本文主要是介绍中间件-ES-中文拼音多音字插件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求背景:中文拼音多音字分词。例如:三一重工,默认拼音分词会解析成sanyizhonggong,但业务需要的是解析成:sanyizhonggong、sanyichonggong。
解决办法:
首先,查看了ES用的中文拼音插件elasticsearch-analysis-pinyin的github中的issue,是有人提出类似需求,但也没有合适的方案:https://github.com/medcl/elasticsearch-analysis-pinyin/issues。
然后:百度了各方面资料,没有找到现成解决方案。但找到一个觉得相对靠谱的解决思路,
https://blog.csdn.net/huochen1994/article/details/88876230。
解决方案:
1、分析当前ES是如何实现的中文拼音分词。
ES用的中文拼音插件是:elasticsearch-analysis-pinyin,它底层用的是nlp-lang来实现的自然语言分词。根据ES的版本从github上下载了对应版本的插件源代码,代码修改主要涉及到了:elasticsearch-analysis-pinyin-5.x、nlp-lang-1.7.8。
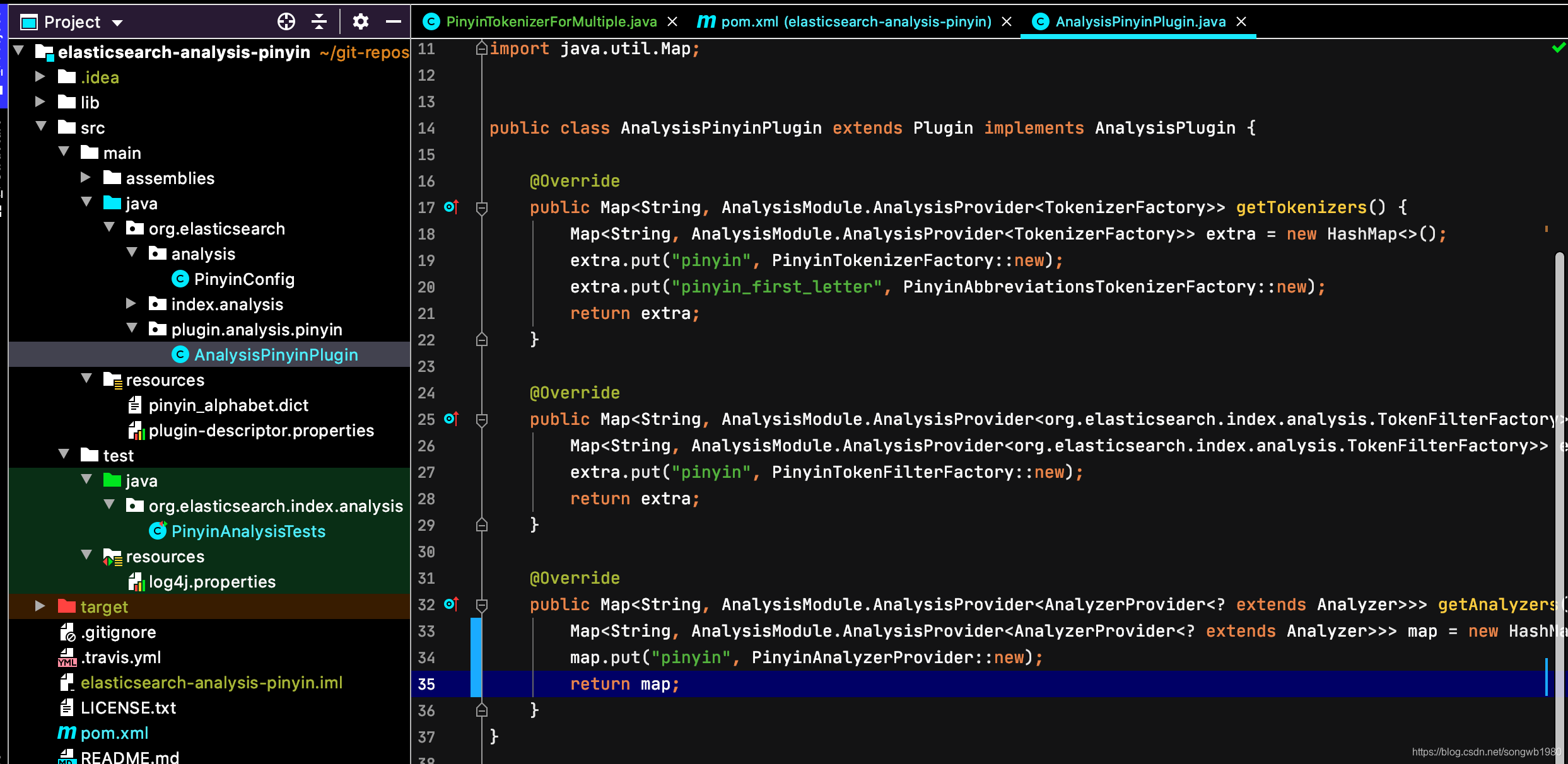
1)拼音分词插件AnalysisPinyinPlugin,它通过实现ES的org.elasticsearch.plugins.AnalysisPlugin、org.elasticsearch.plugins.Plugin,纳入了ES插件体系。如下图,其中“pinyin”就是默认拼音分词的实现。我的想法是仿照“pinyin”分词实现一个多音字的拼音分词,例如叫“multiple_by_pinyin”。这样如果需要使用多音字分词的话,在索引的settings时选择多音字的分词即可。而那些使用默认的pinyin分词的用户也不会受影响。

2、简单描述下实现
下图用类图描述下核心类的关系,可见PinyinTokenizerForMultiple是分词的核心:

在PinyinTokenizerForMultiple中使用了nlp-lang的Pinyin.java来实现中文分词,如下图:


3、测试效果
1)默认分词效果:
入参:

结果:

2)多音字分词效果
入参:同上,其中analyzer输入多音字分词插件。
结果:重分词成 chong、zhong

使用注意:不能支持大字段的多音字分词,限制在100个汉字以内。
这篇关于中间件-ES-中文拼音多音字插件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







