本文主要是介绍基于PaddleDetection的品牌logo目标相似度检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 背景介绍
在现如今的时代,对于logo的设计是每一家商店的独家标志,但是这些标志有时候只要稍作修改人们往往都不易察觉。这时我们可以通过使用相似度检测捕捉logo的特征从而判断自家商店的logo是否被侵犯了知识产权。通过这个项目我们可以及时对近似商标提出异议以免对自身品牌造成不良影响。

1. 数据集介绍
我们的项目使用的是商品logo数据集,其中有50类商品,训练集中有3500张图片,测试集中有7500张测试图片,划分的类别有50种不同的商品logo图标,使用的是coco数据集,所以标注所在的文件都是json文件,如果有你想要更改的标注将json文件下载下来进行更改后进行替换。
执行解压后数据集为:
–work/data/train 训练集
–work/data/val 测试集
而在这之中images中存放的图片为.jpg格式的图片,而annotations文件夹中是作为json文件标注数据存放地。
2. 模型介绍
2.1 ppyoloe的介绍:
详情可参考https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/configs/ppyoloe/README_cn.md
PP-YOLOE是基于PP-YOLOv2的单阶段Anchor-free模型,超越了多种流行的yolo模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免使用诸如deformable convolution或者matrix nms之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。
PP-YOLOE-l 在 COCO test-dev 上精度可达 51.4%,在 V100 上使用 TRT FP16 进行推理,速度可达 149.2FPS,相较于YOLOX-l精度提升 1.3 AP,速度提升 24.96%;相较于YOLOv5-x精度提升 0.7AP,TRT-FP16 加速 26.8%;相较于PP-YOLOv2精度提升 1.9 AP,速度提升 13.35%。

目前YOLOX以50.1达到了速度和精度的最佳平衡,V100上测试可达68FPS,是当前YOLO系列网络的集大成者,YOLOX引入了先进的动态标签分配方法,在精度方面显著优于YOLOv5,受到YOLOX的启发,作者进一步优化了之前的工作PP-YOLOv2。在PP-YOLOv2的基础上提出YOLOE,该检测器避免使用deformable convolution和matrix nms等运算操作,能在各种硬件上得到很好的支持。
2.2 结果展示

3. 模型架构
下面我们来看看pp-yoloe的模型架构并且简单介绍下其中的内容:

PP-YOLOE由以下方法组成:
可扩展的backbone和neck
Task Alignment Learning
Efficient Task-aligned head with DFL和VFL
SiLU激活函数
3.1 RepVGG
RepVGG,这个网络就是在VGG的基础上面进行改进,主要的思路包括:
在VGG网络的Block块中加入了Identity和残差分支,相当于把ResNet网络中的精华应用 到VGG网络中;
模型推理阶段,通过Op融合策略将所有的网络层都转换为3×3卷积,便于网络的部署和加速。
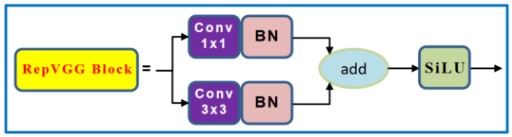
为什么要用VGG式模型?
3×3卷积非常快。在GPU上,3×3卷积的计算密度(理论运算量除以所用时间)可达1×1和5×5卷积的4倍。
单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
RepVGG主体部分只有一种算子:3×3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价可以集成海量的3×3卷积+ReLU计算单元来达到很高的效率。
3.2 CSPNet结构:
CSPNet的主要思想还是Partial Dense Block,设计Partial Dense Block的目的是:
增加梯度路径。
平衡各层的计算。
减少内存流量。
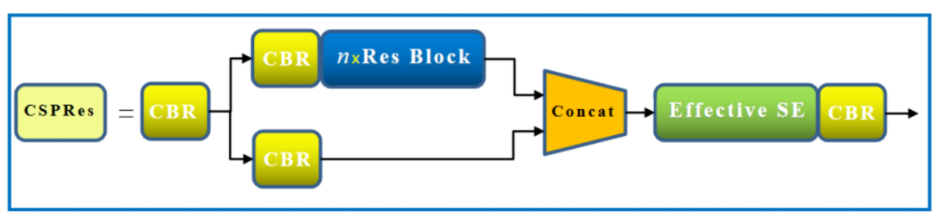
CSPNet的提出解决了以下问题:
强化 CNN 的学习能力:现有 CNN 网络一般在轻量化以后就会降低效果,CSPNet 希望能够在轻量化的同时保持良好的效果。CSPNet 在嵌入分类任务的 ResNet、ResNeXt、DenseNet 等网络后,可以在保持原有效果的同时,降低计算量 10%~20%
移除计算瓶颈:过高的计算瓶颈会导致推理时间更长,在其计算的过程中其他很多单元空闲,所以作者期望所有的计算单元的效率差不太多,从而提升每个单元的利用率,减少不必要的损耗。
减少内存占用:CSPNet 使用 cross-channel pooling 的方法来压缩特征图
3.3 SPP结构
SPP-Net全名为Spatial Pyramid Pooling(空间金字塔池化结构),2015年由微软研究院的何恺明提出,主要解决2个问题:
有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题。
解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
SPP 显著特点
不管输入尺寸是怎样,SPP 可以产生固定大小的输出
使用多个窗口(pooling window)
SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
其它特点
由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
不仅可以用于图像分类而且可以用来目标检测
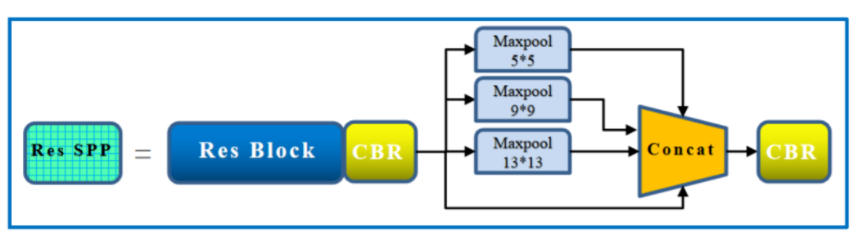
通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。
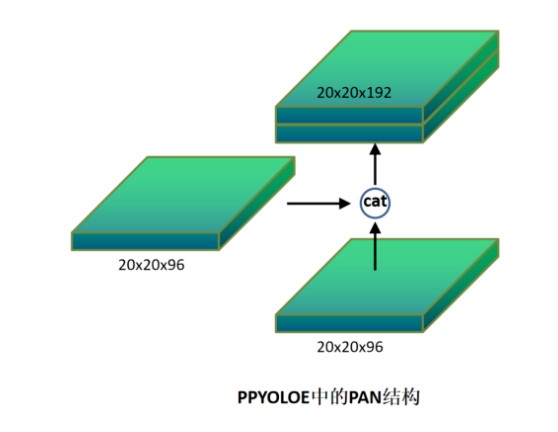
3.4 neck结构
yoloe的neck结构采用的依旧是FPN+PAN结构模式,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。和FPN层不同,yoloe在FPN层的后面还添加了一个自底向上的特征金字塔。FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递,而本文就是针对这一点,在FPN的后面添加一个自底向上的金字塔。这样的操作是对FPN的补充,将低层的强定位特征传递上去。
3.5 head结构
对于PP-YOLOE的head部分,其依旧是TOOD的head,也就是T-Head,主要是包括了Cls Head和Loc Head。具体来说,T-head首先在FPN特征基础上进行分类与定位预测;然后TAL基于所提任务对齐测度计算任务对齐信息;最后T-head根据从TAL传回的信息自动调整分类概率与定位预测。
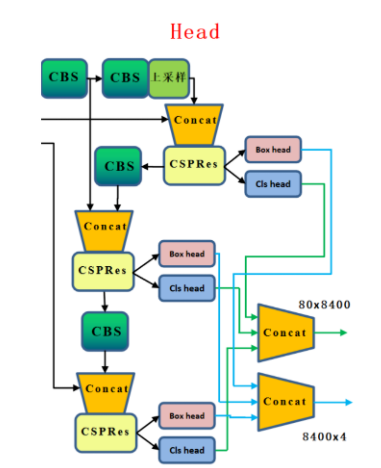
由于2个任务的预测都是基于这个交互特征来完成的,但是2个任务对于特征的需求肯定是不一样的,因为作者设计了一个layer attention来为每个任务单独的调整一下特征,可以理解为是一个channel-wise的注意力机制。这样的话就得到了对于每个任务单独的特征,然后再利用这些特征生成所需要的类别或者定位的特征图。
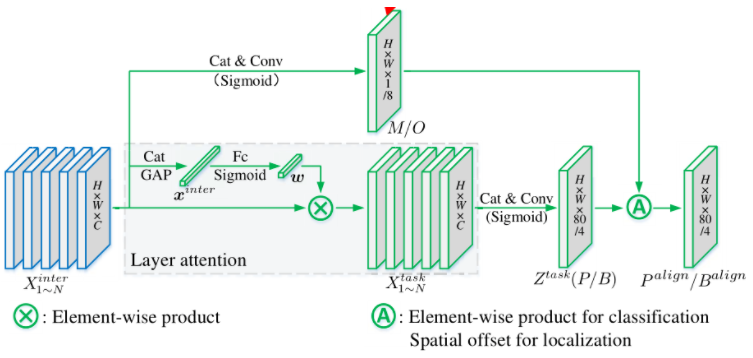
3.6 pp-yoloe+改进之处
精度
首先,我们使用Objects365大规模数据集对模型进行了预训练。Objects365数据集含有的数据量可达百万级,在大数据量下的训练可以使模型获得更强大的特征提取能力、更好的泛化能力,在下游任务上的训练可以达到更好的效果。
其次,我们在RepResBlock中的1x1卷积上增加了一个可学习的权重alpha,进一步提升了backbone的表征能力,获得了不错的效果提升。最后,我们调整了NMS的参数,在COCO上可以获得更好的评估精度。
训练速度
基于Objects365的预训练模型,将学习率调整为原始学习率的十分之一,训练的epoch从300降到了80,在大大缩短了训练时间的同时,获得了精度上的提升。
端到端推理速度
我们精简了预处理的计算方式,由于减均值除方差的方式在CPU上极其耗时,所以我们在优化时直接去除掉了这部分的预处理操作,使得PP-YOLOE+系列模型在端到端的速度上能获得40%以上的加速提升。
下游泛化性增强
我们验证了PP-YOLOE+模型强大的泛化能力,在农业、低光、工业等不同场景下游任务检测效果稳定提升。
ppyoloe+模型效果:
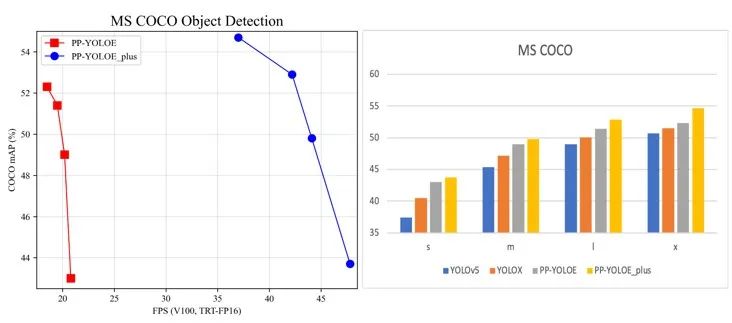
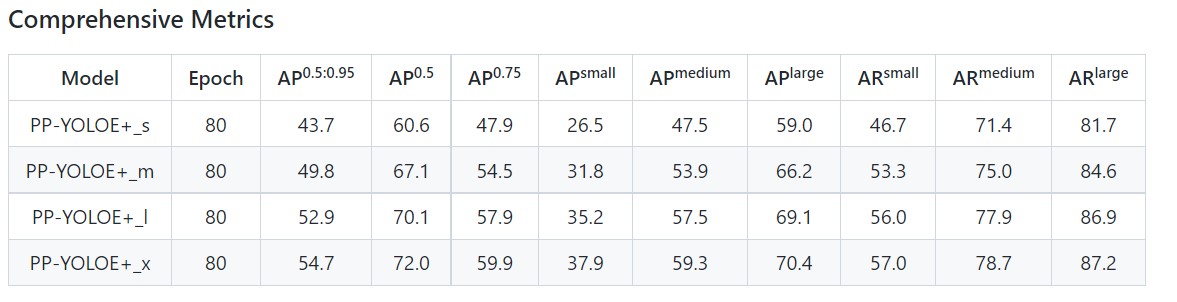
3.7 模型精度展示

原文参考:https://www.eet-china.com/mp/a120559.html
https://blog.csdn.net/jiaoyangwm/article/details/80011656/
https://blog.csdn.net/PaddlePaddle/article/details/127258643
4. 配置环境
下载自己所需环境
!pip install pycocotools
!pip install mmcv
!pip install -U seaborn
!pip install paddlepaddle-gpu
!pip install paddlex
判断是否能使用cuda(因为有一次我老是报ValueError: The device should not be ‘gpu‘, since PaddlePaddle is not compiled with CUDA,后来才发现那个环境没连上cuda,又新创建了一个项目才好)
import paddle
import os
import numpy as np
import cv2
import matplotlib.pyplot as plt
import random
import pycocotools
import os.path as osp
from PIL import Image
import glob
import mmcv
paddle.fluid.is_compiled_with_cuda()
4.1 将数据集解压到特定的文件中
if not os.path.exists("/home/aistudio/work/data"):! unzip -oq data/data151249/fewshotlogodetection_round2_test_202205.zip -d work/data! unzip -oq data/data151249/fewshotlogodetection_round2_train_202205.zip -d work/data! unzip -oq data/data151249/fewshotlogodetection_round1_train_202204.zip -d work/data! unzip -oq data/data151249/fewshotlogodetection_round1_test_202204.zip -d work/data
将训练集转移到一个特定的文件夹中,这样更方便查看
if not os.path.exists("MyDataset"):!mkdir MyDataset%cd!cp -r work/data/train/images MyDataset/JPEGImages!cp work/data/train/annotations/instances_train2017.json MyDataset/annotations.json
/home/aistudio
4.2 划分训练集
因为这里数据集只有训练集才进行了标注,所以我将训练集划分为训练集和验证集,将验证集作为测试集

在数据集按照上面格式组织后,使用如下命令即可快速完成数据集随机划分,其中val_value表示验证集的比例,test_value表示测试集的比例(可以为0),剩余的比例用于训练集。(因为我们之前已经划分过了,所以这里直接运行即可)
from pycocotools.coco import COCO
!paddlex --split_dataset --format COCO --dataset_dir MyDataset --val_value 0.1 --test_value 0
4.3 复制PaddleDetection文件
if not os.path.exists("/home/aistudio/PaddleDetection"):!git clone https://gitee.com/paddlepaddle/PaddleDetection -b release/2.5
4.4 下载PaddleDetection所需环境
%cd PaddleDetection
!pip install -r requirements.txt
# GPU训练 支持单卡,多卡训练,通过CUDA_VISIBLE_DEVICES指定卡号
%env CUDA_VISIBLE_DEVICES=0
%cd ..
5. 配置PaddleDetection
5.1 进入PaddleDetection/configs/datasets/coco_detection.yml
我的配置是这样的

(不知道为什么不复制完整路径就报错)
5.2 ppyoloe文件的使用和配置
数据集根路径dataset_dir
图片文件夹image_dir
标注文件路径anno_path
我这里使用的是/home/aistudio/PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml
进入文件
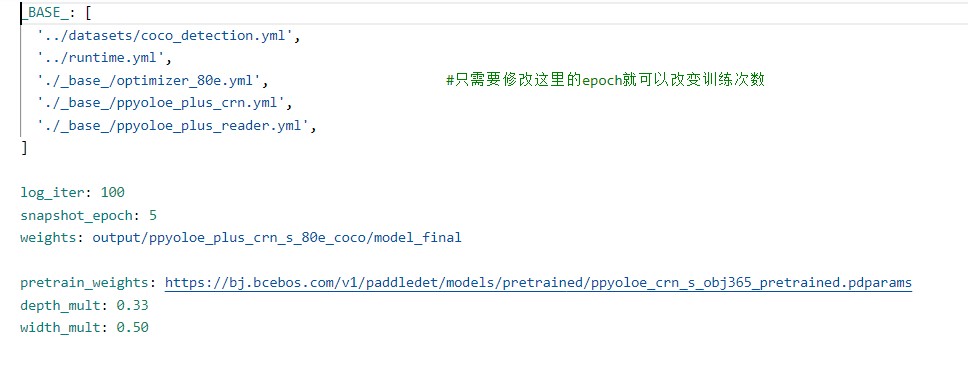
根据指示前往/home/aistudio/PaddleDetection/configs/ppyoloe/base/optimizer_80e.yml
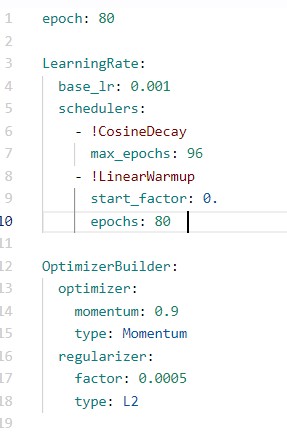
修改epoch为自己需要的。
在yolo系列模型中,可以运行tools/anchor_cluster.py来得到适用于你的数据集Anchor,使用方法如下:
#生成anchor
%cd /home/aistudio/PaddleDetection
!python tools/anchor_cluster.py -c /home/aistudio/PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml -n 9 -s 608 -m v2 -i 1000
%cd ..
6. 开始运行
6.1 训练文件
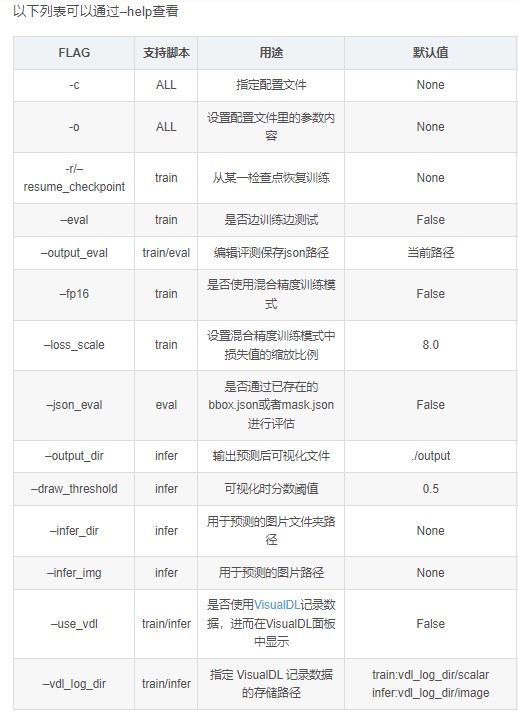
训练参数设置可参考下图:
%cd ~/PaddleDetection/
!python -m paddle.distributed.launch --gpus 0 tools/train.py \-c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml \--use_vdl=true \--vdl_log_dir=vdl_dir/scalar \--eval \-o output_dir=output/ppyoloe_s_plus_80e\snapshot_epoch=2\lr=0.001 \--amp
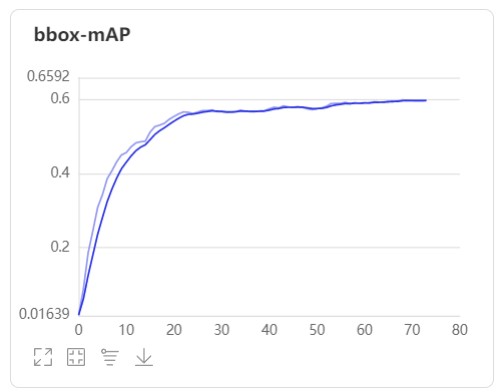
我们可以进入左边可视化界面在设置logdir中选择添加,找到PaddleDetection/vdl_dir中的scalar文件夹,添加进去,之后启动VisualDL服务就可以看到可视化图了。
数据可视化如下:
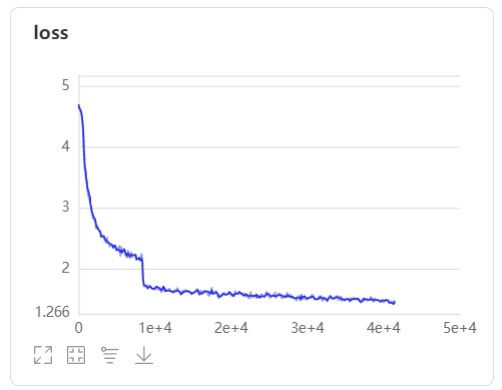
如果训练模型时报了UnicodeEncodeError: ‘latin-1‘ codec can‘t encode characters in position: ordinal not in range(256)这种错误,我建议是将work/data中train和val中的annotations中的json文件全部下载下来,将其中的中文标注全部改为英文,因为我上网搜到的资料是因为中文无法解码造成的错误,而我在改为英文标注后确实不再报错了。注意:在更改后将MyDataset文件删除在重新建立并划分数据集。

6.2 评估模型
设置-o weights指定模型路径,这里我们使用训练出来的最好的模型进行评估
结果展示:
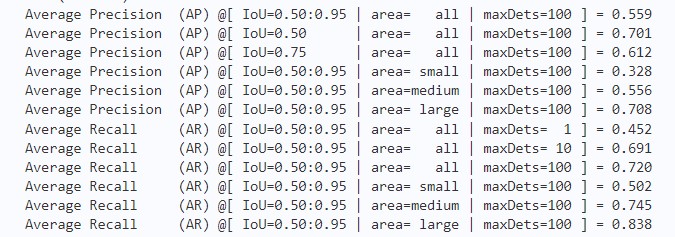
!python -u /home/aistudio/PaddleDetection/tools/eval.py \-c /home/aistudio/PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml \-o weights=/home/aistudio/PaddleDetection/output/ppyoloe_plus_crn_s_80e_coco/best_model.pdparams
6.3 导出模型
!python -u /home/aistudio/PaddleDetection/tools/export_model.py \-c /home/aistudio/PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml \--output_dir=/home/aistudio/inference_model \-o weights=/home/aistudio/PaddleDetection/output/ppyoloe_plus_crn_s_80e_coco/best_model.pdparams6.4 推理测试集
(结果展示)


%cd ~/PaddleDetection/
!python tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml \--infer_dir=/home/aistudio/MyDataset/JPEGImages \--output_dir=infer_output/ \-o weights=/home/aistudio/PaddleDetection/output/ppyoloe_plus_crn_s_80e_coco/best_model.pdparams \--draw_threshold=0.5 \--save_results=True \
7. 结语
通过这次我们学习了PaddleDetection的使用方法和pp-yoloe的模型架构,后续如果想对该模型进行优化建议先将模型复现之后对其中的架构进行优化,也可以通过改变学习率和批量大小进行优化。
通过这一次的实验,我们成功实现了使用ppyoloe对品牌logo的检测,你有没有引起对PaddleDetection的兴趣呢?
我下一步希望实现自己手搭网络模型实现训练数据集(当然,是先学会用别人的模型,再自己手搭)
学员:廖咏波
导师:顾茜
8. 参考项目
- Group35
- 『PPYOLO tiny尝鲜』基于PaddleDetection的人脸疲劳检测
此文章为搬运
[原项目链接].(https://aistudio.baidu.com/aistudio/projectdetail/5297912)
这篇关于基于PaddleDetection的品牌logo目标相似度检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






