本文主要是介绍如何使用labelme上次的标记结果继续制作图像的标签,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知,labelme 软件可以对图像进行标签的制作,本文就来讲解一下如何根据labelme上次的标记结果,继续对图像的标签进行制作。
首先,确保创建的虚拟环境中已经安装了labelme软件,关于labelme的安装在此我就不赘述了,重点来讲解一下如何打开安装好的labelme软件,如下图所示:
第一步:激活已经安装labelme软件的虚拟环境,在此我创建的虚拟环境是PyTorch_cpu
第二步:输入命令 labelme

完成以上两步后就会启动labelme软件,稍等一会儿就会弹出labelme软件的界面,如下图所示

关于该软件的详细使用方法,感兴趣的小伙伴可以参考这位博主的 博文:Labelme的安装和打开并使用_labelme怎么打开-CSDN博客 写得很不错,简单明了,可以快速上手使用labelme
在此,打开路径 “ D:\data\study_a\study1.tif ”下的图像study1.tif , 并对图像中的建筑物进行标注,如下图所示:
图像:

标注结果:
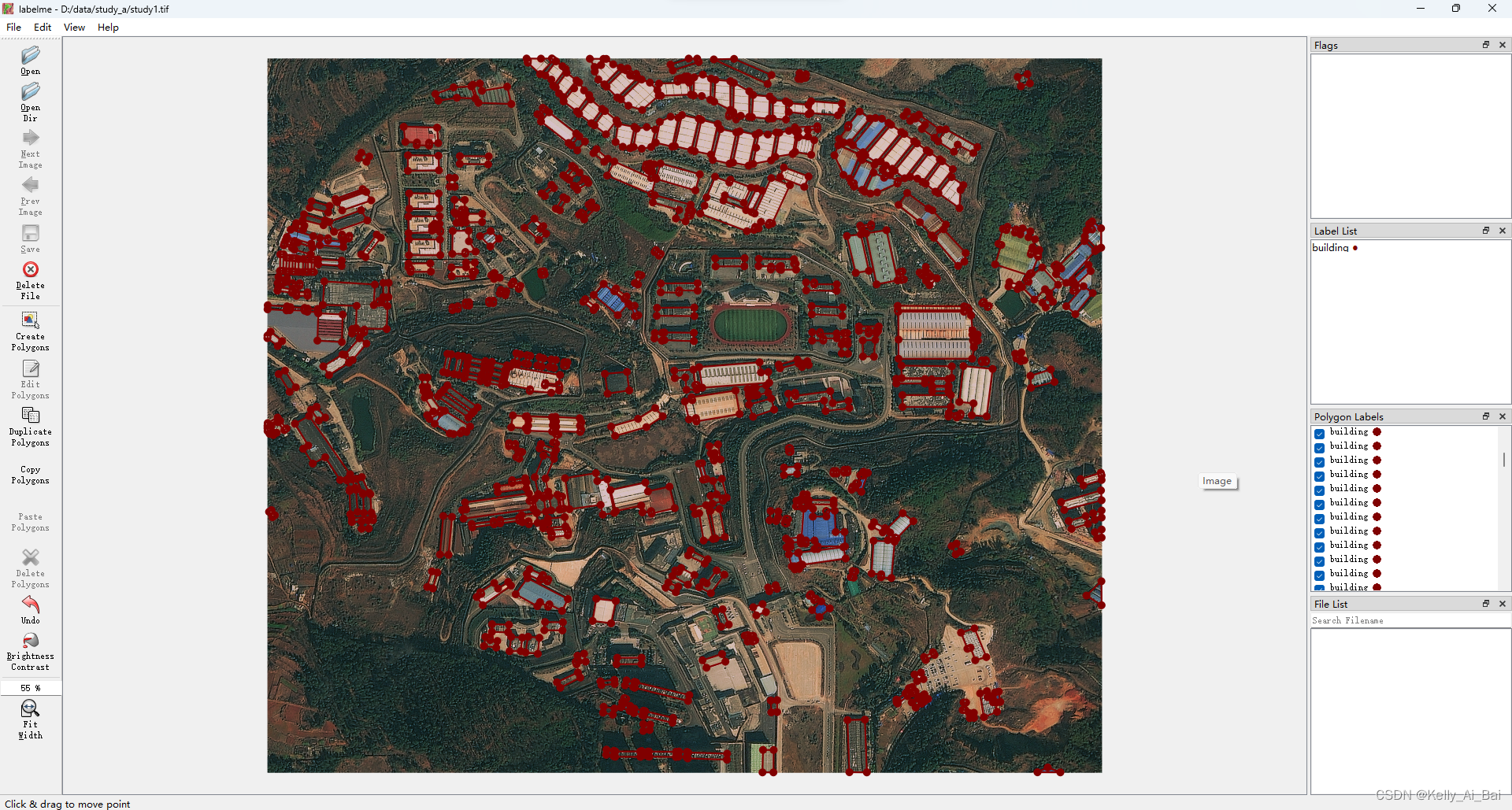
从图中可以看到,建筑物都用红色的矩形框框选了出来,并且说明红色框表示 building 这一类别,这样就完成了标注。
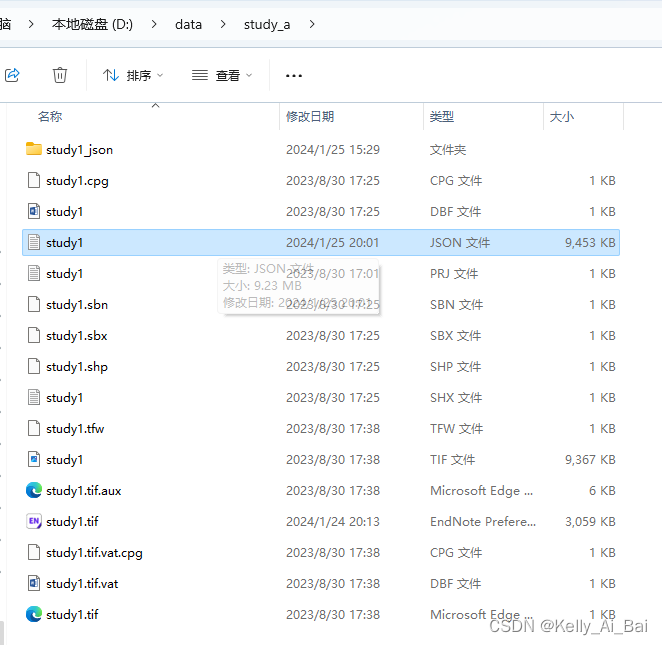
一般地,完成标注之后,点击 save,可以看到我们的标记结果被保存为json文件,如图所示

那么在图像study1.tif所在路径的文件夹(此处是study_a)中就可以找到保存的含有标注信息的json文件study1.json了
重新激活环境 PyTorch_cpu,并且输入如图所示的命令:  就可以看到文件夹下有多了一个文件夹study1_json,该文件夹下的内容如图所示:
就可以看到文件夹下有多了一个文件夹study1_json,该文件夹下的内容如图所示:
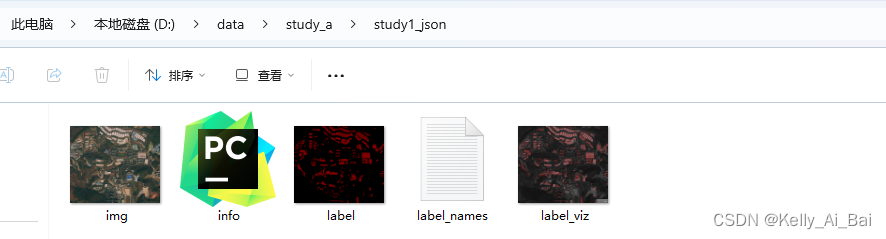
我想 label.png 就是我们需要的标签数据文件了

有的时候可能会发现标签的标注信息不准确,需要对label.png标签图像进行修改,那么应该怎么操作呢?总不能再次重新标记一遍吧
只需要打开我们刚才保存的 json文件(study1.json)就可以继续上次的标记结果来修改标记图像label.png了,如下图所示:
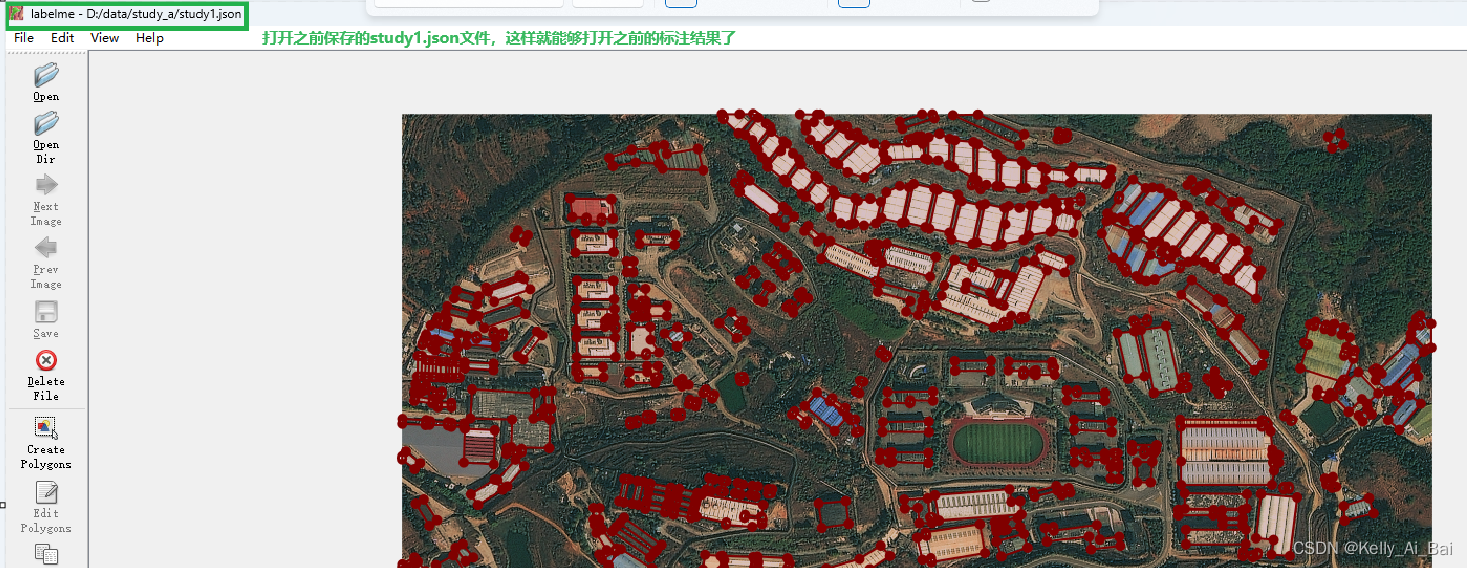
 在蓝色框选的部分中,我又添加了两个建筑物,对该标记结果点击界面右侧的save按钮,就可以对原来study1.json文件中的标注信息进行更新了,重新将该json文件中的信息转换为png图像形式,结果如图所示:
在蓝色框选的部分中,我又添加了两个建筑物,对该标记结果点击界面右侧的save按钮,就可以对原来study1.json文件中的标注信息进行更新了,重新将该json文件中的信息转换为png图像形式,结果如图所示:
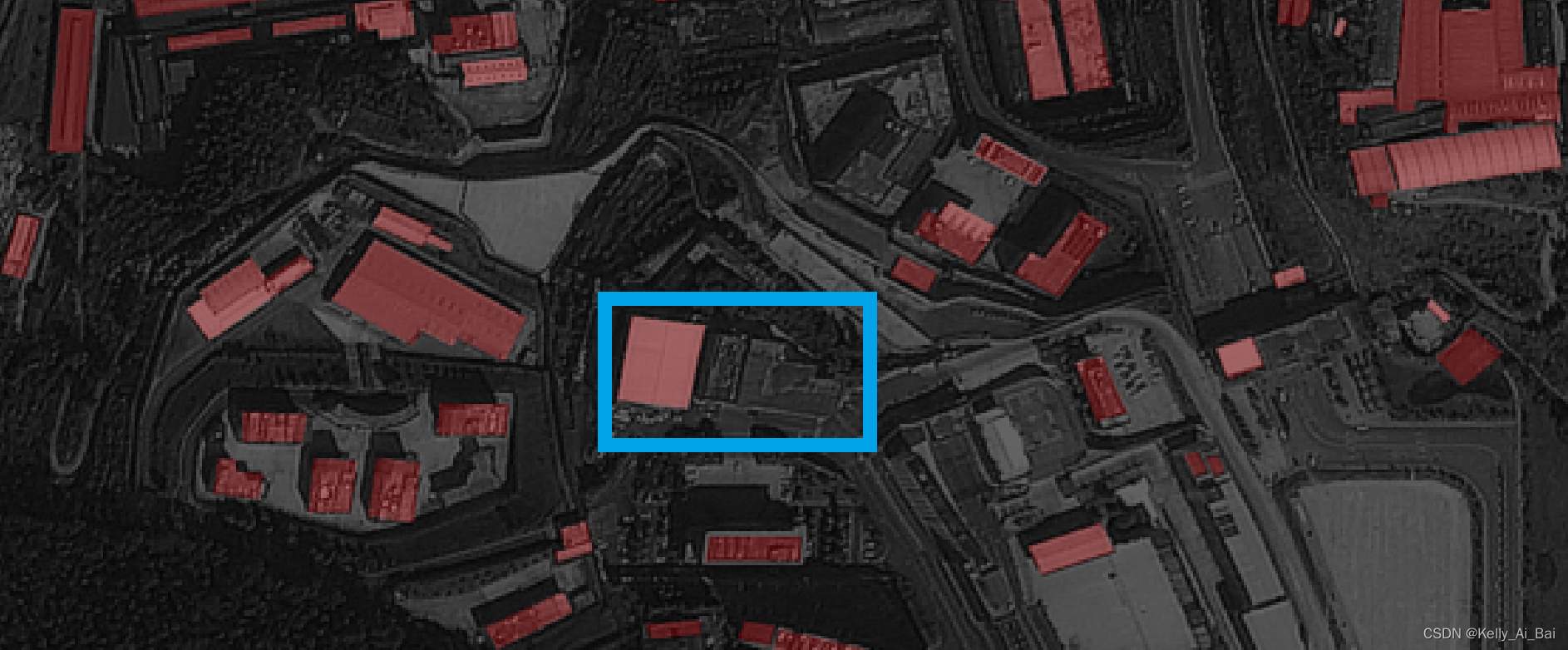
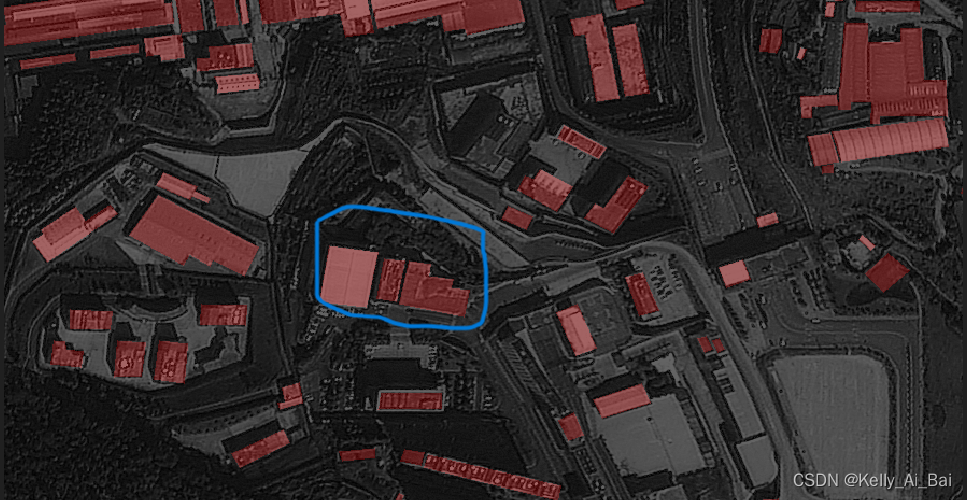 从上述两幅图像的对比可以看到,新的标记结果图已经重新补充了两个建筑物信息
从上述两幅图像的对比可以看到,新的标记结果图已经重新补充了两个建筑物信息
综上所述就是关于如何使用labelme软件修改标注结果的过程,如果有任何问题欢迎评论区下面评论,期待与大家一起讨论!
这篇关于如何使用labelme上次的标记结果继续制作图像的标签的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





