本文主要是介绍bic谈话_让谈话强化学习基础知识第二部分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
bic谈话
This is a continuation of the article Let’s talk Reinforcement Learning — The Fundamentals — Part 1. You can continue reading this article even if you have not read Part 1 if you can recognize the terms below.
这是文章“继续学习强化学习-基础知识-第1部分”的延续。即使您没有阅读第1部分,也可以继续阅读本文,前提是您可以理解以下术语。
See if you can recognize these terms: action, value, reward, k-bandit problem, exploitation vs exploration tradeoff, action selection, epsilon-greedy, upper-confidence bound. If you know at least 5 of these terms, you are good to go. If you are not sure don't worry you can always read Let’s talk Reinforcement Learning — The Fundamentals — Part 1 and come back.
看看您是否可以识别以下术语:动作,价值,报酬,k-bandit问题,开发与探索权衡,动作选择,ε贪婪,置信度上限。 如果您至少知道这些术语中的5个,那就很好了。 如果您不确定不要担心,可以随时阅读“ 增强学习-基础知识-第1部分”, 然后再回来。
In part 1 we saw basic things like rewards and estimating the action values. The K-armed bandit problem(humanoid doctor) gave us an intuition of what reinforcement learning is, but it is not enough to tackle real-world problems. Let us get rid of the humanoid doctor and introduce a new example: The story of a deer.
在第1部分中,我们看到了诸如奖励和估算行动价值之类的基本事物。 K武装匪徒问题(类人动物医生)使我们对强化学习是一种直觉,但不足以解决现实世界中的问题。 让我们摆脱类人动物医生,并介绍一个新的例子: 鹿的故事 。
Fun Fact: Deer adore fruits and nuts. They love pecans, hickory nuts, and beechnuts acorns in addition to acorns. A couple of favorite fruits are apples, blueberries, blackberries, and persimmons.[1]
趣闻:鹿喜欢水果和坚果 。 除了橡子,他们还喜欢山核桃,山核桃和橡子。 苹果,蓝莓,黑莓和柿子是最喜欢的水果。[1]
Deers love to consume pecans. Our deer is at the “road not taken” situation. The left path has grass and the right path has pecans. Now the deer must take the right path to eat its favorite food. The reward is that it gets its hunger satiated and also it is like a feast. However, the left path is also good as it satiates its hunger. The reward is high on the right path. If it was a K-Bandit problem, we would have chosen the right path. Now see the fate of the deer. The deer takes the right path and starts eating pecans but within seconds, a lion starts chasing and eventually kills the deer. Oopsie. Let us not allow it and let’s teach the deer reinforcement learning using Markov Decision Processes.
鹿喜欢吃山核桃。 我们的鹿处在“未走之路”的境地。 左路径有草,右路径有山核桃。 现在,鹿必须走正确的道路才能吃到自己喜欢的食物。 奖励是它可以使饥饿得到满足,并且就像一场盛宴。 然而,左路也能很好地缓解饥饿感。 正确道路上的回报很高。 如果这是一个K-Bandit问题,我们将选择正确的路径。 现在看看鹿的命运。 鹿走了正确的路,开始吃山核桃,但是在几秒钟内,狮子开始追逐并最终杀死了鹿。 哎呀 让我们不允许它,让我们使用“ 马尔可夫决策过程”来教鹿增强学习。
The Markov Decision Process(MDP) gives us a way on estimating the rewards that we may get in the future. A bandit deer would have chosen the right path. But in order to make the deer take the left path, we must consider the actions as states. With each action taken the problem changes into a new state with rewards from that point of time.
马尔可夫决策过程( MDP )为我们提供了一种估计未来可能获得的回报的方法。 土匪鹿会选择正确的道路。 但是为了使鹿走左路,我们必须将这些动作视为状态。 从采取的每项行动开始,问题都会转变为新的状态,并从该时间点开始获得奖励。

Now you can see the two sequences that are possible from the initial state i.e, the point where the deer has to take a path. Technically the agent generates a set of series of possible states at every discrete time steps and selects the best from the set.
现在您可以看到从初始状态(即鹿必须走的地方)开始的两个序列。 从技术上讲,代理会在每个离散时间步长生成一系列可能的状态,并从该状态中选择最佳状态。
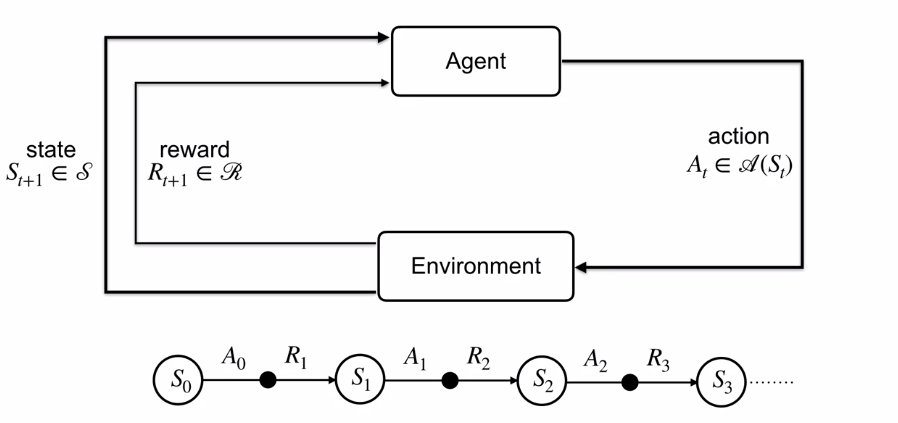
Just like Bandits, the outcomes of MDP is stochastic. Now probability theory comes to our rescue as possibilities are involved. With the transition dynamics probability function p(next state, reward|state, action), we can predict the joint probability of the next state and the set of rewards given the current state and action. Notice that the future state and rewards are only dependent on the current state and action. This is called Markov Property. As a side note, I would point out that unlike here, in Natural Language Processing previous states do matter a lot and they have techniques like Long Short Term Memory Cells and Transformers to deal them.
就像强盗一样,MDP的结果是随机的。 现在,随着可能性的发展,概率论进入了我们的拯救。 使用过渡动力学概率函数p(下一个状态,奖励|状态,动作) ,我们可以预测下一个状态的联合概率以及给定当前状态和活动的奖励集。 注意,将来的状态和奖励仅取决于当前的状态和动作。 这称为Markov属性 。 附带说明一下,我要指出的是,与此处不同的是,在自然语言处理中,以前的状态确实很重要,并且它们具有长短期记忆单元和变压器等技术来处理它们。
The important part of MDP is the modeling of the environment with all possible states, actions, rewards. This is done in the form of discrete graphs. Such graphs make it easy for us to implement in the form of vectors. From the story of the deer, the most important inference is to maximize the sum of rewards from a time step.
MDP的重要部分是对环境进行建模,其中包含所有可能的状态,动作和奖励。 这以离散图的形式完成。 这样的图使我们很容易以向量的形式实现。 从鹿的故事来看,最重要的推论是最大化时间步长的总和。
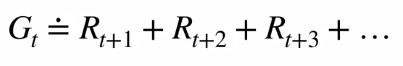
Note that Gt is a random variable. We have so much randomness from a single action as it has many possible states and the MDP is stochastic. This is why we maximize the Expectation rather than the actual sum.
注意,Gt是随机变量。 一个动作有很多可能的状态,并且MDP是随机的,因此我们从一个动作中获得了太多的随机性。 这就是为什么我们最大化期望而不是实际总和的原因。
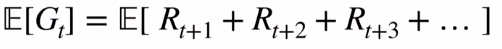
The agent breaks up the series into episodes with a terminal point. Consider the case of deer. Here, the whole process of the deer trying to consume is an episode and actual consumption is the terminal point. This is called an episodic task. The whole point of the episodic task is to deal with what happens after the agent-environment interaction ends. When the agent encounters the episodic task, it resets itself to the start state.
特工将电视连续剧分成带有终点的剧集 。 考虑一下鹿的情况。 在这里,鹿试图消耗的整个过程是一个情节,而实际消耗是终点。 这称为情节任务 。 情节任务的全部重点是处理在主体与环境之间的交互结束之后发生的事情。 当代理程序遇到临时任务时,它将自己重置为开始状态。
I now want to pitch in a very important topic that you may want to dive deeper into. Reward Hypothesis. “Michael Littman calls this the reinforcement learning hypothesis. That name seems appropriate because it is a distinctive feature of reinforcement learning that it takes this hypothesis seriously. Markov decision processes involve rewards, but only with the onset of reinforcement learning has reward maximization been put forth seriously as a reasonable model of a complete intelligent agent analogous to a human being.”[2]
现在,我想提出一个非常重要的主题,您可能想深入探讨。 奖励假设。 “迈克尔·利特曼这就要求强化学习假说 。 该名称似乎是适当的,因为它是强化学习的一个显着特征,因为它认真对待这一假设。 马尔可夫决策过程涉及奖励,但是只有在强化学习开始之后,奖励最大化才能作为类似于人的完整智能主体的合理模型被认真提出。” [2]
What is this? Let me try to put it in words. Think of air conditioners and what can possibly be the reward? Is it going to be the temperature or is it going to be the cost of electricity? Now think of the stock market, and here we have a pretty solid reward — The currency. So, it is not easy to define rewards for many cases in RL. But our brain somehow does it just like that. Think of a very rare objective that could be achieved. Let’s fix the objective to be Kim Jong Un and his path to winning the Nobel Peace Prize. I know it can’t happen, but let us consider an agent in the position of Kim. Now if we are so rigid with the rewards, like +1 for the noble prize and 0 otherwise. How can we monitor the agent’s progress? It is wise to split up and reward the agent with a low value of say +0.001 for even acts like keeping the people of North Korea happy which may lead to the ultimate goal of the agent. What is the point I’m struggling to convey? It is the selection of rewards, how you do it, and how well it turns out to work.
这是什么? 让我尝试用言语表达。 想想空调,什么可能是回报? 是温度还是电费? 现在想想股票市场,在这里,我们有相当丰厚的回报-货币。 因此,在RL中为许多情况定义奖励并不容易。 但是我们的大脑却以某种方式做到了。 想一个可以实现的非常罕见的目标。 让我们将目标定为金正恩及其赢得诺贝尔和平奖的道路。 我知道这是不可能的,但让我们考虑一下Kim的代理人。 现在,如果我们对奖励如此刻板,例如+1可获得高贵奖,否则为0。 我们如何监控代理的进度? 明智的做法是分散并奖励代理人,使他们获得+0.001的低价值,甚至是使朝鲜人民高兴的行为,甚至可能导致代理人的最终目标。 我要传达的重点是什么? 它是对奖励的选择,您如何做以及其效果如何。
We discussed episodic tasks. But there are also cases where an agent-environment interaction has no episodes or terminal points. An automatic air conditioner is a good example of this problem. Here, the agent has to constantly monitor the environment and adapt to the temperature to maintain the need of the user. These kinds of infinite tasks are called Continuing Tasks.
我们讨论了情景任务。 但是,在某些情况下,主体与环境之间的互动没有发作或终点。 自动空调就是这个问题的一个很好的例子。 在此,代理商必须不断监控环境并适应温度,以保持用户的需求。 这些无限的任务称为连续任务 。
The problem here is we are trying to sum up infinite rewards to maximize Gt. We need to model the problem into a finite one. Fortunately, discounting will help us deal with this. We can discount future rewards with γ which is at least 0 and lesser than 1.
这里的问题是我们试图总结无限的奖励以最大化Gt。 我们需要将问题建模为一个有限的问题。 幸运的是, 打折将帮助我们解决这个问题。 我们可以用至少为0且小于1的γ折现未来的奖励。
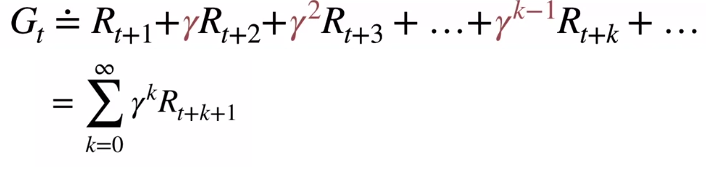
The powers of gamma help in reducing the impact of future rewards. Logically it makes sense as you would want to consider your immediate rewards more than the future rewards like in the case of currency exchanges. Still, it looks like infinite right? Let’s pull some mathematical trick in here.
伽玛的力量有助于减少未来奖励的影响。 从逻辑上讲,这是有道理的,因为与货币兑换一样,您希望比即时奖励更多地考虑即时奖励。 不过,它看起来像是无限的吧? 让我们在这里拉一些数学技巧。

Let us assume that Rmax is the maximum reward that an agent can achieve. Now we upper bound Gt by replacing all rewards with Rmax. Now we are going to rewrite the geometric series (summation of k to infinity of γ to the power k) to 1 / 1 - γ. Yay! we did it. Therefore Gt is finite.
让我们假设Rmax是代理可以实现的最大奖励。 现在我们通过用Rmax代替所有奖励来限制Gt的上限。 现在,我们将把几何级数( k与γ的无穷大之和乘以k )重写为1/1-γ。 好极了! 我们做到了。 因此,Gt是有限的。

I hope that with all the mathematics we discussed the deer will make a decision that is good in the long run.
我希望,与我们讨论过的所有数学方法相比,鹿从长远来看会做出一个好的决定。
带走 (Takeaway)
i) Actions influence rewards but also it influences the future states, future action, and future rewards
i)行动会影响奖励,但也会影响未来的状态,未来的行动和未来的奖励
ii) The goal of an RL agent is to maximize the expected reward after time step t and not the immediate reward.
ii)RL代理的目标是在时间步长t之后而不是即时奖励中最大化预期奖励。
iii) The difference between episodic tasks and continuing tasks
iii)情节任务和连续任务之间的区别
翻译自: https://medium.com/swlh/letss-talk-reinforcement-learning-the-fundamentals-part-2-a9614087a647
bic谈话
相关文章:
这篇关于bic谈话_让谈话强化学习基础知识第二部分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






