本文主要是介绍【Blog】记录一下如何让自己的自建网站让百度搜索收录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
记录一下如何让自己的自建网站让百度搜索收录
目录
- 记录一下如何让自己的自建网站让百度搜索收录
- 一、前言
- 二、开始操作
- 1、第一步:进入设置
- 2、第二步:开始设置
- 3、第三步:让百度收录我们自己的文章
- 三、知识点记录
- 1、注意事项
- 2、可能会出现的问题总结(PS:来自别的博主的经验,搬运而来)
- 四、结尾
一、前言
前端时间博主自己搭建了一个自己的Blog网站,并且已经部署到服务器上面了,感兴趣的小伙伴可以点击访问一下: 依琴の小站 。本站会长期维护,并且时不时会更新一些新的内容。
我们自己建站,相信很多人也都会遇到过,自己写的一些文章并不能被百度进行收录,导致可能明明自己写了很多优质的文章,却没办法被大家看到。博主也是遇到了一样的问题,因此呢,查了一些相关的资料,写下本文记录一下整个的操作过程。便于自己以后记忆,也希望能帮助到一些萌新玩家。
好了,接下来,我们一步一步来操作吧。
二、开始操作
1、第一步:进入设置
打开百度搜索网站:百度一下 输入自己的域名搜索一下:我们可以看到以下一个提示,这个时候,我们点击 提交网址 这个链接,会跳转到百度的一个管理页面。
想省事的小伙伴可以直接点击这个链接:https://ziyuan.baidu.com/linksubmit/url

2、第二步:开始设置
注册百度账号,相信很多小伙伴这个都有的,毕竟当年百度贴吧可是风靡一时,哈哈。注册好的小伙伴直接登入自己的百度账号即可。
登录成功之后,鼠标放到 用户中心 点击 站点管理 。

进入这个页面之后,我们直接点击添加 添加网站 按钮
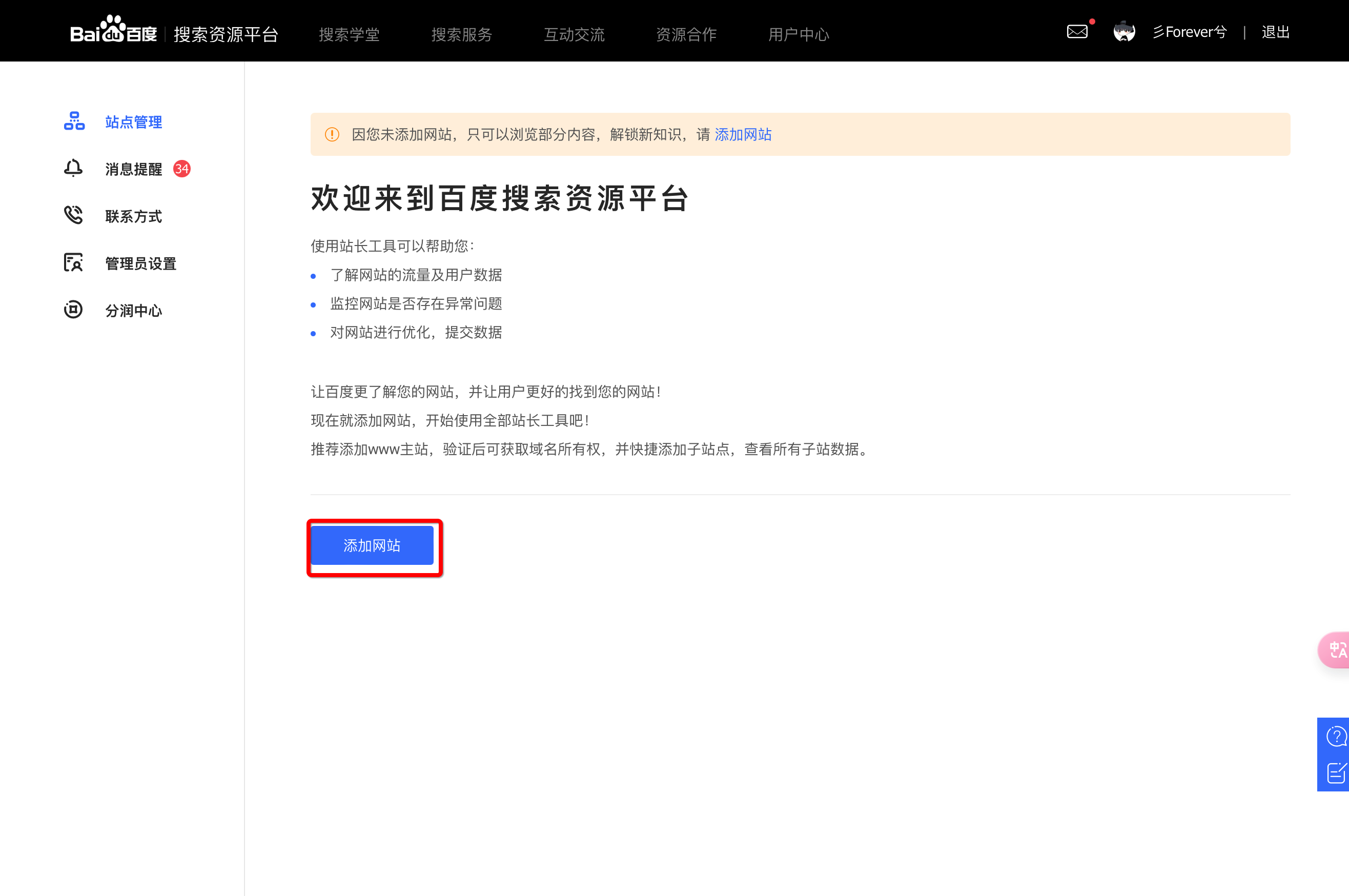
接下来我们就是根据提示一步一步的走下去即可,第一步是输入咱们自己的域名,如果是 http 的就选 http 如果是 https 就选择 https 即可,后面的建议输入 www 加自己的域名哦。
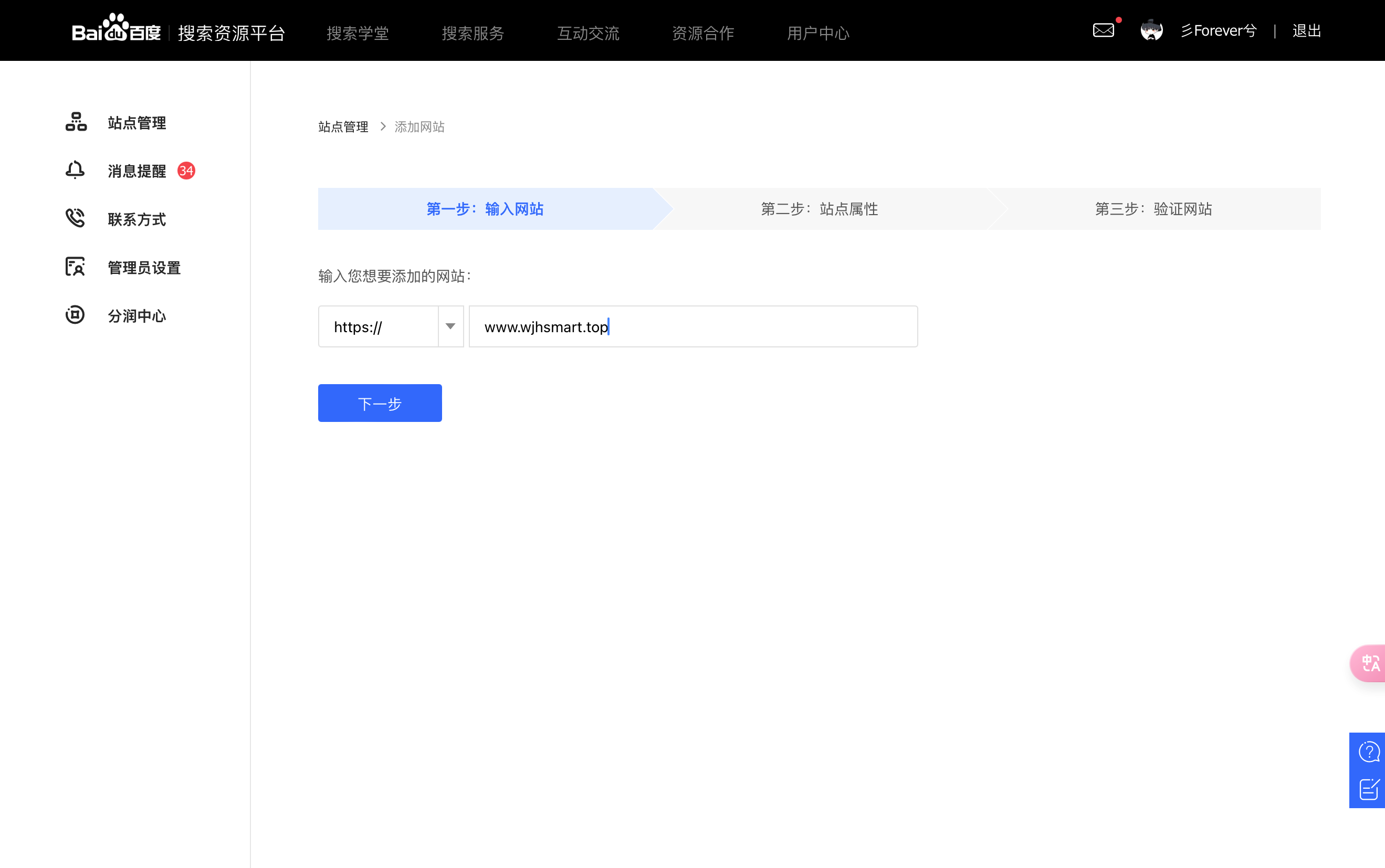
第二步选择自己站点的一个属性,大家根据自己的实际情况来选择即可。
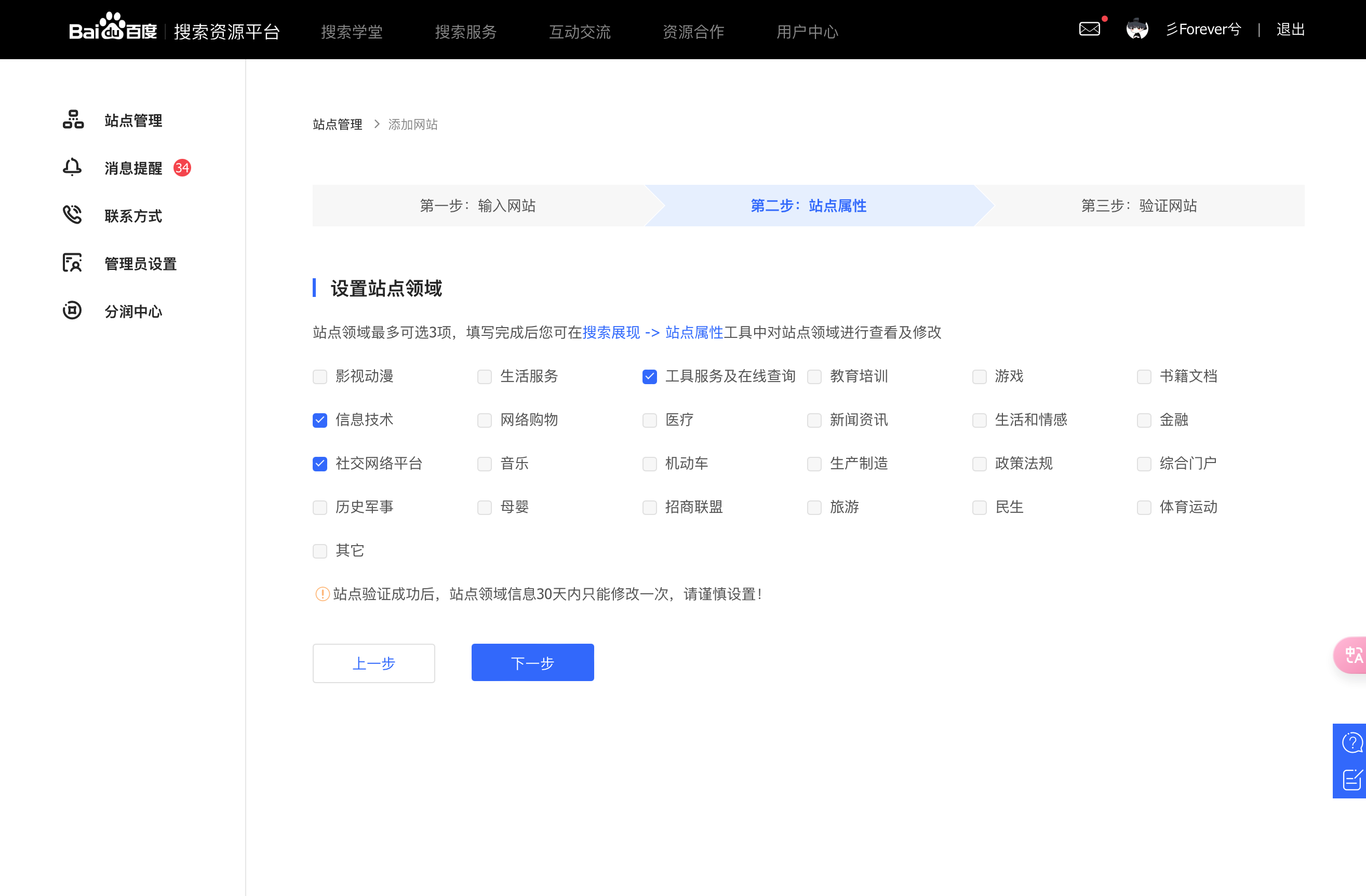
第三步是选择验证方式,大家可以根据个人喜好,看哪个方便用哪个即可,博主选择的是第二种,HTML 验证,直接把下面这段代码放到我们自己网站的头部即可。这一步呢是为了验证你本人对这个站点的所有权,以防别人随意提交一些不合规的站点进行收录,为了安全性。
<meta name="baidu-site-verification" content="换成自己的" />
PS:一定要把 content 换成自己生成的哦,每个站点都会随机生成一个唯一的码。把这段代码复制到自己的 header 标签下面后,把站点重新部署一下,一定要重新部署后再点击完成验证才可以哦。
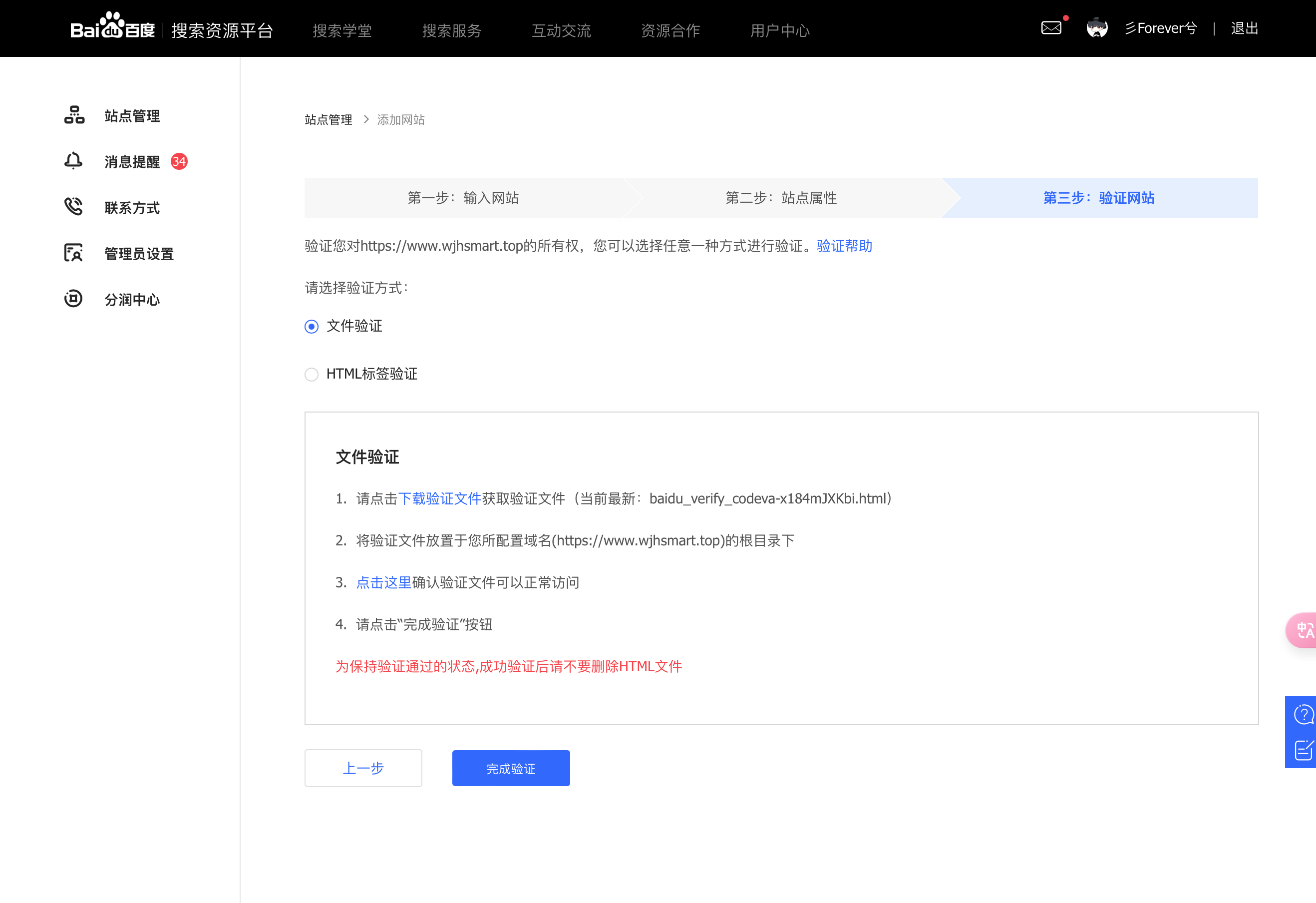
尴尬的事情发生了,忘记了我的首页做了重定向,居然验证失败了,报了个 302 错误,好吧,就当踩第一个坑了。我们来继续填坑把。
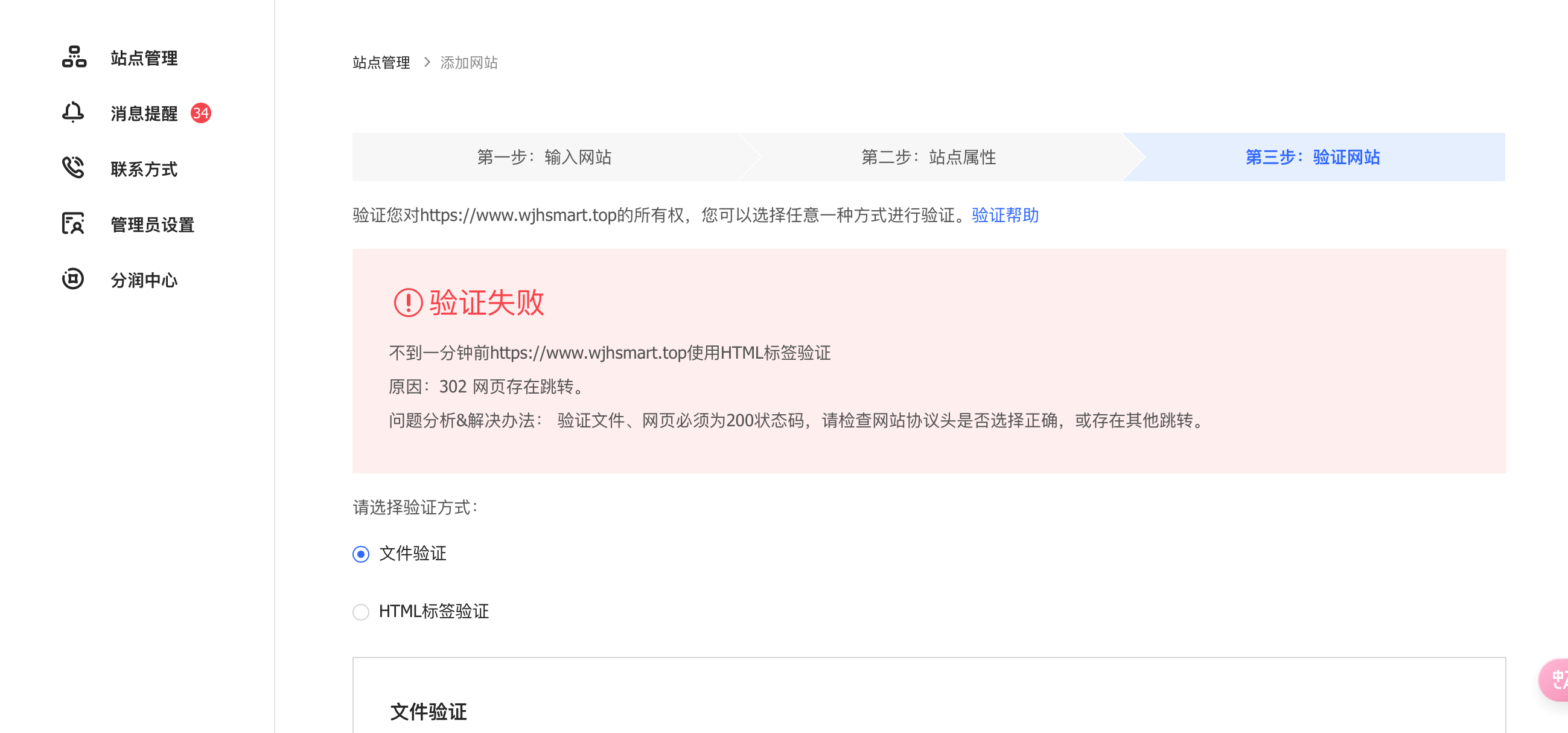
继续选择文件验证的方式,先把验证文件下载下来。上传到服务器上面配置的跟目录上面。
直到出现以下提示,则表示验证成功。
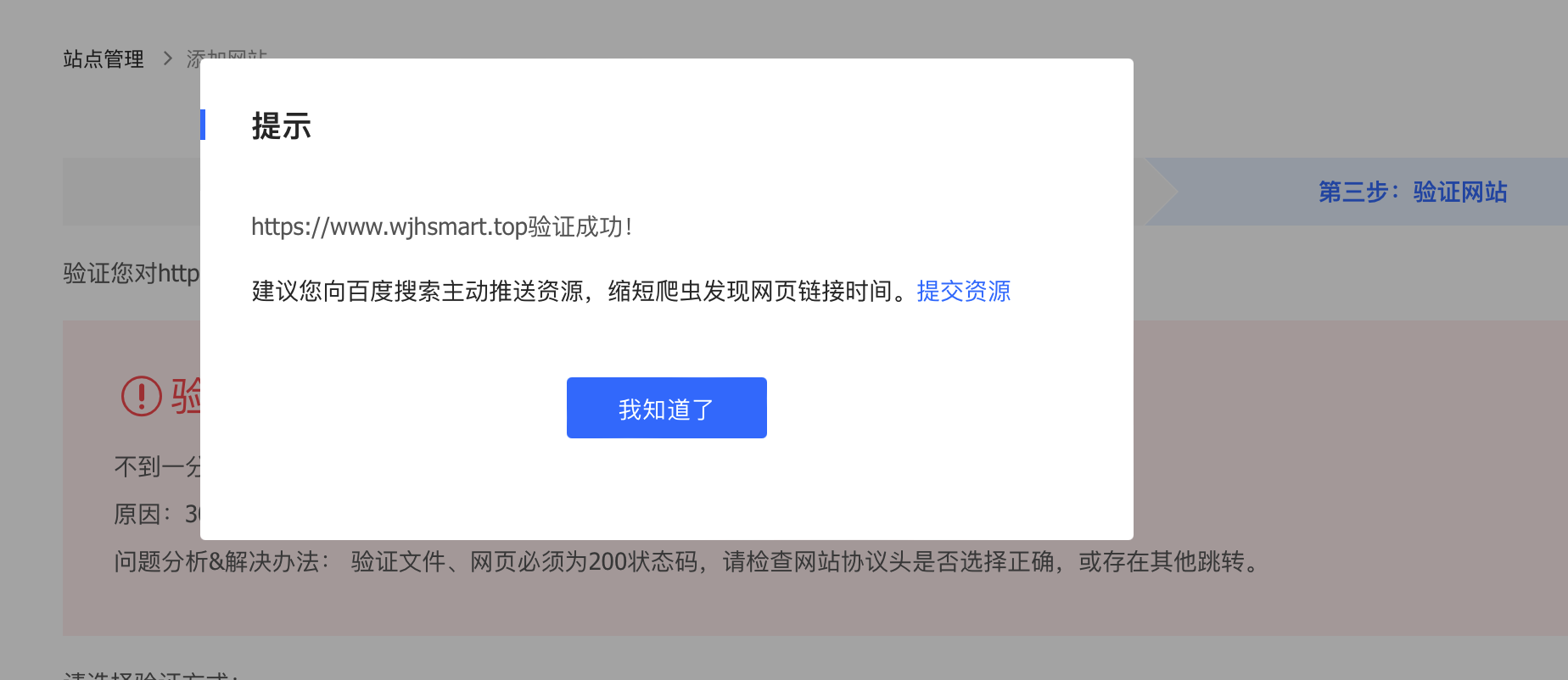
可惜博主换成文件验证方式,还是报 302 错误,百思不得其解,后来才发现是博主配置的原因,因为之前 nginx 配置了 location / {} 全部都会转发到后台项目下面。不管在浏览器输入什么都会默认转发到配置的 8080 后台项目下面,然后返回博客的首页。博主的博客用的是 若依 的 ruoyi-fast 版本,前后端一体的项目,没有做前后端分离,所以 nginx 自然也就没有配置静态资源目录了,直接把所有请求无脑转发给了后端,也就是这个问题导致了又踩了这么一个坑。如果大家的站点是前后端分离的项目,直接把验证文件放到 index.html 同级别的目录下面即可。
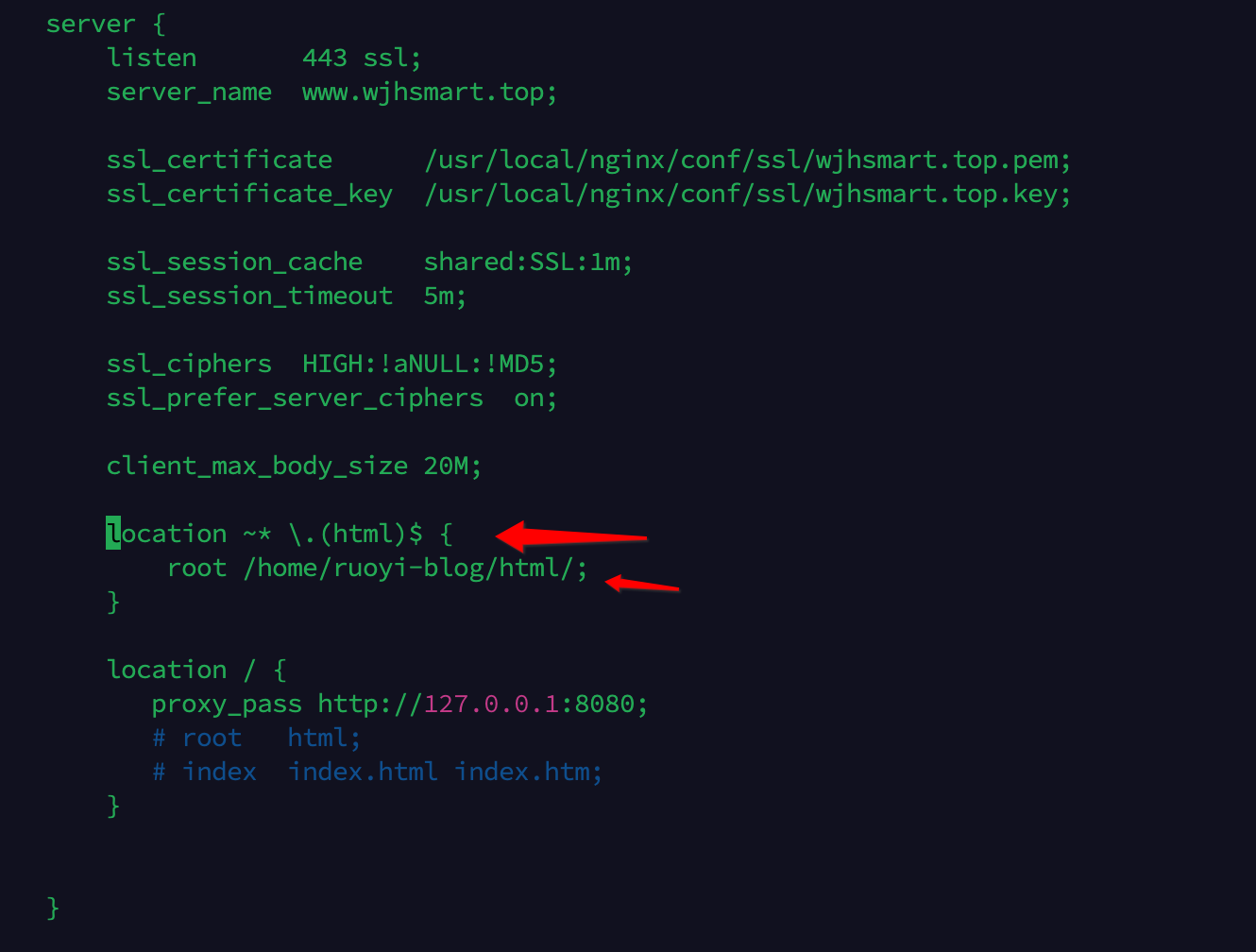
于是博主想了个取巧的方法,nginx 配置 location 配置,把验证地址直接转发到服务器的制定目录下面。
增加的这个配置表示,所有的以 html 结尾的请求,根目录都转发到当前设置的目录下面来。小伙伴们可以直接把下面代码直接复制到自己的配置文件下面即可。
/home/ruoyi-blog/html/ :替换成自己文件的目录
location ~* \.(html)$ {root /home/ruoyi-blog/html/;
}
配置如下图所示:
配置好了之后,按 ESC 输入 :wq 退出编辑模式,直接重启 nginx 服务即可。
重启命令如下所示:这个命令并不是所有人的都一样哦,这取决于当时安装 Nginx 时的方式,如果还有不会安装 Nginx 或者还没安装的小伙伴,可参考:Linux 编译安装 Nginx
/usr/local/nginx/sbin/nginx -s reload
完事之后,我们可以先点击第 3 点的 点击这里 链接进行先验证,如果出现了一串随机码,则说明验证成功,如果还是跳转到了别的页面,那就是还没配置好。
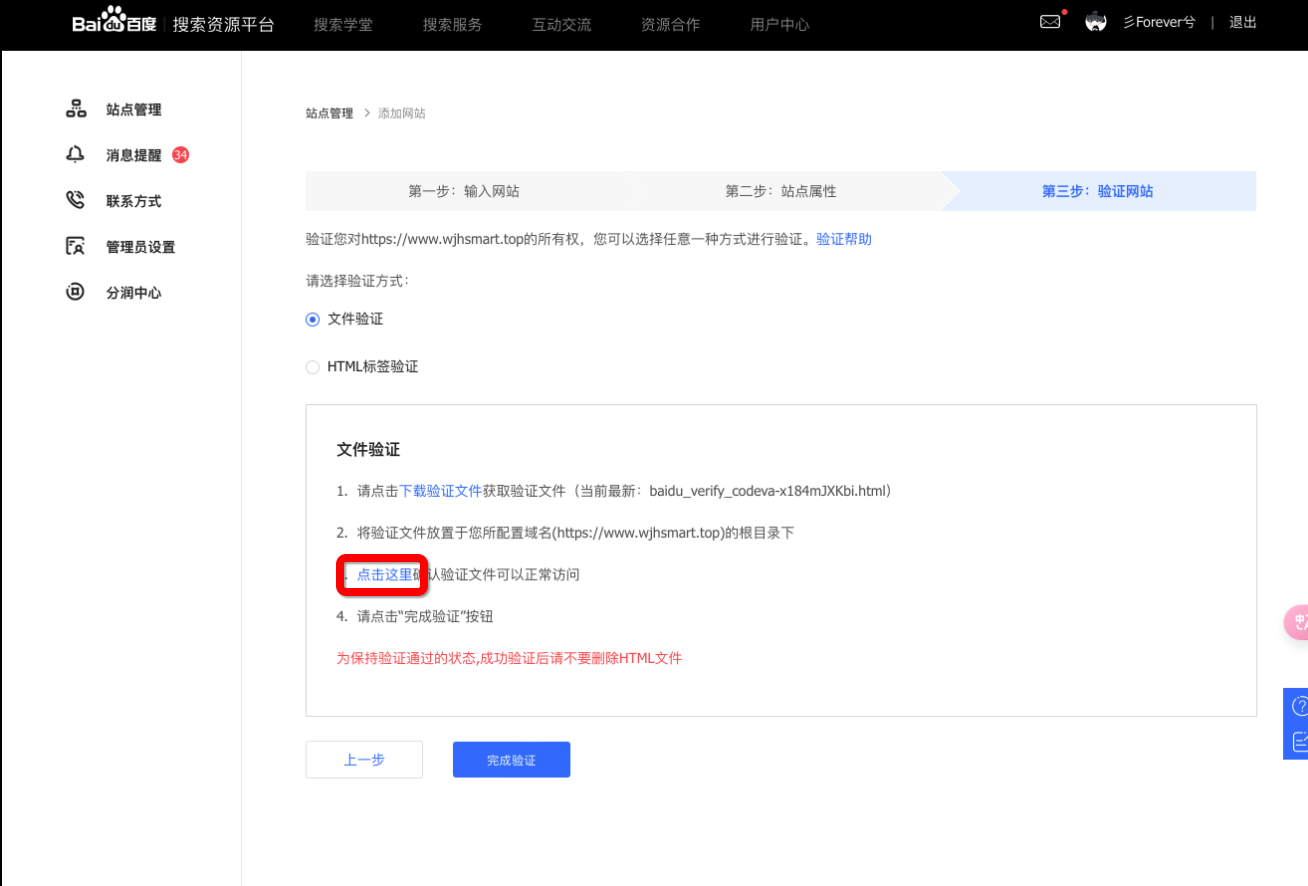
这里博主建议把不带 www 的站点也录入进去,多几个站点就多几个访问入口嘛。
3、第三步:让百度收录我们自己的文章
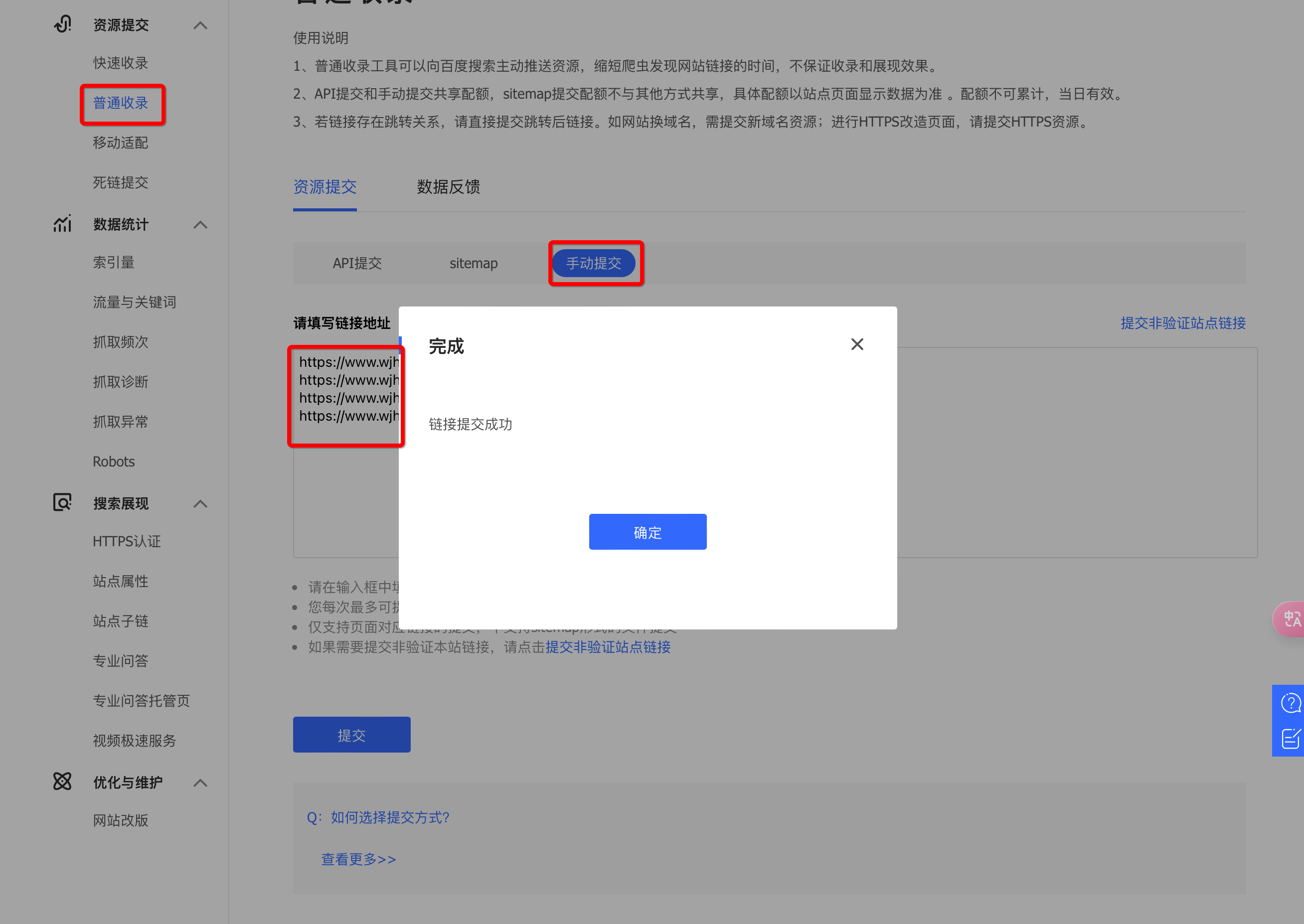
我们设置好主站点之后,还需要把我们自己的文章主动推送给百度,不然等百度的爬虫机制来抓取,不知道要抓到猴年马月去了。
点击链接 https://ziyuan.baidu.com/linksubmit/index?site=https://www.wjhsmart.top/ ,记得把域名换成自己的。
把自己的文章链接一个个的复制到输入框中。点击提交即可。
三、知识点记录
1、注意事项
- 使用百度统计的站点在搜索资源平台也要验证,统计站点批量导入功能已下线,添加网站前需完善账户信息。
- 输入需要验证的网址时,https的站点需要填写协议头,非https的站点可以不写协议头
- 站点领域信息必须填写,需填写1-3项。
- 点击完成验证的时候应该先点击一下蓝色的字:点击这里,确认验证文件可以正常访问,如能正常访问,再点击验证完成。
- 文件验证有时候也会出现验证失败的情况。使用其它任意一种方式都可以,如果是301的问题可以临时修改服务器的配置,或者使用其它任意一种验证方式。
- 如果站长已经验证了站点的主站,可以批量添加站点的子站,无需验证。
- 使用html标签验证的时候,请确保标签的content内容和验证界面提示的是相同哒。
- 如站长更换用户名验证站点的时候,文件验证:一定要重写下载验证文件进行文件验证。html验证:一定要重新添加HTML代码到网站首页。
- 站点验证成功后,验证文件或者html的代码到ziyuan.baidu.com关系不可以取消,取消会导致验证失效。
2、可能会出现的问题总结(PS:来自别的博主的经验,搬运而来)
1.找不到文件
验证文件未正确上传(未上传到网站的根目录)
解决方法: 检查根目录是否有身份验证文件;检查空间服务器是否允许百度认证;使用其他身份验证方法。
2.它卡住了
解决方法: 重新验证
其他百度站长平台验证网站常见错误及解决方案;
3.获取验证文件或网页时出错
解决方法: 请检查服务器设置或稍后再试
4.唐山网站制作数量太多
解决方案: 请检查服务器设置,看看是否设置了多次跳转。如果设置了多次跳转,请取消跳转,并尝试再次验证网站。
5.服务器检查结果为空
解决方法: 请检查服务器是否为百度做了特殊设置,或者稍后再试
6.我们无法访问您的网站
解决方法: 请检查服务器设置是否正确。可能百度已经被UAVIP封杀了。如果被禁,请解除禁令,并再次尝试验证网站。
7.找不到已验证的html标记,或者已验证的html标记的内容错误
解决方法: 请检查html标签内容是否正确
8.已验证文件的内容错误
解决方法: 请检查html标签内容是否正确
9.未找到相应的DMS CNAME记录
解决方法: 请检查网站的DMS设置是否正确
10.网站跳转到另一个域名
解决方法: 请检查服务器是否设置了跳转。如果是,请删除跳转,并尝试再次验证网站
四、结尾
如果你觉得本文对你有帮助,不妨给笔者点个免费的小赞支持一下下吧。
欢迎访问笔者的自建小站 依琴の小站 如果需要添加友联,不妨给我留个言吧。
这篇关于【Blog】记录一下如何让自己的自建网站让百度搜索收录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






