本文主要是介绍对比学习在深度图聚类方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

今天给大家分享的是国防科技大学刘新旺老师团队发表在IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS的论文"Simple Contrastive Graph Clustering"。论文提出了一种简单高效的图对比学习聚类方法SCGC,SCGC十分轻量,并且和一般的深度图聚类相比,不需要花大量时间去预训练。文章提出了一种新的对比学习数据增强方法,设计了一种新颖的基于邻居节点的对比loss。
1 摘要
近期,对比学习在深度图聚类中受到了广泛关注,因为其表现出了良好的性能。然而,复杂的数据增强和耗时的图卷积操作却降低了这些方法的效率。为了解决这个问题,作者提出了一种简单的对比图聚类(SCGC)算法,从网络架构、数据增强和目标函数等方面改进了现有的方法。在架构方面,本文的网络包括两个主要部分:预处理和网络主干。一个简单的低通去噪操作作为独立的预处理进行邻居信息聚合,只有两个多层感知器(MLPs)作为模型主体。对于数据增强,作者没有引入复杂的图操作,而是通过设计参数不共享的MLP编码器和直接扰动节点嵌入,构建了同一顶点的两个增强视图。最后,对于目标函数,为了进一步提升聚类性能,作者设计了一种新的跨视图结构一致性目标函数,以增强学习网络的判别能力。在七个基准数据集上的广泛实验结果证实了本文提出的算法的有效性和优越性。显著的是,本文的算法在平均性能上至少比最近的对比深度聚类算法平均快七倍。
2 方法
符号与问题定义
首先定义图的节点集为,节点的属性表示为。以此为基础,可以构建一个无向图。图的度定义为,而图的拉普拉斯矩阵表示为。通过使用图卷积网络(GCN)中的重整化技巧,得到图的对称归一化拉普拉斯矩阵。
深度图聚类的目标是将图的节点分割为几个独立的群体。更具体地说,可以使用无监督方式预训练一个神经网络,该网络能够编码图的节点和结构信息,表示为:
编码完成后,可以使用K-means、谱聚类等聚类算法,将节点的嵌入划分为独立的群组:
整体框架
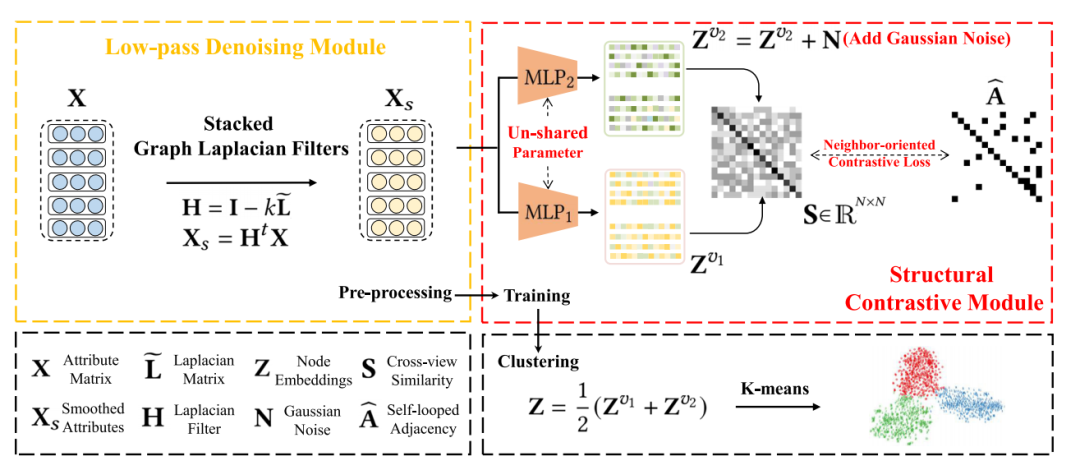
SCGC的整体架构
SCGC主要包含了低通噪声滤波、结构对比模块两个部分。
低通滤波处理噪声
近期的研究表明,拉普拉斯滤波器能够实现与图卷积网络(GCN)相同的效果。受此启发,作者提出了一种低通滤波操作,用于聚合邻近节点的信息,从而有效地过滤掉属性中的高频噪声。具体来说,作者引入了图拉普拉斯滤波器:
其中,代表对称归一化的图拉普拉斯矩阵。作者将个图拉普拉斯滤波器进行了堆叠:
这种低通滤波的降噪操作有效地过滤了高频噪声,从而提升了聚类性能和训练效率。
结构对比模块的优化
作者提出了一种称为SCM的方法,旨在保持两个不同视图之间的结构一致性,以此提升网络的判别能力。具体来讲,作者首先对平滑后的属性使用MLP编码器编码,然后将得到的结点嵌入进行L2规范化:
其中和表示学习到的节点嵌入的两个增强视图。为了进一步保持两个视图的不一致性,作者在嵌入中添加了高斯噪声:
作者设计了两个参数不共享的MLP编码器来实现视图的增强,这种增强方式仅通过扰动嵌入而非采用复杂的图增强方式,效果显著。此外,最近的一些研究显示,复杂的图数据增强方式,例如增加、减少边、图扩散等,可能会导致语义偏移,这也得到了作者后续实验的证实。
接着,作者提出了一种新颖的、面向邻居的对比损失函数,以保持跨视图的一致性。具体来说,作者计算了跨视图采样的相似度矩阵:
其中代表第i个节点和第j个节点的嵌入的余弦相似度。然后,作者强制让跨视图采样的相似度矩阵与自环邻接矩阵保持一致:
在这里,作者将跨视图的邻居节点视为正采样,非邻居节点视为负采样,优化的目标是将正采样拉近,负采样推远。
融合和聚类
作者融合了两个结点的增强视图:
然后,作者直接利用嵌入Z进行K-means聚类。
目标函数
作者直接去优化上述提出的面向邻居的对比loss:
作者分析了loss的时间复杂度。给出采样数目N和学到的特征维度d的时间复杂度为,对齐的复杂度为,整体的复杂度为。整体的细节算法流程如下:

SCGC的算法描述
3 实验
为验证SCGC的有效性和效率,作者在如下的7个benchmark数据集上进行了实验:
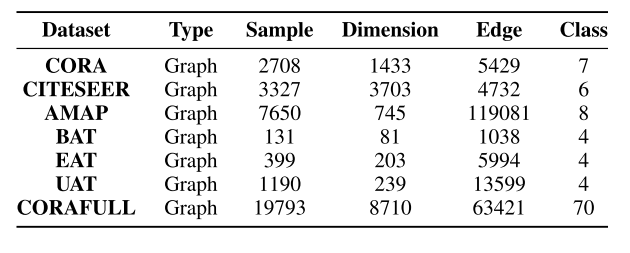
实验数据集
同时,作者将SCGC和13个基线算法进行对比在四种指标上进行了对比:
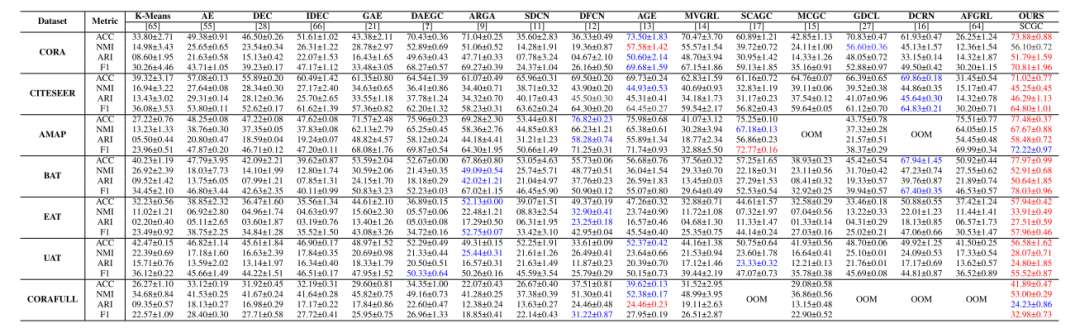
性能对比
K-means聚类直接在属性上进行聚类,效果不好。基于谱的方法SSGC和本文的方法相比,忽略了对比学习强监督信息。SCGC超过了目前优代表性的深度学习聚类方法,因为他们仅考虑了结点属性,忽略了图的拓扑信息。现有的对比学习方法达到了SCGC的次优。原因是本文的方法优化了采样的判别能力。
时间和显存消耗是评估算法效率的重要指标。由于本文的算法的模型结构非常简单,只有两层MLP,并且解构了GCN,使用低通滤波降噪来聚合邻居信息,所以十分高效。
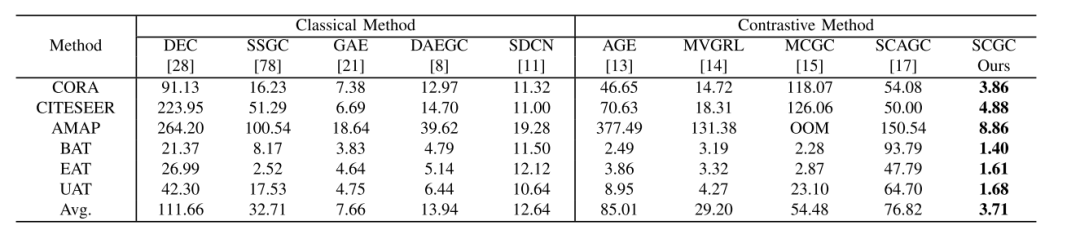
时间成本比较
同时,本文的方法在显存占用上,取得了和经典深度学习相当的显存占用。并且和对比学习图聚类算法相比,节省了59%的显存占用。作者将这个归结于两个原因:1、SCGC的MLP编码器很轻量;2、提出的方法在潜空间上进行数据增强。
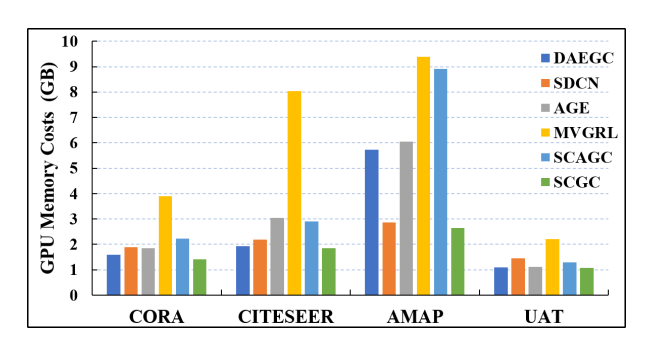
显存占用比较
作者进行了消融实验,证明了低通滤波器、数据增强手段是有效的。
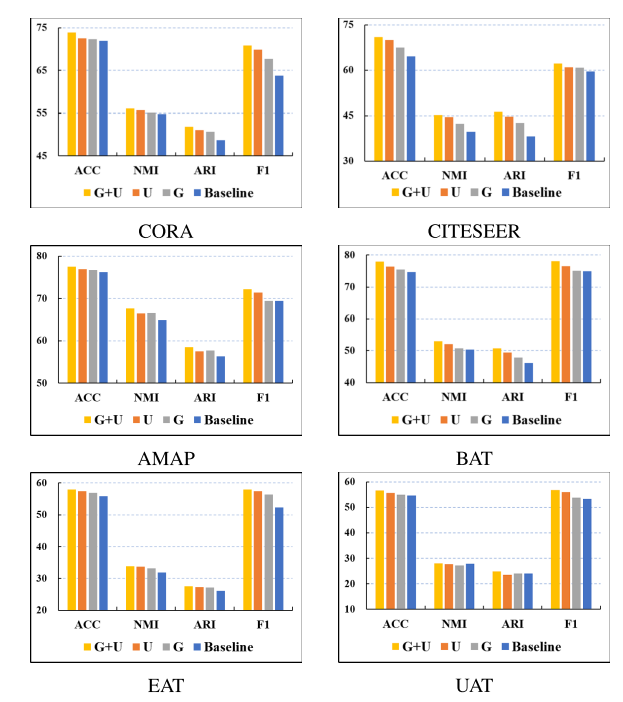
消融实验
同时,作者对聚类结果进行了可视化。视觉的结果表明,与其他基线相比,SCGC更好地揭示了内在的聚簇结构。

聚类结果可视化
4 总结
本文介绍了一种改进版的对比学习图聚类方法——SCGC。这一方法在网络架构、数据增强以及目标函数等方面优化了现有的技术。其被视为一种可应用于社区检测、文档挖掘、宏基因组包、单细胞RNA测序和知识图谱等领域的工具。
然而,SCGC也存在一些限制:首先,它依赖于预设的聚类数量,无法自动确定聚类的数量;其次,SCGC只适合处理中等规模的图,无法应对大型图数据。
鉴于上述不足,作者已规划了未来的改进计划:一是采用基于密度的聚类方法或基于强化学习的策略,以解决需要预设聚类数量的问题;二是为了能够处理大规模图数据,计划设计更高效的时间和空间采样、聚类方法;三是使该方法能够适应同质图和异质图的需求。
这篇关于对比学习在深度图聚类方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






