本文主要是介绍排序算法(python)- 插入排序和谢尔排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 插入排序
- LeetCode剑指 Offer 45. 把数组排成最小的数
- 谢尔排序
插入排序
插入排序的思路与冒泡排序、选择排序不同,时间复杂度却是O(n^2)。

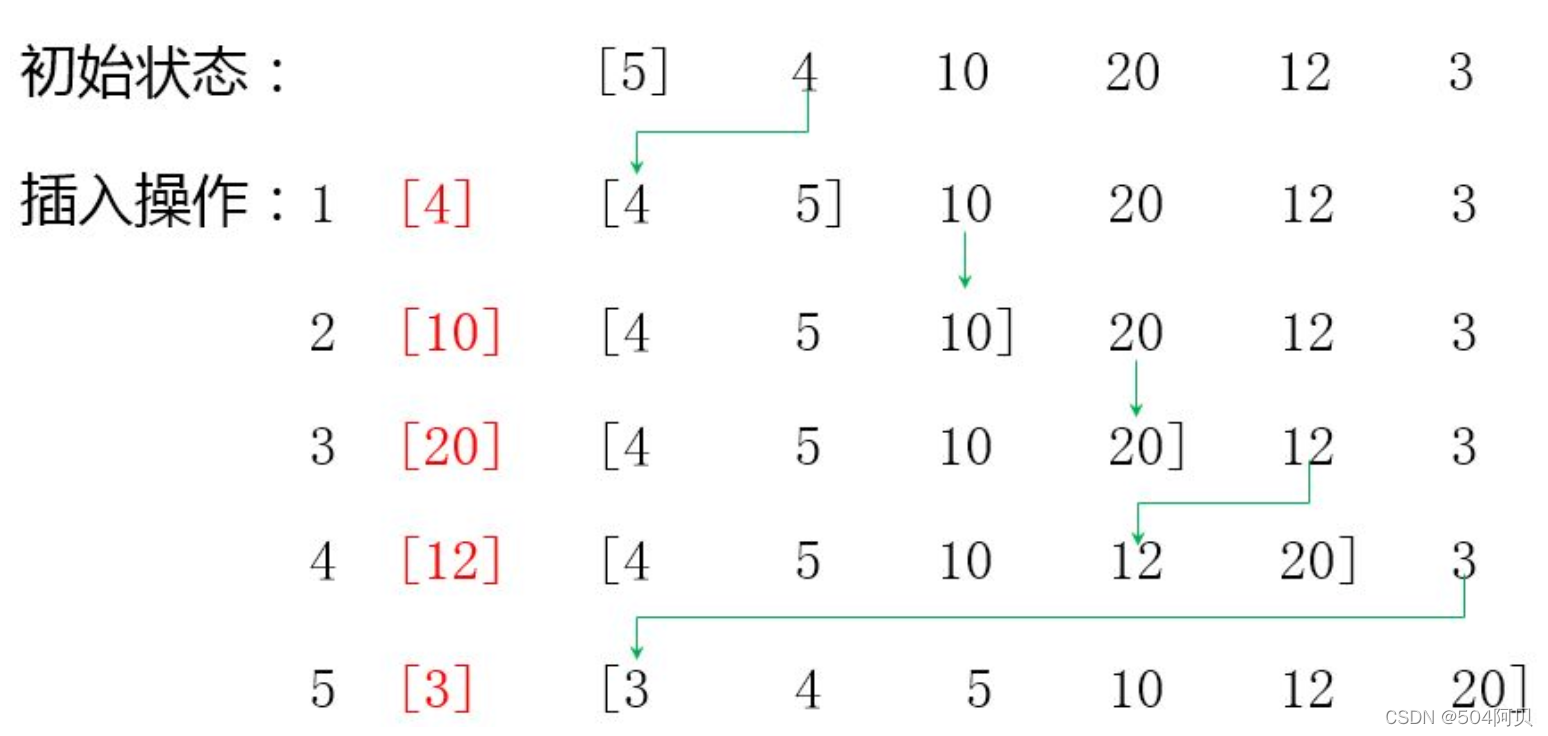
插入排序维持一个已经排好的子列表在列表的前部,然后逐渐扩大这个子列表直到全表。
- 第一步,子列表包含第一项数据,将第二项作为新项与第一项比较,放到合适位置,这样一排好的就有两项了;
- 再将第三项与前两项比较,并移动比自身大的数据项,空出来位置,以便加入到子列表中;
- 经过n-1次比对和插入,已排好的子列表扩展到全表,排序完成。
def Insert_Sort(alist):n = len(alist)for i in range(1,n):cur = alist[i]j = iwhile j > 0 and alist[j-1] > cur:alist[j] = alist[j-1]j -= 1alist[j] = curreturn alisttest_list = [54,2,1,77,100,15,12,18]
print(Insert_Sort(test_list))
最好的情况,就是列表已经拍好序的时候,每次仅需要一次比对,总次数就是O(n)。
LeetCode剑指 Offer 45. 把数组排成最小的数
def com(x,y):x, y = str(x), str(y)if int(x + y) < int(y + x):return Trueelse:return Falsedef min_Number(nums):for i in range(1, len(nums)):cur = nums[i]j = i - 1#改变了比较的条件while j >= 0 and com(cur, nums[j]):nums[j + 1] = nums[j]j -= 1nums[j + 1] = curres = ''.join(map(str, nums))return res
test_list = [3,30,34,5,9]
print(min_Number(test_list))
输出:
3033459
谢尔排序
我们注意到插入排序的比对次数,在最好的情况下是O(n),是在列表有序的情况下,实际上列表越接近有序,插入排序的比对次数就越少。
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。
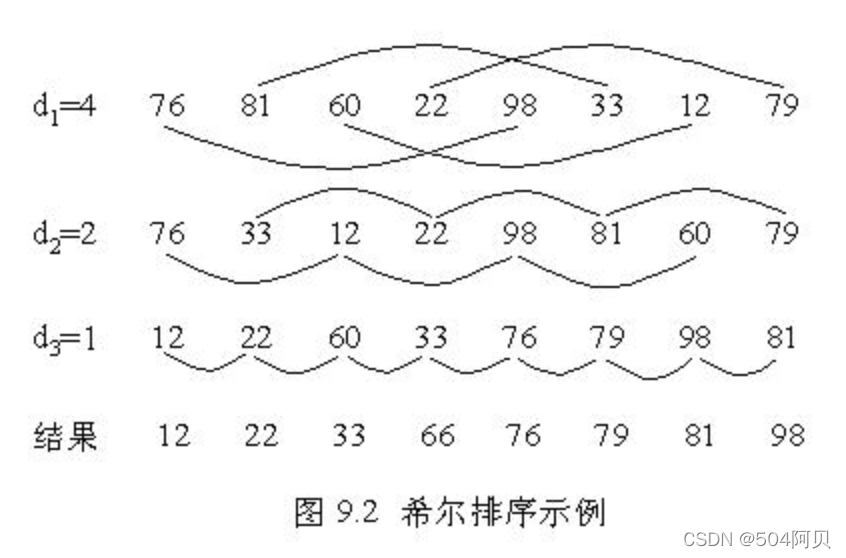
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
子列表的间隔一般从n/2开始,每趟倍增:n/4,n/8,……直到1。
def Shell_Sort(alist):sub_count = len(alist) // 2 #间隔设定while sub_count > 0:for start in range(sub_count):gap_insert_sort(alist, start, sub_count)print(sub_count, alist)sub_count = sub_count // 2return alistdef gap_insert_sort(alist, start, gap):for i in range(start+gap, len(alist), gap):cur = alist[i]j = iwhile j >= gap and alist[j-gap] > cur:alist[j] = alist[j-gap]j -= gapalist[j] = curtest_list = [54,2,1,77,100,15,12,18]
print(Shell_Sort(test_list))
输出:
4 [54, 2, 1, 18, 100, 15, 12, 77]
2 [1, 2, 12, 15, 54, 18, 100, 77]
1 [1, 2, 12, 15, 18, 54, 77, 100]
[1, 2, 12, 15, 18, 54, 77, 100]
谢尔排序是以插入排序为基础的,但是由于每次都使得列表更接近有序,所以过程中会减少很多原先的无效的比对。
谢尔排序的复杂度比较特殊,介于O(n)和O(n^2)之间。
这篇关于排序算法(python)- 插入排序和谢尔排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




