本文主要是介绍AIOps探索 | 如何实现相似事件识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一、什么是事件
关联引擎将一组相关的告警聚集到一起生成的事件(incident)。其目的是在逻辑上将告警工作台上杂乱无章的告警按不同的使用场景分为多个分组,以便将描述同一个问题的相关告警或有关联关系的告警分组到一起进行集中处置,而不需要将无关的噪音放到同一工作台上对事件管理员造成过多的干扰。
有了事件之后,可以按不同的目标将告警关联到一起生成事件,如:
1.应用管理员:希望将同一应用系统所产生的业务层、应用层、数据库层的告警分组到一起,以便更好地感知事件的详细上下文信息,加速排障过程。
2.数据库管理员:希望将不同业务系统的数据库集群所产生的告警,按应用系统分组成不同的告警,以集中处理集群的问题,而非一个个独立主机的不同告警。
3.devops工程师:希望将endpoints的不同告警分组到一起,如cusLogin1.0、cusLogin1.1,都属于用户登录服务,分属于不同的版本,但都是由同一队人共同开发和运维的,希望能够分组到一起共同进行分析处理。
二、事件同告警的主要区别
从运营数据中心提高效率和降低噪音干扰的角度来看,事件与告警存在以下主要区别:

1.Event 管理阶段:早期阶段处理来自监控系统(如apm、zabbix、prometheus)产生的各种异常信号。这些异常信号数量庞大,其中包含大量重复的内容。在处理这些信息时,面临着大量噪音和难以高效处理的问题。
2.Alert 管理阶段:集中处理各个监控系统产生的事件,进行有效去重和压缩处理。告警数量迅速减少,但仍需要处理大量告警。随着数字化转型,监控的内容越来越多,相互之间的影响和关联越来越难以管理。这导致事件管理员通常需要在告警工作台上面对大量杂乱无章的告警,花费大量精力才能手动整理这些信息。
3.Incident 管理阶段:使用告警关联的方法将涉及时间和空间关联关系的告警分组,为事件管理员提供更丰富的故障上下文。这样可以避免被太多无关的告警干扰,专注于解决具体问题。
三、为什么要识别相似事件
通过识别相似事件,可以查看过去事件管理员或运维领域专家在处理类似事件时采取的方法和步骤。参考过去相似事件的解决方案可以节省解决当前事件所需的时间。
同时,相似事件还可以揭示一些模式,这些模式表明设备、服务、应用或其他组件导致事件发生的长期问题。提供的信息可以帮助有效追踪这些事件的根源并防止将来再次发生。
四、Jaccard算法简介
Jaccard系数是一种用于衡量两个集合相似性的统计方法。计算Jaccard系数的方法是通过计算两个集合的交集元素数量除以并集元素数量来衡量它们的相似程度。Jaccard系数的取值范围是0到1,越接近于1表示两个集合越相似,越接近于0表示两个集合越不相似。
1.计算公式
J(A, B) = |A ∩ B| / |A ∪ B|
其中,A和B分别表示两个集合,|A|表示集合A的元素数量,|B|表示集合B的元素数量,|A ∩ B|表示A和B的交集元素数量,|A ∪ B|表示A和B的并集元素数量。
2.计算示例说明
假设有两个集合A和B,分别包含以下元素:
A = {1, 2, 3, 4, 5} B = {4, 5, 6, 7, 8}
首先计算交集元素数量:A ∩ B = {4, 5} 交集元素数量为2。
然后计算并集元素数量:A ∪ B = {1, 2, 3, 4, 5, 6, 7, 8} 并集元素数量为8。
最后,计算Jaccard系数:J(A, B) = |A ∩ B| / |A ∪ B| = 2 / 8 = 0.25
因此,集合A和集合B的Jaccard系数为0.25,表示它们的相似程度较低。
3.Jaccard算法在通用领域主要应用场景
·文本挖掘:可以用来衡量两个文档之间的相似性,本例中即是将两个事件的相关特性文本化之后,评估不同事件的特征文档相似性。
·图像分析:用于稳定两幅图像之间的相似度。
·推荐系统:可以用于衡量两个购物栏之间的相似性,然后以此信息向用户提出建议。
4.Jaccard算法在智能运维领域应用场景
相似事件识别
事件根因定位
基于事件的已知故障识别:针对已知故障,可以直接定位故障根因,并推荐自动化处置策略,可以进行手工或自动化问题解决。
告警关联生成事件:通过相似性识别来完成对告警的关联生成事件。
五.如何实现相似事件的识别
1.如何表征事件
在进行相似事件识别之前,我们先来看一下如何表征事件,只有了解事件的特征之后,才可以通过不同的方案完成事件的相似性判断。
一个事件通知由一组告警组成,以某大型国有银行“资产证券化系统”的告警关联为例,其应用架构如下所示:
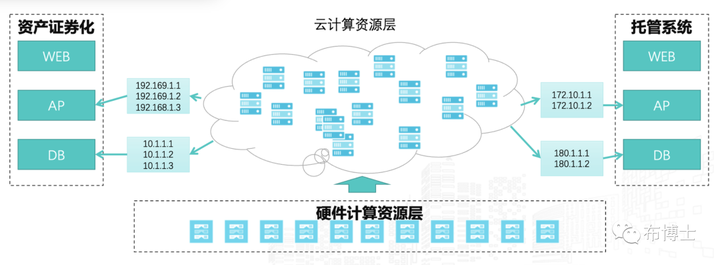
应用系统通常做了如下的监控内容:
①业务层监控,应用系统可能支持一个或多个业务,或包括多个子系统,监控业务成功率、系统成功率等:
②技术组件 -服务器监控,如cpu、内存、服务器网络性能、服务器磁盘忙等
③技术组件 - 数据库,如数据库cpu、表空间不足、磁盘使用率等
④技术组件 - 应用中间件,如weblogic 的fullgc异常、jvm使用的堆栈空间百分比等
⑤技术组件 - 存储,如响应时间超时等。
⑥应用日志,如特定的数据库服务器日志、应用日志等
当该系统发生告警时,将业务层及技术组件层相关的告警按20分钟的滑动时间窗口,都会关联成为一个事件,不同的时间窗口,我们可以看到如下事件:
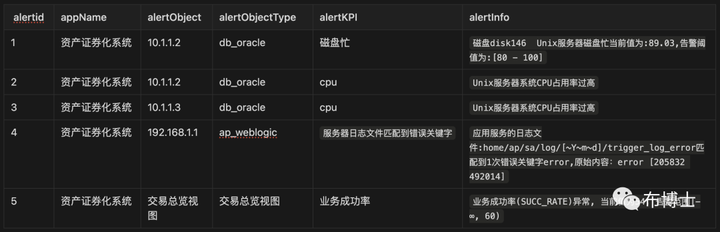
事件1
针对事件1,我们在进行故障处理时,通常会这样来描述该事件:
业务系统资产证券化系统出现 交易总览视图 业务成功率异常,同时 数据库 出现了cpu和磁盘忙现象,应用服务器weblogic 出现 服务器日志文件匹配错误关键字。
我们通过非常简短的一段话把整个事件中所包含5条告警的特征描述清楚了。

事件2
针对事件2,我们在进行故障处理时,通常会这样来描述该事件:
业务系统资产证券化系统 未出现业务层的告警,数据库出现了cpu和磁盘忙现象,同时 存储 出现 响应时间超时 问题。
通过对事件的描述,我们可以知道在以应用系统的视角进行关联时,alertObjectType和alertKPI两个字段是非常容易描述事件特征的,针对这些理解,我们可以将上述两个事件的特征表征如下:
-
事件1的特征描述:db_oracle:磁盘忙 db_oracle:cpu ap_weblogic:服务器日志文件匹配到错误关键字 交易总览视图:业务成功率
-
事件2的特征描述:db_oracle:磁盘忙 db_oracle:cpu 存储:响应时间
通过上面章节jaccard的介绍,我们可以计算:
两个事件的交集共2项,为:db_oracle:磁盘忙 db_oracle:cpu
两个事件的并集共5项,为:db_oracle:磁盘忙 db_oracle:cpu ap_weblogic:服务器日志文件匹配到错误关键字 交易总览视图:业务成功率 db_oracle:cpu 存储:响应时间
jaccard相似度计算结果为:0.4
注意:在进行生产时要注意,不要将alertObject作为特征内容。一般应用系统会以集群方式部署,我们只需要关注是否发生了数据库类的告警,而不需要知道具体是哪台服务器发生了告警。也许现在是192.168.1.1发生了告警,而下次可能是集群中的192.168.1.2发生了告警,但是对于特征来说,它们都是数据库发生的告警。
六、示例及代码实现
# jaccard相似度计算函数
def jaccard_similarity(str1, str2):
list1 = str1.split() # 按空格分割并转换为列表
list2 = str2.split() # 按空格分割并转换为列表
# 取得两个list的交集
intersection_list =set(list1) & set(list2)
print(len(intersection_list))
# 取得两个list的并集
union_list =set(list1) | set(list2)
print(len(union_list))# 计算相似度
similarity = len(intersection_list) / len(union_list)return similarity
# 针对单一字符串计算相似度的方法,本例暂时用不到,后续的其它场景会用到
# 将字符串按不同的长度进行切分,字符串中出现空格时以下划线进行替换
# 示例:“Hello World”切分后为,“Hel ell llo lo_ o_W _Wo Wor orl rld"
def process_string(input_string,split_num = 3):
result = ""
for i in range(len(input_string)-split_num+1):
chunk = input_string[i:i+split_num]
chunk = chunk.replace(" ", "_")
result += chunk
if i + split_num < len(input_string):
result += " "
return result# 示例 :
# 在这里我们仅将两个事件的特征串直接用于验证
incident_1 = 'db_oracle:磁盘忙 db_oracle:cpu ap_weblogic:服务器日志文件匹配到错误关键字 交易总览视图:业务成功率'
incident_2 = 'db_oracle:磁盘忙 db_oracle:cpu 存储:响应时间'
#str1 = process_string(str1)
#str2 = process_string(str2)print("Jaccard相似度:", jaccard_similarity(incident_1,incident_2))
输出结果为
2 5 Jaccard相似度: 0.4
在实际的生产上进行应用时,需要实时将进入事件的告警确认其alertObjectType和alertKPI两个字段组合生成的串是否已经存在,如果不存在则加入,如果存在表明同样的问题已经发生了,不需要再重复记录。
本次分享到这里就告一段落了,如果大家对jaccard算法原理感兴趣,可以直接点击以下网址,阅读文章。
jaccard - wiki :https://en.wikipedia.org/wiki/Jaccard_index
感谢大家支持,我们下次见~
![]()

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择
 了解更多运维干货与行业前沿动态
了解更多运维干货与行业前沿动态
可以右上角一键关注
我们是深耕智能运维领域近十年的
连续多年获Gartner推荐的AIOps标杆供应商
下期我们不见不散~
这篇关于AIOps探索 | 如何实现相似事件识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






