本文主要是介绍更新至2023年各省环境规制数据合集(七种测算方法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更新至2023年各省环境规制数据合集(七种测算方法)
一、2002-2023年全国各省ZF报告词频环境规制关键词词频统计数据
1、时间:2001-2022年
2、指标:文本总长度、仅中英文-文本总长度、文本总词频-全模式、文本总词频-精确模式、环境规制力度词频和、环境保护、环保、污染、能耗、减排、排污、生态、绿色、低碳、空气、化学需氧量、二氧化硫、二氧化碳、PM10、PM2.5
3、来源:ZF工作报告
4、方法说明:借助Python软件对政府工作报告进行分词处理,分别统计了2002-2023省级政府工作报告中与环境规制相关的关键词的词频。
5、参考文献:
雾霾污染 、 政府治理与经济高质量发展(陈诗一,陈登科)
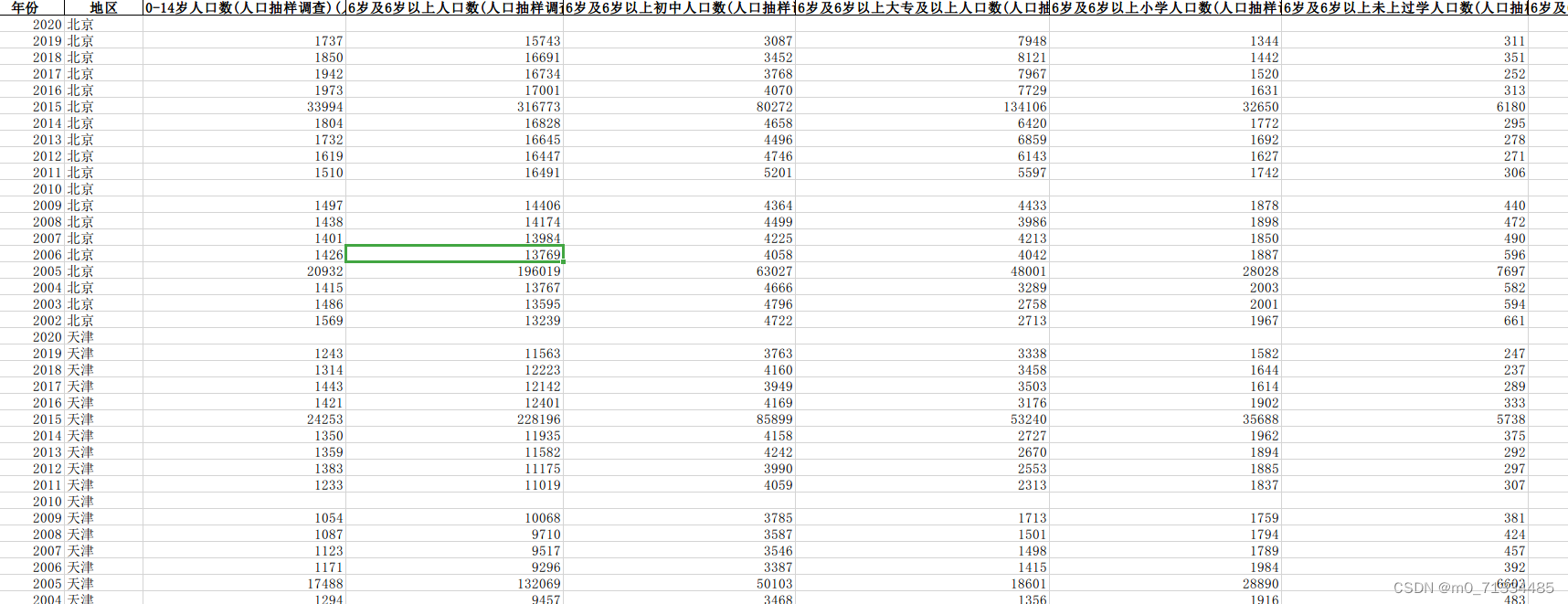
二、2002-2020年全国各省非正式环境规制水平数据
1、时间:2002-2020年
2、指标:14岁人口数(人口抽样调查)、人口数(人口抽样调查)、城镇单位在岗职工平均工资、常住人口密度、6岁及6岁以上人口数(人口抽样调查)、6岁及6岁以上小学人口数(人口抽样调查)、6岁及6岁以上未上过学人口数(人口抽样调查)、6岁及6岁以上初中人口数(人口抽样调查)、6岁及6岁以上高中人口数(人口抽样调查)、6岁及6岁以上大专及以上人口数(人口抽样调查)、收入水平、受教育水平、人口密度、年龄结构、非正式环境规制水平
3、方法说明:借鉴PargalandWheeler的方法,选取收入水平、受教育程度、人口密度和年龄结构等一系列指标用熵权法综合度量各地区的非正式规制强度。
4、来源:统计年鉴、国家统计局
5、参考文献:环境规制的产业结构调整效应研究—基于中国省际面板数据的实证检验(原毅军,谢荣辉)
三、2005-2019年各省行政型环境规制(GER)数据
1、时间:2005-2019年
2、指标:年份、省份、行政处罚案件数量
3、方法说明:以行政处罚案件数量来衡量环境规制
四、2005-2019年各省公众型环境规制(PER)数据
1、时间:2005-2019年
2、来源:环境年鉴
4、指标:省份、时间、环保来信举报
5、范围:31省
6、方法说明:以信访综述和环保来信的数量来衡量环境规制
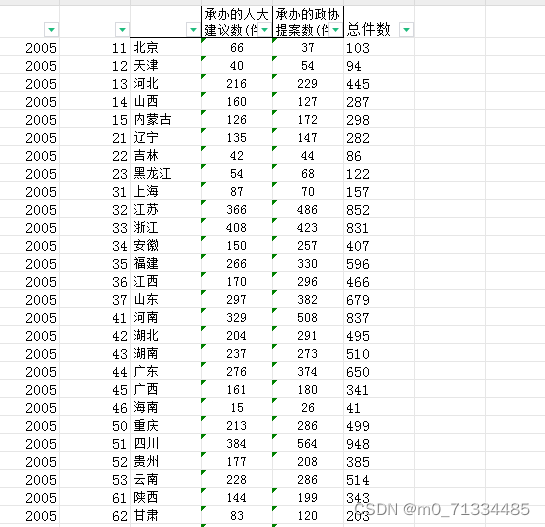
五、2005-2019年全国各省环境规制水平数据
1、时间:2005-2019年
2、来源:环境年鉴
3、指标:承办的人大建议数(件)、承办的政协提案数(件)、总件数
4、方法说明:以承办的人大建议数(件)和承办的政协提案(件)加总来衡量环境规制
5、范围:30个省市
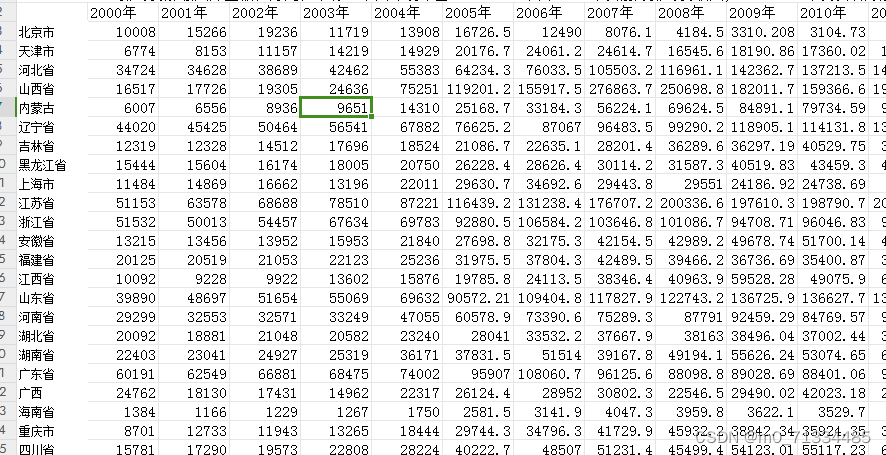
六、2000-2021年各省环境规制数据(排污费)数据
1、时间:2000-2019年
2、范围:30个省市
3、来源及指标:环境年鉴、税务年鉴(其中2006年以前为排污费收入,2007-2017年及以后为解缴入库金额;2018年-2021年为环保税金额。
4、方法说明:以排污费解缴入库金额来衡量环境规制
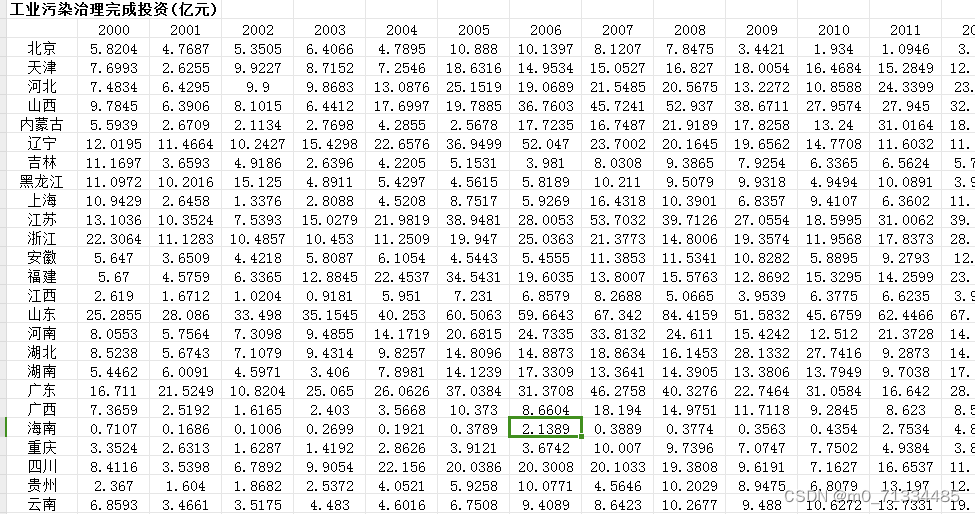
七、2000-2021年全国各省环境规制水平数据
1、时间:2000-2021年
2、来源:国家统计局、统计年鉴、环境统计年鉴
3、指标:工业污染治理完成投资(亿元)、工业增加值(亿元)、工业污染治理完成投资额/工业增加值
4、范围:30个省市
5、方法说明:参考刘荣增(2021)年对环境规制的计算方法,以工业污染治理完成投资额/工业增加值来衡量环境规制
6、参考文献:刘荣增,何春.环境规制对城镇居民收入不平等的门槛效应研究[J].中国软科学,2021,(08).
八、下载链接:
更新至2023年各省环境规制数据合集(七种测算方法)![]() https://download.csdn.net/download/m0_71334485/88775632
https://download.csdn.net/download/m0_71334485/88775632



这篇关于更新至2023年各省环境规制数据合集(七种测算方法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







