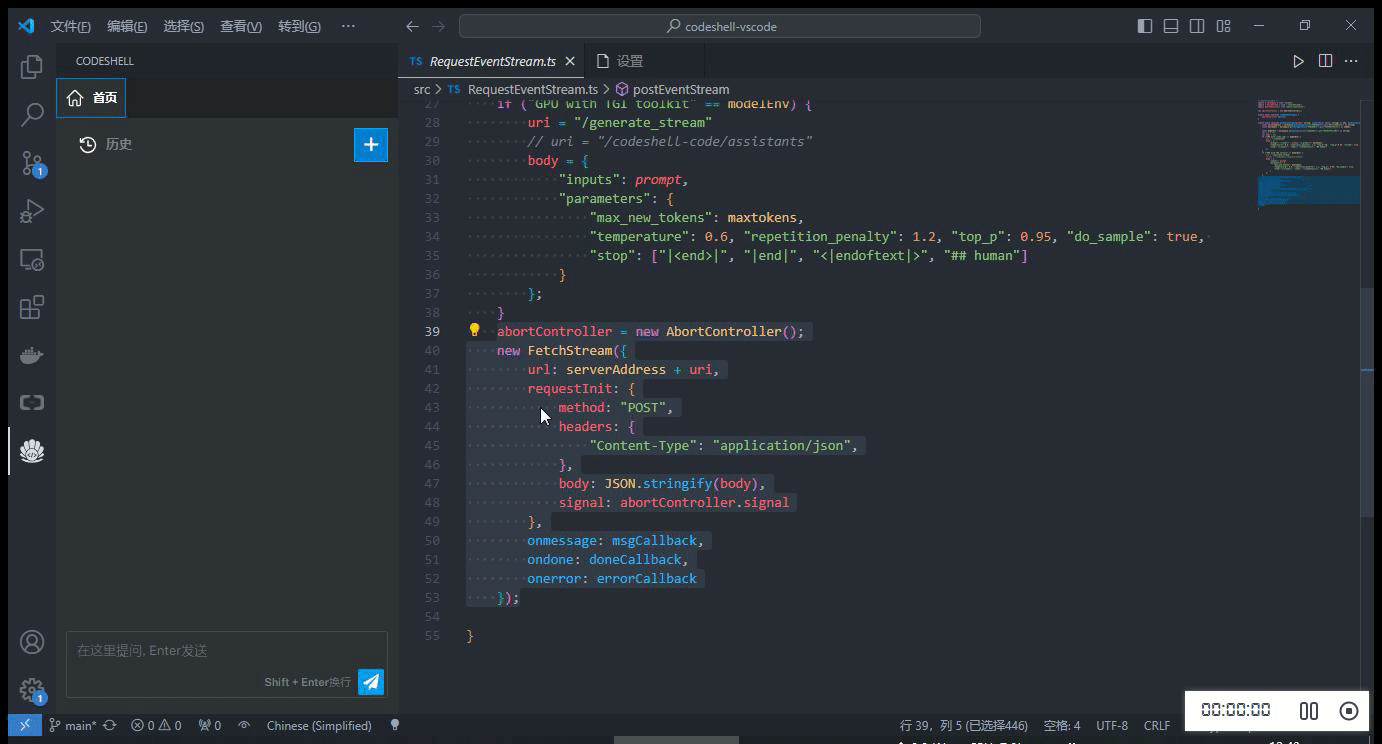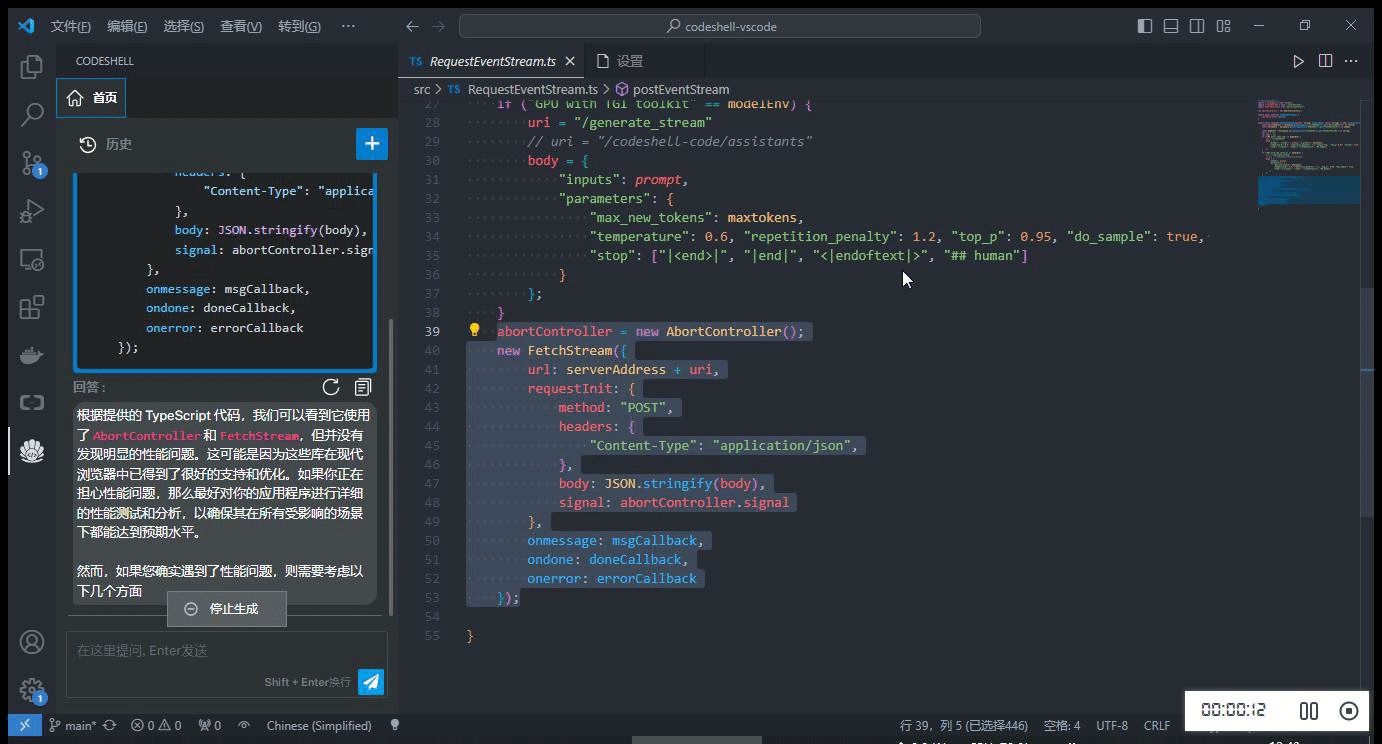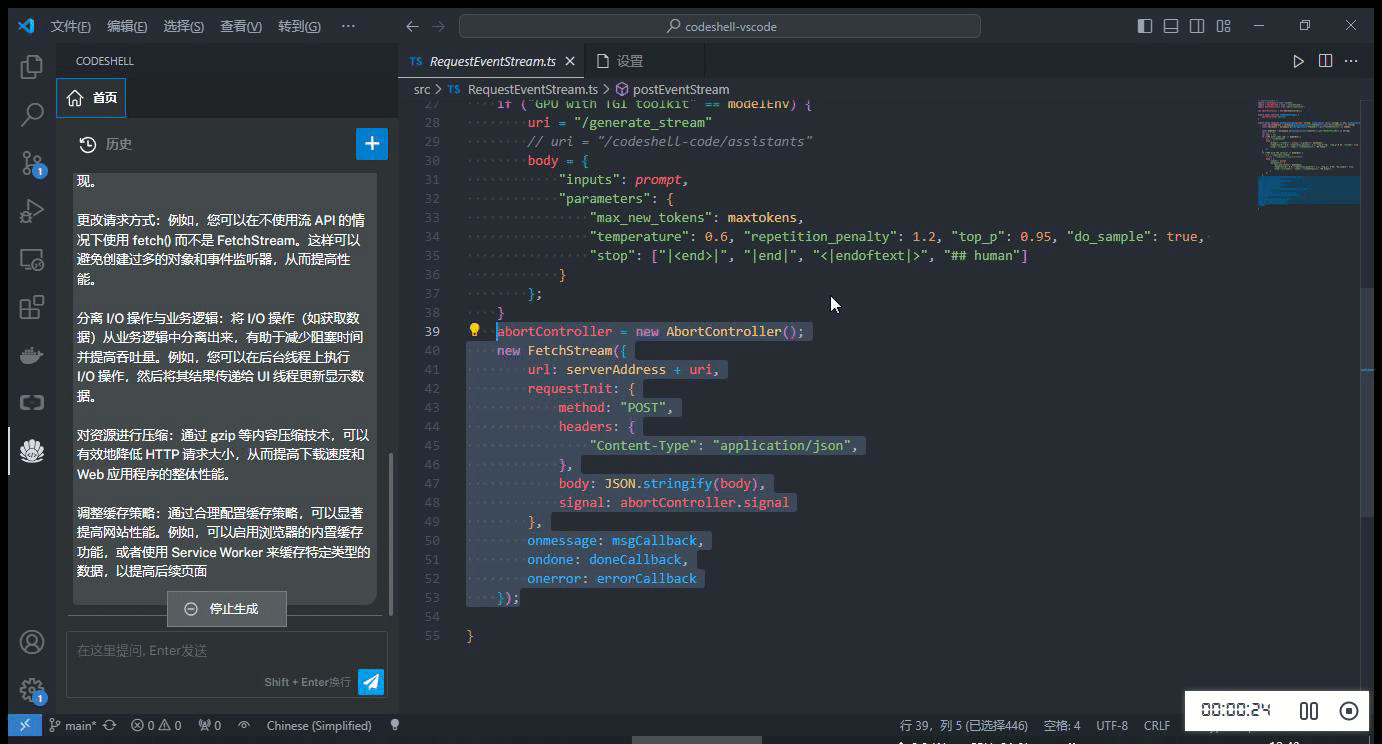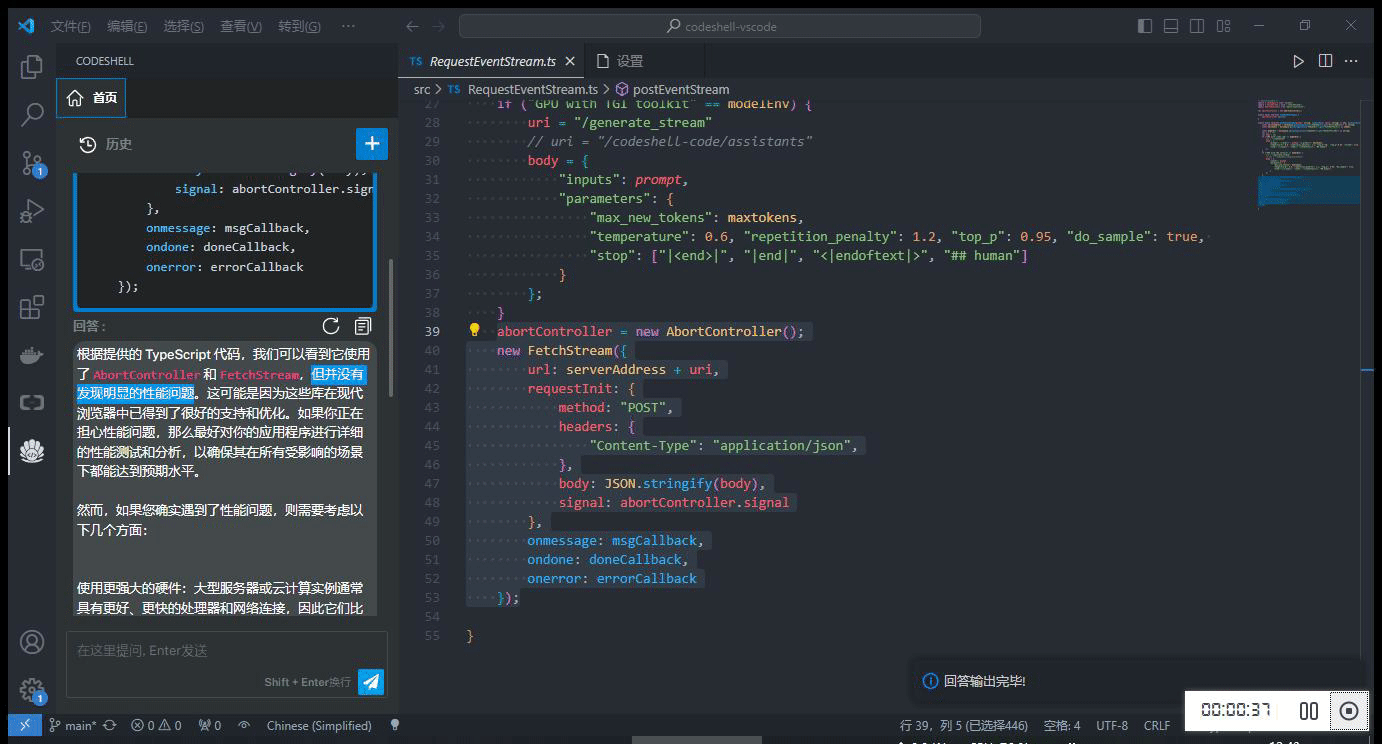
-
代码补全
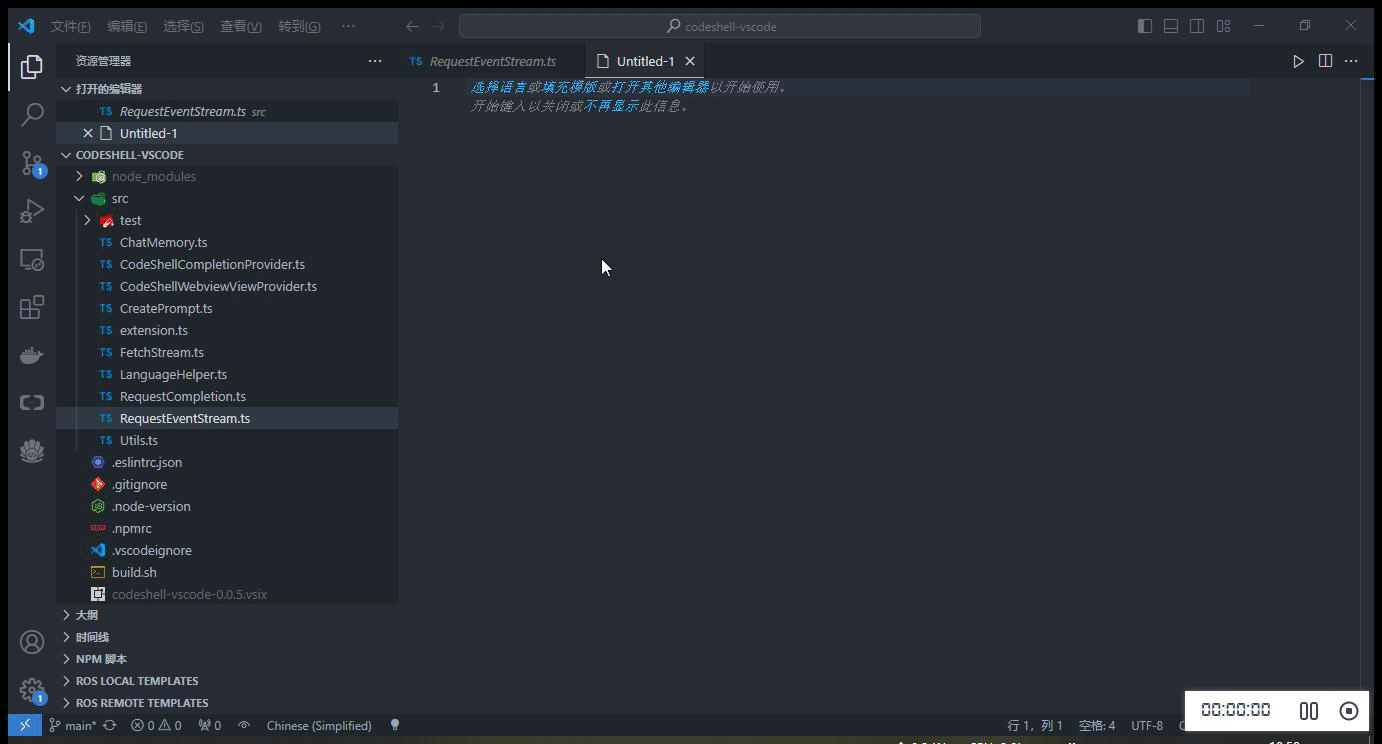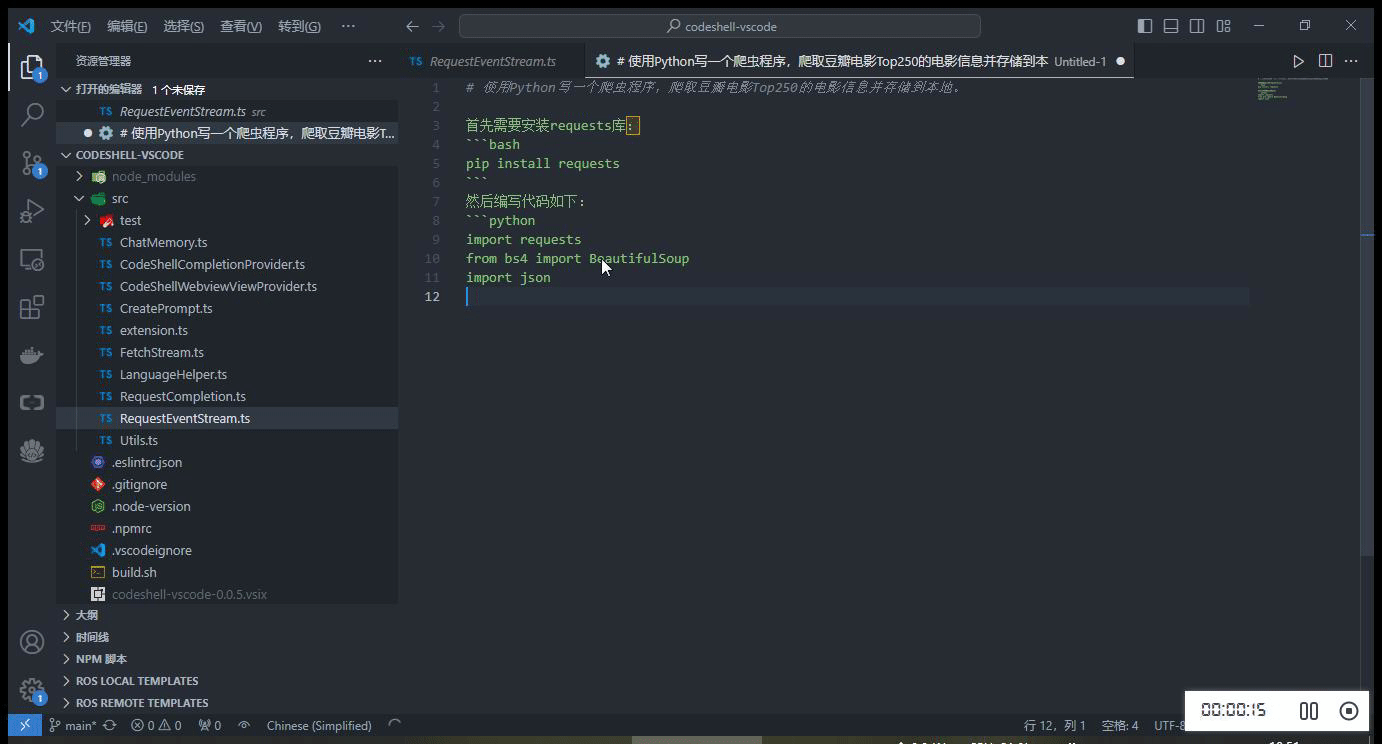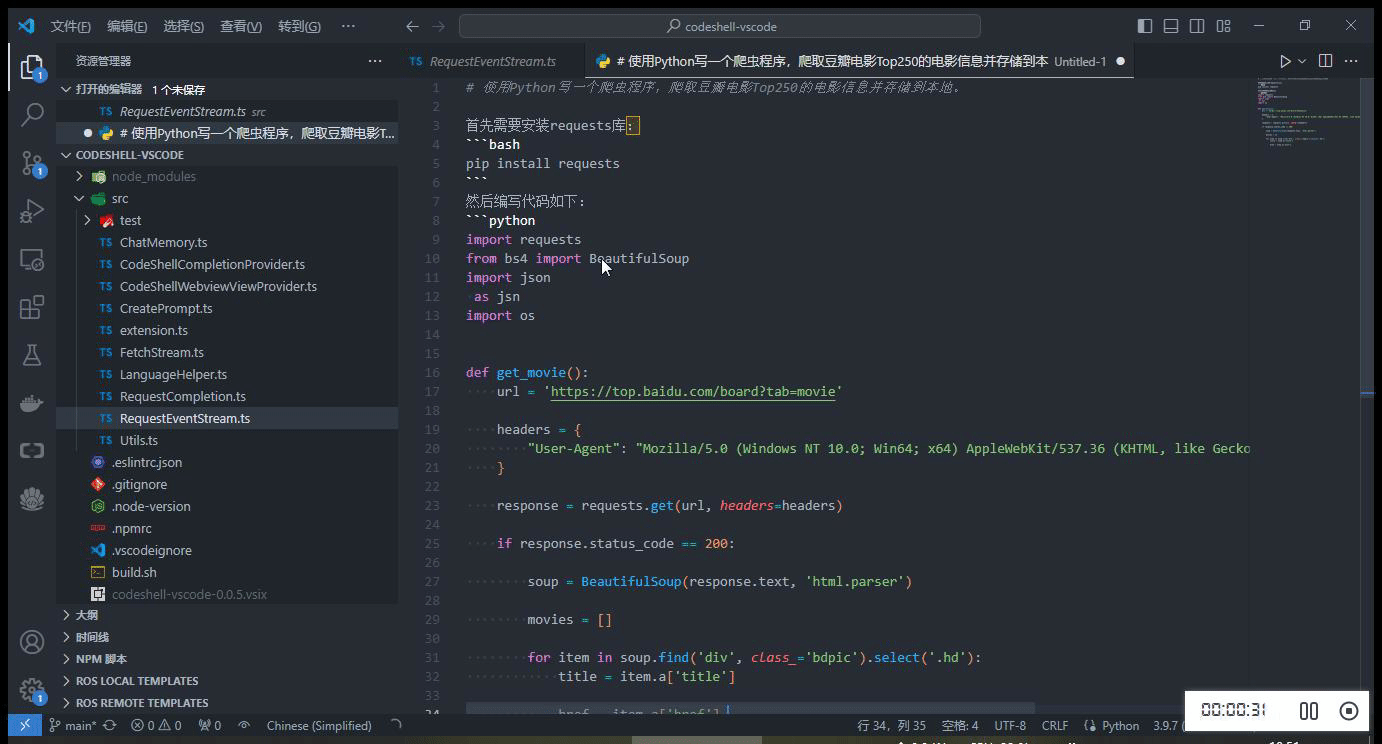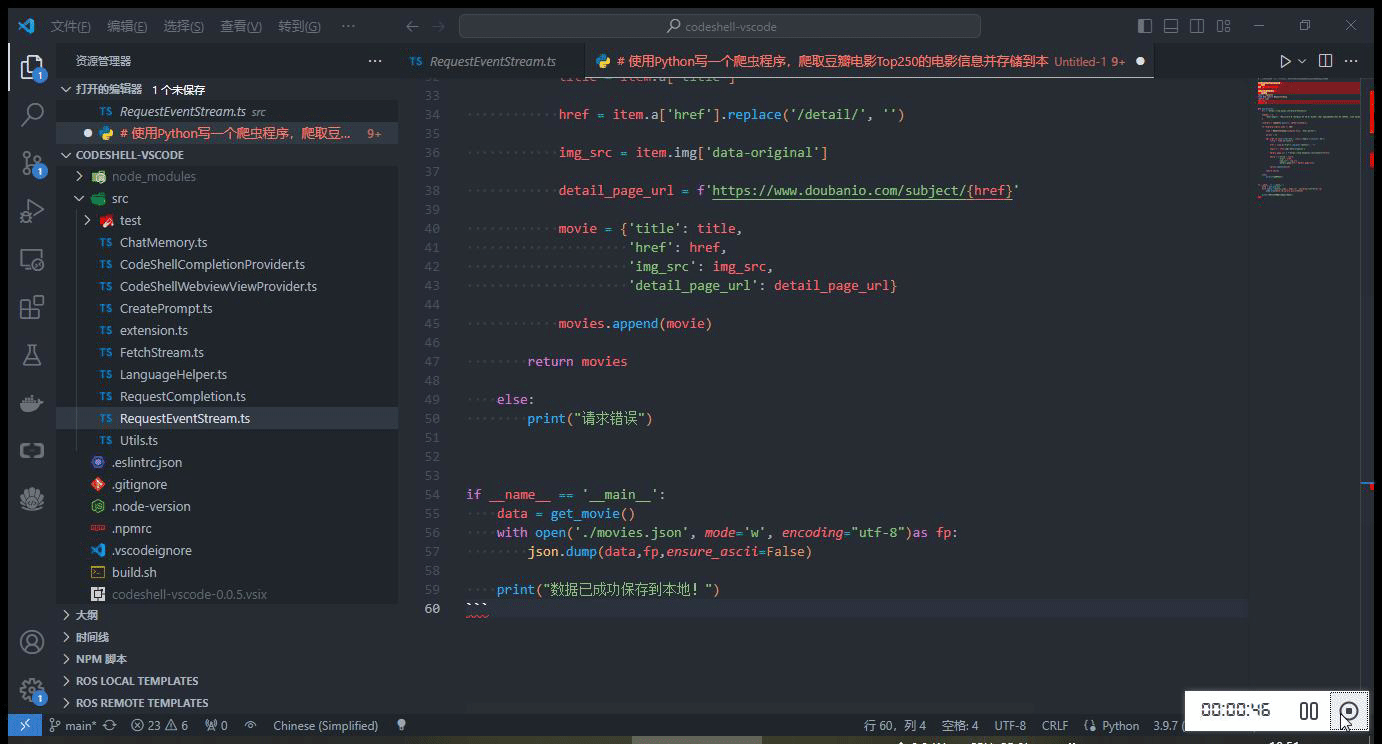
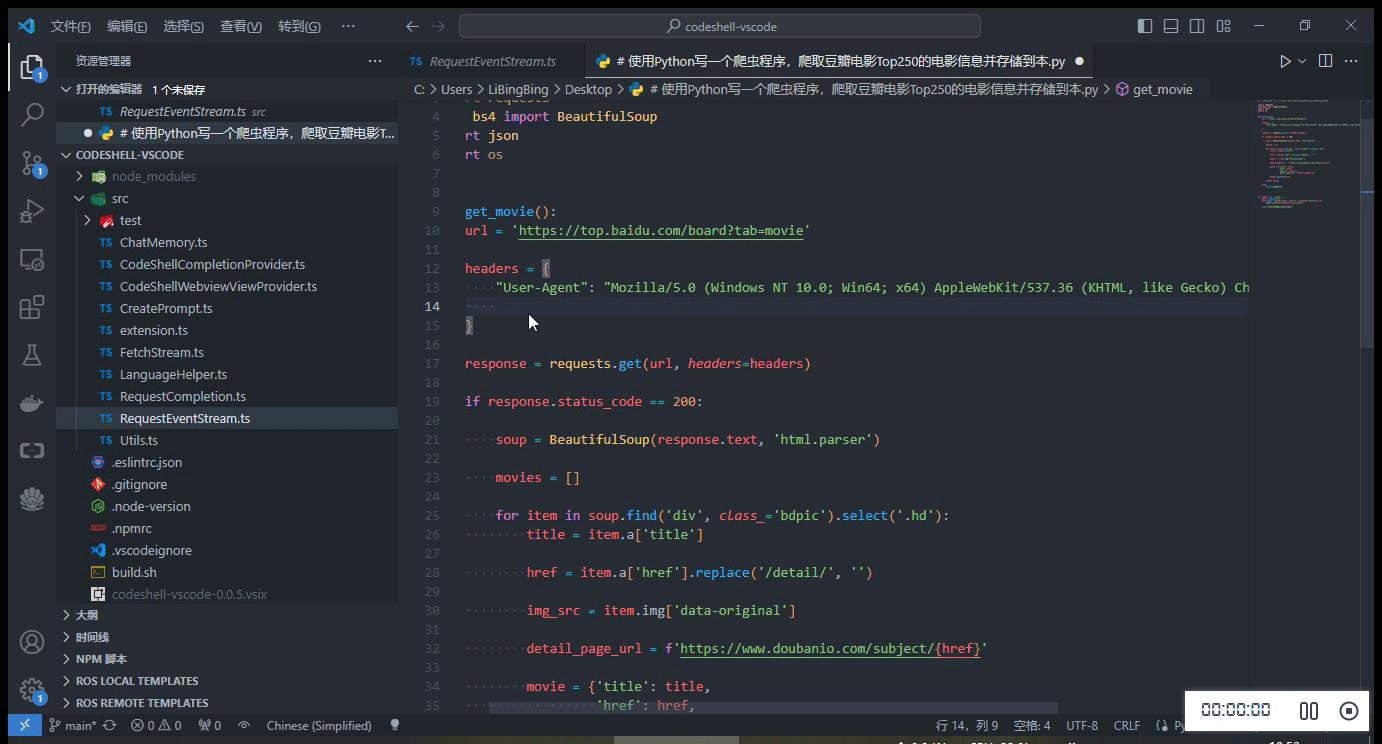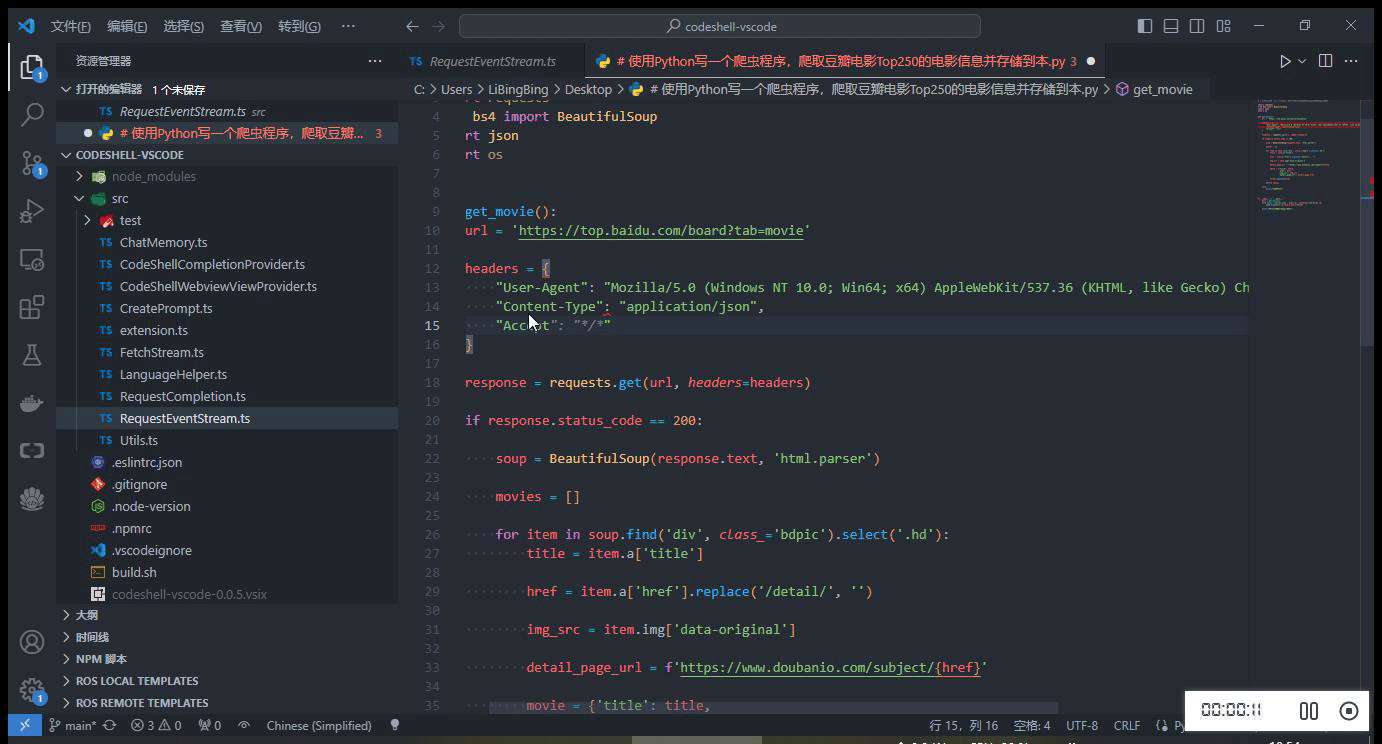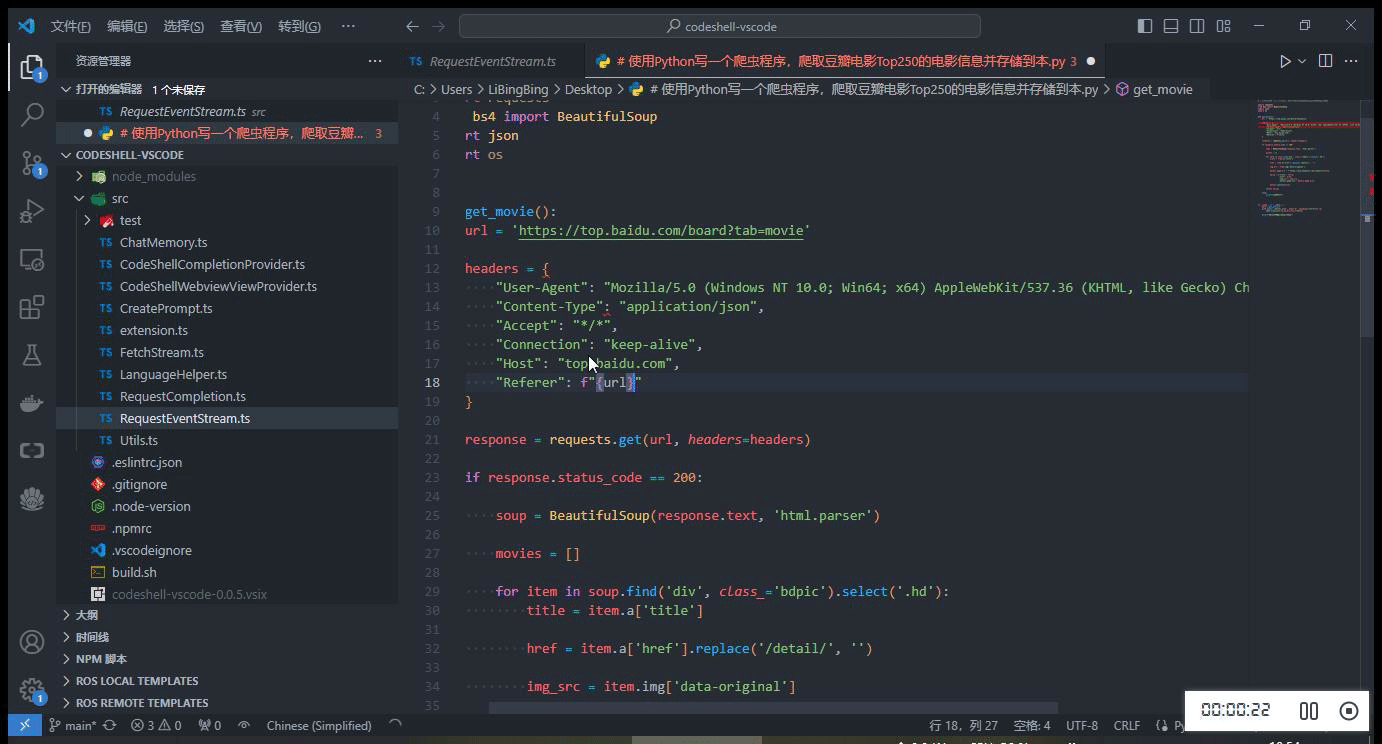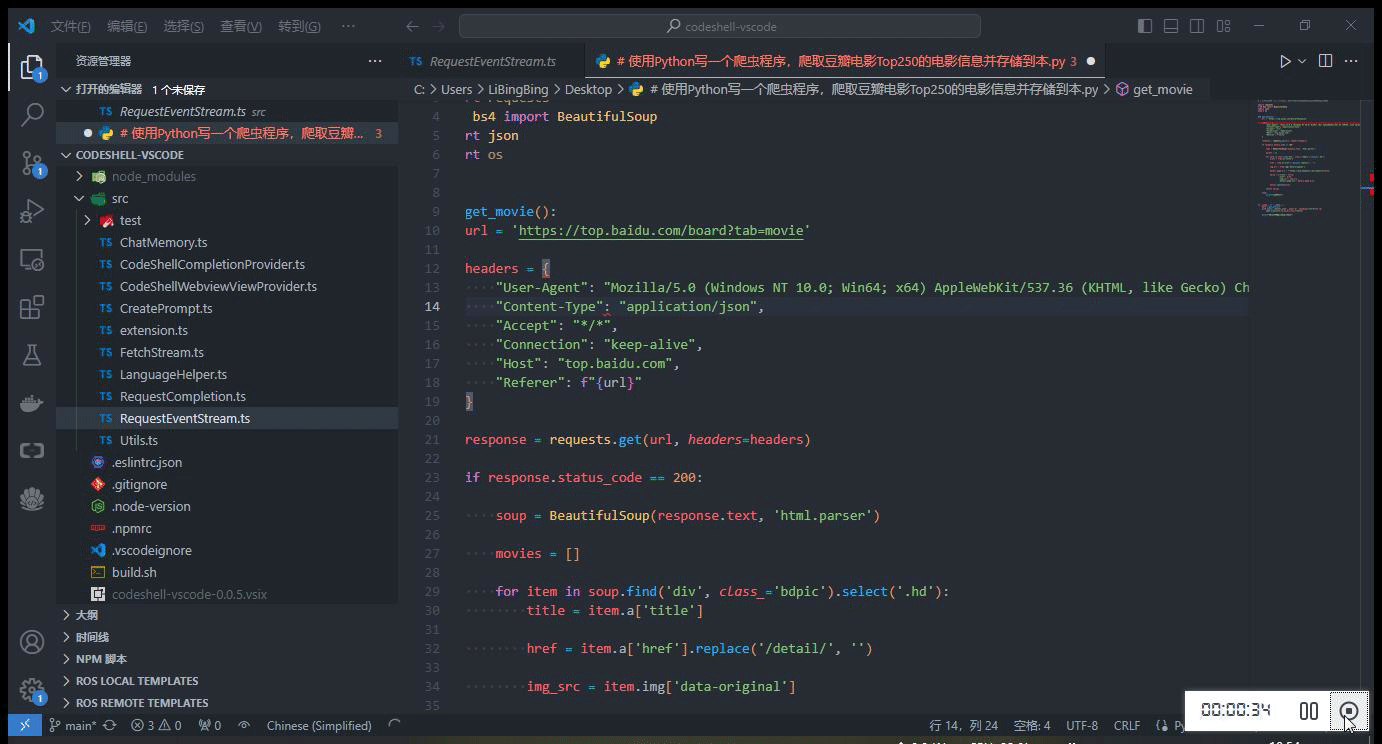
- 自动触发代码建议
- 热键触发代码建议
在编码过程中,当停止输入时,代码补全建议可自动触发(在配置选项
Auto Completion Delay中可设置为 1~3 秒),或者也可以主动触发代码补全建议,使用快捷键Alt+\(对于Windows电脑)或option+\(对于Mac电脑)。当插件提供代码建议时,建议内容以灰色显示在编辑器光标位置,可以按下 Tab 键来接受该建议,或者继续输入以忽略该建议。
-
简单模拟并发请求,同时使用 Chat 问答模式及代码补全模式
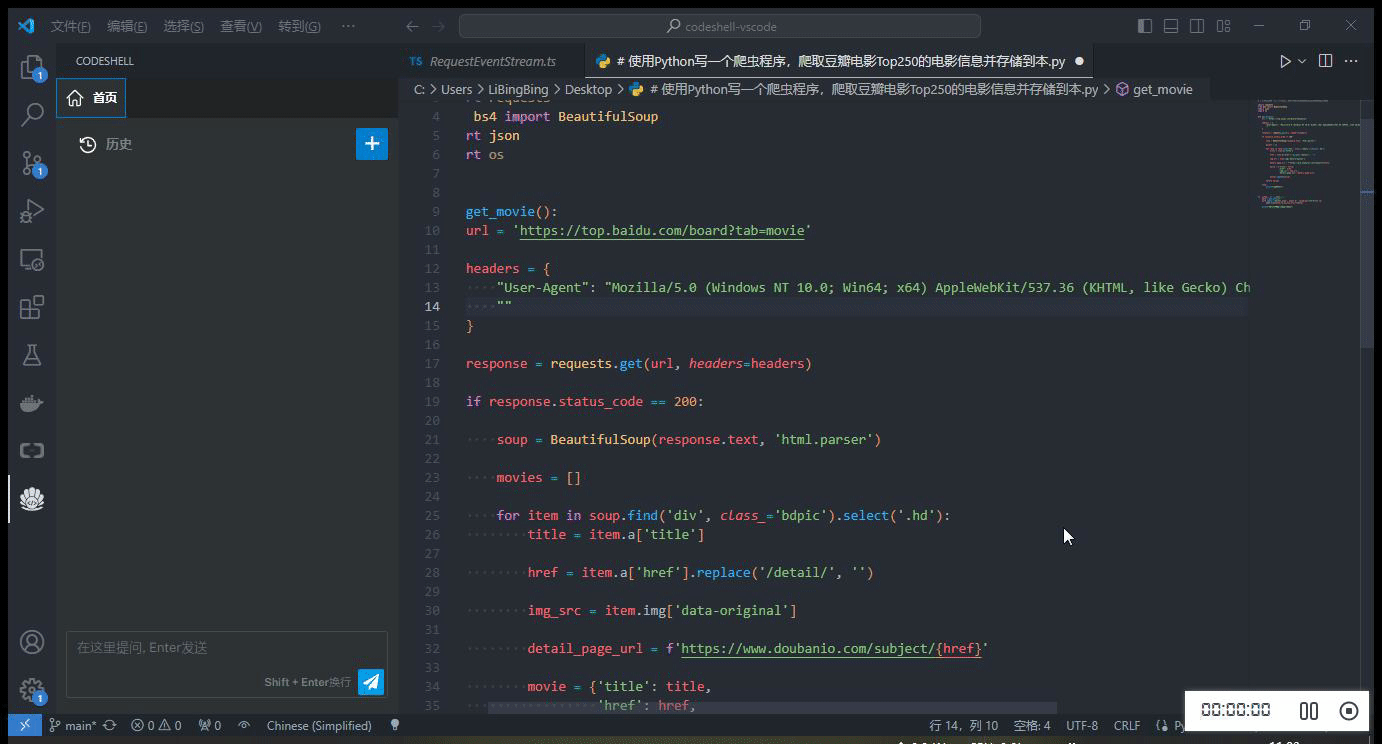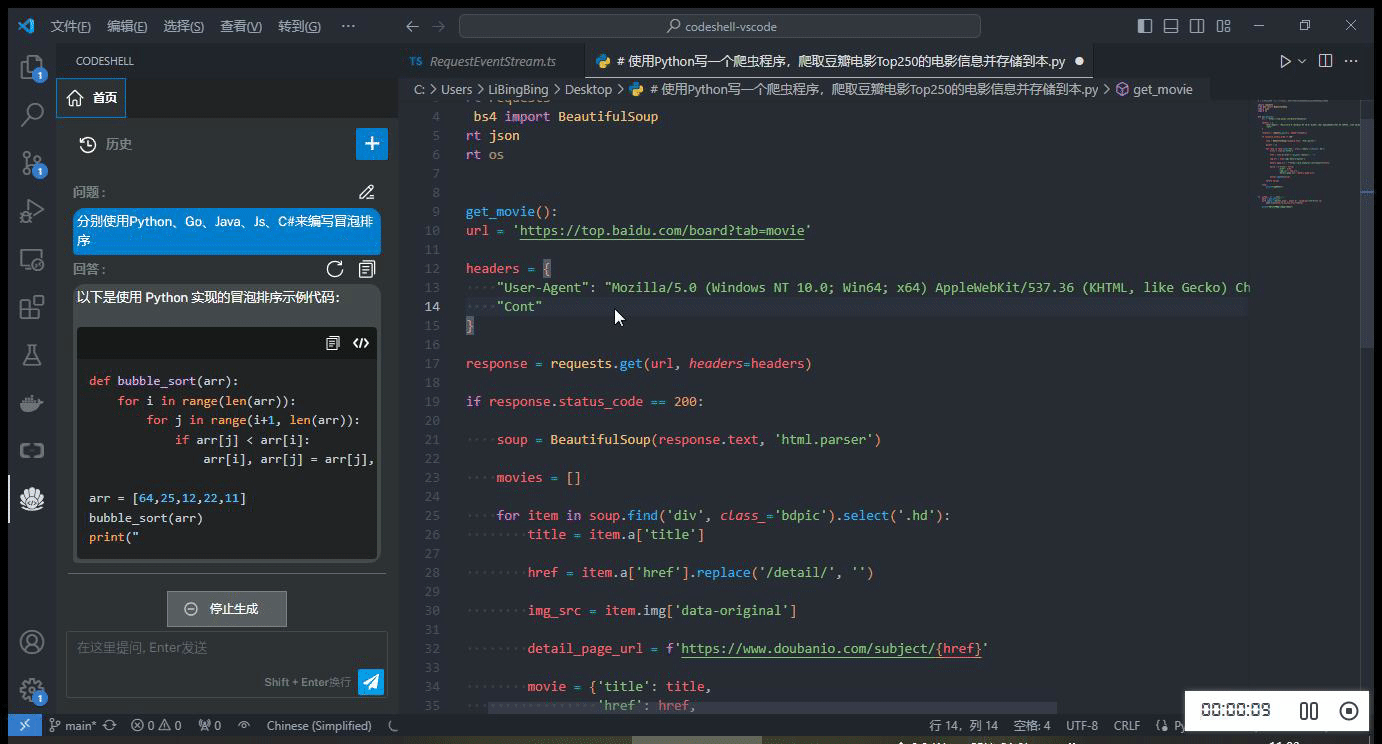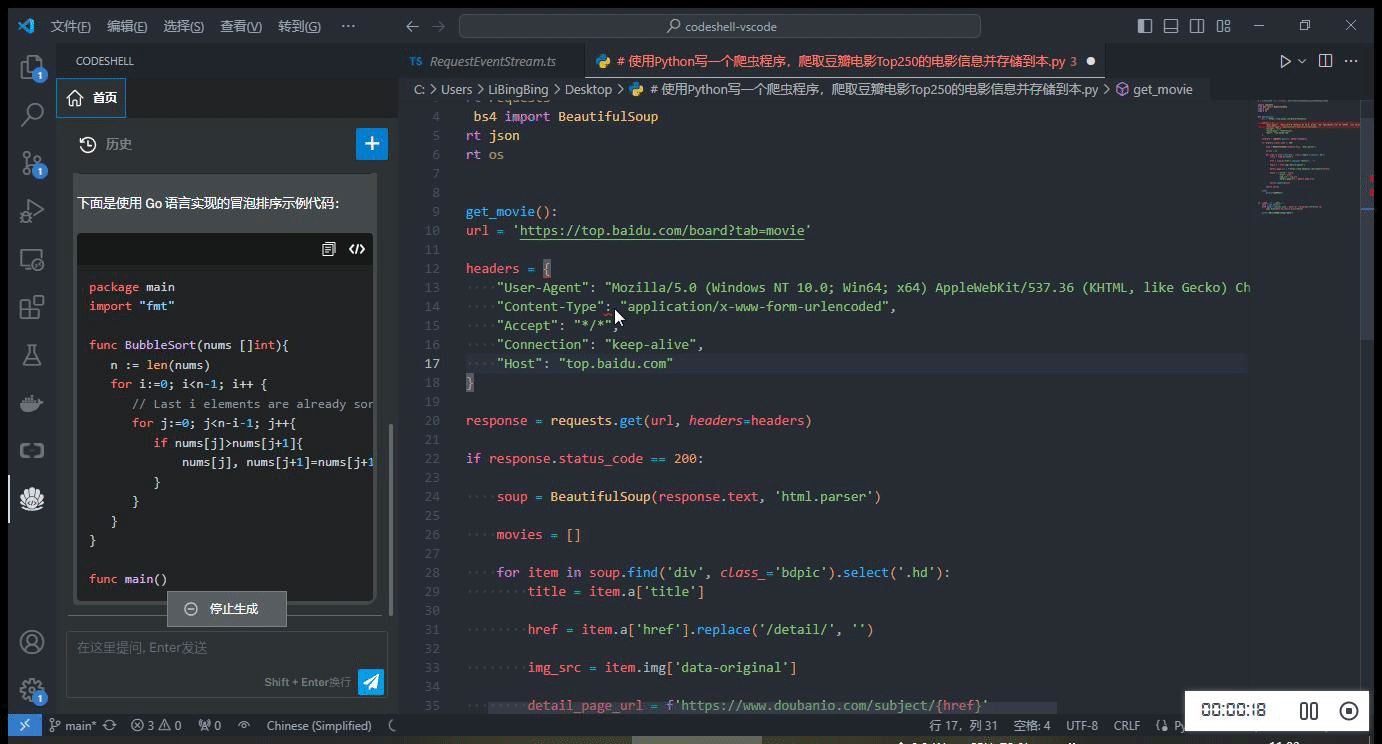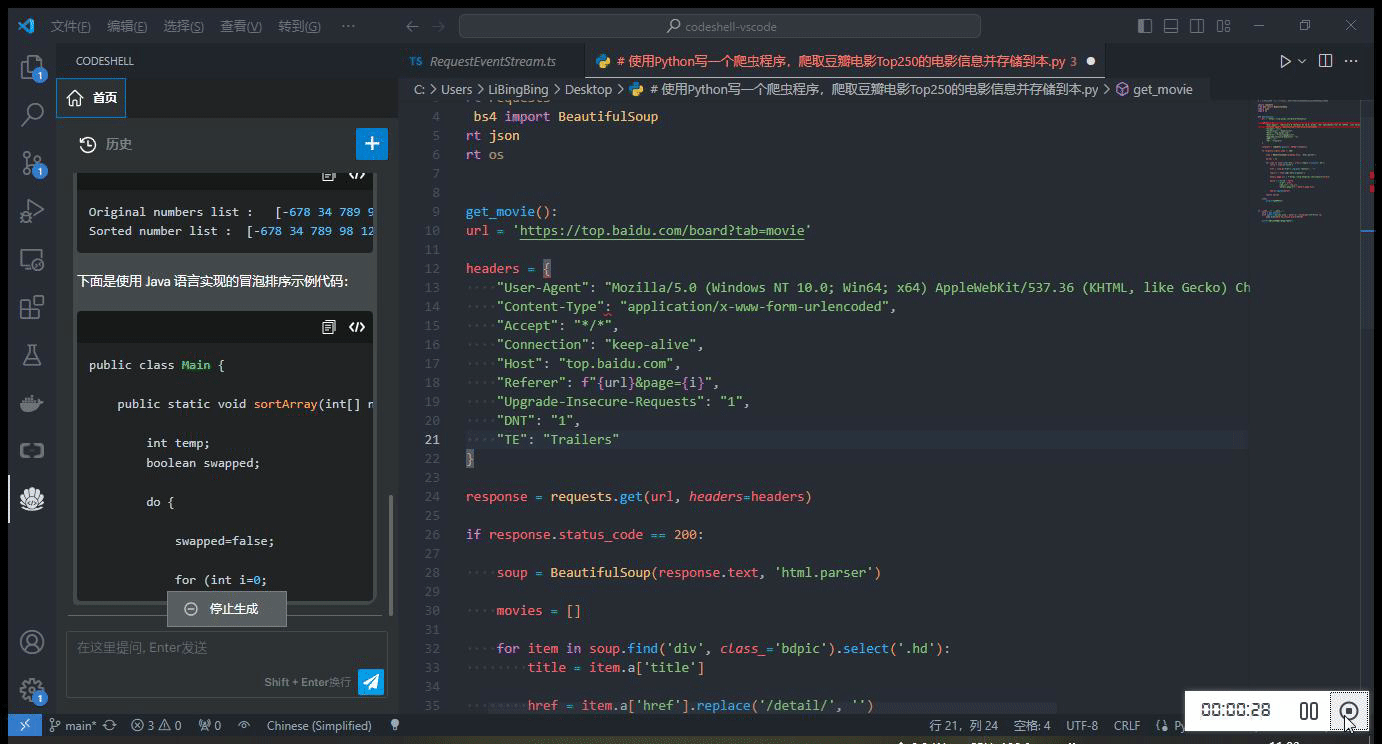
四、HAI 中 TGI 服务基准测试
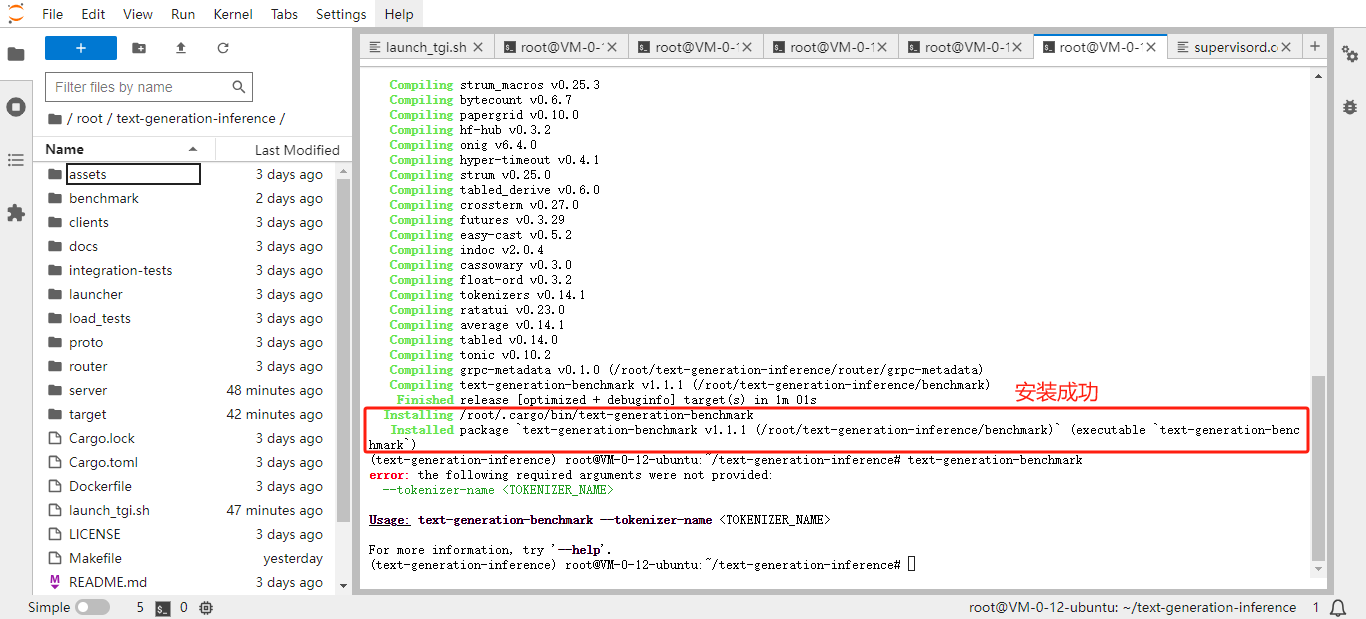
4.1 安装 text-generation-benchmark
# 安装benchmark
conda activate text-generation-inference
cd /root/text-generation-inference
make install-benchmark
4.2 运行 text-generation-benchmark
# 先启动TGI服务
conda activate text-generation-inference
cd /root/text-generation-inference
make run-codeshell# 等待TGI服务启动成功后,开启一个新的终端窗口,执行text-generation-benchmark
conda activate text-generation-inference
cd /root/text-generation-inference
text-generation-benchmark --tokenizer-name /root/CodeShell-7B-Chat
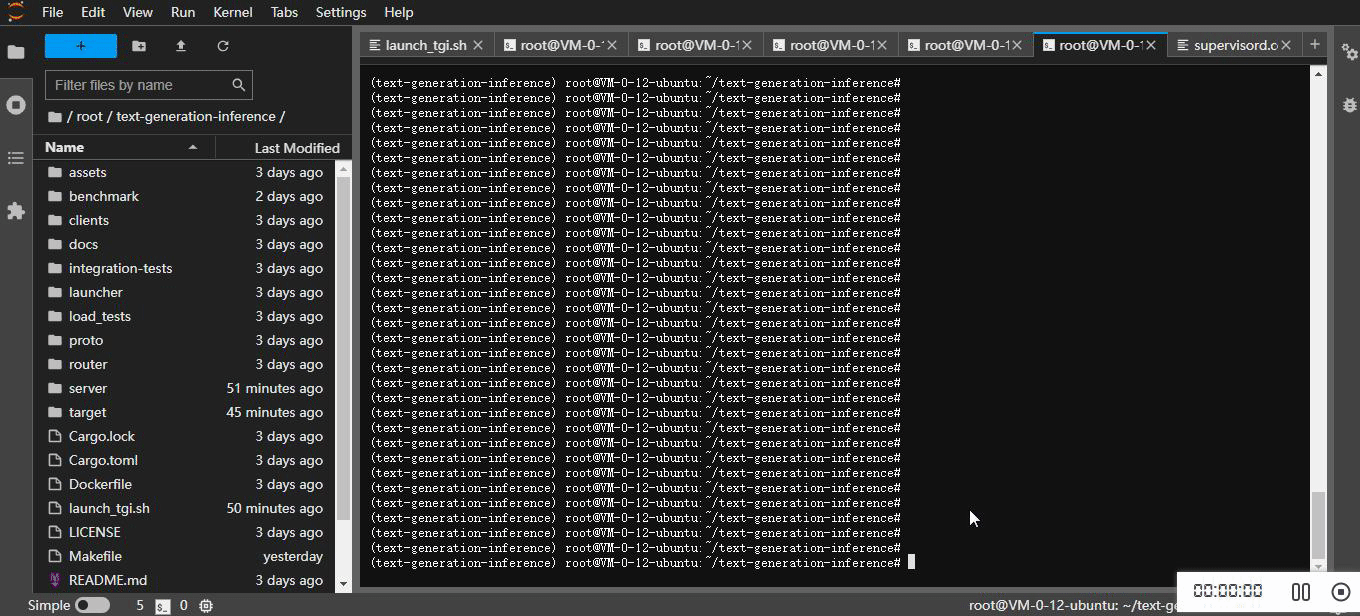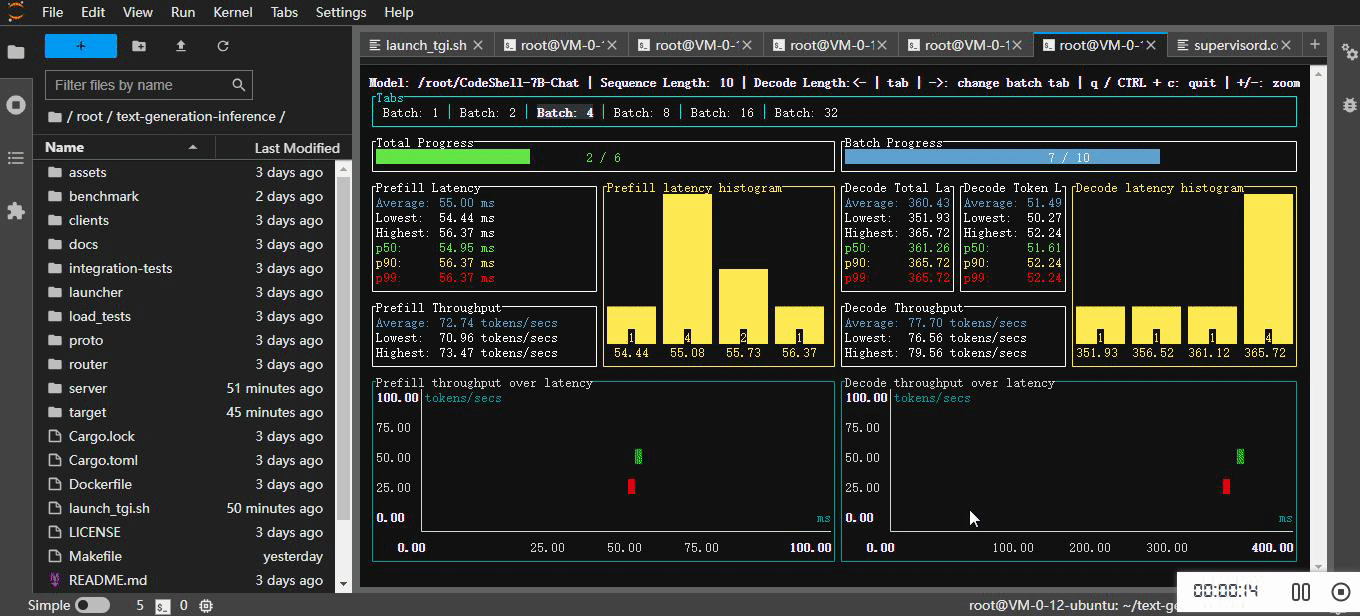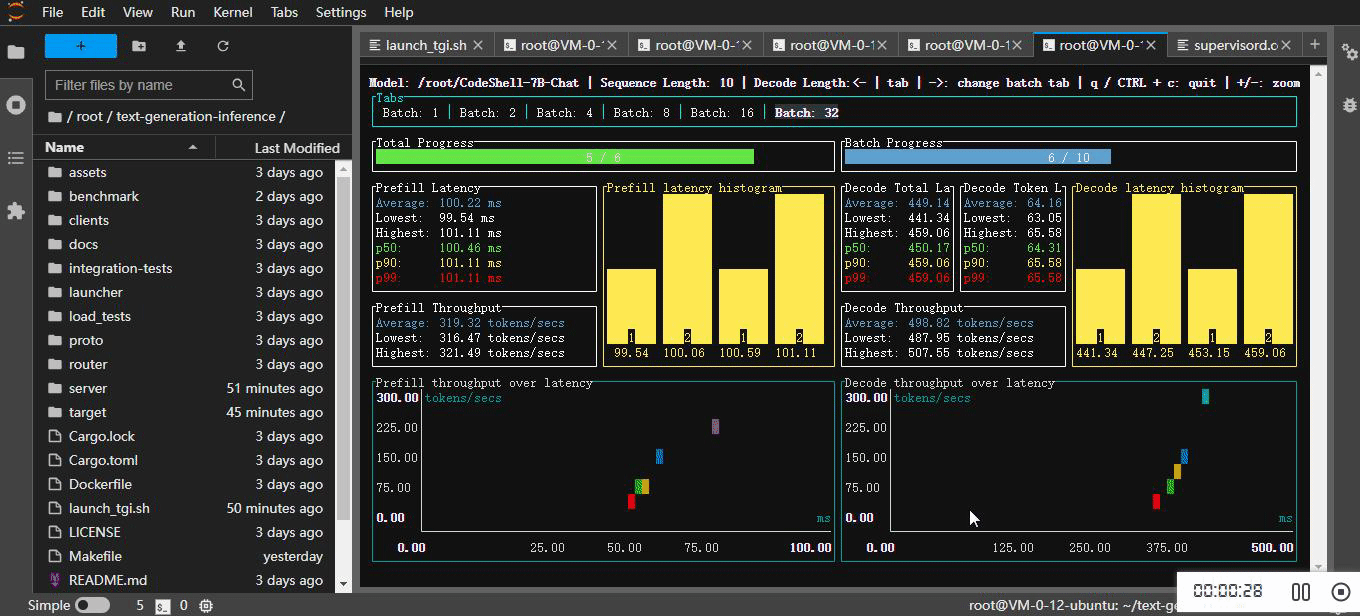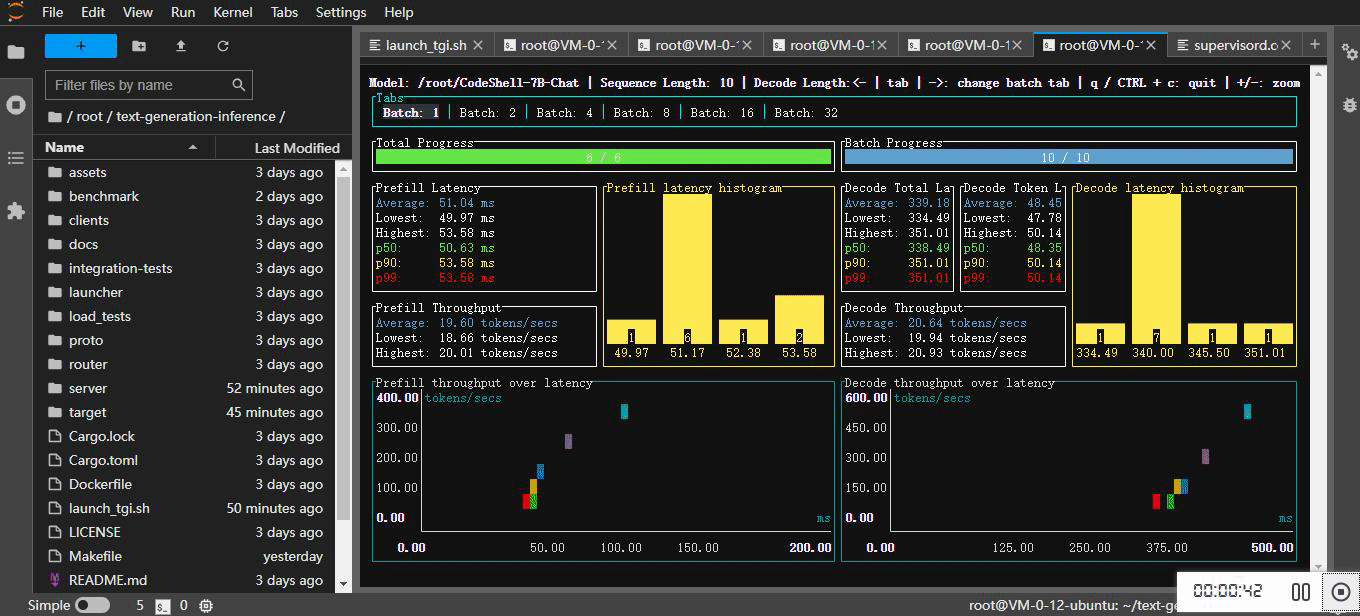
4.3 查看基准测试报告
2023-12-07T04:58:06.759860Z INFO text_generation_benchmark: benchmark/src/main.rs:155: Tokenizer loaded
2023-12-07T04:58:06.765350Z INFO text_generation_benchmark: benchmark/src/main.rs:164: Connect to model server
2023-12-07T04:58:06.777364Z INFO text_generation_benchmark: benchmark/src/main.rs:173: Connected| Parameter | Value |
|--------------------|-------------------------|
| Model | /root/CodeShell-7B-Chat |
| Sequence Length | 10 |
| Decode Length | 8 |
| Top N Tokens | None |
| N Runs | 10 |
| Warmups | 1 |
| Temperature | None |
| Top K | None |
| Top P | None |
| Typical P | None |
| Repetition Penalty | None |
| Watermark | false |
| Do Sample | false || Step | Batch Size | Average | Lowest | Highest | p50 | p90 | p99 |
|----------------|------------|-----------|-----------|-----------|-----------|-----------|-----------|
| Prefill | 1 | 50.06 ms | 49.33 ms | 50.72 ms | 50.00 ms | 50.72 ms | 50.72 ms |
| | 2 | 52.11 ms | 51.50 ms | 53.28 ms | 52.20 ms | 53.28 ms | 53.28 ms |
| | 4 | 57.67 ms | 56.70 ms | 59.75 ms | 57.73 ms | 59.75 ms | 59.75 ms |
| | 8 | 59.05 ms | 58.87 ms | 59.40 ms | 59.03 ms | 59.40 ms | 59.40 ms |
| | 16 | 73.30 ms | 72.77 ms | 74.18 ms | 73.19 ms | 74.18 ms | 74.18 ms |
| | 32 | 100.92 ms | 99.99 ms | 102.04 ms | 101.01 ms | 102.04 ms | 102.04 ms |
| Decode (token) | 1 | 48.03 ms | 47.51 ms | 49.00 ms | 47.89 ms | 49.00 ms | 49.00 ms |
| | 2 | 50.38 ms | 49.39 ms | 51.78 ms | 50.09 ms | 51.78 ms | 51.78 ms |
| | 4 | 52.48 ms | 50.55 ms | 55.98 ms | 51.58 ms | 55.98 ms | 55.98 ms |
| | 8 | 53.65 ms | 52.57 ms | 54.68 ms | 53.80 ms | 54.68 ms | 54.68 ms |
| | 16 | 56.76 ms | 55.24 ms | 60.45 ms | 56.26 ms | 60.45 ms | 60.45 ms |
| | 32 | 63.68 ms | 62.53 ms | 69.83 ms | 62.97 ms | 69.83 ms | 69.83 ms |
| Decode (total) | 1 | 336.21 ms | 332.56 ms | 343.00 ms | 335.25 ms | 343.00 ms | 343.00 ms |
| | 2 | 352.69 ms | 345.74 ms | 362.47 ms | 350.65 ms | 362.47 ms | 362.47 ms |
| | 4 | 367.36 ms | 353.89 ms | 391.88 ms | 361.07 ms | 391.88 ms | 391.88 ms |
| | 8 | 375.55 ms | 368.02 ms | 382.76 ms | 376.57 ms | 382.76 ms | 382.76 ms |
| | 16 | 397.31 ms | 386.70 ms | 423.16 ms | 393.80 ms | 423.16 ms | 423.16 ms |
| | 32 | 445.75 ms | 437.69 ms | 488.82 ms | 440.78 ms | 488.82 ms | 488.82 ms || Step | Batch Size | Average | Lowest | Highest |
|---------|------------|--------------------|--------------------|--------------------|
| Prefill | 1 | 19.98 tokens/secs | 19.72 tokens/secs | 20.27 tokens/secs |
| | 2 | 38.39 tokens/secs | 37.54 tokens/secs | 38.83 tokens/secs |
| | 4 | 69.37 tokens/secs | 66.95 tokens/secs | 70.54 tokens/secs |
| | 8 | 135.49 tokens/secs | 134.69 tokens/secs | 135.89 tokens/secs |
| | 16 | 218.27 tokens/secs | 215.70 tokens/secs | 219.87 tokens/secs |
| | 32 | 317.10 tokens/secs | 313.61 tokens/secs | 320.03 tokens/secs |
| Decode | 1 | 20.82 tokens/secs | 20.41 tokens/secs | 21.05 tokens/secs |
| | 2 | 39.70 tokens/secs | 38.62 tokens/secs | 40.49 tokens/secs |
| | 4 | 76.32 tokens/secs | 71.45 tokens/secs | 79.12 tokens/secs |
| | 8 | 149.14 tokens/secs | 146.30 tokens/secs | 152.17 tokens/secs |
| | 16 | 282.12 tokens/secs | 264.67 tokens/secs | 289.63 tokens/secs |
| | 32 | 503.03 tokens/secs | 458.25 tokens/secs | 511.78 tokens/secs |
五、生产场景优化建议
5.1 基于自有代码集微调
希望在特定领域任务中应用 CodeShell 模型的用户可以参照 CodeShell 提供的 官方微调示例,在 HAI 上进行模型微调。由于博主暂时没有微调的需求,因此这一章节就不展开细说了。
5.2 TGI 服务访问安全优化
在前文的 3.5 章节,为了测试及演示方便,我们直接将 TGI 服务向公网开放,并通过 HTTP 协议访问 TGI 服务。这个操作会使得 TGI 服务面临一些安全风险,包括但不限于中间人攻击、恶意请求等,因此只适用于短时间的测试及演示场景。生产场景下,建议根据实际情况不同采用不同方案进行安全限制。此处简单列举三个方案以供参考,如果各位小伙伴有更好的方案可以评论区留言交流:
-
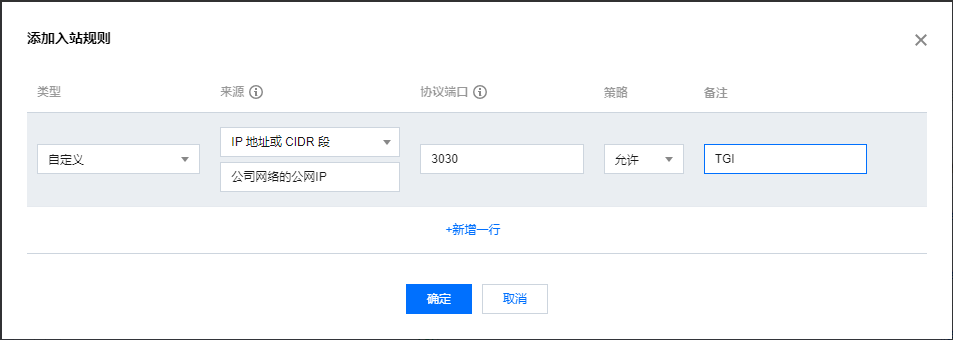
方案一:限制源 IP;成本最低、安全性最差
配置 HAI 安全组规则时,来源 IP 填写公司网络的公网 IP。这样只有公网网络可以连接 TGI 服务。此方案无法解决 HTTP 协议访问带来的诸如中间人攻击等安全问题。
-
方案二:限制源 IP+Nginx 反代;成本中等、安全性一般
TGI 服务不直接向公网环境提供服务,而是使用 Nginx 等反向代理服务器作为其公网服务出口,基于 Nginx 可以配置 SSL 证书使用 HTTPS 协议访问服务,还可以结合方案一,对 Nginx 服务进行来源 IP 限制。需要注意的是 TGI 服务通过 SSE(Server-Sent Events,一种基于 HTTP 的服务器推送技术,它允许服务器将实时数据流式传输到客户端)传输数据,因此 Nginx 反向代理配置中需要额外关注一些参数,具体细节可以参考 使用 Nginx 配置反向代理处理 SSE 请求。
-
方案三:限制源 IP+Nginx 反代+代理层鉴权;成本较高、安全性最好
在方案二的基础上,在代理层增加鉴权认证,此方案需要修改 CodeShell 插件配合实现,动手能力强的读者可以尝试一下。CodeShell 插件开源地址:VsCode 插件、Jetbrains 插件。
5.3 HAI 成本优化
由于 AI 编程助手只会在工作时间使用,因此我们希望在非工作时间关闭 HAI 实例以节约成本,也就是实现 定时开关机功能。但由于 HAI 目前暂未开放 开关机 相关的 API,同时进阶型算力比较紧俏,很容易出现关机后资源售罄无法开机的情况,再加上 HAI 每次开关机都会重新分配公网 IP 等因素,此项优化只能暂时搁置。期待 HAI 后续的迭代更新可以支持自动开关机相关的功能。
5.4 HAI 开机自动启动 TGI 服务
虽然定时开关机功能暂时无法实现,但不妨碍我们先为 HAI 加上 开机自动启动TGI服务 功能。
Supervisor 是用 Python 开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台 daemon,并监控进程状态,异常退出时能自动重启。HAI 实例内预置了 Supervisor 来作为 jupyerlab 及其他 webui 的进程守护工具。
-
编写 TGI 启动脚本:在
/root/text-generation-inference目录下创建文件launch_tgi.sh,复制粘贴以下内容:#!/bin/bash source $HOME/miniconda3/etc/profile.d/conda.sh conda activate text-generation-inference export PATH="$HOME/.cargo/bin:$PATH" /root/.cargo/bin/text-generation-launcher --model-id /root/CodeShell-7B-Chat --port 3030 --num-shard 1 --max-total-tokens 5000 --max-input-length 4096 --max-stop-sequences 12 --trust-remote-code 2>&1 | tee -a /var/log/tgi_service.log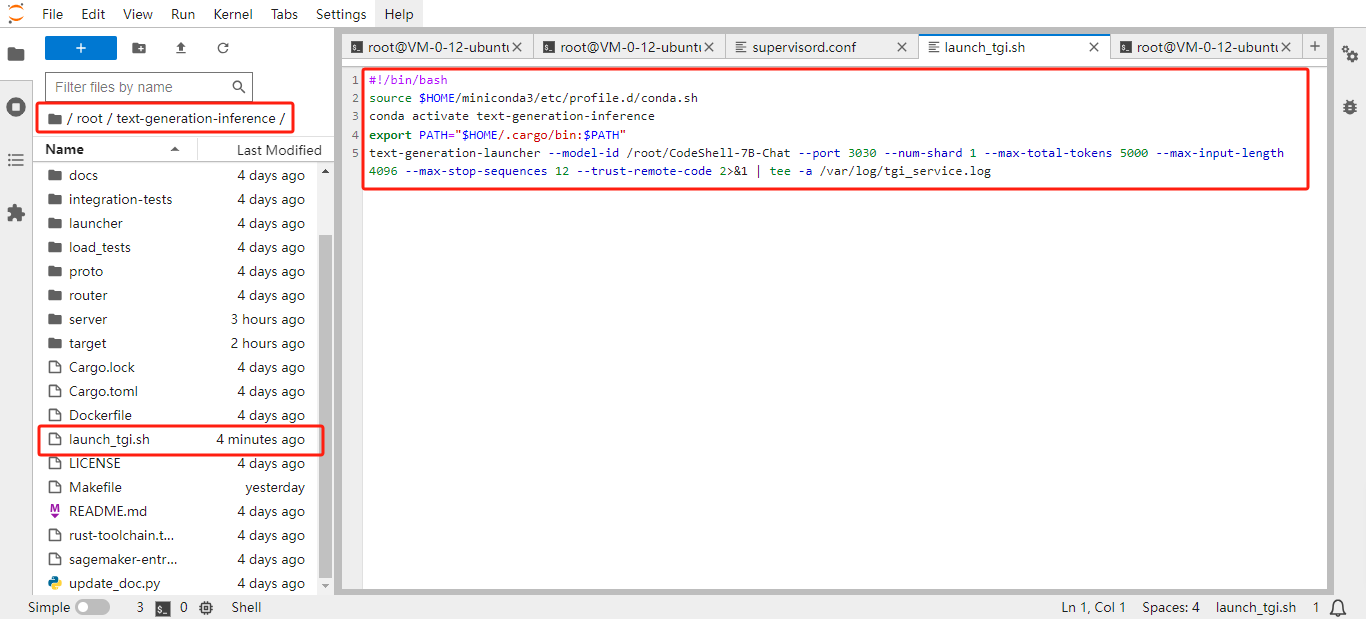
-
向
launch_tgi.sh赋予执行权限:chmod +x /root/text-generation-inference/launch_tgi.sh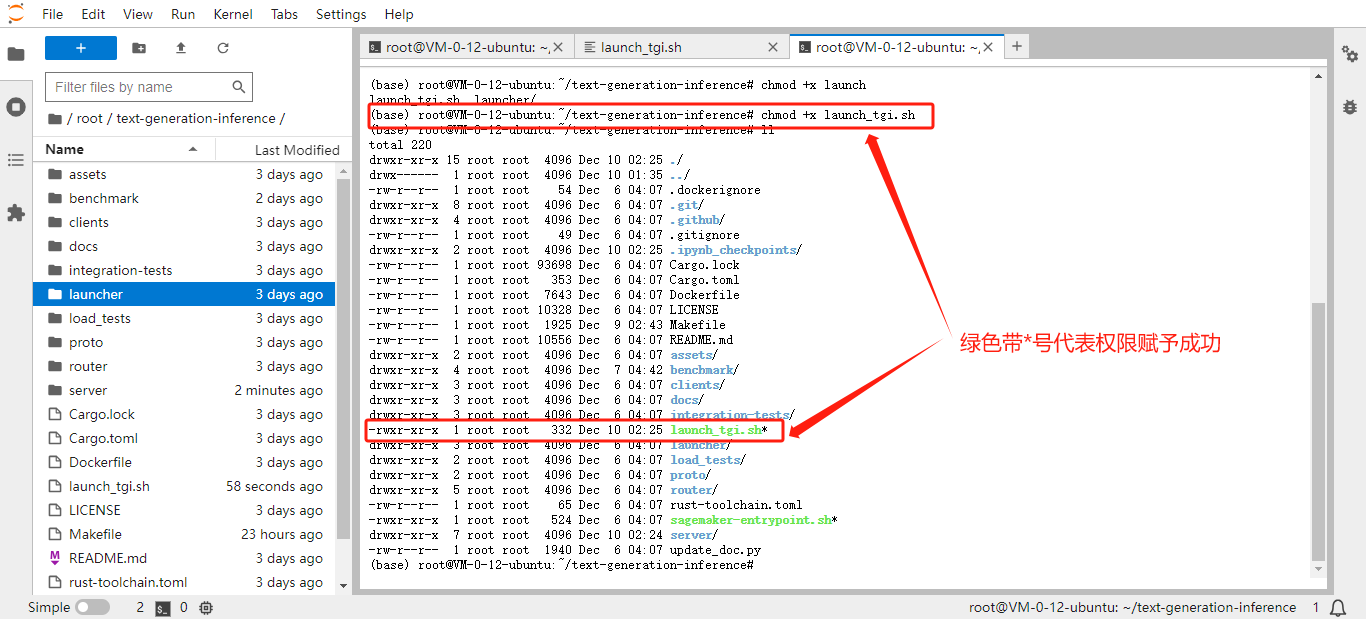
-
配置 Supervisor:打开
/etc/目录下的supervisord.conf文件,在文件中追加以下内容:[program:text-generation-inference] command=/root/text-generation-inference/launch_tgi.sh autostart=true autorestart=true numprocs=1 redirect_stderr=true startretries=10 startsecs=60 stdout_logfile=/dev/stdout stdout_logfile_maxbytes=0 stdout_events_enabled=true stderr_events_enabled=true stopasgroup=true killasgroup=true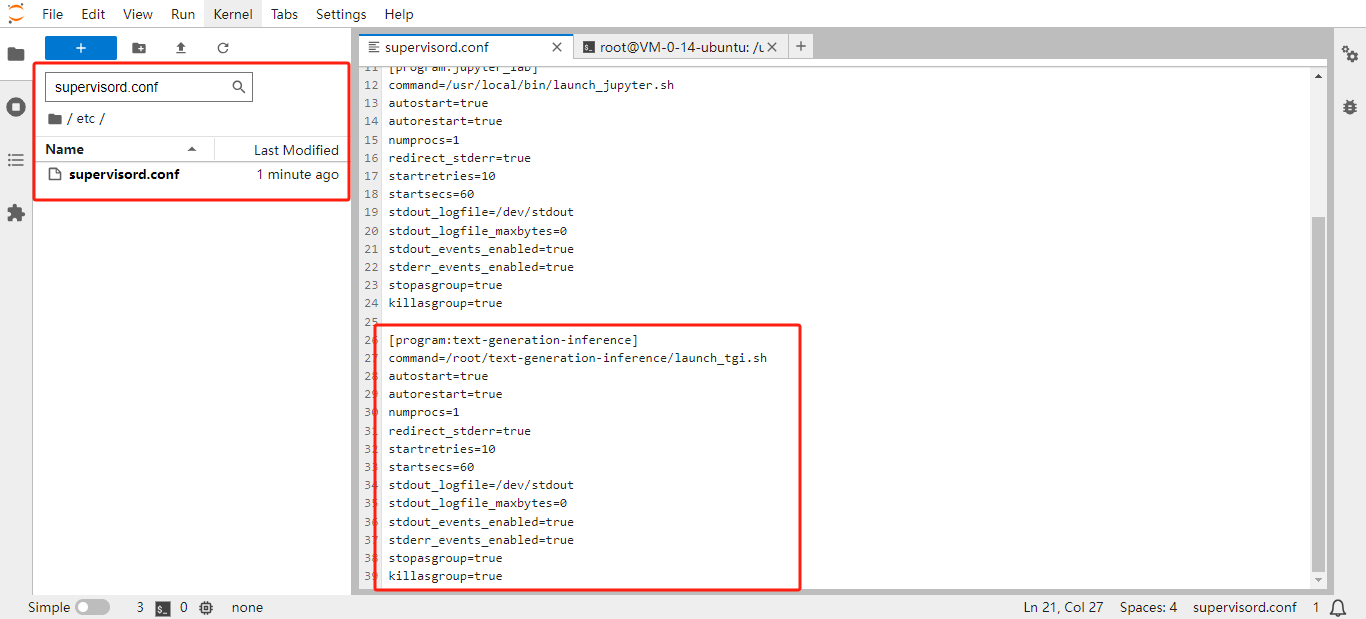
-
HAI 开机后,可以查看
/var/log/tgi_service.log确认是否已经自动启动 TGI 服务tail -f /var/log/tgi_service.log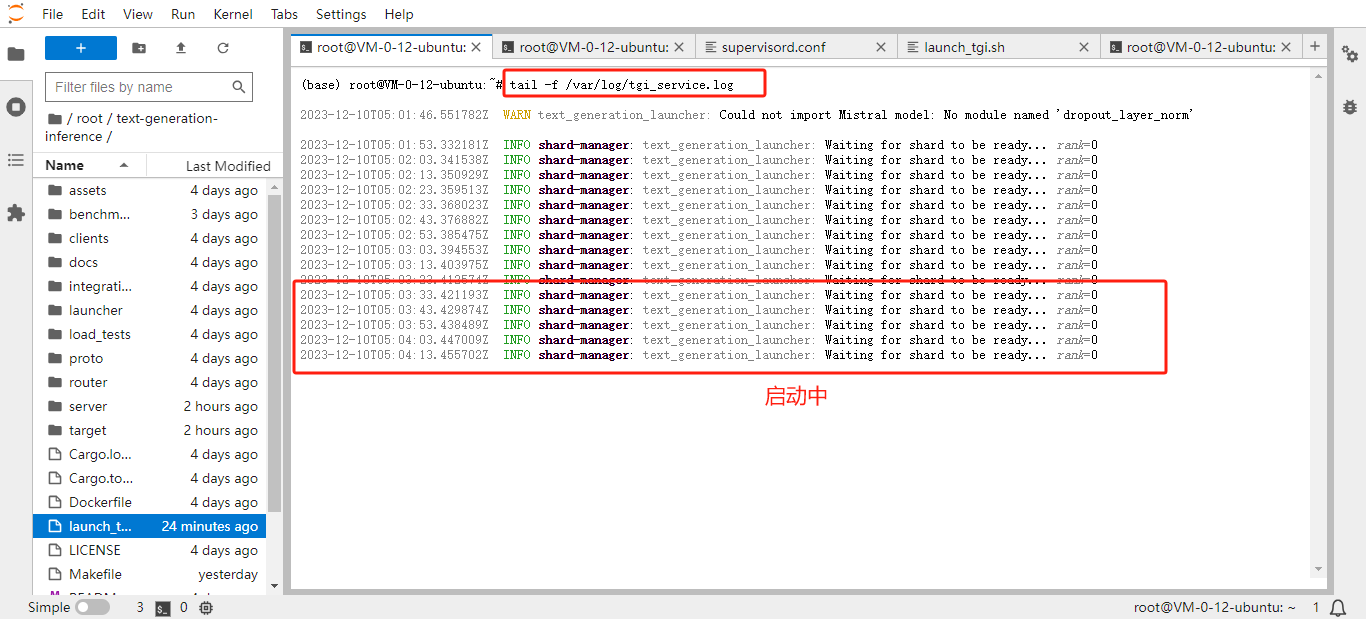
六、总结&建议
在如今整个 AI 浪潮席卷全球,AI 领域发展“日新周异”的背景下,HAI 的推出,打通了 AI 到普通用户的”最后一公里“,大大降低了中小企业和开发者 AI 实践的门槛,为广大用户走进 AIGC、AGI 提供了坚实的基石。在使用HAI的过程中,个人最大的感受就是清爽,不需要去纠结GPU型号,也不需要再去配置复杂的基础环境,只需要关注应用层即可,大大提高了生产效率。
HAI 这款产品真正做到了如腾讯云品牌视频中描述的那样:科技就像长城上的砖、埃菲尔铁塔上的螺丝,你不必知道他的复杂,你只需要拿来即用,简单易用、即插即用,这才是科技该有的样子。我们将最前沿的科技打磨成简单的样子,用极致算力,集成最优化组合,让需求一目了然、让问题直面解决方案。化繁为简,以小建大。
HAI 在本文发布之时(2023 年 12 月上旬)仍处于内测阶段,结合在部署 CodeShell 大模型过程中遇到的一些问题,在这里也向 HAI 提出一些产品建议:
- 用户成本优化:希望可以支持定时开关机功能或开放开关机 API 供用户自行实现;
- 实例带宽:希望可以像硬盘一样,提供更高的可选的带宽规格,或提供挂载 COS 等功能,使用户可以快捷方便的获取模型文件;
- 预置环境的软件版本:希望预置环境的软件版本可在购买时选配预装版本或便捷的升降级,以此来为更多应用场景提供即开即用的服务实例;
- 磁盘动态扩容:磁盘容量希望在购买后可以动态扩容,避免出现中途磁盘空间不足又无法扩容的问题;
期待 HAI 能够早日正式发布,引领中小企业和开发者迈向普惠 AI 时代。
这篇关于【腾讯云 HAI域探秘】释放生产力:基于 HAI 打造团队专属的 AI 编程助手的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








