本文主要是介绍java大数据hadoop2.9.2 Linux安装mariadb和hive,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、安装mariadb
版本centos7
1、检查Linux服务器是否已安装mariadb
yum list installed mariadb*
2、如果安装了,想要卸载
yum remove mariadb
rm -rf /etc/my.cnf
rm -rf /var/lib/mysql
才能完全删除
3、安装mariadb
在线网络安装
yum install -y mariadb-server
开启服务
systemctl start mariadb.service
输入下方命令,进入数据库内部
mysql
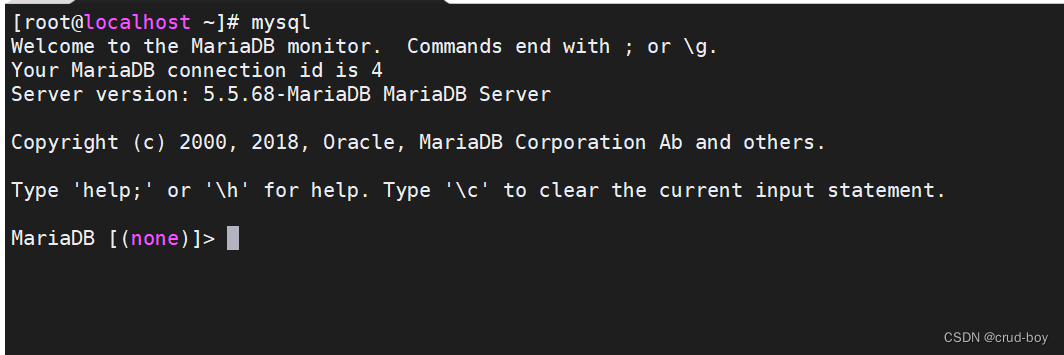
给用户权限,方便后续使用navicat等工具远程登录
show databases;
use mysql;
grant all on *.* to 'root'@'%' identified by '123456';
select user,host,password from user;
二、安装Hive
1、上传hive压缩包到Linux系统解压
tar -zcvf apache-hive-3.1.1-bin.tar.gz
把解压缩的文件复制到/usr/local/hive
2、修改配置文件
(1)修改hive-env.sh
cd /usr/local/hive/conf
cp ./hive-env.sh.template . /hive-env.sh
编辑hive-env.sh
添加下方两行
HADOOP_HOME=/usr/local/hadoop
export HADOOP_HOME

(2)修改hive-site.xml
hive-site.xml文件
编辑指定hive元数据要保存的关系数据库的连接信息
cd /usr/local/hive/conf
cp ./hive-default.xml.template ./hive-site.xml
编辑hive-site.xml
在hive-site.xml文件修改部分节点配置
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://ip:3306/hive?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description></property>
</configuration>3、启动测试
vi /etc/profile
添加下方全局配置
HIVE_HOME=/usr/local/hive
export HIVE_HOME
PATH=$HIVE_HOME/bin:$PATH
export PATH
navicat连接mysql创建一个库,即前面安装的mariadb中新增hive数据库
schematool -dbType mysql -initSchema//初始化表结构
命令有可能报错,需要下载mysql驱动
https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.47.tar.gz
tar -zxvf mysql-connector-java-5.1.47.tar.gz
解压缩后,把里面的jar包mysql-connector-java-5.1.47.jar文件拷贝到
/usr/local/hive/lib
start-all.sh启动Hadoop,然后再执行初始化表结构的命令
进入hive内部,输入hive命令,有可能报错,需要修改配置文件hive-site.xml
vi /usr/local/hive/conf/hive-site.xml
修改如下几个节点
将hive-site.xml文件中的${system:java.io.tmpdir}替换为hive的临时目录,例如我替换为/home/lch/software/Hive/apache-hive-2.1.1-bin/tmp/,该目录(tmp)如果不存在则要自己手工创建,并且赋予读写权限。
<property><name>Hive.exec.local.scratchdir</name><value>/usr/local/hive/tmp/${user.name}</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.downloaded.resources.dir</name><value>/usr/local/hive/tmp/${hive.session.id}_resources</value><description>Temporary local directory for added resources in the remote file system.</description></property><property><name>hive.server2.logging.operation.log.location</name><value>/usr/local/hive/tmp/operation_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description></property>后面输入hive即可进入
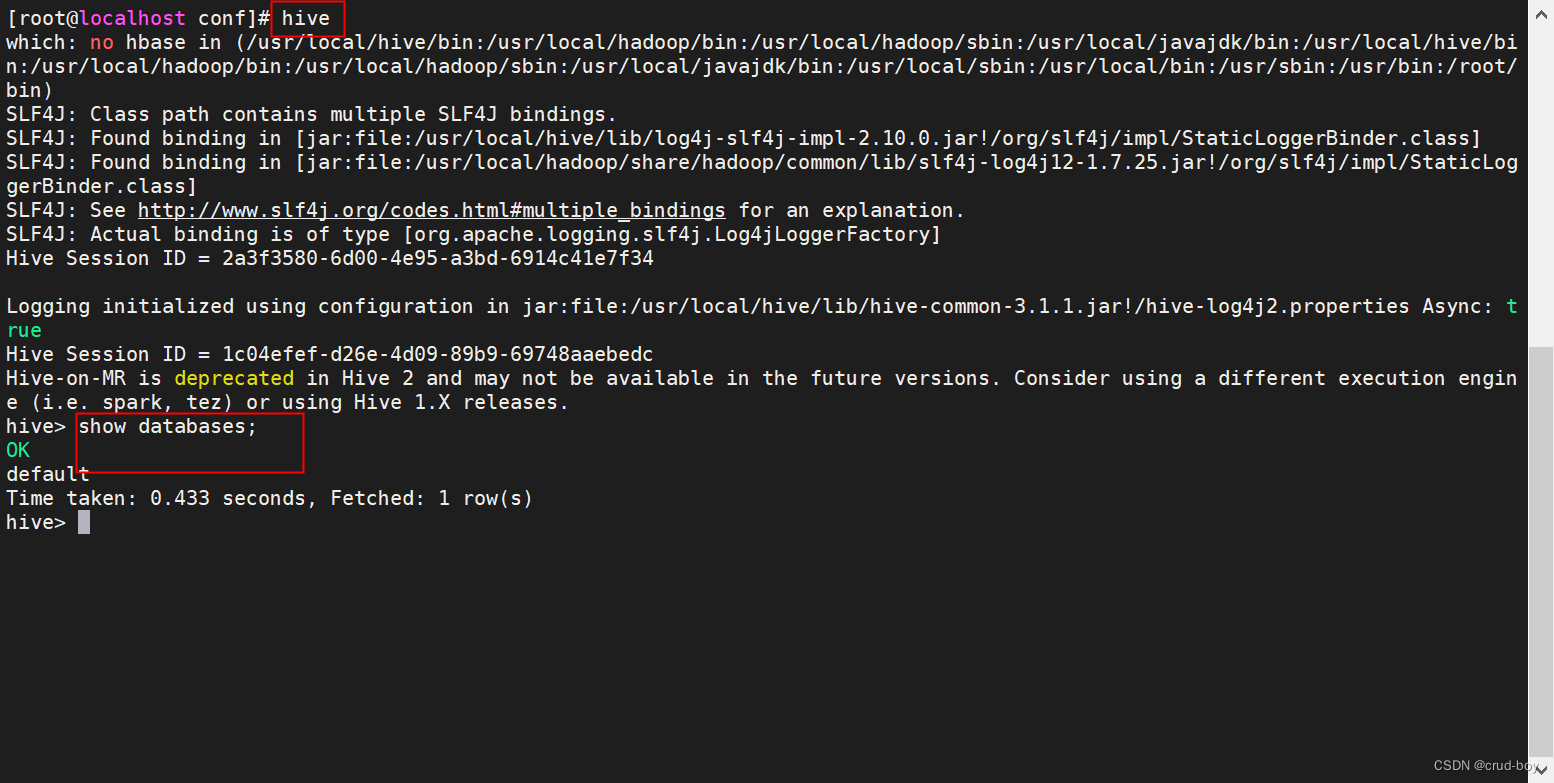
4、hive操作
创建数据库
create database test;
创建表
use test;create table t_student(id int,name string,sex string,age int
)
row format delimited fields terminated by ',';后面可在hadoop的文件系统web端查看到创建的库和表
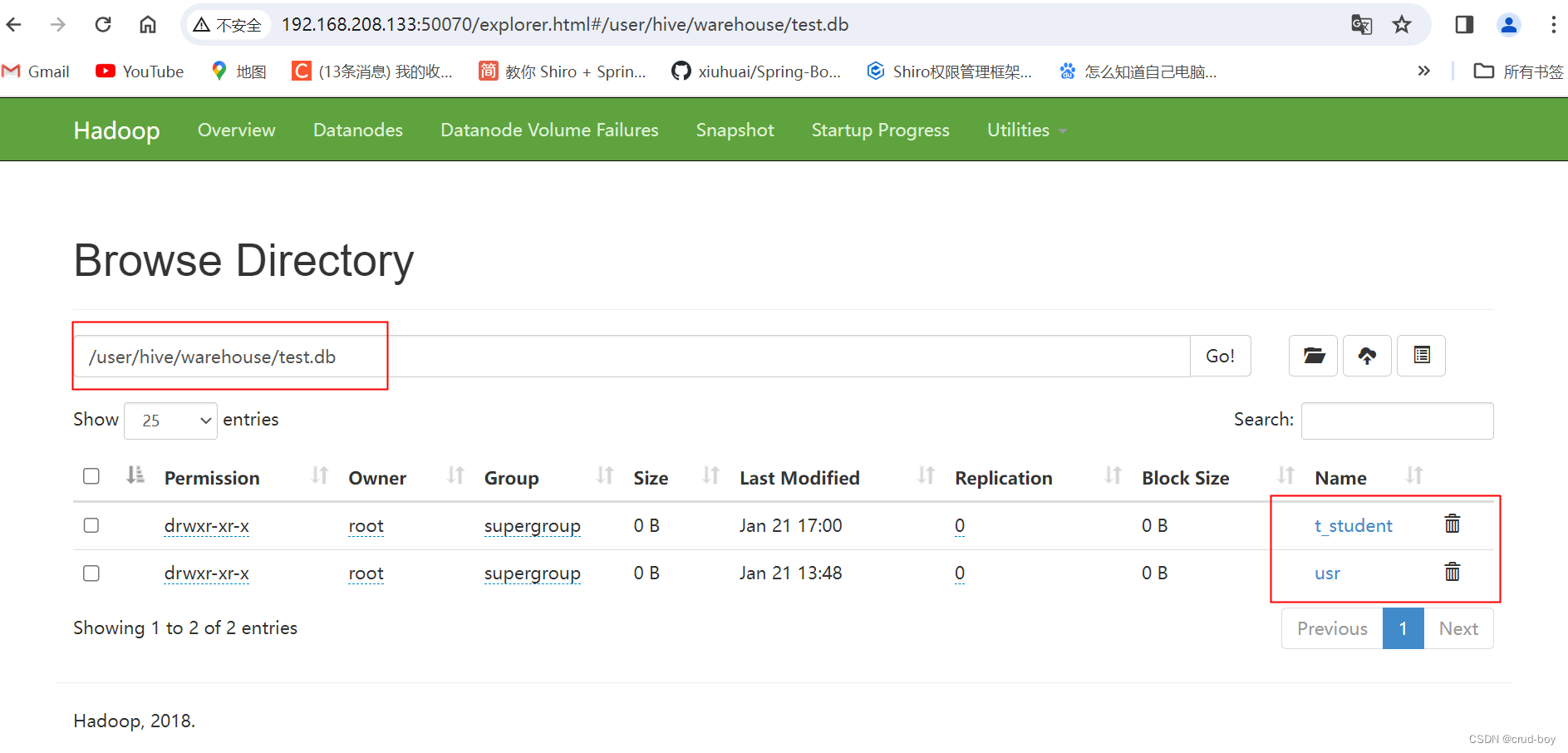
在Linux的任意一个目录新增一个文件,my_student.txt
cd /root/app/
vi ./my_student.txt
1,zhangsan,man,20
2,lisi,woman,21
3,wangwu,man,34
4,xiaofan,woman,24文件上传到hadoop中的hive目录
hdfs dfs -put ./my_student.txt /user/hive/warehouse/test.db/t_student
再去hive里面通过sql查询语句
select * from t_student;
5、Java操作
创建maven项目,依赖如下
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc --><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>2.3.4</version></dependency>操作代码
public class TestHive {public static void main(String[] args) throws Exception{test();}public static void test()throws Exception{Class.forName("org.apache.hive.jdbc.HiveDriver");Connection conn = DriverManager.getConnection("jdbc:hive2://192.168.208.133:10000/test", "root", "123456");Statement stmt = conn.createStatement();String sql = "select * from t_student";ResultSet rs = stmt.executeQuery(sql);while(rs.next()) {System.out.println(rs.getInt(1));System.out.println(rs.getString(2));System.out.println(rs.getString(3));System.out.println(rs.getInt(4));}}
}需要hive开启远程
(1)配置远程
vi /usr/local/hadoop/etc/hadoop/core-site.xml
添加两个节点
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
Linux运行命令
hiveserver2
启动hiveserver2这个命令需要等几分钟才能完全启动,后面才能运行Java代码连接hive客户端查询里面的表数据
这篇关于java大数据hadoop2.9.2 Linux安装mariadb和hive的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








