本文主要是介绍用于医学分割的实时Test-time adaption,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机构:约翰霍普金斯
论文:https://arxiv.org/abs/2203.05574
代码:https://github.com/jeya-maria-jose/On-The-Fly-Adaptation
摘要
基于深度学习的医学成像解决方案的一个主要问题是,当模型在不同于其训练的数据分布上进行测试时,性能会下降。在测试时调整源模型以适应目标数据分布是解决数据迁移问题的有效方法。以前的方法通过使用熵最小化或正则化等技术使模型适应目标分布来解决这个问题。在这些方法中,模型仍然是通过对完整测试数据分布使用无监督损失的反向传播来更新的。在现实世界的临床环境中,动态调整模型以适应新的测试图像更有意义,并且由于隐私问题和部署时缺乏计算资源而避免在推理期间更新模型。为此,我们提出了一种新的设置- On-the-Fly adaptive,它是零镜头和情景的(即,模型一次适应单个图像,并且在测试期间不进行任何反向传播)。为了实现这一点,我们提出了一个名为自适应UNet的新框架,其中每个卷积块都配备了一个自适应批处理归一化层,以根据domain代码调整特征。该域代码是使用在大型医学图像语料库上训练的预训练编码器生成的。在测试过程中,模型只接收新的测试图像,并根据测试数据生成域代码来适应源模型的特征。我们验证了2D和3D数据分布变化的性能,与之前的TTA方法相比,我们获得了更好的性能。
背景
许多医学图像分割的领域自适应技术都在研究解决这一问题[11]。但是,此设置假定我们可以访问源模型、源数据以及目标数据。另一种非常接近实时的设置是完全测试时适应[31],我们假设我们无法访问源数据,并通过每个样本执行一次反向传播来使模型适应目标数据。
然而,由于模型权重至少更新了一个完整的历元,因此该模型适应于完整的测试分布。这种设置可以被认为是one-shot适应,因为模型至少一次看到分布中的所有数据。在这项工作中,我们提出了一种临床动机设置,称为Test-Time adaption,其中模型一次适应单个图像/体积。
相关工作
Unsupervised Domain Adaptation
医学图像分割是一个被广泛探索的课题。已经提出了使用对抗训练(adversarial training)的特征对齐[18,24]、解纠缠表示(disentangling the representation)[32]、集成和使用软标签(ensembling and using soft labels)[25]等方法。然而,这些方法使用源数据和目标数据的训练分布进行适应,由于隐私问题,这对于医学成像并不总是可行的。
Source-free Unsupervised Domain Adaptation
医学图像分割假设没有可用的源数据。在[6]中,使用域不变先验定义了目标分布上的无标签熵损失。文献[7]提出了一种不确定性感知去噪伪标签方法。
Test-time Adaptation
TENT[31]等方法使用批量范数统计的熵最小化来适应新的目标分布。最近,Hu等人[13]提出使用区域核范数regional nuclear norm和轮廓正则化contour regular-ization等新的损失来提高医学图像分割的测试时间性能。自域适应网络Self domain adapted networks[12]使用基于自编码器的适配器来快速适应测试时的新任务。Karani等人[19]提出了一种逐测试图像per-test-image adaptation自适应方法,他们对图像进行自适应,以获得可信的分割。他们仍然在测试期间通过评估给定分割与源数据中的相似度来更新权重。

好奇怪啊,这可怎么训练
On-the-Fly Adaption
一组输入数据和标签:X,Y
source distribution: Xs, Ys
target distribution: Xt, Yt
normal source 训练中,我们用 Xs train 和 Ys train 训练模型,然后在Xs test上测试数据
direct testing(no adapting)中,我们使用在 Xs train 和 Ys train 训练的模型,然后在Xt test上测试
我们能获得最好的性能当模型在Xt train 和 Yt train 上训练然后在Xt test 上测试
在一般的测试时间适应中,我们假设整个目标测试分布Xt test在测试期间是可用的。权重会用梯度优化用一个从Xt test获得的无监督的损失函数Ltta(Xt test )。
工作如[19]为每一个测试图片做adaption。然而,他们确实在推理过程中根据手头的证据来优化权重,在测试分布中优化所有数据的网络权重,然后在Xtest t上再次使用新模型进行验证,这并不适合临床环境。
为每个测试图像调整模型更有意义,因为在医疗环境中使用整个测试分布涉及在测试时使用各种患者数据。在部署期间更新模型权重也很困难,因为它需要大量的计算能力。
在提出的on the fly 适应中,我们专注于一次适应单个测试图像/体积,如图1所示。
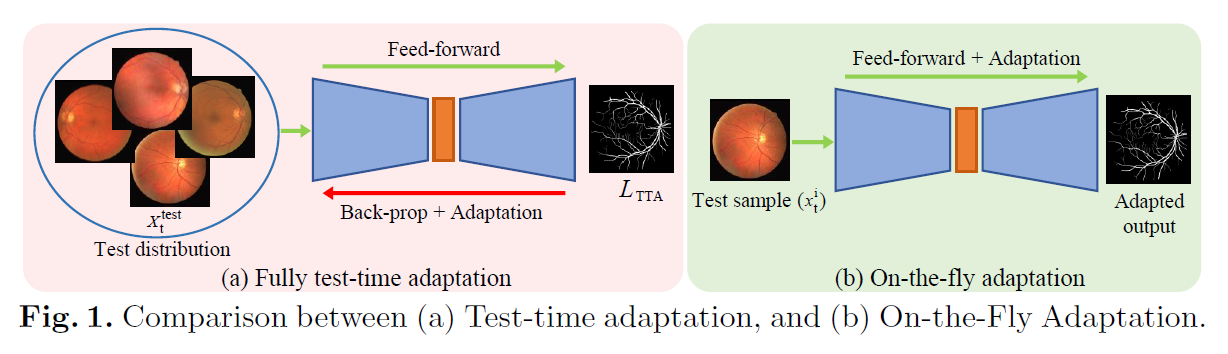
比起假设我们有一整个Xt test 我们假设我们只有一个在临床部署中的数据实例 Xti。这使得即时适应具有偶然性,因为它重置为初始权重以适应每个数据实例。同时我们限制在test-phase中的反向传播,因为它在测试过程中需要算力或者云端资源,这使得即时适应归零,因为它在测试期间不涉及任何梯度反向传播。
好奇怪啊,这可怎么训练
贡献
1)我们引入了更接近现实世界临床场景的实时适应,其中适应是zero-shot 和偶发的,消除了测试阶段完整目标分布和反向传播的可用性假设。
2)我们提出了一种新的框架adaptive - unet,它利用域代码和自适应批处理归一化来学习适应新的测试数据实例。
3)我们验证了我们的方法在二维眼底图像和三维MRI体积的医学图像分割中的9个域移位,我们得到了比最近的测试时间适应方法更好的性能。
方法

Network Details
我们用的是Unet结构。编码器和解码器分别有五个卷积模块,
编码器中的每个卷积块由一个卷积层、自适应批归一化 adaptive batch normalization、ReLU激活和最大池化层组成。
解码器中的每个卷积块由一个卷积层、自适应批归一化 adaptive batch normalization、ReLU激活和上采样层组成。上采样我们使用的是双线性插值。
3d实验我们使用的是3D UNet ,2d卷积换成3d卷积,2d最大池化换成3d最大池化,双线性插值换成三线性插值。
Adaptive Batch Normalization
这里有点疑问就是bn的想法会不会和前面看的综述有点冲突?
批归一化(Batch Normalization, BN)层[16]用于DNNs,以缓解内部协变量移位的问题。它归一化网络中的特征以帮助训练和更快的收敛。
BN可以被定义为↓,其中 x是输入 batch, z是输出, µ 是E[X]的平均值,σ是 标准差![]() ,这里γ和β都是可学习参数在正规化时控制缩放和移动
,这里γ和β都是可学习参数在正规化时控制缩放和移动
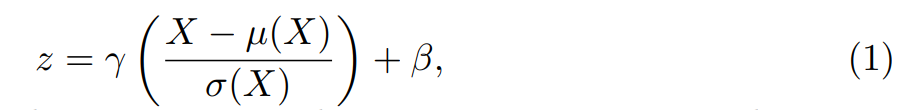
Adaptive Instance normalization (AdaIN),用于对齐两个特征代码的平均值和标准偏差(通常一个是context,另一个是style)。AdaIN被定义如下↓,其中x和y是两个特征码,z是归一化输出
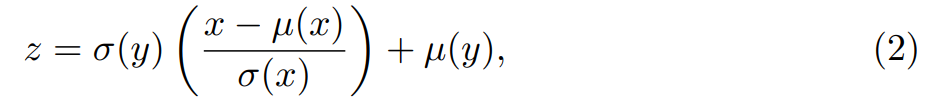
在我们的Adaptive Unet中,我们用Adaptive Batch Normalization (AdaBN), 它基本上学习缩放和移动操作,同时自适应地规范化两个代码之间的批统计信息。AdaBN可定义为:

请注意,我们的公式与[20]中解释的AdaBN有点不同,因为它试图将模型转移到测试数据的均值和标准差,而不是对齐它们。在这里,我们对齐代码,同时也学习如何通过学习移位和缩放参数来对齐它们。在Adaptive UNet中,AdaBN层的输入是来自UNet的feature code,表示为X,域代码Y由domain prior generator生成。
Domain Prior Generator
域先验发生器(DPG)是一种预训练自编码器的编码器。我们首先将UNet作为医学图像的自编码器进行预训练.这个任务是自监督的,因为我们只是试图预测原始图像,同时提供增强版本的数据作为输入。这样做有助于模型在latent space 中学习抽象代码。我们在由不同模态组成的各种医疗数据上训练模型..我们确保我们进行实验来验证自适应UNet的数据分布不会与自编码器训练的数据重叠。然而,它确实有类似模态的数据。这有助于编码器为不同模态生成不同的域码。例如,T1 MRI的两幅图像与T1 MRI和T2 MRI相比,其对应的域代码在latent space中更接近。
Training source model
在源模型的训练阶段,我们将输入图像同时提供给UNet的编码器和预训练的domain prior generator。从domain prior generator获得的域码被传递到编码器和解码器中的AdaBN层。使用AdaBN根据域代码对特征映射进行归一化。
因此,在训练过程中,模型已经学会了适应当前模态/分布的域代码。AdaBN层的可学习参数γ和β学习适应每一层风格代码所需的scale和shift,以提供最佳的分割预测。注意,权重仅针对UNet分段网络更新。预训练的域先验生成器在训练源模型期间被冻结。
Inference on target data instance
当在Xs train上训练的模型在目标数据实例xt上得到验证时,我们将图像xt传递给域先验生成器和源模型。首先,我们使用域先验生成器为新图像xt生成新的域代码。接下来,我们将此域代码传递给Adaptive UNet中的所有AdaBN层。在前馈过程中,自适应UNet每层提取的特征都适应于新的域代码.因此,模型可以根据新模态/目标域的代码进行调整。由于前馈本身已经适应了特征,因此不涉及反向传播。同样,由于模型权重没有改变,这个框架是偶然性episodic的,并且不依赖于验证的整个测试数据分布。
实验
数据集
2D:
CHASE [10],
RITE [14] ,
HRF[23]
对于二维实验,DPG是对来自[1]的眼底图像进行预训练的
3D:
BraTS
对于MRI实验,我们在Kaggle MRI数据集[2]和IXI数据集的MRI图像上预训练DPG
实现细节
框架:Pytorch
损失函数:
2d:
binary cross entropy (BCE) 和dice loss
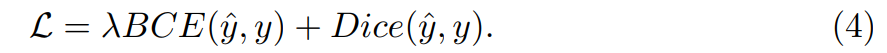
优化器:
Adam lr:0.0001(这个损失函数也太小了吧)动量:0.9
我们还使用了最小学习率高达0.00001的余弦退火学习率调度程序。
batchsize:8
3d:
我们使用类似的损失,但使用0.001的学习率,同时将批大小减少到2。
实验结果
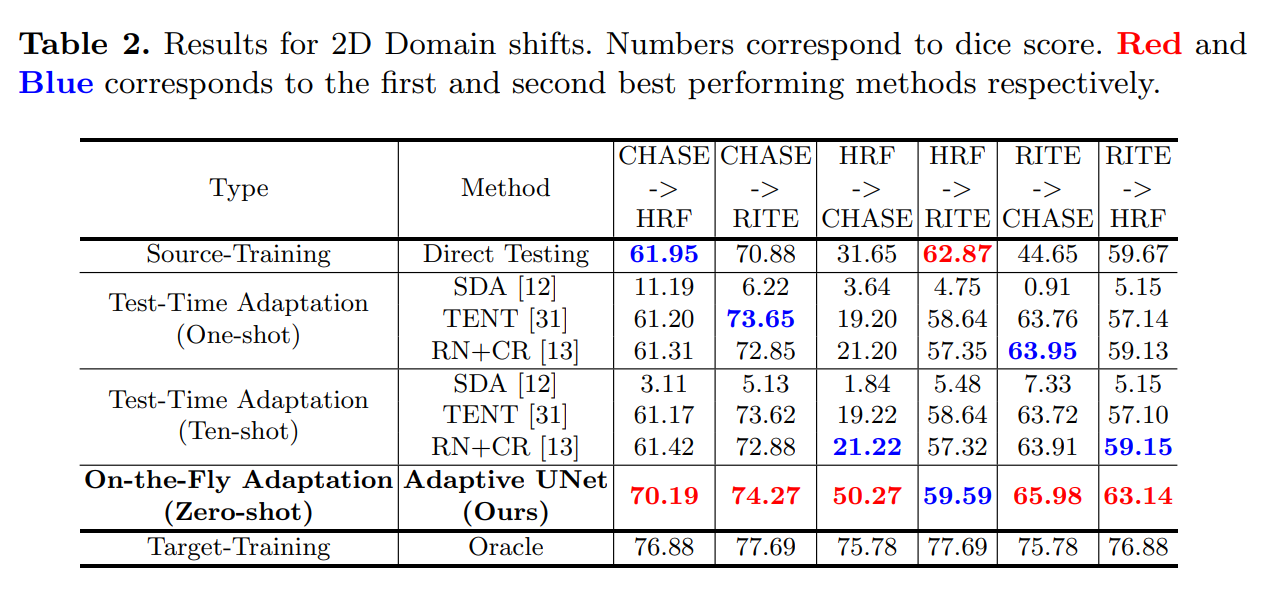

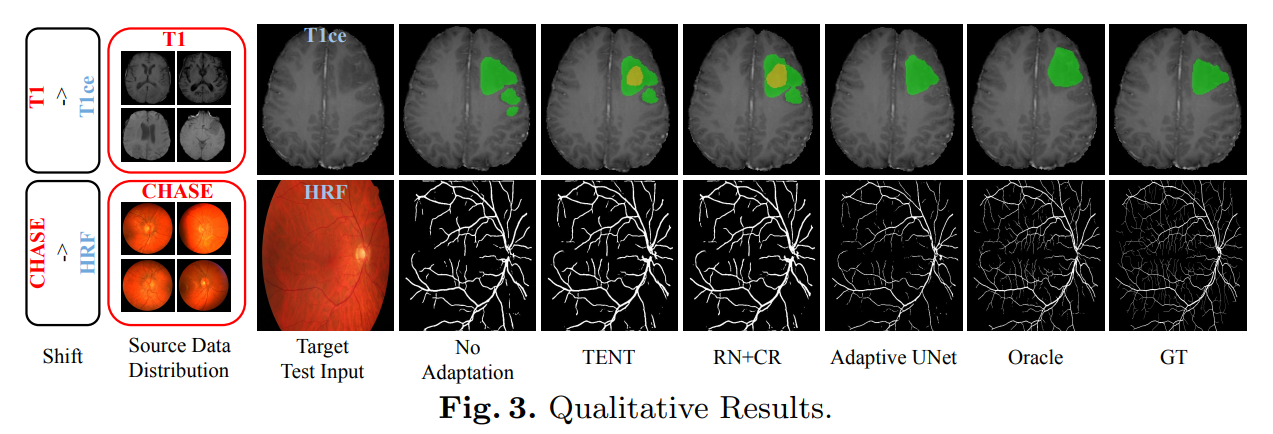
总结
在这项工作中,我们提出了一种新的适应设置,称为On-the-Fly adaptation。在这种情况下,我们将自适应约束为偶发性和零射击,从而假设在测试期间整个目标分布和模型更新不可用。这使得在现实世界的临床环境中部署深度学习模型时,实时适应非常接近场景。我们提出了一个新的框架——Adaptive UNet,利用自适应批归一化和域先验来解决这一自适应问题。我们在眼底图像和MRI体积的2D和3D域位移上验证了我们的模型,并表明即使在更严格的实时适应约束下,所提出的方法也比最近的测试时间适应方法具有竞争力。
这篇关于用于医学分割的实时Test-time adaption的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






