本文主要是介绍【MySQL·8.0·源码】subquery 子查询处理分析(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
在 SQL 中,子查询属于 Nested Query 的一种形式,根据 Kim 的分类[1],Nested Query 即嵌套查询是一种 SQL-like 形式的查询语句嵌套在另一 SQL 中,SQL-like 的嵌套子句可以出现在 SELECT、FROM 和 WHERE 子句的任意位置。
在 MySQL 中,一般把出现在 WHERE 子句中的嵌套 SQL 称为 subquery(子查询),而出现在 FROM 子句的称为 derived table,因为出现在 WHERE 子句中,最终属于 boolean factor 的一部分,目的是为了进行 FILTER 过滤记录。而出现在 FROM 子句不同,其结果最终是需要以抽象成一张虚拟表,用以与其他表进行 JOIN 操作或者用于二次计算过滤使用。
subquery 出现在 WHERE 子句中,而谓词形式一般为 [Ri.ck op Q]:
Ri 表示为第 i 张 Relation,ck 表示第 k 列,op 表示运算操作符,Q 则表示一个 SQL-like 形式的子查询
op 可以是 scalar 标量比较运算符(=、!=、>、>=、<、<=)或者是 set 集合成员运算符(IS IN,IS NOT IN、EXISTS、NOT EXISTS、ANY、ALL、SOME)。
两者的区别在于 scalar 标量运算符的右操作数总是返回当行当列值,而 set 运算符右操作数则是一个集合。
例如:
-
scalar 子查询
select * from t1 where c1 = (select max(c1) from t2 where c2 > 25); -
普通子查询
select * from t1 where c1 in (select c1 from t2 where c2 > 25);
Rule-based 转换
前面在 【MySQL·8.0·源码】MySQL 的查询处理有介绍,SQL 在 Transform 阶段会根据规则进行尝试简化,在此之前,我们必须知道子查询有以下等效规则[2]:
- Exists 的转换
可以被等效为WHERE EXISTS (select <sel> from <tbl> where <cond>)WHERE 0 < (select count(<sel>) from <tbl> where <cond>) - Not Exists 的转换
可以被等效为WHERE NOT EXISTS (select <sel> from <tbl> where <cond>)WHERE 0 = (select count(<sel>) from <tbl> where <cond>) - ANY 和 ALL 的转换
< ANY
可以被等效为< ANY (select <sel> from <tbl> where <cond>)< (select MAX(<sel>) from <tbl> where <cond>)> ANY
可以被等效为> ANY (select <sel> from <tbl> where <cond>)> (select MIN(<sel>) from <tbl> where <cond>)< ALL
可以被等效为< ALL (select <sel> from <tbl> where <cond>)< (select MIN(<sel>) from <tbl> where <cond>)> ALL
可以被等效为> ALL (select <sel> from <tbl> where <cond>)> (select MAX(<sel>) from <tbl> where <cond>)
语法树形式
引言中介绍了子查询有以下形式:
select <selitems> from Ri where Ri.ck op <Q>
在 【MySQL·8.0·源码】MySQL 语法树基础知识 中有介绍,在 MySQL 中,<SELECT> 和 <WHERE> 子句都是使用 Item 来表示各个 expression 表达式的。
对于子查询也不例外,MySQL 通过使用一个 Item_subselect 的基类引申不同类型的子查询:
Item_subselect 基类的继承关系有:
Item_subselect
+--Item_singlerow_subselect+--Item_maxmin_subselect
+--Item_exists_subselect+--Item_in_subselect+--Item_allany_subselect
其中:
- Item_singlerow_subselect 对应的是 SCALAR 子查询或者单行的子查询
- Item_exists_subselect 对应的是 [NOT] EXISTS 的子查询
- Item_in_subselect 对应的是 [NOT] IN 子查询
- Item_allany_subselect 对应
<op> ALL或者<op> ANY形式的子查询
引言中提到,子查询是 Nested Query 的一种形式,在【MySQL·8.0·源码】MySQL 语法树结构 中有介绍过形如另外几种形式的嵌套查询:
- 括号嵌套查询
select * from t3, (t1, t2) where t1.c1 = t2.c2;
- 外连接嵌套查询
select * from t1 left outer join(t2, t3) on t1.c1 = t2.c1 and t1.c2 = t3.c2 where t1.c1 = t2.c2;它们两的语法结构形式可以回顾【MySQL·8.0·源码】MySQL 语法树结构 。
同理,子查询作为另外一种嵌套查询,在 MySQL 中也是以相同的形式进行组织,而且子查询的 WHERE 子句上也使用形如 Item_xxx_subselect 代替普通的 Item 来表示一个子查询,整体语法树结构大致为:
例如,形如一下的 IN 子查询
select * from t1 where c1 in (select c1 from t2 where c1 > 25);
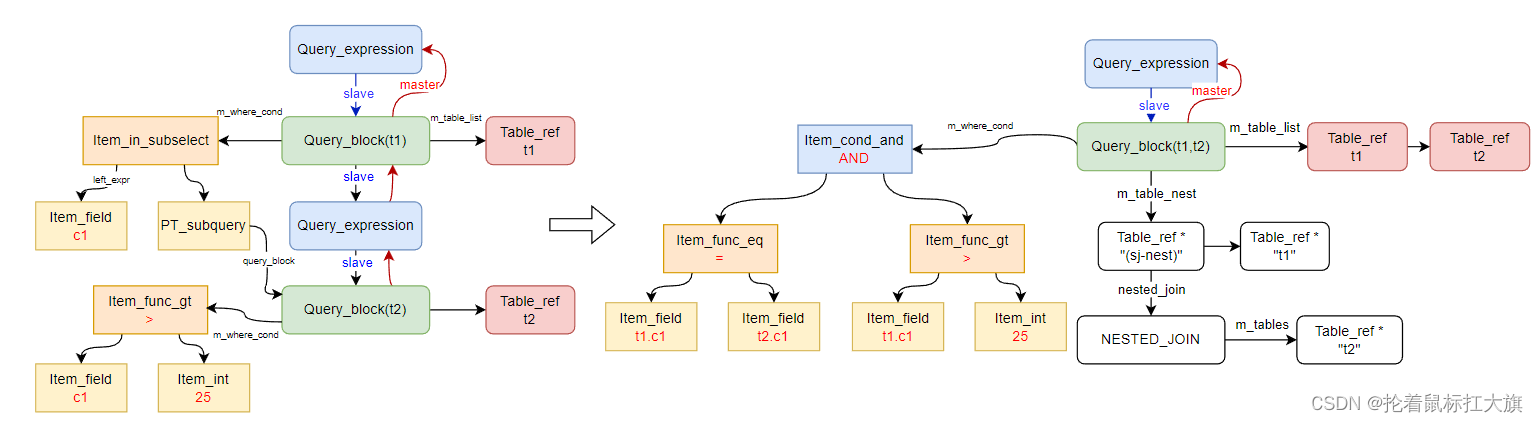
左侧为 Parse 结束后的语法树结构,两个 Query_block 分别对应外表 t1 和子查询 t2,除了 Query_block 和 Query_expression 可以从 t1 查询找到 t2 查询外,外表 t1 还通过 where 子句 Item_in_subselect 可以找到内表子查询 Query_block(t2),两个 Query 分别都有各自的 select list,from,where 子句。
右侧为经过 Transform 转为 semi-join 之后的语法树逻辑,这时内表子查询 t2 已经被 pullout 或 Merge 到外表查询块上,而内表条件也被 merge 到外表 where 条件中,而 t1 与 t2 也称为了的一种 semi-join 形式的嵌套查询。
Scalar 子查询的处理
对于只需返回单一值的子查询,称为 Scalar 子查询
可以是 scalar 标量比较运算符(=、!=、>、>=、<、<=)和 > ALL、< ALL、> ANY、< ANY 及其拓展形式
子查询中使用聚合函数(SUM,AVG,MAX,MIN,COUNT)返回结果等
例如:
select * from t1 where c1 > (select max(c1) from t2 where c1 > 25);
Prepare
在外表查询块 Query_block::prepare 进行 resolve 时,会 resolve where 条件,尝试解析 where 条件上的 Item 列到
实际 table field 的各种引用关系,而外表查询块的 where 条件是一个子查询 item(Item_singlerow_subselect),所以
最终会尝通过 Item_singlerow_subselect::fix_fields 来解析子查询 item 到实际 field 的引用。
Item_singlerow_subselect::fix_fields()->Item_subselect::fix_fields()->query_expr()->prepare()
子查询右侧操作数实际上是一个查询 Query_block,所以 resolve 时,会进一步调用子查询 Query_block::prepare 来
进一步 resolve/transform 子查询块,直到最终实际上是引用到 max(t2.c1) field
Optimize
子查询块的 prepare 是通过外层查询块的 resolve where 子句触发的,而 optimize 则是挪到了实际 Execute 阶段,由于
scalar 子查询最终返回的是单行单列结果,所以对实际延迟到 Execute 做子查询的 optimize 没有任何影响
Execute
scalar 子查询的执行由外层查询块在 evaluate where 条件时触发,对 Item_in_select 进行 boolean factor 的校验时,
触发子查询的 optimize 和 Execute,单行单列结果存储在子查询的 <select> 中
Item_singlerow_subselect::val_xxx()->Item_subselect::exec()->query_expr()->optimize()
Item_singlerow_subselect::val_xxx()->Item_subselect::exec()->query_expr()->execute()
预告:下篇继续普通 set 集合运算 subquery 的处理分析
引用
- Kim W. On optimizing an SQL-like nested query[J]. ACM Transactions on Database Systems (TODS), 1982, 7(3): 443-469.
- Ganski R A, Wong H K T. Optimization of nested SQL queries revisited[J]. ACM SIGMOD Record, 1987, 16(3): 23-33.
这篇关于【MySQL·8.0·源码】subquery 子查询处理分析(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




