本文主要是介绍大模型笔记【3】 gem5 运行模型框架LLama,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一 LLama.cpp
LLama.cpp 支持x86,arm,gpu的编译。
1. github 下载llama.cpp
https://github.com/ggerganov/llama.cpp.git
2. gem5支持arm架构比较好,所以我们使用编译LLama.cpp。
以下是我对Makefile的修改
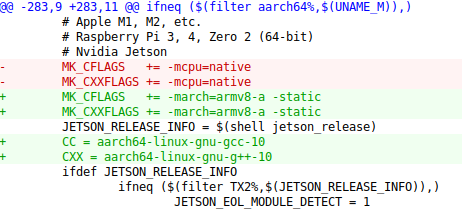
开始编译:
make UNAME_M=aarch64
编译会使用到aarch64-linux-gnu-gcc-10,编译成功可以生成一个main 文件,这里我把main重命名成main_arm_backup了。
可以使用file main查看一下文件:
![]()
3. 下载一个大模型的model到llama.cpp/models的目录下,这里我下载了llama-2-7b-chat.Q2_K.gguf。
这个模型2bit量化,跑起来不到3G的内存。
GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)

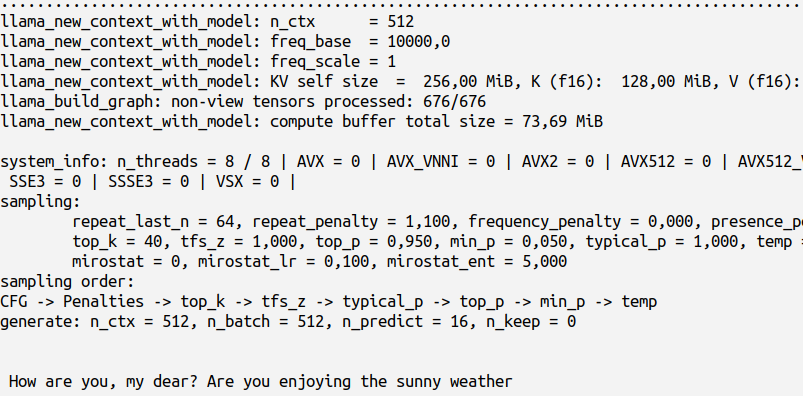
4. 此时我们可以本地运行以下main和模型,我的prompt是How are you
./main -m ./models/llama-2-7b-chat.Q2_K.gguf -p "How are you" -n 16
下图最下面一行就是模型自动生成的
二 gem5
gem5下载编译好后,我们可以使用gem5.fast运行模型了。
build/ARM/gem5.fast
--outdir=./m5out/llm_9
./configs/example/se.py -c
$LLAMA_path/llama.cpp/main-arm
'--options=-m $LLAMA_path/llama-2-7b-chat.Q2_K.gguf -p Hi -n 16'
--cpu-type=ArmAtomicSimpleCPU --mem-size=8GB -n 8
此时我的prompt是Hi,预期是n=8,跑8核。
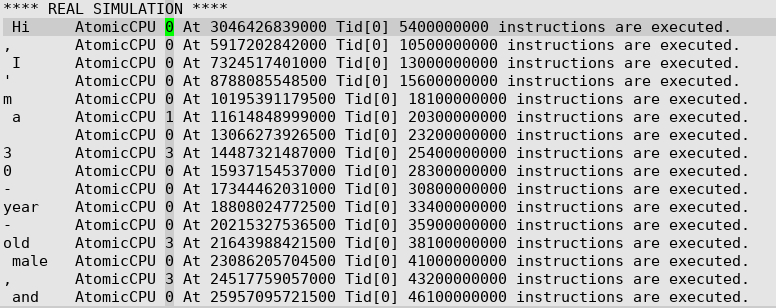
上图是gem5运行大模型时生成的simout,我增加了AtomicCPU 运行指令数量的打印,这是在gem5的改动。
如果你下载的是gem5的源码,那么现在运行起来应该只是最前面大模型的输出。
模型的回答是Hi,I'm a 30-year-old male, and
但是我预期的是8核,实际上运行起来:
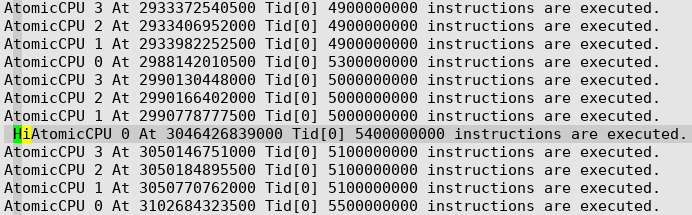
可以看出来,实际上只跑起来4核,定位后发现,模型默认是4核,需要增加-t 8选项,即threadnumber设置成8,下面的红色标注的command.
build/ARM/gem5.fast
--outdir=./m5out/llm_9
./configs/example/se.py -c
$LLAMA_path/llama.cpp/main-arm
'--options=-m $LLAMA_path/llama-2-7b-chat.Q2_K.gguf -p Hi -n 16 -t 8'
--cpu-type=ArmAtomicSimpleCPU --mem-size=8GB -n 8
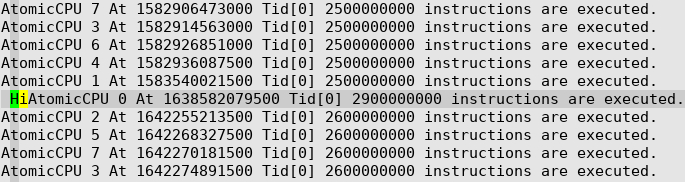
如上图所示,8核都跑起来了,处理到Hi这个token的时候,CPU0执行了2.9 Billion指令,相对于4核时的5.4 Billion约减少了一半。
这篇关于大模型笔记【3】 gem5 运行模型框架LLama的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








