本文主要是介绍mysql 导入数据 1273 - Unknown collation: ‘utf8mb4_0900_ai_ci‘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言: mysql 导入数据 遇到这个错误 1273 - Unknown collation: 'utf8mb4_0900_ai_ci' 具体原因没有深究 但应该是设计数据库的 字符集类型会出现这个问题 例如: char varchar text.....
utf8mb4 类型可以存储表情 在现在这个时代会用很多 以后会用的更多 所以不建议改成 utf8
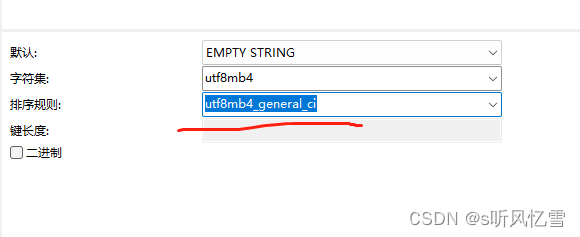
1. 设计数据库的时候 字符集设计的是 utf8mb4 (可以存储表情 特殊符号等) 然后排序规则就用的默认的了

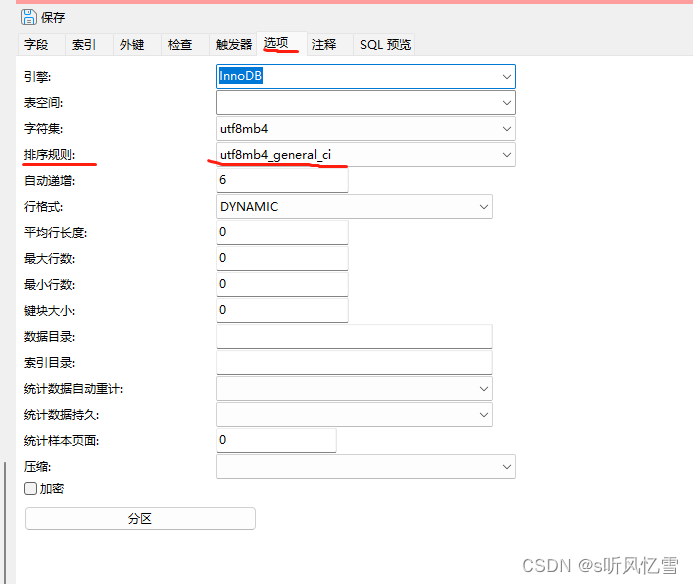
2. 解决方法也很简单 可以选择这个 utf8mb4_general_ci 算是通用 排序规则 把字段的排序规则 和表的排序规则都该成这个就行了
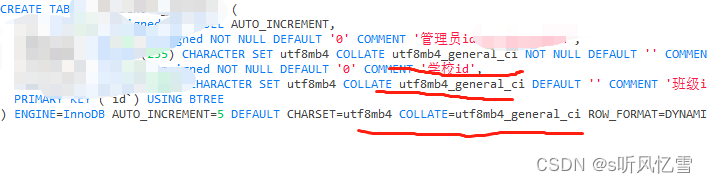
sql预览
这篇关于mysql 导入数据 1273 - Unknown collation: ‘utf8mb4_0900_ai_ci‘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








